Pash: Light-Touch Data-Parallel Shell Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LS-90 Operation Guide
Communicating Thermostat - TheLS-90 has 2 RTM-1 radio ports. These allow your thermostat to communicate with other systems. Depending on your area Power Company, programs may be available to connect your thermostat to power grid status information. This can make it easy for you to moderate your energy use at peak hours and use power when it is less expensive. The RTM-1 ports also allow you to connect yourLS-90 to your home WiFi network. This can give you access to your home’s HVAC system even when you are away. It can also give you access to web based efficient energy management sites that RTM-1 port can help you save money and protect the environment. Customer support:877-254-5625 or www.LockStateConnect.com PG 20 PG 1 LS-90 Operation Guide top cover The LS-90 programmable communicating Wire thermostat operates via a high-quality, easy- terminals Power Grid Reset to-use touch screen. To program or adjust status button your LS-90, simply touch your finger or the indicators Home stylus firmly to the screen. The screen will button SAVE NORMAL automatically light up and you will hear a ENERGY $0.05 KW H FAN 12:30pm “beep.” The screen will respond differently to 5/25 WED different types of touches, so you may want Control o TARGET bar to experiment with both your finger and with F 77o Save TEMP Power the stylus, which is included with the LS-90, Energy HUMI D button HVAC 23% Button STATUS Power Status Normal $.05/kW to see what works best for you. -

Bash Scripts for Avpres Verify Manifest(1)
verify_manifest(1) Bash Scripts for AVpres verify_manifest(1) NAME verify_manifest - Verify a checksum manifest of a folder or file SYNOPSIS verify_manifest -i input_path [-m manifest_file] verify_manifest -h | -x DESCRIPTION Bash AVpres is a collection of Bash scripts for audio-visual preservation. One of these small programs is verify_manifest.Itcreates a checksum manifest of a folder or file. Bash version 3.2 is required, but we strongly advise to use the current version 5.1. OPTIONS BASIC OPTIONS -i input_path,--input=input_path path to an input folder or file -m manifest_file,--manifest=manifest_file path to the manifest file If this parameter is not passed, then the script uses for a folder: <input_path>_<algorithm>.txt and for a file: <input_path>_<extension>_<algorithm>.txt ADVA NCED OPTIONS The arguments of the advanced options can be overwritten by the user.Please remember that anystring containing spaces must be quoted, or its spaces must be escaped. --algorithm=(xxh32|xxh64|xxh128|md5|sha1|sha256|sha512|crc32) We advise to use a faster non-cryptographic hash functions, because we consider that, for archival purposes, there is no necessity to apply a more complexunkeyed cryptographic hash function. The algorithm name can be passed in upper or lower case letters. The default algorithm is xxHash 128: --algorithm=xxh128 Note that until end of 2020 the default algorithm was MD5, which has the same checksum size than the xxHash 128 algorithm. Therefore, if you verity files with an MD5 checksum, then you may pass the option --algorithm=md5 in order to speed-up the verification. Also xxHash 32 and CRC-32 have the same checksum size. -

Download Instructions—Portal
Download instructions These instructions are recommended to download big files. How to download and verify files from downloads.gvsig.org • H ow to download files • G NU/Linux Systems • MacO S X Systems • Windows Systems • H ow to validate the downloaded files How to download files The files distributed on this site can be downloaded using different access protocols, the ones currently available are FTP, HTTP and RSYNC. The base URL of the site for the different protocols is: • ftp://gvsig.org/ • http://downloads.gvsig.org/ • r sync://gvsig.org/downloads/ To download files using the first two protocols is recommended to use client programs able to resume partial downloads, as it is usual to have transfer interruptions when downloading big files like DVD images. There are multiple free (and multi platform) programs to download files using different protocols (in our case we are interested in FTP and HTTP), from them we can highlight curl (http://curl.haxx.se/) and wget (http://www.gnu.org/software/wget/) from the command line ones and Free Download Manager from the GUI ones (this one is only for Windows systems). The curl program is included in MacOS X and is available for almost all GNU/Linux distributions. It can be downloaded in source code or in binary form for different operating systems from the project web site. The wget program is also included in almost all GNU/Linux distributions and its source code or binaries of the program for different systems can be downloaded from this page. Next we will explain how to download files from the most usual operating systems using the programs referenced earlier: • G NU/Linux Systems • MacO S X Systems • Windows Systems The use of rsync (available from the URL http://samba.org/rsync/) it is left as an exercise for the reader, we will only said that it is advised to use the --partial option to avoid problems when there transfers are interrupted. -

High-Level and Efficient Stream Parallelism on Multi-Core Systems
WSCAD 2017 - XVIII Simp´osio em Sistemas Computacionais de Alto Desempenho High-Level and Efficient Stream Parallelism on Multi-core Systems with SPar for Data Compression Applications Dalvan Griebler1, Renato B. Hoffmann1, Junior Loff1, Marco Danelutto2, Luiz Gustavo Fernandes1 1 Faculty of Informatics (FACIN), Pontifical Catholic University of Rio Grande do Sul (PUCRS), GMAP Research Group, Porto Alegre, Brazil. 2Department of Computer Science, University of Pisa (UNIPI), Pisa, Italy. {dalvan.griebler, renato.hoffmann, junior.loff}@acad.pucrs.br, [email protected], [email protected] Abstract. The stream processing domain is present in several real-world appli- cations that are running on multi-core systems. In this paper, we focus on data compression applications that are an important sub-set of this domain. Our main goal is to assess the programmability and efficiency of domain-specific language called SPar. It was specially designed for expressing stream paral- lelism and it promises higher-level parallelism abstractions without significant performance losses. Therefore, we parallelized Lzip and Bzip2 compressors with SPar and compared with state-of-the-art frameworks. The results revealed that SPar is able to efficiently exploit stream parallelism as well as provide suit- able abstractions with less code intrusion and code re-factoring. 1. Introduction Over the past decade, vendors realized that increasing clock frequency to gain perfor- mance was no longer possible. Companies were then forced to slow the clock frequency and start adding multiple processors to their chips. Since that, software started to rely on parallel programming to increase performance [Sutter 2005]. However, exploiting par- allelism in such multi-core architectures is a challenging task that is still too low-level and complex for application programmers. -
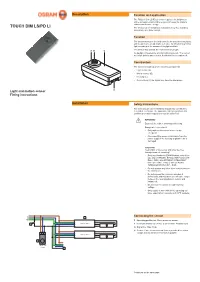
Mounting Instructions OSRAM Sensor Touch DIM LS/PD LI Light And
Description Function and application The TOUCH DIM LS/PD LI sensor regulates the brightness at the workplace and in office areas to increase the working comfort and to save energy. TOUCH DIM LS/PD LI The sensor can be installed in luminaires (e.g. floor standing luminaires) or in false ceilings. Function The sensor measures the brightness in the area to be regulated and keeps this to an adjustable set value by introducing artificial light according to the amount of daylight available. A B C The sensor also detects the movements of people. As daylight increases the artificial light is reduced . The sensor no longer detects any motions, it switches the luminaires off. Construction The sensor is made up of the following components: • Light sensor (A) • Motion sensor (B) • Housing (C) • Connections (D) for signal line, zero line and phase D Light and motion sensor Fitting instructions Installation Safety instructions The sensor must only be installed and put into operation by a qualified electrician. The applicable safety regulations and accident prevention regulations must be observed. WARNING! Exposed, live cables or damaged housing. Danger of electric shock! • Only work on the sensor when it is de- energized. • Disconnect the sensor or luminaire from the power supply if the housing or plastic lens is damaged. CAUTION! Destruction of the sensor and other devices through incorrect mounting! • Only use electronic OSRAM ballast coils of the type QUICKTRONIC INTELLIGENT DALI (QTi DALI…DIM), HALOTRONIC INTELLIGENT DALI (HTi DALI…DIM) or OPTOTRONIC INTELLIGENT DALI (OT…DIM). • Do not operate any other other control units on the control line. -

GNU Coreutils Cheat Sheet (V1.00) Created by Peteris Krumins ([email protected], -- Good Coders Code, Great Coders Reuse)
GNU Coreutils Cheat Sheet (v1.00) Created by Peteris Krumins ([email protected], www.catonmat.net -- good coders code, great coders reuse) Utility Description Utility Description arch Print machine hardware name nproc Print the number of processors base64 Base64 encode/decode strings or files od Dump files in octal and other formats basename Strip directory and suffix from file names paste Merge lines of files cat Concatenate files and print on the standard output pathchk Check whether file names are valid or portable chcon Change SELinux context of file pinky Lightweight finger chgrp Change group ownership of files pr Convert text files for printing chmod Change permission modes of files printenv Print all or part of environment chown Change user and group ownership of files printf Format and print data chroot Run command or shell with special root directory ptx Permuted index for GNU, with keywords in their context cksum Print CRC checksum and byte counts pwd Print current directory comm Compare two sorted files line by line readlink Display value of a symbolic link cp Copy files realpath Print the resolved file name csplit Split a file into context-determined pieces rm Delete files cut Remove parts of lines of files rmdir Remove directories date Print or set the system date and time runcon Run command with specified security context dd Convert a file while copying it seq Print sequence of numbers to standard output df Summarize free disk space setuidgid Run a command with the UID and GID of a specified user dir Briefly list directory -

Addresstranslation Adminguide
Address Translation Administrator Guide This guide is for administrators of MessageLabs Email Services. This guide is for administrators of MessageLabs Email Services. The Address Translation service is a MessageLabs Email Services feature that enables external internet-routable email addresses to be converted into internally-routable addresses, and vice versa. Document version 1.0 2006-12-07 Table of Contents 1 About the guide 3 1.1 Audience and scope 3 1.2 Versions of this guide 3 1.3 Conventions 3 2 Introduction to Address Translation 4 3 Configuring Address Translation 5 3.1 Formatting configuration data 5 3.2 Providing configuration data in CSV files 5 4 Uploading addrtrans.csv 6 4.1 Generating sha1sums (Linux) 6 4.2 Generating sha1sums (Windows) 6 4.3 Uploading CSV files to a Linux server 7 4.4 Uploading CSV files to a Windows server 7 5 Maintaining Address Translation data 8 2 1 About the guide 1.1 Audience and scope This guide is for administrators of MessageLabs Email Services. The Address Translation service is a MessageLabs Email Services feature that enables external internet-routable email addresses to be converted into internally-routable addresses, and vice versa. 1.2 Versions of this guide This guide is available in two page sizes: Letter (279 mm x 215.9 mm) and A4 (297 mm x 210 mm). The version is identified at the end of the file name as _Ltr or _A4. The content is identical in the two versions. Use whichever suits your printing requirements. 1.3 Conventions In this guide, the following conventions are used: Formatting Denotes Bold Button, tab or field Bold Italic Window title or description Note: A note containing extra information that may be useful Text to type in Text to type in Output from a computer Output from a computer Link A link to a website Screenshots normally display an Internet Explorer window. -
Uniq Tablet Ll 12.2” User Manual Version 1.0
Uniq Tablet ll 12.2” User Manual version 1.0 1 This manual was not subject to any language revision. This manual or any part of it may not be copied, reproduced or otherwise distributed without the publisher‘s consent. All rights reserved. Elcom, spoločnosť s ručením obmedzeným, Prešov © ELCOM, spoločnosť s ručením obmedzeným, Prešov, 2017 2 CONTENTS IMPORTANT NOTICES .............................................................................................................04 CONFORMITY DECLARATION .................................................................................................05 KEY LAYOUT AND DEFINITION ...............................................................................................06 USING THE DEVICE ..................................................................................................................07 BEFORE USING THE DEVICE ..................................................................................................10 BEFORE USING THE DEVICE ..................................................................................................10 LOGGING ON TO THE OPERATING SYSTEM ........................................................................10 SWITCHING OFF .......................................................................................................................10 RESTARTING ............................................................................................................................. 11 CONTROLLING ......................................................................................................................... -

Productionview™ Hd Mv
Installation and User Guide PRODUCTIONVIEW™ HD MV High Definition Camera Control Console with Integrated Multiviewer Touch Screen Control, Multi-View Control Panel Layout Options and Expanded I/O Capabilities Part Number 999-5625-000 North America Part Number 999-5625-001 International ©2013 Vaddio - All Rights Reserved ● ProductionVIEW HD MV ● Document Number 342-0241 Rev. F ProductionVIEW HD MV Inside Front Cover - Blank ProductionVIEW HD MV Manual - Document Number 342-0241 Rev F Page 2 of 36 ProductionVIEW HD MV Overview: The Vaddio™ ProductionVIEW HD MV Production Switcher with integrated camera controller and multiviewer is a powerful, cost effective and easy to operate platform for live presentation environments. With Vaddio’s revolutionary TeleTouch™ Touch Screen Control Panel (optional, sold separately), production operators can easily see and switch all live video feeds and create “video thumbnails” of preset camera shots with the touch of their finger. ProductionVIEW HD MV is a broadcast quality, 6x2; multi-format, seamless video mixer that also provides two discrete outputs for dual bus program feeds (two independent 6 x 1 switchers/mixers). ProductionVIEW HD MV Accepting any combination of input signals from Camera Control Console analog HD YPbPr video, RGBHV, SD (Y/C and CVBS) video with Input 6 providing a DVI-I input, the ProductionVIEW HD MV supports HD resolutions up to and including 1080p/60fps. The outputs have been configured for analog (YPbPr, RGBHV and SD) and digital (DVI-D) video support allowing for either a standard preview output or multiviewer preview output with support for two monitors or the multiviewer output supporting a Vaddio TeleTouch Touch Screen Control Panel. -

Parallel Processing.Pptx
Compute Grid: Parallel Processing RCS Lunch & Learn Training Series Bob Freeman, PhD Director, Research Technology Operations HBS 8 November, 2017 Overview • Q&A • Introduction • Serial vs parallel • Approaches to Parallelization • Submitting parallel jobs on the compute grid • Parallel tasks • Parallel Code Serial vs Parallel work Serial vs Multicore Approaches Traditionally, software has been written for serial computers • To be run on a single computer having a single Central Processing Unit (CPU) • Problem is broken into a discrete set of instructions • Instructions are executed one after the other • One one instruction can be executed at any moment in time Serial vs Multicore Approaches In the simplest sense, parallel computing is the simultaneous use of multiple compute resources to solve a computational problem: • To be run using multiple CPUs • A problem is broken into discrete parts (either by you or the application itself) that can be solved concurrently • Each part is further broken down to a series of instructions • Instructions from each part execute simultaneously on different CPUs or different machines Serial vs Multicore Approaches Many different parallelization approaches, which we won't discuss: Shared memory Distributed memory 6 Hybrid Distributed-Shared memory Parallel Processing… So, we are going to briefly touch on two approaches: • Parallel tasks • Tasks in the background • gnu_parallel • Pleasantly parallelizing • Parallel code • Considerations for parallelizing • Parallel frameworks & examples We will not discuss parallelized frameworks such as Hadoop, Apache Spark, MongoDB, ElasticSearch, etc Parallel Jobs on the Compute Grid… Nota Bene!! • In order to run in parallel, programs (code) must be explicitly programmed to do so. • And you must ask the scheduler to reserve those cores for your program/work to use. -

Queue Streaming Model Theory, Algorithms, and Implementation
Mississippi State University Scholars Junction Theses and Dissertations Theses and Dissertations 1-1-2019 Queue Streaming Model Theory, Algorithms, and Implementation Anup D. Zope Follow this and additional works at: https://scholarsjunction.msstate.edu/td Recommended Citation Zope, Anup D., "Queue Streaming Model Theory, Algorithms, and Implementation" (2019). Theses and Dissertations. 3708. https://scholarsjunction.msstate.edu/td/3708 This Dissertation - Open Access is brought to you for free and open access by the Theses and Dissertations at Scholars Junction. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of Scholars Junction. For more information, please contact [email protected]. Queue streaming model: Theory, algorithms, and implementation By Anup D. Zope A Dissertation Submitted to the Faculty of Mississippi State University in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Computational Engineering in the Center for Advanced Vehicular Systems Mississippi State, Mississippi May 2019 Copyright by Anup D. Zope 2019 Queue streaming model: Theory, algorithms, and implementation By Anup D. Zope Approved: Edward A. Luke (Major Professor) Shanti Bhushan (Committee Member) Maxwell Young (Committee Member) J. Mark Janus (Committee Member) Seongjai Kim (Committee Member) Manav Bhatia (Graduate Coordinator) Jason M. Keith Dean Bagley College of Engineering Name: Anup D. Zope Date of Degree: May 3, 2019 Institution: Mississippi State University Major Field: Computational Engineering Major Professor: Edward A. Luke Title of Study: Queue streaming model: Theory, algorithms, and implementation Pages of Study: 195 Candidate for Degree of Doctor of Philosophy In this work, a model of computation for shared memory parallelism is presented. -

GNU Astronomy Utilities
GNU Astronomy Utilities Astronomical data manipulation and analysis programs and libraries for version 0.7, 8 August 2018 Mohammad Akhlaghi Gnuastro (source code, book and webpage) authors (sorted by number of commits): Mohammad Akhlaghi ([email protected], 1101) Mos`eGiordano ([email protected], 29) Vladimir Markelov ([email protected], 18) Boud Roukema ([email protected], 7) Leindert Boogaard ([email protected], 1) Lucas MacQuarrie ([email protected], 1) Th´er`eseGodefroy ([email protected], 1) This book documents version 0.7 of the GNU Astronomy Utilities (Gnuastro). Gnuastro provides various programs and libraries for astronomical data manipulation and analysis. Copyright c 2015-2018 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled \GNU Free Documentation License". For myself, I am interested in science and in philosophy only because I want to learn something about the riddle of the world in which we live, and the riddle of man's knowledge of that world. And I believe that only a revival of interest in these riddles can save the sciences and philosophy from narrow specialization and from an obscurantist faith in the expert's special skill, and in his personal knowledge and authority; a faith that so well fits our `post-rationalist' and `post- critical' age, proudly dedicated to the destruction of the tradition of rational philosophy, and of rational thought itself.