Optimization Design of Monitoring Sections of Qinghe River Basin
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Corporate Information
THIS DOCUMENT IS IN DRAFT FORM. THE INFORMATION CONTAINED HEREIN IS INCOMPLETE AND IS SUBJECT TO CHANGE. THIS DOCUMENT MUST BE READ IN CONJUNCTION WITH THE SECTION HEADED “WARNING” ON THE COVER OF THIS DOCUMENT. CORPORATE INFORMATION Head Office, Registered Office and No. 177-1, Chuangxin Road Principal Place of Business in the PRC Hunnan District Shenyang Liaoning Province the PRC Principal Place of Business in Hong Kong 40/F, Dah Sing Financial Centre 248 Queen’s Road East Wanchai Hong Kong Company’s Website www.neusoftmedical.com (information on this website does not form part of this Document) Joint Company Secretaries Mr. LI Feng (李峰) No. 177-1, Chuangxin Road Hunnan District Shenyang Liaoning Province the PRC Mr. CHENG Ching Kit (鄭程傑) (ACS, ACG) 40/F, Dah Sing Financial Centre 248 Queen’s Road East Wanchai Hong Kong Authorized Representatives Mr. WU Shaojie (武少傑) No. 177-1, Chuangxin Road Hunnan District Shenyang Liaoning Province the PRC Mr. CHENG Ching Kit (鄭程傑) (ACS, ACG) 40/F, Dah Sing Financial Centre 248 Queen’s Road East Wanchai Hong Kong –91– THIS DOCUMENT IS IN DRAFT FORM. THE INFORMATION CONTAINED HEREIN IS INCOMPLETE AND IS SUBJECT TO CHANGE. THIS DOCUMENT MUST BE READ IN CONJUNCTION WITH THE SECTION HEADED “WARNING” ON THE COVER OF THIS DOCUMENT. CORPORATE INFORMATION Audit Committee Dr. YAO Haixin (姚海鑫)(Chairman) Dr. CHOI Koon Shum (蔡冠深) Mr. ZHAO JOHN HUAN (趙令歡) Dr. CHEN LIAN YONG (陳連勇) Dr. FENG Xiaoyuan (馮曉源) Remuneration and Appraisal Committee Dr. FENG Xiaoyuan (馮曉源) (Chairman) Mr. WU Shaojie (武少傑) Dr. CHEN LIAN YONG (陳連勇) Dr. -

Fu Shou Yuan International Group Limited 福壽園國際集團有限公司 (Incorporated in the Cayman Islands with Limited Liability) (Stock Code: 1448)
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. Fu Shou Yuan International Group Limited 福壽園國際集團有限公司 (incorporated in the Cayman Islands with limited liability) (Stock Code: 1448) VOLUNTARY ANNOUNCEMENT STRATEGIC COOPERATION AGREEMENTS This is a voluntary announcement made by Fu Shou Yuan International Group Limited (the “Company”, together with its subsidiaries, the “Group”) for keeping the shareholders of the Company and potential investors informed of the latest business development of the Group. The board of directors (the “Board”) of the Company is pleased to announce that, on December 19, 2014, the Company entered into strategic cooperation agreements with each of the People’s Government of Hunnan District of Shenyang City* (瀋陽市渾南區人民政府)(“Shenyang City Hunnan District Government”) (“Shenyang Strategic Cooperation”) and the People’s Government of Jinzhou City* in Liaoning Province (遼寧省錦州市人民政府)(“Jinzhou City Government”) (“Jinzhou Strategic Cooperation”), in relation to the further development and cooperation in the death care services industry in the respective cities. SHENYANG STRATEGIC COOPERATION Under the Shenyang Strategic Cooperation, among other things, the Shenyang City Hunnan District Government will source potential funeral services development projects for the Company, which they will in return (i) provide due diligence support and feasibility analysis (ii) source investment funding and introduce high-technology funeral equipments and (iii) structure innovative service system, implement the Company’s business objectives and management expertise. -

Shengjing Bank Co., Ltd.* (A Joint Stock Company Incorporated in the People's Republic of China with Limited Liability) Stock Code: 02066 Annual Report Contents
Shengjing Bank Co., Ltd.* (A joint stock company incorporated in the People's Republic of China with limited liability) Stock Code: 02066 Annual Report Contents 1. Company Information 2 8. Directors, Supervisors, Senior 68 2. Financial Highlights 4 Management and Employees 3. Chairman’s Statement 7 9. Corporate Governance Report 86 4. Honours and Awards 8 10. Report of the Board of Directors 113 5. Management Discussion and 9 11. Report of the Board of Supervisors 121 Analysis 12. Social Responsibility Report 124 5.1 Environment and Prospects 9 13. Internal Control 126 5.2 Development Strategies 10 14. Independent Auditor’s Report 128 5.3 Business Review 11 15. Financial Statements 139 5.4 Financial Review 13 16. Notes to the Financial Statements 147 5.5 Business Overview 43 17. Unaudited Supplementary 301 5.6 Risk Management 50 Financial Information 6. Significant Events 58 18. Organisational Chart 305 7. Change in Share Capital and 60 19. The Statistical Statements of All 306 Shareholders Operating Institution of Shengjing Bank 20. Definition 319 * Shengjing Bank Co., Ltd. is not an authorised institution within the meaning of the Banking Ordinance (Chapter 155 of the Laws of Hong Kong), not subject to the supervision of the Hong Kong Monetary Authority, and not authorised to carry on banking and/or deposit-taking business in Hong Kong. COMPANY INFORMATION Legal Name in Chinese 盛京銀行股份有限公司 Abbreviation in Chinese 盛京銀行 Legal Name in English Shengjing Bank Co., Ltd. Abbreviation in English SHENGJING BANK Legal Representative ZHANG Qiyang Authorised Representatives ZHANG Qiyang and ZHOU Zhi Secretary to the Board of Directors ZHOU Zhi Joint Company Secretaries ZHOU Zhi and KWONG Yin Ping, Yvonne Registered and Business Address No. -
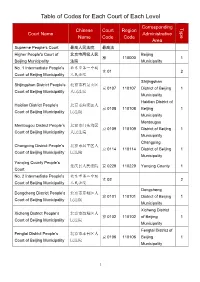
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

Annual Report Is Published
Contents 1. Company Information 2 8. Directors, Supervisors, Senior 73 2. Financial Highlights 4 Management and Employees 3. Chairman’s Statement 7 9. Corporate Governance Report 90 4. Honours and Awards 8 10. Report of the Board of Directors 117 5. Management Discussion and 9 11. Report of the Board of Supervisors 125 Analysis 12. Social Responsibility Report 128 5.1 Analysis of Overall 9 13. Internal Control 130 Operations 14. Independent Auditor’s Report 132 5.2 Financial Review 11 15. Financial Statements 142 5.3 Business Overview 44 16. Notes to the Financial Statements 150 5.4 Risk Management 52 17. Unaudited Supplementary 302 5.5 Environmental Outlook and 58 Financial Information Development Strategy 18. Organisational Chart 306 6. Significant Events 60 19. The Statistical Statements of All 307 7. Change in Share Capital and 64 Operating Institution of Shengjing Shareholders Bank 20. Definition 323 * Shengjing Bank Co., Ltd. is not an authorised institution within the meaning of the Banking Ordinance (Chapter 155 of the Laws of Hong Kong), not subject to the supervision of the Hong Kong Monetary Authority, and not authorised to carry on banking and/or deposit-taking business in Hong Kong. Chapter 1 Company Information COMPANY INFORMATION Legal Name in Chinese 盛京銀行股份有限公司 Abbreviation in Chinese 盛京銀行 Legal Name in English Shengjing Bank Co., Ltd. Abbreviation in English SHENGJING BANK Legal Representative QIU Huofa Authorised Representatives QIU Huofa and ZHOU Zhi Secretary to the Board of Directors ZHOU Zhi Joint Company Secretaries -

Vibration Control of a High-Rise Slender Structure with a Spring Pendulum Pounding Tuned Mass Damper
actuators Article Vibration Control of a High-Rise Slender Structure with a Spring Pendulum Pounding Tuned Mass Damper Qi Wang 1,2 , Hong-Nan Li 1,3 and Peng Zhang 4,* 1 School of Civil Engineering, Shenyang Jianzhu University, Hunnan District, Shenyang 110168, China; [email protected] (Q.W.); [email protected] (H.-N.L.) 2 Department of Road and Bridge Engineering, Liaoning Provincial College of Communications, Shenyang 110168, China 3 State Laboratory of Coastal and Offshore Engineering, Faculty of Infrastructure Engineering, Dalian University of Technology, Ganjingzi District, Dalian 116024, China 4 Institute of Road and Bridge Engineering, Dalian Maritime University, Dalian 116023, China * Correspondence: [email protected] Abstract: High-rise structures are normally tall and slender with a large height-width ratio. Under the strong seismic action, such a structure may experience violent vibrations and large deformation. In this paper, a spring pendulum pounding tuned mass damper (SPPTMD) system is developed to reduce the seismic response of high-rise structures. This SPPTMD system consists of a barrel limiter with the built-in viscoelastic material and a spring pendulum (SP). This novel type of tuned mass damper (TMD) relies on the internal resonance feature of the spring pendulum and the collision between the added mass and barrel limiter to consume the energy of the main structure. Based on the Hertz-damper model, the motion equation of the structure-SPPTMD system is derived. Further- more, a power transmission tower is selected to evaluate the vibration reduction performance of the Citation: Wang, Q.; Li, H.-N.; Zhang, SPPTMD system. -

Research Article Coordination and Coupling of Active and Passive Energy Optimization in Public Institutions: a Case Study of Hunnan District, Shenyang in China
Hindawi Mathematical Problems in Engineering Volume 2020, Article ID 5301842, 8 pages https://doi.org/10.1155/2020/5301842 Research Article Coordination and Coupling of Active and Passive Energy Optimization in Public Institutions: A Case Study of Hunnan District, Shenyang in China Shui Yu , Jianghui Yang, and Qixiang Gao School of Municipal and Environmental Engineering, Shenyang Jianzhu University, 110168 Shenyang, China Correspondence should be addressed to Shui Yu; [email protected] Received 26 September 2019; Revised 12 December 2019; Accepted 18 December 2019; Published 9 January 2020 Academic Editor: Carlo Renno Copyright © 2020 Shui Yu et al. 'is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Taking Hunnan District of Shenyang City as an example, this paper investigates 32 government agencies, 17 tertiary first-class hospitals, and 15 colleges and universities in Hunnan region and analyzes the energy consumption characteristics of three types of public institutions. 'rough the use of DeST energy consumption software to simulate the energy consumption of three types of public institutions, combined with the load density method to predict the total energy demand of hospitals, universities, and government agencies in Hunnan area and the MARKAL model coupling mechanism, the coupling model of active and passive energy suitable for public institutions is presented. According to the forecast results of energy demand, combined with the energy consumption structure and energy conversion efficiency, the energy supply of each subitem of the public institution was solved and the energy supply of the public institutions in Hunnan District was optimized in accordance with the relevant constraints. -

China-Hospital-Deposit-Guarantee
User Guide and Hospital list With our free of charge China Hospital Deposit Guarantee Card, you can receive in-patient medical treatment in case of accident at over 250 designated hospitals in mainland China without the need to pay deposit in advance. In case of accidental injury, you can refer to this User Guide or call the 24-hour China Hospital Deposit Guarantee Hotline (852) 2528 9333 for the details of the nearest designated hospital. Please present your China Hospital Deposit Guarantee Card and your personal indentification document with photo (e.g. China visa entry card, Hong Kong identity card/Macau identity card or passport) to the hospital staff. The designated hospital will check your eligibility with AXA General Insurance Hong Kong Limited once you are admitted to the hospital. Please remember to take your card and keep it with you whenever you travel to mainland China. Should you forget to bring it with you, provide your policy number to the designated hospital and they will try to contact with AXA General Insurance Hong Kong Limited to check your eligibility for the service. Please note that this will take time and your hospital admission and in-patient treatment may be delayed. Hong Kong (852) 2867 8678 (852) 2528 9333 AXA General Insurance Hong Kong Limited 5/F, AXA Southside 38 Wong Chuk Hang Road Wong Chuk Hang, Hong Kong 1. Verify the information on your card. If any changes are required, please call the Insurance Service Hotline. 2. Notify AXA immediately if you lose your card. 3. Return the card when you or any insured family members cease to be insured. -

Gft Group Liaoning General Fair Testing Co.,Ltd
通 正 集 团 GFT GROUP LIAONING GENERAL FAIR TESTING CO.,LTD. 目录 Content 01 02 03 04 05 News on GFT Group Environmental Environmental An overview of environmental Qualification detection consulting the performance protection business business segment segment 01 News on environmental protection The meeting made recommendations on the formulation of the fourteenth five-year plan for national economic and social development: Promote green development and harmonious coexistence between human and nature. The Recommendation points out, adhere to the concept that clear water and green mountains are gold and silver mountains. We should respect nature, comply with nature and protect nature. We should give priority to conservation, protection and natural restoration in order to protect the boundaries of natural and ecological security. Implement the strategy of sustainable development and improve the mechanism for overall planning and coordination in the field of ecological progress. Build a system for promoting ecological progress to promote green transformation in economic and social development in all respects, and modernize the system for achieving harmonious coexistence between human and nature. We should accelerate efforts to promote green and low-carbon development, continue to improve environmental quality, and improve the quality and stability of the ecosystem, the efficiency of resource utilization. 01 News on environmental protection President Xi Jinping’s important speech at the general debate of the 75th session of the UN General Assembly. -

Global Environmental Fund “China Contaminated Site Management Project” Liaoning Demonstration Project Public Disclosure Authorized
Global environmental fund “China Contaminated Site Management Project” Liaoning demonstration project Public Disclosure Authorized Environmental and Social Impact Assessment Report for Remeidation of the Northeast Pharmaceutical Plant contaminated site Public Disclosure Authorized Public Disclosure Authorized Shenyang Lvheng Environment Consulting Co. Ltd April 2018 Public Disclosure Authorized Project name: Global environmental fund “China Contaminated Site Management Project” Liaoning demonstration project Environmental and Social Impact Assessment Report for Remeidation of the Northeast Pharmaceutical Plant contaminated siteName of outcome: Evaluation report of environmental and social effects Responsible unit: Shenyang Lvheng Environment Counsulting Co. Ltd Version: 20180619 Submitted to: Department of Environmental Protection of Liaoning Province “China Contaminated Site Management Project” Project-in-charge Person-in-charge of project: Wang Chengbing Deputy General manager, Senior Engineer Main drafters: Shi Deyu, Senior engineer Fan Huijiang, Senior engineer Yuan Baocheng, Engineer Fang Xiaoming, Engineer Liu Zhongzhi, Engineer A Lina, Engineer Global environmental fund “China Contaminated Site Management Project” Liaoning demonstration project Environmental and Social Impact Assessment Report for Remeidation of the Northeast Pharmaceutical Plant contaminated site Table of contents 1. Project overview ........................................................................................................................ 1 1.1 Project -

Swine Disease Global Surveillance Report
Swine Disease Global Surveillance Report Thursday, August 16, 2018 There is now a second case of African swine fever (ASF) in China. It was found in a slaughterhouse where 30 pigs died of ASF. The slaughterhouse is located in the city of Zhengzhou in the Henan province. The pigs came from Tangyuan district of the city of Jiamusi, in the Heilongjiang province, over 500 miles to northeast of the first reported herd, which was detected approximately two weeks ago. By road, the distance from the farm to the slaughterhouse is approximately 1,400 miles, travelling through areas with high pig density. The slaughterhouse is a large commercial facility, owned by Shuanghui, part of the WH Group, the world’s largest pork producer. Government officials are moving quickly to try to isolate the disease. The slaughterhouse has been closed with a no movement zone within a radius of approximately of 6 miles and a zone of 2 miles for destroying all pigs. This news outbreak signals that there may be a number of concerns about the status of ASF in China. The distance between the original detection in Shenyang and this newly identified farm, as well as slaughterhouse, shows that the disease is being transported widely. The areas of concern now involve multiple Chinese provinces and heighten the likelihood of further cases. 4 key locations: Red dot, new ASF outbreak reported in slaughterhouse is located in the city of Zhengzhou in the Henan province; blue: first ASF outbreak reported in a small pig farm in district of Shenbei New, in the province of Liaoning; green dot: farm (owner Wang) located in the Hunnan District, Shenyang city, Liaoning province; purple: Tangyuan district of the city of Jiamusi, in the Heilongjiang province. -

Exploring the New Child Protection System in Mainland China: How Does It Work?
Accepted Manuscript Exploring the new child protection system in Mainland China: How does it work? Xiaoou Man, Richard P. Barth, Yue-e Li, Zuobao Wang PII: S0190-7409(17)30257-8 DOI: doi: 10.1016/j.childyouth.2017.03.012 Reference: CYSR 3274 To appear in: Children and Youth Services Review Received date: 24 May 2016 Revised date: 18 March 2017 Accepted date: 18 March 2017 Please cite this article as: Xiaoou Man, Richard P. Barth, Yue-e Li, Zuobao Wang , Exploring the new child protection system in Mainland China: How does it work?. The address for the corresponding author was captured as affiliation for all authors. Please check if appropriate. Cysr(2017), doi: 10.1016/j.childyouth.2017.03.012 This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain. ACCEPTED MANUSCRIPT Exploring the new child protection system in Mainland China: How does it work? Xiaoou Man, PhD Northeastern University, School of Humanities and Law Richard P. Barth, PhD, MSW University of Maryland, School of Social Work Yue-e Li, PhD Northeastern University, School of Humanities and Law Zuobao Wang, PhD Northeastern University, School of Humanities and Law Correspondence should be addressed to Xiaoou Man as follows: Dr.