Using Eidr Language Codes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sign Language Typology Series
SIGN LANGUAGE TYPOLOGY SERIES The Sign Language Typology Series is dedicated to the comparative study of sign languages around the world. Individual or collective works that systematically explore typological variation across sign languages are the focus of this series, with particular emphasis on undocumented, underdescribed and endangered sign languages. The scope of the series primarily includes cross-linguistic studies of grammatical domains across a larger or smaller sample of sign languages, but also encompasses the study of individual sign languages from a typological perspective and comparison between signed and spoken languages in terms of language modality, as well as theoretical and methodological contributions to sign language typology. Interrogative and Negative Constructions in Sign Languages Edited by Ulrike Zeshan Sign Language Typology Series No. 1 / Interrogative and negative constructions in sign languages / Ulrike Zeshan (ed.) / Nijmegen: Ishara Press 2006. ISBN-10: 90-8656-001-6 ISBN-13: 978-90-8656-001-1 © Ishara Press Stichting DEF Wundtlaan 1 6525XD Nijmegen The Netherlands Fax: +31-24-3521213 email: [email protected] http://ishara.def-intl.org Cover design: Sibaji Panda Printed in the Netherlands First published 2006 Catalogue copy of this book available at Depot van Nederlandse Publicaties, Koninklijke Bibliotheek, Den Haag (www.kb.nl/depot) To the deaf pioneers in developing countries who have inspired all my work Contents Preface........................................................................................................10 -

Deaf and in Need : Finding Culturally Sensitive Human Services
California State University, Monterey Bay Digital Commons @ CSUMB Capstone Projects and Master's Theses 2007 Deaf and in need : finding culturally sensitive human services Colleen M. Moore California State University, Monterey Bay Follow this and additional works at: https://digitalcommons.csumb.edu/caps_thes Recommended Citation Moore, Colleen M., "Deaf and in need : finding culturally sensitive human services" (2007). Capstone Projects and Master's Theses. 350. https://digitalcommons.csumb.edu/caps_thes/350 This Capstone Project is brought to you for free and open access by Digital Commons @ CSUMB. It has been accepted for inclusion in Capstone Projects and Master's Theses by an authorized administrator of Digital Commons @ CSUMB. Unless otherwise indicated, this project was conducted as practicum not subject to IRB review but conducted in keeping with applicable regulatory guidance for training purposes. For more information, please contact [email protected]. Deaf and in Need: Finding Culturally Sensitive Human Services © 2007 Colleen M Moore. All Rights Reserved. 1 INTRODUCTION Imagine that you are unable to provide food for your family or must obtain housing, health care, psychiatric services, child care, family planning services or any other human service; you are unable to gain access to these things due to any number of difficult life circumstances. You must go to the local Department of Social and Employment Services (California), apply for aid, surrender private information and face the potential emotional backlash or shame that, for some, accompanies the decision to ask for help. Now imagine that you are a member of a cultural group that uses a language, customs and social mores unknown to most people. -
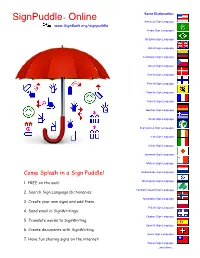
Learn to Use Signpuddle 1.0 on The
Some Dictionaries: ™ SignPuddle Online American Sign Language www.SignBank.org/signpuddle Arabic Sign Languages Brazilian Sign Language British Sign Language Colombian Sign Language Czech Sign Language Danish Sign Language Finnish Sign Language Flemish Sign Language French Sign Language German Sign Language Greek Sign Language International Sign Languages Irish Sign Language Italian Sign Language Japanese Sign Language Maltese Sign Language Come Splash in a Sign Puddle! Netherlands Sign Language 1. FREE on the web! Nicaraguan Sign Language Northern Ireland Sign Language 2. Search Sign Language Dictionaries. Norwegian Sign Language 3. Create your own signs and add them. Polish Sign Language 4. Send email in SignWriting®. Quebec Sign Language 5. Translate words to SignWriting. Spanish Sign Language 6. Create documents with SignWriting. Swiss Sign Languages 7. Have fun sharing signs on the internet! Taiwan Sign Language ...and others... http://www.SignBank.org/signpuddle Search by Words 1. Click on the icon: Search by Words 2. In the Search field: Type a word or a letter. 3. Press the Search button. 4. All the signs that use that word will list for you in SignWriting. 5. You can then copy the sign, or drag and drop it, into other documents. http://www.SignBank.org/signpuddle Search by Signs 1. Click on the icon: Search by Signs 2. In the Search field: Type a word or a letter. 3. Press the Search button. 4. The signs will list in small size. 5. Click on the small sign you want, and a larger version will appear... http://www.SignBank.org/signpuddle Search by Symbols 1. -

Prayer Cards (709)
Pray for the Nations Pray for the Nations A Che in China A'ou in China Population: 43,000 Population: 2,800 World Popl: 43,000 World Popl: 2,800 Total Countries: 1 Total Countries: 1 People Cluster: Tibeto-Burman, other People Cluster: Tai Main Language: Ache Main Language: Chinese, Mandarin Main Religion: Ethnic Religions Main Religion: Ethnic Religions Status: Unreached Status: Unreached Evangelicals: 0.00% Evangelicals: 0.00% Chr Adherents: 0.00% Chr Adherents: 0.00% Scripture: Translation Needed Scripture: Complete Bible www.joshuaproject.net Source: Operation China, Asia Harvest www.joshuaproject.net Source: Operation China, Asia Harvest "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations A-Hmao in China Achang in China Population: 458,000 Population: 35,000 World Popl: 458,000 World Popl: 74,000 Total Countries: 1 Total Countries: 2 People Cluster: Miao / Hmong People Cluster: Tibeto-Burman, other Main Language: Miao, Large Flowery Main Language: Achang Main Religion: Christianity Main Religion: Ethnic Religions Status: Significantly reached Status: Partially reached Evangelicals: 75.0% Evangelicals: 7.0% Chr Adherents: 80.0% Chr Adherents: 7.0% Scripture: Complete Bible Scripture: Complete Bible www.joshuaproject.net www.joshuaproject.net Source: Anonymous Source: Wikipedia "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations Achang, Husa in China Adi -

Critical Inquiry in Language Studies New Directions in ASL-English
This article was downloaded by: [Gallaudet University], [Adam Stone] On: 26 August 2014, At: 09:23 Publisher: Routledge Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK Critical Inquiry in Language Studies Publication details, including instructions for authors and subscription information: http://www.tandfonline.com/loi/hcil20 New Directions in ASL-English Bilingual Ebooks Adam Stonea a Gallaudet University Published online: 22 Aug 2014. To cite this article: Adam Stone (2014) New Directions in ASL-English Bilingual Ebooks, Critical Inquiry in Language Studies, 11:3, 186-206, DOI: 10.1080/15427587.2014.936242 To link to this article: http://dx.doi.org/10.1080/15427587.2014.936242 PLEASE SCROLL DOWN FOR ARTICLE Taylor & Francis makes every effort to ensure the accuracy of all the information (the “Content”) contained in the publications on our platform. However, Taylor & Francis, our agents, and our licensors make no representations or warranties whatsoever as to the accuracy, completeness, or suitability for any purpose of the Content. Any opinions and views expressed in this publication are the opinions and views of the authors, and are not the views of or endorsed by Taylor & Francis. The accuracy of the Content should not be relied upon and should be independently verified with primary sources of information. Taylor and Francis shall not be liable for any losses, actions, claims, proceedings, demands, costs, expenses, damages, and other liabilities whatsoever or howsoever caused arising directly or indirectly in connection with, in relation to or arising out of the use of the Content. -

Orthography of Solomon Birnbaum
iQa;;&u*,"" , I iii The "Orthodox" Orthography of Solomon Birnbaum Kalman Weiser YORK UNIVERSITY Apart from the YIVO Institute's Standard Yiddish Orthography, the prevalent sys tem in the secular sector, two other major spelling codes for Yiddish are current today. Sovetisher oysteyg (Soviet spelling) is encountered chiefly among aging Yid dish speakers from the former Soviet bloc and appears in print with diminishing frequency since the end of the Cold War. In contrast, "maskiIic" spelling, the system haphazardly fashioned by 19th-century proponents of the Jewish Enlightenment (which reflects now obsolete Germanized conventions) continues to thrive in the publications of the expanding hasidic sector. As the one group that has by and large preserved and even encouraged Yiddish as its communal vernacular since the Holocaust, contemporary ultra-Orthodox (and primarily hasidic) Jews regard themselves as the custodians of the language and its traditions. Yiddish is considered a part of the inheritance of their pious East European ancestors, whose way of life they idealize and seek to recreate as much as possible. l The historic irony of this development-namely, the enshrinement of the work of secularized enlighteners, who themselves were bent on modernizing East European Jewry and uprooting Hasidism-is probably lost upon today's tens of thousands of hasidic Yiddish speakers. The irony, however, was not lost on Solomon (in German, Salomo; in Yiddish, Shloyme) Birnbaum (1898-1989), a pioneering Yiddish linguist and Hebrew pa leographer in the ultra-Orthodox sector. This essay examines Birnbaum's own "Or thodox" orthography for Yiddish in both its purely linguistic and broader ideolog ical contexts in interwar Poland, then home to the largest Jewish community in Europe and the world center of Yiddish culture. -

The Signing Space for the Synthesis of Directional Verbs in NGT
The signing space for the synthesis of directional verbs in NGT Shani E. Mende-Gillings Layout: typeset by the author using LATEX. Cover illustration: Unknown artist The signing space for the synthesis of directional verbs in NGT Shani E. Mende-Gillings 11319836 Bachelor thesis Credits: 18 EC Bachelor Kunstmatige Intelligentie University of Amsterdam Faculty of Science Science Park 904 1098 XH Amsterdam Supervisor dr. F. Roelofsen Institute for Logic, Language and Computation Faculty of Science University of Amsterdam Science Park 107 1098 XG Amsterdam 26 June 2020 Acknowledgements I would like to thank my supervisor Floris Roelofsen for his guidance during this project. I am also very grateful to John Glauert and Richard Kennaway for proving valuable insight into SiGML and the JASigning software. Special thanks go to Inge Zwitserlood, Onno Crasborn and Johan Ros for providing the database of encoded NGT signs, without which this project would not have been possible. Last, but not least, I would also like to thank Marijke Scheffener for providing evaluation material and valuable feedback on the program. Preface This paper describes an individual contribution to a larger project executed in close collaboration with [1] and [2]. The first parts of these three papers describe the overall project and were jointly written, making them largely identical. Section 1.2 describes the global research question, and sections 2 and 3 provide the- oretical context and set up a hypothesis. Section 5.1.1 shows the overall program created, including the components of the other projects, and section 5.2.1 evaluates the result. These previously mentioned chap- ters and sections have been written in joint collaboration with [1] and [2] An introduction to and motivation for the overall project are provided in section 1. -

Passenger Information Using a Sign Language Avatar Individual Travel Assistance for Passengers with Special Needs in Public Transport
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Institute of Transport Research:Publications STRATEGIES Travel Assistance Photo: Helmer Photo: Passenger information using a sign language avatar Individual travel assistance for passengers with special needs in public transport Public transport, passenger information, travel assistance, information and communication technology, reduced mobility, accessibility, inclusion Public transport operators are legally obliged to ensure equal access to transportation services. This includes equal access to information and communication related to those services. Deaf passengers mostly prefer to communicate in sign language. For this reason, the specific needs of deaf and hard-of- hearing passengers still are not adequately addressed – despite the tremendous efforts public transport operators have put in providing accessible communication services to their passengers. This article describes a novel approach to passenger information in sign language based on the automatic translation of natural (written) language text into sign language. This includes the use of a sign language avatar to display the information to deaf and hard-of-hearing passengers. Authors: Lars Schnieder, Georg Tschare ublic transport operators provide nature and causes of disruptions [2]. The tion on the Rights of Persons with Disabili- real-time passenger information passenger information system may be used ties oblige all ratifying countries to ensure via electronic information systems both physically within a transportation hub that persons with disabilities have the in order to keep passengers up to as well as remotely via mobile devices used opportunity to live independently and par- Pdate about the current status of the public by the passengers. -

Sign Classification in Sign Language Corpora with Deep Neural Networks
Sign Classification in Sign Language Corpora with Deep Neural Networks Lionel Pigou, Mieke Van Herreweghe, Joni Dambre Ghent University flionel.pigou, mieke.vanherreweghe, [email protected] Abstract Automatic and unconstrained sign language recognition (SLR) in image sequences remains a challenging problem. The variety of signers, backgrounds, sign executions and signer positions makes the development of SLR systems very challenging. Current methods try to alleviate this complexity by extracting engineered features to detect hand shapes, hand trajectories and facial expressions as an intermediate step for SLR. Our goal is to approach SLR based on feature learning rather than feature engineering. We tackle SLR using the recent advances in the domain of deep learning with deep neural networks. The problem is approached by classifying isolated signs from the Corpus VGT (Flemish Sign Language Corpus) and the Corpus NGT (Dutch Sign Language Corpus). Furthermore, we investigate cross-domain feature learning to boost the performance to cope with the fewer Corpus VGT annotations. Keywords: sign language recognition, deep learning, neural networks 1. Introduction In previous work (Pigou et al., 2015), we showed that deep neural networks are very successful for gesture recognition SLR systems have many different use cases: corpus anno- and gesture spotting in spatiotemporal data. Our developed tation, in hospitals, as a personal sign language learning system is able to recognize 20 different Italian gestures (i.e., assistant or translating daily conversations between signers emblems). We achieved a classification accuracy of 97.23% and non-signers to name a few. Unfortunately, unconstrained in the Chalearn 2014 Looking At People gesture spotting SLR remains a big challenge. -

Partitive Article
Book Disentangling bare nouns and nominals introduced by a partitive article IHSANE, Tabea (Ed.) Abstract The volume Disentangling Bare Nouns and Nominals Introduced by a Partitive Article, edited by Tabea Ihsane, focuses on different aspects of the distribution, semantics, and internal structure of nominal constituents with a “partitive article” in its indefinite interpretation and of potentially corresponding bare nouns. It further deals with diachronic issues, such as grammaticalization and evolution in the use of “partitive articles”. The outcome is a snapshot of current research into “partitive articles” and the way they relate to bare nouns, in a cross-linguistic perspective and on new data: the research covers noteworthy data (fieldwork data and corpora) from Standard languages - like French and Italian, but also German - to dialectal and regional varieties, including endangered ones like Francoprovençal. Reference IHSANE, Tabea (Ed.). Disentangling bare nouns and nominals introduced by a partitive article. Leiden ; Boston : Brill, 2020 DOI : 10.1163/9789004437500 Available at: http://archive-ouverte.unige.ch/unige:145202 Disclaimer: layout of this document may differ from the published version. 1 / 1 Disentangling Bare Nouns and Nominals Introduced by a Partitive Article - 978-90-04-43750-0 Downloaded from PubFactory at 10/29/2020 05:18:23PM via Bibliotheque de Geneve, Bibliotheque de Geneve, University of Geneva and Universite de Geneve Syntax & Semantics Series Editor Keir Moulton (University of Toronto, Canada) Editorial Board Judith Aissen (University of California, Santa Cruz) – Peter Culicover (The Ohio State University) – Elisabet Engdahl (University of Gothenburg) – Janet Fodor (City University of New York) – Erhard Hinrichs (University of Tubingen) – Paul M. -
![Adaptations of Hebrew Script -Mala Enciklopedija Prosvetq I978 [Small Prosveta Encyclopedia]](https://docslib.b-cdn.net/cover/2327/adaptations-of-hebrew-script-mala-enciklopedija-prosvetq-i978-small-prosveta-encyclopedia-702327.webp)
Adaptations of Hebrew Script -Mala Enciklopedija Prosvetq I978 [Small Prosveta Encyclopedia]
726 PART X: USE AND ADAPTATION OF SCRIPTS Series Minor 8) The Hague: Mouton SECTION 6I Ly&in, V. I t952. Drevnepermskij jazyk [The Old Pemic language] Moscow: Izdalel'slvo Aka- demii Nauk SSSR ry6r. Komi-russkij sLovar' [Komi-Russian diclionary] Moscow: Gosudarstvennoe Izda- tel'slvo Inostrannyx i Nacional'nyx Slovuej. Adaptations of Hebrew Script -MaLa Enciklopedija Prosvetq I978 [Small Prosveta encycloPedia]. Belgrade. Moll, T. A,, & P. I InEnlikdj t951. Cukotsko-russkij sLovaf [Chukchee-Russian dicrionary] Len- BENJAMIN HARY ingrad: Gosudtrstvemoe udebno-pedagogideskoe izdatel'stvo Ministerstva Prosveldenija RSFSR Poppe, Nicholas. 1963 Tatqr Manual (Indima Universily Publications, Uralic atrd Altaic Series 25) Mouton Bloomington: Indiana University; The Hague: "lagguages" rgjo. Mongolian lnnguage Handbook.Washington, D C.: Center for Applied Linguistics Jewish or ethnolects HerbertH Papet(Intema- Rastorgueva,V.S. 1963.A ShortSketchofTajikGrammar, fans anded It is probably impossible to offer a purely linguistic definition of a Jewish "language," tional Joumal ofAmerican Linguisticr 29, no part 2) Bloominglon: Indiana University; The - 4, as it is difficult to find many cornmon linguistic criteria that can apply to Judeo- Hague: Moulon. (Russiu orig 'Kratkij oderk grammatiki lad;ikskogo jzyka," in M. V. Rax- Arabic, Judeo-Spanish, and Yiddish, for example. Consequently, a sociolinguistic imi & L V Uspenskaja, eds,Tadiikskurusstj slovar' lTajik-Russian dictionary], Moscow: Gosudustvennoe Izdatel'stvo Inostrmyx i Nacional'tryx SIovarej, r954 ) definition with a more suitable term, such as ethnolect, is in order. An ethnolect is an Sjoberg, Andr€e P. t963. Uzbek StructuraL Grammar (Indiana University Publications, Uralic and independent linguistic entity with its own history and development that refers to a lan- Altaic Series r8). -

Prayer Cards | Joshua Project
Pray for the Nations Pray for the Nations Abkhaz in Ukraine Abor in India Population: 1,500 Population: 1,700 World Popl: 307,600 World Popl: 1,700 Total Countries: 6 Total Countries: 1 People Cluster: Caucasus People Cluster: South Asia Tribal - other Main Language: Abkhaz Main Language: Adi Main Religion: Non-Religious Main Religion: Unknown Status: Minimally Reached Status: Minimally Reached Evangelicals: 1.00% Evangelicals: Unknown % Chr Adherents: 20.00% Chr Adherents: 16.36% Scripture: New Testament Scripture: Complete Bible www.joshuaproject.net www.joshuaproject.net Source: Apsuwara - Wikimedia "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations Achuar Jivaro in Ecuador Achuar Jivaro in Peru Population: 7,200 Population: 400 World Popl: 7,600 World Popl: 7,600 Total Countries: 2 Total Countries: 2 People Cluster: South American Indigenous People Cluster: South American Indigenous Main Language: Achuar-Shiwiar Main Language: Achuar-Shiwiar Main Religion: Ethnic Religions Main Religion: Ethnic Religions Status: Minimally Reached Status: Minimally Reached Evangelicals: 1.00% Evangelicals: 2.00% Chr Adherents: 14.00% Chr Adherents: 15.00% Scripture: New Testament Scripture: New Testament www.joshuaproject.net www.joshuaproject.net Source: Gina De Leon Source: Gina De Leon "Declare his glory among the nations." Psalm 96:3 "Declare his glory among the nations." Psalm 96:3 Pray for the Nations Pray for the Nations Adi in India Adi Gallong in India