Quality Assessment of Deep-Learning-Based Image Compression Giuseppe Valenzise, Andrei Purica, Vedad Hulusic, Marco Cagnazzo
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Energy-Efficient Design of the Secure Better Portable
Energy-Efficient Design of the Secure Better Portable Graphics Compression Architecture for Trusted Image Communication in the IoT Umar Albalawi Saraju P. Mohanty Elias Kougianos Computer Science and Engineering Computer Science and Engineering Engineering Technology University of North Texas, USA. University of North Texas, USA. University of North Texas. USA. Email: [email protected] Email: [email protected] Email: [email protected] Abstract—Energy consumption has become a major concern it. On the other hand, researchers from the software field in portable applications. This paper proposes an energy-efficient investigate how the software itself and its different uses can design of the Secure Better Portable Graphics Compression influence energy consumption. An efficient software is capable (SBPG) Architecture. The architecture proposed in this paper is suitable for imaging in the Internet of Things (IoT) as the main of adapting to the requirements of everyday usage while saving concentration is on the energy efficiency. The novel contributions as much energy as possible. Software engineers contribute to of this paper are divided into two parts. One is the energy efficient improving energy consumption by designing frameworks and SBPG architecture, which offers encryption and watermarking, tools used in the process of energy metering and profiling [2]. a double layer protection to address most of the issues related to As a specific type of data, images can have a long life if privacy, security and digital rights management. The other novel contribution is the Secure Digital Camera integrated with the stored properly. However, images require a large storage space. SBPG architecture. The combination of these two gives the best The process of storing an image starts with its compression. -

Improved Lossy Image Compression with Priming and Spatially Adaptive Bit Rates for Recurrent Networks
Improved Lossy Image Compression with Priming and Spatially Adaptive Bit Rates for Recurrent Networks Nick Johnston, Damien Vincent, David Minnen, Michele Covell, Saurabh Singh, Troy Chinen, Sung Jin Hwang, Joel Shor, George Toderici {nickj, damienv, dminnen, covell, saurabhsingh, tchinen, sjhwang, joelshor, gtoderici} @google.com, Google Research Abstract formation from the current residual and combines it with context stored in the hidden state of the recurrent layers. By We propose a method for lossy image compression based saving the bits from the quantized bottleneck after each it- on recurrent, convolutional neural networks that outper- eration, the model generates a progressive encoding of the forms BPG (4:2:0), WebP, JPEG2000, and JPEG as mea- input image. sured by MS-SSIM. We introduce three improvements over Our method provides a significant increase in compres- previous research that lead to this state-of-the-art result us- sion performance over previous models due to three im- ing a single model. First, we modify the recurrent architec- provements. First, by “priming” the network, that is, run- ture to improve spatial diffusion, which allows the network ning several iterations before generating the binary codes to more effectively capture and propagate image informa- (in the encoder) or a reconstructed image (in the decoder), tion through the network’s hidden state. Second, in addition we expand the spatial context, which allows the network to lossless entropy coding, we use a spatially adaptive bit to represent more complex representations in early itera- allocation algorithm to more efficiently use the limited num- tions. Second, we add support for spatially adaptive bit rates ber of bits to encode visually complex image regions. -

Comparison of JPEG's Competitors for Document Images
Comparison of JPEG’s competitors for document images Mostafa Darwiche1, The-Anh Pham1 and Mathieu Delalandre1 1 Laboratoire d’Informatique, 64 Avenue Jean Portalis, 37200 Tours, France e-mail: fi[email protected] Abstract— In this work, we carry out a study on the per- in [6] concerns assessing quality of common image formats formance of potential JPEG’s competitors when applied to (e.g., JPEG, TIFF, and PNG) that relies on optical charac- document images. Many novel codecs, such as BPG, Mozjpeg, ter recognition (OCR) errors and peak signal to noise ratio WebP and JPEG-XR, have been recently introduced in order to substitute the standard JPEG. Nonetheless, there is a lack of (PSNR) metric. The authors in [3] compare the performance performance evaluation of these codecs, especially for a particular of different coding methods (JPEG, JPEG 2000, MRC) using category of document images. Therefore, this work makes an traditional PSNR metric applied to several document samples. attempt to provide a detailed and thorough analysis of the Since our target is to provide a study on document images, aforementioned JPEG’s competitors. To this aim, we first provide we then use a large dataset with different image resolutions, a review of the most famous codecs that have been considered as being JPEG replacements. Next, some experiments are performed compress them at very low bit-rate and after that evaluate the to study the behavior of these coding schemes. Finally, we extract output images using OCR accuracy. We also take into account main remarks and conclusions characterizing the performance the PSNR measure to serve as an additional quality metric. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

Forensic Considerations for the High Efficiency Image File Format (HEIF)
Author’s version DOI: 10.1109/CyberSecurity49315.2020.9138890 ©2020 IEEE IEEE International Conference on Cyber Incident Response, Coordination, Containment & Control (Cyber Incident 2020) Forensic Considerations for the High Efficiency Image File Format (HEIF) Sean McKeown Gordon Russell School of Computing School of Computing Edinburgh Napier University Edinburgh Napier University Edinburgh, Scotland Edinburgh, Scotland [email protected] [email protected] Abstract—The High Efficiency File Format (HEIF) was the relatively recent adoption of the High Efficiency Image File adopted by Apple in 2017 as their favoured means of capturing Format (HEIF) by Apple in 2017, beginning with the iPhone 7, images from their camera application, with Android devices such 6th generation iPad, and Mac computers running OS X High as the Galaxy S10 providing support more recently. The format is positioned to replace JPEG as the de facto image compression Sierra (10.13) and above. While claims of higher encoding file type, touting many modern features and better compression efficiency have done little to sway users in the past, Apple’s ratios over the aging standard. However, while millions of devices hardware and software support across millions of devices across the world are already able to produce HEIF files, digital potentially allows the HEIF format to eventually replace JPEG forensics research has not given the format much attention. in mainstream use. Contemporary Apple devices save images As HEIF is a complex container format, much different from traditional still picture formats, this leaves forensics practitioners from the camera directly in the HEIF format by default. This exposed to risks of potentially mishandling evidence. -

Proceedings of The
PROCEEDINGS OF THE IEEE CATALOG NUMBERS USB PART NUMBER: CFP 2139D – USB ISBN: 978 – 1 – 7281 – 1064 - 6 ORGANIZED BY 3XEOLFDWLRQ&RQWDFW $+0=DKLUXO$ODP )DFXOW\RI(QJLQHHULQJ ,QWHUQDWLRQDO,VODPLF8QLYHUVLW\0DOD\VLD -DODQ*RPEDN.XDOD/XPSXU 0DOD\VLD 7HO (PDLO]DKLUXODODP#LLXPHGXP\ ZHEKWWSV]DKLUXODODPVWDIIDWLLXPHGXP\ COPYRIGHT Copyright © 2021 by the Institute of Electrical and Electronics Engineers, Inc. All rights reserved. Copyright and Reprint Permissions: Abstracting is permitted with credit to the source. Libraries are permitted to photocopy beyond the limit of U.S. copyright law for private use of patrons those articles in this volume that carry a code at the bottom of the first page, provided the per copy fee indicated in the code is paid through Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923. For reprint or republication permission, email to IEEE Copyrights Manager at pubspermissions@ ieee.org. All rights reserved. Copyright ©2021 by IEEE. IEEE Catalog Number USB Part Number: CFP2139D-USB ISBN : 978-1-7281-1064-6 Additional Resources IEEE Conference Operations 445 Hoes Lane Pistacaway, NJ 08854-4150 USA Fax: +1 732 981 1769 Email: [email protected] © 2021 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the IEEE. IEEE catalog Number CFP2139D-USB ISBN 978-1-7281-1064-6 Copyright © 2021 by the Institute of Electrical and Electronics Engineers, Inc. All rights reserved. -

High Efficiency Image File Format Implementation
LASSE HEIKKILÄ HIGH EFFICIENCY IMAGE FILE FORMAT IMPLEMENTATION Master of Science thesis Examiner: Prof. Petri Ihantola Examiner and topic approved by the Faculty Council of the Faculty of Computing and Electrical Engineering on 4th of May 2016 i ABSTRACT LASSE HEIKKILÄ: High Efficiency Image File Format implementation Tampere University of Technology Master of Science thesis, 49 pages, 1 Appendix page June 2016 Master’s Degree Programme in Electrical Engineering Technology Major: Embedded systems Examiner: Prof. Petri Ihantola Keywords: High Efficiency Image File Format, HEIF, HEVC During recent years, methods used to encode video have been developing quickly. However, image file formats commonly used for saving still images, such as PNG and JPEG, are originating from the 1990s. Therefore it is often possible to get better image quality and smaller file sizes, when photographs are compressed with modern video compression techniques. The High Efficiency Video Coding (HEVC) standard was finalized in 2013, and in the same year work for utilizing it for still image storage started. The resulting High Efficiency Image File Format (HEIF) standard offers a competitive image data compression ratio, and several other features such as support for image sequences and non-destructive editing. During this thesis work, writer and reader programs for handling HEIF files were developed. Together with an HEVC encoder the writer can create HEIF compliant files. By utilizing the reader and an HEVC decoder, an HEIF player program can then present images from HEIF files without the most detailed knowledge about their low-level structure. To make development work easier, and improve the extensibility and maintainability of the programs, code correctness and simplicity were given special attention. -

IDOL Keyview Filter SDK 12.6 .NET Programming Guide
KeyView Software Version 12.6 Filter SDK .NET Programming Guide Document Release Date: June 2020 Software Release Date: June 2020 Filter SDK .NET Programming Guide Legal notices Copyright notice © Copyright 2016-2020 Micro Focus or one of its affiliates. The only warranties for products and services of Micro Focus and its affiliates and licensors (“Micro Focus”) are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. Micro Focus shall not be liable for technical or editorial errors or omissions contained herein. The information contained herein is subject to change without notice. Documentation updates The title page of this document contains the following identifying information: l Software Version number, which indicates the software version. l Document Release Date, which changes each time the document is updated. l Software Release Date, which indicates the release date of this version of the software. To check for updated documentation, visit https://www.microfocus.com/support-and-services/documentation/. Support Visit the MySupport portal to access contact information and details about the products, services, and support that Micro Focus offers. This portal also provides customer self-solve capabilities. It gives you a fast and efficient way to access interactive technical support tools needed to manage your business. As a valued support customer, you can benefit by using the MySupport portal to: l Search for knowledge documents of interest l Access product documentation l View software vulnerability alerts l Enter into discussions with other software customers l Download software patches l Manage software licenses, downloads, and support contracts l Submit and track service requests l Contact customer support l View information about all services that Support offers Many areas of the portal require you to sign in. -
Improving Inference for Neural Image Compression
Improving Inference for Neural Image Compression Yibo Yang, Robert Bamler, Stephan Mandt Department of Computer Science University of California, Irvine {yibo.yang, rbamler, mandt}@uci.edu Abstract We consider the problem of lossy image compression with deep latent variable models. State-of-the-art methods [Ballé et al., 2018, Minnen et al., 2018, Lee et al., 2019] build on hierarchical variational autoencoders (VAEs) and learn inference networks to predict a compressible latent representation of each data point. Drawing on the variational inference perspective on compression [Alemi et al., 2018], we identify three approximation gaps which limit performance in the conventional approach: an amortization gap, a discretization gap, and a marginalization gap. We propose remedies for each of these three limitations based on ideas related to iterative inference, stochastic annealing for discrete optimization, and bits-back coding, resulting in the first application of bits-back coding to lossy compression. In our experiments, which include extensive baseline comparisons and ablation studies, we achieve new state-of-the-art performance on lossy image compression using an established VAE architecture, by changing only the inference method. 1 Introduction Deep learning methods are reshaping the field of data compression, and recently started to outperform state-of-the-art classical codecs on image compression [Minnen et al., 2018]. Besides useful on its own, image compression is a stepping stone towards better video codecs [Lombardo et al., 2019, Habibian et al., 2019, Yang et al., 2020a], which can reduce a sizable amount of global internet traffic. State-of-the-art neural methods for lossy image compression [Ballé et al., 2018, Minnen et al., 2018, Lee et al., 2019] learn a mapping between images and latent variables with a variational autoencoder (VAE). -

Effective Decompression of JPEG Document Images The-Anh Pham, Mathieu Delalandre
IMAGE PROCESSING, IEEE TRANSACTIONS ON 1 Effective decompression of JPEG document images The-Anh Pham, Mathieu Delalandre Abstract—This work concentrates on developing an effective out for lossless and near lossless compression methods that are approach for decompressing JPEG document images. Our main devoted to document images such as MRC [1], DjVu [2], Digi- goal is targeted to time-critical applications, especially to those Paper [3], and TSMAP/RDOS [4]. Although these attempts situated on mobile network infrastructures. To this aim, the proposed approach is designed to work either in the trans- were shown to outperform the state-of-the-art compression form domain or image spatial plane. Specifically, the image techniques on a particular class of document images, they blocks are first classified into smooth blocks (e.g., background, require new standards for image representation. This constraint uniform regions) and non-smooth blocks (e.g., text, graphics, is not always applicable for many applications, especially for line-drawings). Next, the smooth blocks are fully decoded in those on mobile markets. Mobile users, in practice, prefer to the transform domain by minimizing the total block boundary variation, which is very efficient to compute. For decoding non- keep the existing standards, such as JPEG [5], for the images smooth blocks, a novel text model is presented that accounts being accessed. for the specifics of document content. Additionally, an efficient This work concentrates on improving the visual quality of optimization algorithm is introduced to reconstruct the non- document images compressed by the JPEG standard. At low smooth blocks. The proposed approach has been validated by bit-rate coding, JPEG encoded images are subject to heavy extensive experiments, demonstrating a significant improvement of visual quality, assuming that document images have been distortion of both blocking and ringing artifacts. -

Point Cloud Compression Using Depth Maps
©2016 Society for Imaging Science and Technology DOI: 10.2352/ISSN.2470-1173.2016.21.3DIPM-397 Point Cloud Compression using Depth Maps Arnaud Bletterer1;2, Frédéric Payan1, Marc Antonini1, Anis Meftah2; 1Laboratory I3S - University of Nice - Sophia Antipolis and CNRS (UMR 7271), France; 2Cintoo3D, France Abstract from the camera. Indeed, the image is sampled on a regular lattice, In this paper we investigate the usage of depth maps as a the coordinates fi; jg of the pixel in the image are implicit, and do structure to represent a point cloud. The main idea is that depth not need to be stored. To project points from the map to the 3D maps implicitly define a global manifold structure for the under- space, one matrix is needed for each depth map (16 real numbers). lying surface of a point cloud. Thus, it is possible to only work on Its cost is negligible, in comparison with the map cost. Thus, the parameter domain, and to modify the point cloud indirectly. depth maps are naturally more compact than point clouds, as long 1 3 We show that this approach simplifies local computations on the as 3 of the total number of pixels represent points in R . point cloud and allows using standard image processing algo- Depth maps do not provide only geometric information. rithms to interact with the point cloud. We present results of the They also define a parameterization domain and a segmentation application of standard image compression algorithms applied on related to the different points of view (position and orientation of depth maps to compress a point cloud, and compare them with the system during acquisition). -
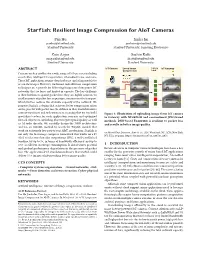
Starfish: Resilient Image Compression for Aiot Cameras
Starfish: Resilient Image Compression for AIoT Cameras Pan Hu Junha Im [email protected] [email protected] Stanford University Stanford University, Samsung Electronics Zain Asgar Sachin Katti [email protected] [email protected] Stanford University Stanford University IoT Camera Lossy Image Lossy IoT Gateway ABSTRACT Compression Link Cameras are key enablers for a wide range of IoT use cases including smart cities, intelligent transportation, AI-enabled farms, and more. These IoT applications require cloud software (including models) to Starfish act on the images. However, traditional task oblivious compression techniques are a poor fit for delivering images over low power IoT networks that are lossy and limited in capacity. The key challenge is their brittleness against packet loss; they are highly sensitive to small amounts of packet loss requiring retransmission for transport, which further reduces the available capacity of the network. We JPEG propose Starfish, a design that achieves better compression ratios and is graceful with packet loss. In addition to that, Starfish features content-awareness and task-awareness, meaning that we can build Figure 1: Illustration of uploading image from IoT camera specialized codecs for each application scenario and optimized to Gateway with Starfish and conventional JPEG-based for task objectives, including objective/perceptual quality as well methods. DNN-based Starfish is resilient to packet loss as AI tasks directly. We carefully design the DNN architecture and results in better image quality. and use an AutoML method to search for TinyML models that work on extremely low power/cost AIoT accelerators. Starfish is on Neural Gaze Detection, June 03–05, 2018, Woodstock, NY.