Lab 1: Installing Python
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Consonant Characters and Inherent Vowels
Global Design: Characters, Language, and More Richard Ishida W3C Internationalization Activity Lead Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 1 Getting more information W3C Internationalization Activity http://www.w3.org/International/ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 2 Outline Character encoding: What's that all about? Characters: What do I need to do? Characters: Using escapes Language: Two types of declaration Language: The new language tag values Text size Navigating to localized pages Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 3 Character encoding Character encoding: What's that all about? Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 4 Character encoding The Enigma Photo by David Blaikie Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 5 Character encoding Berber 4,000 BC Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 6 Character encoding Tifinagh http://www.dailymotion.com/video/x1rh6m_tifinagh_creation Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 7 Character encoding Character set Character set ⴰ ⴱ ⴲ ⴳ ⴴ ⴵ ⴶ ⴷ ⴸ ⴹ ⴺ ⴻ ⴼ ⴽ ⴾ ⴿ ⵀ ⵁ ⵂ ⵃ ⵄ ⵅ ⵆ ⵇ ⵈ ⵉ ⵊ ⵋ ⵌ ⵍ ⵎ ⵏ ⵐ ⵑ ⵒ ⵓ ⵔ ⵕ ⵖ ⵗ ⵘ ⵙ ⵚ ⵛ ⵜ ⵝ ⵞ ⵟ ⵠ ⵢ ⵣ ⵤ ⵥ ⵯ Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 8 Character encoding Coded character set 0 1 2 3 0 1 Coded character set 2 3 4 5 6 7 8 9 33 (hexadecimal) A B 52 (decimal) C D E F Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 9 Character encoding Code pages ASCII Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 10 Character encoding Code pages ISO 8859-1 (Latin 1) Western Europe ç (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 11 Character encoding Code pages ISO 8859-7 Greek η (E7) Copyright © 2005 W3C (MIT, ERCIM, Keio) slide 12 Character encoding Double-byte characters Standard Country No. -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -

Handy Katakana Workbook.Pdf
First Edition HANDY KATAKANA WORKBOOK An Introduction to Japanese Writing: KANA THIS IS A SUPPLEMENT FOR BEGINNING LEVEL JAPANESE LANGUAGE INSTRUCTION. \ FrF!' '---~---- , - Y. M. Shimazu, Ed.D. -----~---- TABLE OF CONTENTS Page Introduction vi ACKNOWLEDGEMENlS vii STUDYSHEET#l 1 A,I,U,E, 0, KA,I<I, KU,KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #1 2 PRACTICE: A, I,U, E, 0, KA,KI, KU,KE, KO, GA,GI,GU, GE,GO, N WORKSHEET #2 3 MORE PRACTICE: A, I, U, E,0, KA,KI,KU, KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #~3 4 ADDmONAL PRACTICE: A,I,U, E,0, KA,KI, KU,KE, KO, GA,GI,GU,GE,GO, N STUDYSHEET #2 5 SA,SHI,SU,SE, SO, ZA,JI,ZU,ZE,ZO, TA, CHI, TSU, TE,TO, DA, DE,DO WORI<SHEEI' #4 6 PRACTICE: SA,SHI,SU,SE, SO, ZA,II, ZU,ZE,ZO, TA, CHI, 'lSU,TE,TO, OA, DE,DO WORI<SHEEI' #5 7 MORE PRACTICE: SA,SHI,SU,SE,SO, ZA,II, ZU,ZE, W, TA, CHI, TSU, TE,TO, DA, DE,DO WORKSHEET #6 8 ADDmONAL PRACI'ICE: SA,SHI,SU,SE, SO, ZA,JI, ZU,ZE,ZO, TA, CHI,TSU,TE,TO, DA, DE,DO STUDYSHEET #3 9 NA,NI, NU,NE,NO, HA, HI,FU,HE, HO, BA, BI,BU,BE,BO, PA, PI,PU,PE,PO WORKSHEET #7 10 PRACTICE: NA,NI, NU, NE,NO, HA, HI,FU,HE,HO, BA,BI, BU,BE, BO, PA, PI,PU,PE,PO WORKSHEET #8 11 MORE PRACTICE: NA,NI, NU,NE,NO, HA,HI, FU,HE, HO, BA,BI,BU,BE, BO, PA,PI,PU,PE,PO WORKSHEET #9 12 ADDmONAL PRACTICE: NA,NI, NU, NE,NO, HA, HI, FU,HE, HO, BA,BI,3U, BE, BO, PA, PI,PU,PE,PO STUDYSHEET #4 13 MA, MI,MU, ME, MO, YA, W, YO WORKSHEET#10 14 PRACTICE: MA,MI, MU,ME, MO, YA, W, YO WORKSHEET #11 15 MORE PRACTICE: MA, MI,MU,ME,MO, YA, W, YO WORKSHEET #12 16 ADDmONAL PRACTICE: MA,MI,MU, ME, MO, YA, W, YO STUDYSHEET #5 17 -
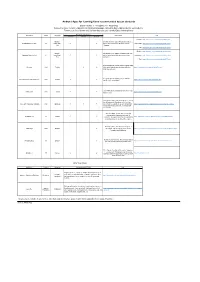
Android Apps for Learning Kana Recommended by Our Students
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

Na Kana Magiti Kei Na Lotu
1 NA KANA MAGITI KEI NA LOTU (Vola Tabu : Maciu 22:1-10; Luke 14:12-24) Vola ko Rev. Dr. Ilaitia S. Tuwere. Sa inaki ni vunau oqo me taroga ka sauma talega na taro : A cava na Lotu? Ni da tekivu edaidai ena noda solevu vakalotu, sa na yaga meda taroga ka tovolea talega me sauma na taro oqori. Ia, ena levu na kena isau eda na solia, me vaka na: gumatuataki ni masu kei na vulici ni Vola Tabu, bula vakayalo, muria na ivakarau se lawa ni lotu ka vuqa tale. Na veika oqori era ka dina ka tu kina eso na isau ni taro : A Cava na Lotu. Na i Vola Tabu e sega ni tuvalaka vakavosa vei keda na ibalebale ni lotu. E vakavuqa me boroya vei keda na iyaloyalo me vakadewataka kina na veika eso e vinakata me tukuna. E sega talega ni solia e duabulu ga na iyaloyalo me baleta na lotu. E vuqa sara e solia vei keda. Oqori me vaka na Qele ni Sipi kei na i Vakatawa Vinaka; na Vuni Vaini kei na Tabana; na i Vakavuvuli kei iratou na nona Gonevuli se Tisaipeli, na Masima se Rarama kei Vuravura, na Ulu kei na Vo ni Yago taucoko, ka vuqa tale. Ena mataka edaidai, meda raica vata yani na iyaloyalo ni kana magiti. E rua na kena ivakamacala eda rogoca, mai na Kosipeli i Maciu kei na nei Luke. Na kana magiti se na solevu edua na ivakarau vakaitaukei. Eda soqoni vata kina vakaveiwekani ena noda veikidavaki kei na marau, kena veitalanoa, kena sere kei na meke, kena salusalu kei na kumuni iyau. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

KANA Guidelines
Knoxville Area Of Narcotics Anonymous Area Guidelines Revised: August 2018 1 | P a g e Table of Contents Table of Contents ........................................................................................................................... 2 Article I. Name ............................................................................................................................... 6 Article II. Defining KANA ............................................................................................................ 6 Article III. Purpose of the Area Service Committee ................................................................... 6 Article IV. Spiritual Guidelines, Order of Guiding Documents ................................................ 7 Article V. The KANA ASC ........................................................................................................... 7 Article VI. Participants ................................................................................................................. 7 Section A. Voting Participants ............................................................................................. 7 Section B. Non-voting Participants ...................................................................................... 8 Section C. Observers ............................................................................................................ 8 Article VII. Voting and Quorum .................................................................................................. 8 Section -

Introduction to the Special Issue on Japanese Geminate Obstruents
J East Asian Linguist (2013) 22:303-306 DOI 10.1007/s10831-013-9109-z Introduction to the special issue on Japanese geminate obstruents Haruo Kubozono Received: 8 January 2013 / Accepted: 22 January 2013 / Published online: 6 July 2013 © Springer Science+Business Media Dordrecht 2013 Geminate obstruents (GOs) and so-called unaccented words are the two properties most characteristic of Japanese phonology and the two features that are most difficult to learn for foreign learners of Japanese, regardless of their native language. This special issue deals with the first of these features, discussing what makes GOs so difficult to master, what is so special about them, and what makes the research thereon so interesting. GOs are one of the two types of geminate consonant in Japanese1 which roughly corresponds to what is called ‘sokuon’ (促音). ‘Sokon’ is defined as a ‘one-mora- long silence’ (Sanseido Daijirin Dictionary), often symbolized as /Q/ in Japanese linguistics, and is transcribed with a small letter corresponding to /tu/ (っ or ッ)in Japanese orthography. Its presence or absence is distinctive in Japanese phonology as exemplified by many pairs of words, including the following (dots /. / indicate syllable boundaries). (1) sa.ki ‘point’ vs. sak.ki ‘a short time ago’ ka.ko ‘past’ vs. kak.ko ‘paranthesis’ ba.gu ‘bug (in computer)’ vs. bag.gu ‘bag’ ka.ta ‘type’ vs. kat.ta ‘bought (past tense of ‘buy’)’ to.sa ‘Tosa (place name)’ vs. tos.sa ‘in an instant’ More importantly, ‘sokuon’ is an important characteristic of Japanese speech rhythm known as mora-timing. It is one of the four elements that can form a mora 1 The other type of geminate consonant is geminate nasals, which phonologically consist of a coda nasal and the nasal onset of the following syllable, e.g., /am. -

Page 1 LAWATU NI CURUCURU Kei Na IVAKALEKALEKA NI CURUCURU SEGA-NI-SAUMI KEVAKA O GADREVA NA VEIVUKE MO KILA VINAKA NA NOTISI OQO, VEITARATARA MAI
LAWATU NI CURUCURU kei na IVAKALEKALEKA NI CURUCURU SEGA-NI-SAUMI KEVAKA O GADREVA NA VEIVUKE MO KILA VINAKA NA NOTISI OQO, VEITARATARA MAI KIVEI BOB MUENCH ena (801) 578-8378. Na idusidusi oqo e volai me vukei iko mo kila na vei lawatu kei na iwalewale ni curucuru sega-ni-saumi ka vakakina se ocei e rawa ni sega-ni-saumi nona icurucuru ena vei Koronivuli ena Tikina o Salt Lake City. Rai-Vakararaba 1. Na lawa e Utah e vakatara na kena saumi na icurucuru ena kalasi vitu ka yacova sara na tinikarua. Kena ibalebale oqo ena rawa ni sauma na nomu gonevuli na isau ni iyaya ni vuli, itaviqaravi, kei na vei porokaramu tale eso. 2. Na icurucuru kece e rawa ni sega-ni-saumi. 3. Na gonevuli kece e cakitaki nona kerekere ni icurucuru sega-ni-saumi e tiko nona dodonu ni kerekere tale se appeal. Lawatu ni Tikina me baleta na iCurucuru Sega-ni-Saumi Na Matabose ni Vuli ena Tikina ni Koronivuli e Salt Lake City e sa tekivuna ka vakatara e dua na lawatu me baleta na curucuru sega-ni-saumi kei na ituvatuva ni saumi icurucuru ka vakatudonutaka kina na lawa ni yasana. Na lawatu, iwalewale, kei na ituvatuva ni saumi icurucuru e rawa ni laurai ena drauniveva ni tikina ena initaneti:slcschools.org/board-of-education/policies/ - scroll down the page and look for S-10: Curucuru ni Gonevuli kei na Curucuru Sega-ni-Saumi iWalewale ni Curucuru Sega-ni-Saumi Na dui qasenivuli-liu ena vei koronivuli era sa lesi me ra railesuva ka vakayulewa ena vei kerekere ni curucuru sega-ni-saumi. -

Sveučilište Josipa Jurja Strossmayera U Osijeku Filozofski Fakultet U Osijeku Odsjek Za Engleski Jezik I Književnost Uroš Ba
CORE Metadata, citation and similar papers at core.ac.uk Provided by Croatian Digital Thesis Repository Sveučilište Josipa Jurja Strossmayera u Osijeku Filozofski fakultet u Osijeku Odsjek za engleski jezik i književnost Uroš Barjaktarević Japanese-English Language Contact / Japansko-engleski jezični kontakt Diplomski rad Kolegij: Engleski jezik u kontaktu Mentor: doc. dr. sc. Dubravka Vidaković Erdeljić Osijek, 2015. 1 Summary JAPANESE-ENGLISH LANGUAGE CONTACT The paper examines the language contact between Japanese and English. The first section of the paper defines language contact and the most common contact-induced language phenomena with an emphasis on linguistic borrowing as the dominant contact-induced phenomenon. The classification of linguistic borrowing thereby follows Haugen's distinction between morphemic importation and substitution. The second section of the paper presents the features of the Japanese language in terms of origin, phonology, syntax, morphology, and writing. The third section looks at the history of language contact of the Japanese with the Europeans, starting with the Portuguese and Spaniards, followed by the Dutch, and finally the English. The same section examines three different borrowing routes from English, and contact-induced language phenomena other than linguistic borrowing – bilingualism , code alternation, code-switching, negotiation, and language shift – present in Japanese-English language contact to varying degrees. This section also includes a survey of the motivation and reasons for borrowing from English, as well as the attitudes of native Japanese speakers to these borrowings. The fourth and the central section of the paper looks at the phenomenon of linguistic borrowing, its scope and the various adaptations that occur upon morphemic importation on the phonological, morphological, orthographic, semantic and syntactic levels. -

Abin Yi Idan Kana Da COVID-19
Abin yi idan kana da COVID-19 KOYI YADDA ZAKA KULA DA KANKA DA KUMA WADANSU A GIDA. Menene Alamomin COVID-19? • Akwai alamomi iri-iri masu yawa, fara daga masu sauki zuwa masu tsanani. Wadansu mutane ba su da wadansu alamomin cutar. • Mafi yawan alamomi sun haɗa da zazzaɓi ko sanyi, tari, gajeruwar numfashi ko wahalar numfashi, gajiya, ciwon jijiyoyi ko jiki, ciwon kai, rashin dandano ko jin wari, ciwon makogwaro ko yoyon hanci, tashin zuciya ko amai, da gudawa. Wanene ke da Hadari don Me ya kamata in yi idan ina da alamomin COVID-19? Tsananin ciwo daga COVID-19? • Tsaya a gida! Kada ka bar gida sai dai don • Tsakanin manya, haɗarin yin gwaji don COVID-19 da sauran muhimman mummunan rashin lafiya yana abubuwan kula da lafiya ko bukatun ƙaruwa tare da shekaru, tsofaffi yau-da-kullum, kamar su kayan masarufi, na cikin haɗari mafi girma. idan wani ba zai iya samar maka su ba. Kada ka je wurin aiki, ko da kuwa kana • Mutane daga wadansu launin ma’aikaci mai muhimmanci. fatar da kabilu (hade da Bakake, ’yan Latin Amurka da ’Yan asali) • Yi magana da mai baka kulawar lafiya! saboda tsarin lafiya da rashin Yi amfani da tarho ko telemedicine idan zai yiwu. daidaiton zamantakewa. • Yi gwaji! Idan mai baka kulawa baya bayar • Mutanen na kowane shekaru yin gwaji, ziyarci nyc.gov/covidtest ko kira waɗanda suke da yanayin 311 don neman wurin gwaji kusa da kai. boyayyen rashin lafiya, kamar: Wurare dayawa Na bayar da gwajin kyauta. Ciwon daji • Kira 911 a yanayin gaggawa! Idan kana Daɗɗaɗen Ciwon koda da matsalar numfashi, zafi ko matsin lamba Daɗɗaɗen ciwon huhu a kirjinka, ka rikice ko baka iya zama farke, Ciwon mantuwa da sauran kana da leɓuna masu ruwan bula ko fuska, cututtukan jijiyoyin jiki ko wadansu yanayin gaggawa, jeka asibiti Ciwon suga ko kira 911 nan take. -

Wai Vakaviti
WAI VAKAVITI Fijian Medicine SCIENTIA EST POTENTIA 2 1 Foreword An extended project of WAI VAKAVITI (Tabani Vosa Kei Na ITOVO Vakaviti Tabacakacaka Itaukei, March 1992) This task is initiated for knowledge propagation and conservation of Fijian Medicine. It is from this book and day to day collected knowledge that further combination of herbal medicine will be attempted for a broader spectrum and focussed medicinal care. Later versions will be coming later hopefully containing plants pictures and measurements together with their botanical names if that is possible. www.mobdelta.yolasite.com The following was involved in this project Mr.Meli Tupua Mr. Eroni Takape Mr. Joeli Tupua Mr. Apisai Camaitoga Ms. Nai Laisa Tanioria Mr. Marika Camaitoga Mr. Ropate Matalau Mr. Maika Tupua Mr. Meli Nayakalou Mr. Jone Karitakia 3 2 Table of Contents 1 FOREWORD ............................................................................................................................................. 2 2 TABLE OF CONTENTS ............................................................................................................................... 3 3 ALSA/VIDIKOSO ....................................................................................................................................... 7 4 BATABATĀ ............................................................................................................................................... 7 5 BATI [MOSI] ..........................................................................................................................................