Light-Touch Data-Parallel Shell Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LS-90 Operation Guide
Communicating Thermostat - TheLS-90 has 2 RTM-1 radio ports. These allow your thermostat to communicate with other systems. Depending on your area Power Company, programs may be available to connect your thermostat to power grid status information. This can make it easy for you to moderate your energy use at peak hours and use power when it is less expensive. The RTM-1 ports also allow you to connect yourLS-90 to your home WiFi network. This can give you access to your home’s HVAC system even when you are away. It can also give you access to web based efficient energy management sites that RTM-1 port can help you save money and protect the environment. Customer support:877-254-5625 or www.LockStateConnect.com PG 20 PG 1 LS-90 Operation Guide top cover The LS-90 programmable communicating Wire thermostat operates via a high-quality, easy- terminals Power Grid Reset to-use touch screen. To program or adjust status button your LS-90, simply touch your finger or the indicators Home stylus firmly to the screen. The screen will button SAVE NORMAL automatically light up and you will hear a ENERGY $0.05 KW H FAN 12:30pm “beep.” The screen will respond differently to 5/25 WED different types of touches, so you may want Control o TARGET bar to experiment with both your finger and with F 77o Save TEMP Power the stylus, which is included with the LS-90, Energy HUMI D button HVAC 23% Button STATUS Power Status Normal $.05/kW to see what works best for you. -
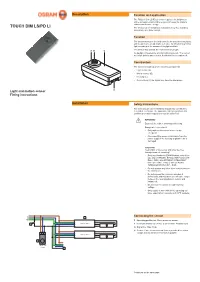
Mounting Instructions OSRAM Sensor Touch DIM LS/PD LI Light And
Description Function and application The TOUCH DIM LS/PD LI sensor regulates the brightness at the workplace and in office areas to increase the working comfort and to save energy. TOUCH DIM LS/PD LI The sensor can be installed in luminaires (e.g. floor standing luminaires) or in false ceilings. Function The sensor measures the brightness in the area to be regulated and keeps this to an adjustable set value by introducing artificial light according to the amount of daylight available. A B C The sensor also detects the movements of people. As daylight increases the artificial light is reduced . The sensor no longer detects any motions, it switches the luminaires off. Construction The sensor is made up of the following components: • Light sensor (A) • Motion sensor (B) • Housing (C) • Connections (D) for signal line, zero line and phase D Light and motion sensor Fitting instructions Installation Safety instructions The sensor must only be installed and put into operation by a qualified electrician. The applicable safety regulations and accident prevention regulations must be observed. WARNING! Exposed, live cables or damaged housing. Danger of electric shock! • Only work on the sensor when it is de- energized. • Disconnect the sensor or luminaire from the power supply if the housing or plastic lens is damaged. CAUTION! Destruction of the sensor and other devices through incorrect mounting! • Only use electronic OSRAM ballast coils of the type QUICKTRONIC INTELLIGENT DALI (QTi DALI…DIM), HALOTRONIC INTELLIGENT DALI (HTi DALI…DIM) or OPTOTRONIC INTELLIGENT DALI (OT…DIM). • Do not operate any other other control units on the control line. -
Uniq Tablet Ll 12.2” User Manual Version 1.0
Uniq Tablet ll 12.2” User Manual version 1.0 1 This manual was not subject to any language revision. This manual or any part of it may not be copied, reproduced or otherwise distributed without the publisher‘s consent. All rights reserved. Elcom, spoločnosť s ručením obmedzeným, Prešov © ELCOM, spoločnosť s ručením obmedzeným, Prešov, 2017 2 CONTENTS IMPORTANT NOTICES .............................................................................................................04 CONFORMITY DECLARATION .................................................................................................05 KEY LAYOUT AND DEFINITION ...............................................................................................06 USING THE DEVICE ..................................................................................................................07 BEFORE USING THE DEVICE ..................................................................................................10 BEFORE USING THE DEVICE ..................................................................................................10 LOGGING ON TO THE OPERATING SYSTEM ........................................................................10 SWITCHING OFF .......................................................................................................................10 RESTARTING ............................................................................................................................. 11 CONTROLLING ......................................................................................................................... -

Productionview™ Hd Mv
Installation and User Guide PRODUCTIONVIEW™ HD MV High Definition Camera Control Console with Integrated Multiviewer Touch Screen Control, Multi-View Control Panel Layout Options and Expanded I/O Capabilities Part Number 999-5625-000 North America Part Number 999-5625-001 International ©2013 Vaddio - All Rights Reserved ● ProductionVIEW HD MV ● Document Number 342-0241 Rev. F ProductionVIEW HD MV Inside Front Cover - Blank ProductionVIEW HD MV Manual - Document Number 342-0241 Rev F Page 2 of 36 ProductionVIEW HD MV Overview: The Vaddio™ ProductionVIEW HD MV Production Switcher with integrated camera controller and multiviewer is a powerful, cost effective and easy to operate platform for live presentation environments. With Vaddio’s revolutionary TeleTouch™ Touch Screen Control Panel (optional, sold separately), production operators can easily see and switch all live video feeds and create “video thumbnails” of preset camera shots with the touch of their finger. ProductionVIEW HD MV is a broadcast quality, 6x2; multi-format, seamless video mixer that also provides two discrete outputs for dual bus program feeds (two independent 6 x 1 switchers/mixers). ProductionVIEW HD MV Accepting any combination of input signals from Camera Control Console analog HD YPbPr video, RGBHV, SD (Y/C and CVBS) video with Input 6 providing a DVI-I input, the ProductionVIEW HD MV supports HD resolutions up to and including 1080p/60fps. The outputs have been configured for analog (YPbPr, RGBHV and SD) and digital (DVI-D) video support allowing for either a standard preview output or multiviewer preview output with support for two monitors or the multiviewer output supporting a Vaddio TeleTouch Touch Screen Control Panel. -

Midterm Test #1 − 10% Ian! D
45 M/C Questions -1- 45 minutes 45 M/C Questions -2- 45 minutes 6. [66/167] If mt is an empty sub-directory,what is true after this: PRINT Name: LAB Section: touch bar ; mkdir foo ; mv bar mt/foo Test Version: ___ One-Answer Multiple Choice 45 Questions − 10 of 10% a. the directory foo nowcontains a file named bar the directory mt nowcontains a file named foo ☞ b. Read all the words of these instructions and both sides (back and front) of all pages. c. the directory mt nowcontains a file named bar ☞ Manage your time. Answer questions you know, first. One Answer per question. d. the command fails because mt/foo is not a directory ☞ Put your Name and Lab on this Question Sheet. Youmay write or drawonthis sheet. e. the directory mt is still empty ☞ Use your full, unabbreviated name on the mark-sense form. Do not abbreviate your name. ☞ Put the three-digit Test Version above into NO. OF QUESTIONS and NO. OF STUDENTS 7. [67/168] What is the output of this in an empty directory: ☞ Fill in the bubbles with pencil only,nopen. Enter your NAME, Test Version, and answers. touch 1 13 .13 2 213 3 30 31 .31 ; echo [13]* ☞ Taip The answer to the last question about reading/doing all these test instructions is: a. 13 b. an error message from echo saying [13]* does not exist c. [13]* 1. [49/169] If file foo contains 8 lines, and file bar contains 9 lines, then how manylines are output on your screen by this: cat bar | echo foo d. -

Uniq Display 15½
Uniq Display 15½ &/(-*4) User manual version 1.0.0 Uniq Monitor contentS INTRODuction ........................................................................................................................18 important notice ..........................................................................................................................................18 PRODuct DeScriPtion ........................................................................................................19 Parts of the display, basic features ...........................................................................................................19 uSing the Device ..................................................................................................................22 remote control ............................................................................................................................................22 Turning On and Off ..............................................................................................................22 Menu ................................................................................................................................23 Working with menus ......................................................................................................24 &/(-*4) Switching the display brightness ............................................................................................24 connecting to a computer and configuration .........................................................................................24 -
Linux and Unix Echo Command Help and Examples
2/23/2017 Linux and Unix echo command help and examples You are here: Help > Linux and Unix Linux and Unix echo command About echo echo syntax echo examples Related commands Linux and Unix main page About echo echo displays a line of text. Overview echo is a fundamental command found in most operating systems that offer a command line. It is frequently used in scripts, batch files, and as part of individual commands; anywhere you may need to insert text. Many command shells such as bash, ksh and csh implement echo as a builtin command. bash is the default command shell in nearly every major Linux distribution, so in this documentation we will look at the behavior, syntax, and options of bash's implementation of echo. echo syntax echo [SHORT‐OPTION]... [STRING]... http://www.computerhope.com/unix/uecho.htm 1/6 2/23/2017 Linux and Unix echo command help and examples echo LONG‐OPTION Options n Do not output a trailing newline. e Enable interpretation of backslash escape sequences (see below for a list of these). E Disable interpretation of backslash escape sequences (this is the default). help Display a help message and exit. Output version information and exit. version If you specify the e option, the following escape sequences are recognized: \\ A literal backslash character ("\"). \a An alert (The BELL character). \b Backspace. \c Produce no further output after this. \e The escape character; equivalent to pressing the escape key. \f A form feed. \n A newline. http://www.computerhope.com/unix/uecho.htm 2/6 2/23/2017 Linux and Unix echo command help and examples \r A carriage return. -

Laboratory Manual
LINUX SHELL PROGRAMMING LAB (4CS4-24) LABORATORY MANUAL FOR IV -SEMESTER COMPUTER SCIENCE& ENGINEERING Linux Shell Programming Lab- 4CS4-24 INTERNAL MARKS: 30 EXTERNAL MARKS: 20 Department of Computer Science and Engineering GLOBAL INSTITUTE OF TECHNOLOGY, JAIPUR Department of Computer Science & Engineering Global Institute of Technology, Jaipur LINUX SHELL PROGRAMMING LAB (4CS4-24) Scheme as per RTU M.M M.M. Subject Exam Sessional/ Total Name of Subject L T P End Code Hrs. Mid M.M. Term Term 4CS4-24 Linux Shell Prog. 2 - - 2 30 20 50 Lab Assessment criteria A. Internal Assessment: 30 In continuous evaluation system of the university, a student is evaluated throughout semester. His/her performance in the lab, attendance, practical knowledge, problem solving skill, written work in practical file and behavior are main criteria to evaluate student performance. Apart from that a lab quiz will be organize to see program programming skill and knowledge about the proposed subject. B. External Assessment: 20 At the end of the semester a lab examination will be scheduled to check overall programming skill, in which student will need to solve 2 programming problems in time span of 3 hours. C. Total Marks: 30+20=50 Department of Computer Science & Engineering Global Institute of Technology, Jaipur LINUX SHELL PROGRAMMING LAB (4CS4-24) SYLLABUS AS PER RTU 1. Use of basic Unix Shell Commands: ls, mkdir, rmdir, cd, cat, banner, touch, file, wc, sort, cut, grep, dd, dfspace, du, ulimit. 2. Commands related to inode, I/O redirection, piping, process control commands, mails. 3. Shell Programming: shell script exercise based on following: a. -

Pash: Light-Touch Data-Parallel Shell Processing
PaSh: Light-touch Data-Parallel Shell Processing Nikos Vasilakis∗ Konstantinos Kallas∗ Konstantinos Mamouras MIT University of Pennsylvania Rice University [email protected] [email protected] [email protected] Achilles Benetopoulos Lazar Cvetković Unaffiliated University of Belgrade [email protected] [email protected] Abstract Parallelizability Parallelizing Runtime Classes §3 Transformations §4.3 Primitives §5 Dataflow This paper presents PaSh, a system for parallelizing POSIX POSIX, GNU §3.1 Regions shell scripts. Given a script, PaSh converts it to a dataflow Annotations §3.2 § 4.1 DFG § 4.4 graph, performs a series of semantics-preserving program §4.2 transformations that expose parallelism, and then converts Seq. Script Par. Script the dataflow graph back into a script—one that adds POSIX constructs to explicitly guide parallelism coupled with PaSh- Fig. 1. PaSh overview. PaSh identifies dataflow regions (§4.1), converts provided Unix-aware runtime primitives for addressing per- them to dataflow graphs (§4.2), applies transformations (§4.3) based onthe parallelizability properties of the commands in these regions (§3.1, §3.2), formance- and correctness-related issues. A lightweight an- and emits a parallel script (§4.4) that uses custom primitives (§5). notation language allows command developers to express key parallelizability properties about their commands. An accompanying parallelizability study of POSIX and GNU • Command developers, responsible for implementing indi- commands—two large and commonly used groups—guides vidual commands such as sort, uniq, and jq. These de- the annotation language and optimized aggregator library velopers usually work in a single programming language, that PaSh uses. PaSh’s extensive evaluation over 44 unmod- leveraging its abstractions to provide parallelism when- ified Unix scripts shows significant speedups (0.89–61.1×, ever possible. -

Gnu Coreutils Core GNU Utilities for Version 6.9, 22 March 2007
gnu Coreutils Core GNU utilities for version 6.9, 22 March 2007 David MacKenzie et al. This manual documents version 6.9 of the gnu core utilities, including the standard pro- grams for text and file manipulation. Copyright c 1994, 1995, 1996, 2000, 2001, 2002, 2003, 2004, 2005, 2006 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, with no Front-Cover Texts, and with no Back-Cover Texts. A copy of the license is included in the section entitled \GNU Free Documentation License". Chapter 1: Introduction 1 1 Introduction This manual is a work in progress: many sections make no attempt to explain basic concepts in a way suitable for novices. Thus, if you are interested, please get involved in improving this manual. The entire gnu community will benefit. The gnu utilities documented here are mostly compatible with the POSIX standard. Please report bugs to [email protected]. Remember to include the version number, machine architecture, input files, and any other information needed to reproduce the bug: your input, what you expected, what you got, and why it is wrong. Diffs are welcome, but please include a description of the problem as well, since this is sometimes difficult to infer. See section \Bugs" in Using and Porting GNU CC. This manual was originally derived from the Unix man pages in the distributions, which were written by David MacKenzie and updated by Jim Meyering. -

Linux-Cheat-Sheet-Sponsored-By-Loggly.Pdf
Linux Command Cheat Sheet Share This Cheat Sheet Basic commands File management File Utilities Memory & Processes | Pipe (redirect) output find search for a file tr -d translate or delete character free -m display free and used system memory sudo [command] run < command> in superuser ls -a -C -h list content of directory uniq -c -u report or omit repeated lines mode killall stop all process by name rm -r -f remove files and directory split -l split file into pieces nohup [command] run < command> immune to sensors CPU temperature hangup signal locate -i find file, using updatedb(8) wc -w print newline, word, and byte database counts for each file top display current processes, real man [command] display help pages of time monitoring < command> cp -a -R -i copy files or directory head -n output the first part of files kill -1 -9 send signal to process [command] & run < command> and send task du -s disk usage cut -s remove section from file to background service manage or run sysV init script file -b -i identify the file type diff -q file compare, line by line [start|stop|restart] >> [fileA] append to fileA, preserving existing contents mv -f -i move files or directory join -i join lines of two files on a ps aux display current processes, common field snapshot > [fileA] output to fileA, overwriting grep, egrep, fgrep -i -v print lines matching pattern contents more, less view file content, one page at a dmesg -k display system messages time echo -n display a line of text sort -n sort lines in text file xargs build command line from File compression previous output -

Interactive Touch Screen User Manual
Interactive Touch Screen User Manual Copyright © 2017 Newline Interactive. All Rights Reserved. Welcome: Thanks for purchasing this product. Please read the instructions carefully before using this product. This device complies with part 15 of the FCC Rules. Operation is subject to the following two conditions: (1) This device may not cause harmful interference, and (2) this device must accept any interference received, including interference that may cause undesired operation. NOTE 1: This equipment has been tested and found to comply with the limits for a Class B digital device, pursuant to part 15 of the FCC Rules. These limits are designed to provide reasonable protection against harmful interference in a residential installation. This equipment generates, uses and radiates radio frequency energy and, if not installed and used in accordance with the instructions, may cause harmful interference to radio communications. However, there is no guarantee that interference will not occur in a particular installation. If this equipment does cause harmful interference to radio or television reception, which can be determined by turning the equipment off and on, the user is encouraged to try to correct the interference by one or more of the following measures: •Reorient or relocate the receiving antenna. •Increase the separation between the equipment and receiver. •Connect the equipment into an outlet on a circuit different from that to which the receiver is connected. •Consult the dealer or an experienced radio/ TV technician for help. NOTE 2: Any changes or modifications to this unit not expressly approved by the party responsible for compliance could void the user’s authority to operate the equipment.