Co-Clustering Phenome–Genome for Phenotype Classification And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Identification of Differentially Expressed Genes in Human Bladder Cancer Through Genome-Wide Gene Expression Profiling
521-531 24/7/06 18:28 Page 521 ONCOLOGY REPORTS 16: 521-531, 2006 521 Identification of differentially expressed genes in human bladder cancer through genome-wide gene expression profiling KAZUMORI KAWAKAMI1,3, HIDEKI ENOKIDA1, TOKUSHI TACHIWADA1, TAKENARI GOTANDA1, KENGO TSUNEYOSHI1, HIROYUKI KUBO1, KENRYU NISHIYAMA1, MASAKI TAKIGUCHI2, MASAYUKI NAKAGAWA1 and NAOHIKO SEKI3 1Department of Urology, Graduate School of Medical and Dental Sciences, Kagoshima University, 8-35-1 Sakuragaoka, Kagoshima 890-8520; Departments of 2Biochemistry and Genetics, and 3Functional Genomics, Graduate School of Medicine, Chiba University, 1-8-1 Inohana, Chuo-ku, Chiba 260-8670, Japan Received February 15, 2006; Accepted April 27, 2006 Abstract. Large-scale gene expression profiling is an effective CKS2 gene not only as a potential biomarker for diagnosing, strategy for understanding the progression of bladder cancer but also for staging human BC. This is the first report (BC). The aim of this study was to identify genes that are demonstrating that CKS2 expression is strongly correlated expressed differently in the course of BC progression and to with the progression of human BC. establish new biomarkers for BC. Specimens from 21 patients with pathologically confirmed superficial (n=10) or Introduction invasive (n=11) BC and 4 normal bladder samples were studied; samples from 14 of the 21 BC samples were subjected Bladder cancer (BC) is among the 5 most common to microarray analysis. The validity of the microarray results malignancies worldwide, and the 2nd most common tumor of was verified by real-time RT-PCR. Of the 136 up-regulated the genitourinary tract and the 2nd most common cause of genes we detected, 21 were present in all 14 BCs examined death in patients with cancer of the urinary tract (1-7). -

Quantitative SUMO Proteomics Reveals the Modulation of Several
www.nature.com/scientificreports OPEN Quantitative SUMO proteomics reveals the modulation of several PML nuclear body associated Received: 10 October 2017 Accepted: 28 March 2018 proteins and an anti-senescence Published: xx xx xxxx function of UBC9 Francis P. McManus1, Véronique Bourdeau2, Mariana Acevedo2, Stéphane Lopes-Paciencia2, Lian Mignacca2, Frédéric Lamoliatte1,3, John W. Rojas Pino2, Gerardo Ferbeyre2 & Pierre Thibault1,3 Several regulators of SUMOylation have been previously linked to senescence but most targets of this modifcation in senescent cells remain unidentifed. Using a two-step purifcation of a modifed SUMO3, we profled the SUMO proteome of senescent cells in a site-specifc manner. We identifed 25 SUMO sites on 23 proteins that were signifcantly regulated during senescence. Of note, most of these proteins were PML nuclear body (PML-NB) associated, which correlates with the increased number and size of PML-NBs observed in senescent cells. Interestingly, the sole SUMO E2 enzyme, UBC9, was more SUMOylated during senescence on its Lys-49. Functional studies of a UBC9 mutant at Lys-49 showed a decreased association to PML-NBs and the loss of UBC9’s ability to delay senescence. We thus propose both pro- and anti-senescence functions of protein SUMOylation. Many cellular mechanisms of defense have evolved to reduce the onset of tumors and potential cancer develop- ment. One such mechanism is cellular senescence where cells undergo cell cycle arrest in response to various stressors1,2. Multiple triggers for the onset of senescence have been documented. While replicative senescence is primarily caused in response to telomere shortening3,4, senescence can also be triggered early by a number of exogenous factors including DNA damage, elevated levels of reactive oxygen species (ROS), high cytokine signa- ling, and constitutively-active oncogenes (such as H-RAS-G12V)5,6. -

Role and Regulation of the P53-Homolog P73 in the Transformation of Normal Human Fibroblasts
Role and regulation of the p53-homolog p73 in the transformation of normal human fibroblasts Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Bayerischen Julius-Maximilians-Universität Würzburg vorgelegt von Lars Hofmann aus Aschaffenburg Würzburg 2007 Eingereicht am Mitglieder der Promotionskommission: Vorsitzender: Prof. Dr. Dr. Martin J. Müller Gutachter: Prof. Dr. Michael P. Schön Gutachter : Prof. Dr. Georg Krohne Tag des Promotionskolloquiums: Doktorurkunde ausgehändigt am Erklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbständig angefertigt und keine anderen als die angegebenen Hilfsmittel und Quellen verwendet habe. Diese Arbeit wurde weder in gleicher noch in ähnlicher Form in einem anderen Prüfungsverfahren vorgelegt. Ich habe früher, außer den mit dem Zulassungsgesuch urkundlichen Graden, keine weiteren akademischen Grade erworben und zu erwerben gesucht. Würzburg, Lars Hofmann Content SUMMARY ................................................................................................................ IV ZUSAMMENFASSUNG ............................................................................................. V 1. INTRODUCTION ................................................................................................. 1 1.1. Molecular basics of cancer .......................................................................................... 1 1.2. Early research on tumorigenesis ................................................................................. 3 1.3. Developing -

Rabbit Anti-EBP2 /FITC Conjugated Antibody
SunLong Biotech Co.,LTD Tel: 0086-571- 56623320 Fax:0086-571- 56623318 E-mail:[email protected] www.sunlongbiotech.com Rabbit Anti-EBP2 /FITC Conjugated antibody SL14495R-FITC Product Name: Anti-EBP2 /FITC Chinese Name: FITC标记的EB病毒核抗原1Binding protein2抗体 EBNA1-binding protein 2; EBNA1 binding protein 2; ebna1bp2; EBP2; Alias: EBP2_HUMAN; NOBP; nuclear FGF3 binding protein; Nucleolar protein p40; P40; Probable rRNA processing protein EBP2; Probable rRNA-processing protein ebp2. Organism Species: Rabbit Clonality: Polyclonal React Species: Human,Mouse,Rat, ICC=1:50-200IF=1:50-200 Applications: not yet tested in other applications. optimal dilutions/concentrations should be determined by the end user. Molecular weight: 36kDa Form: Lyophilized or Liquid Concentration: 1mg/ml immunogen: KLH conjugated synthetic peptide derived from human EBP2 Lsotype: IgG Purification: affinity purified by Protein A Storage Buffer: 0.01Mwww.sunlongbiotech.com TBS(pH7.4) with 1% BSA, 0.03% Proclin300 and 50% Glycerol. Store at -20 °C for one year. Avoid repeated freeze/thaw cycles. The lyophilized antibody is stable at room temperature for at least one month and for greater than a year Storage: when kept at -20°C. When reconstituted in sterile pH 7.4 0.01M PBS or diluent of antibody the antibody is stable for at least two weeks at 2-4 °C. background: The replication and stable maintenance of latent Epstein-Barr virus DNA episomes in human cells requires only one viral protein, Epstein-Barr nuclear antigen 1 (EBNA1). EBNA1 binding protein 2, also designated p40/EBP2, is a nuclear protein required for Product Detail: the processing of the 27S pre-rRNA. -

A Master Autoantigen-Ome Links Alternative Splicing, Female Predilection, and COVID-19 to Autoimmune Diseases
bioRxiv preprint doi: https://doi.org/10.1101/2021.07.30.454526; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. A Master Autoantigen-ome Links Alternative Splicing, Female Predilection, and COVID-19 to Autoimmune Diseases Julia Y. Wang1*, Michael W. Roehrl1, Victor B. Roehrl1, and Michael H. Roehrl2* 1 Curandis, New York, USA 2 Department of Pathology, Memorial Sloan Kettering Cancer Center, New York, USA * Correspondence: [email protected] or [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2021.07.30.454526; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Abstract Chronic and debilitating autoimmune sequelae pose a grave concern for the post-COVID-19 pandemic era. Based on our discovery that the glycosaminoglycan dermatan sulfate (DS) displays peculiar affinity to apoptotic cells and autoantigens (autoAgs) and that DS-autoAg complexes cooperatively stimulate autoreactive B1 cell responses, we compiled a database of 751 candidate autoAgs from six human cell types. At least 657 of these have been found to be affected by SARS-CoV-2 infection based on currently available multi-omic COVID data, and at least 400 are confirmed targets of autoantibodies in a wide array of autoimmune diseases and cancer. -

Primepcr™Assay Validation Report
PrimePCR™Assay Validation Report Gene Information Gene Name EBNA1 binding protein 2 Gene Symbol EBNA1BP2 Organism Human Gene Summary Description Not Available Gene Aliases EBP2, NOBP, P40 RefSeq Accession No. NC_000001.10, NG_028079.1, NT_032977.9 UniGene ID Hs.346868 Ensembl Gene ID ENSG00000117395 Entrez Gene ID 10969 Assay Information Unique Assay ID qHsaCIP0031375 Assay Type Probe - Validation information is for the primer pair using SYBR® Green detection Detected Coding Transcript(s) ENST00000236051, ENST00000431635 Amplicon Context Sequence CTTTCTGATATTTCTTAATAGCATTCATCATATGGGCTTTCTCCTGCTGCCTCTTC TGAAGAACCTCCGTTTGCACCTTCTTCCCGTATTTCCTAAGTGCTCGCAGTTGCT TAGCT Amplicon Length (bp) 86 Chromosome Location 1:43632831-43634649 Assay Design Intron-spanning Purification Desalted Validation Results Efficiency (%) 97 R2 0.9997 cDNA Cq 19.17 cDNA Tm (Celsius) 81.5 gDNA Cq Specificity (%) 100 Information to assist with data interpretation is provided at the end of this report. Page 1/4 PrimePCR™Assay Validation Report EBNA1BP2, Human Amplification Plot Amplification of cDNA generated from 25 ng of universal reference RNA Melt Peak Melt curve analysis of above amplification Standard Curve Standard curve generated using 20 million copies of template diluted 10-fold to 20 copies Page 2/4 PrimePCR™Assay Validation Report Products used to generate validation data Real-Time PCR Instrument CFX384 Real-Time PCR Detection System Reverse Transcription Reagent iScript™ Advanced cDNA Synthesis Kit for RT-qPCR Real-Time PCR Supermix SsoAdvanced™ SYBR® Green Supermix Experimental Sample qPCR Human Reference Total RNA Data Interpretation Unique Assay ID This is a unique identifier that can be used to identify the assay in the literature and online. Detected Coding Transcript(s) This is a list of the Ensembl transcript ID(s) that this assay will detect. -

Supplementary Table 1
Supplementary Table 1. 492 genes are unique to 0 h post-heat timepoint. The name, p-value, fold change, location and family of each gene are indicated. Genes were filtered for an absolute value log2 ration 1.5 and a significance value of p ≤ 0.05. Symbol p-value Log Gene Name Location Family Ratio ABCA13 1.87E-02 3.292 ATP-binding cassette, sub-family unknown transporter A (ABC1), member 13 ABCB1 1.93E-02 −1.819 ATP-binding cassette, sub-family Plasma transporter B (MDR/TAP), member 1 Membrane ABCC3 2.83E-02 2.016 ATP-binding cassette, sub-family Plasma transporter C (CFTR/MRP), member 3 Membrane ABHD6 7.79E-03 −2.717 abhydrolase domain containing 6 Cytoplasm enzyme ACAT1 4.10E-02 3.009 acetyl-CoA acetyltransferase 1 Cytoplasm enzyme ACBD4 2.66E-03 1.722 acyl-CoA binding domain unknown other containing 4 ACSL5 1.86E-02 −2.876 acyl-CoA synthetase long-chain Cytoplasm enzyme family member 5 ADAM23 3.33E-02 −3.008 ADAM metallopeptidase domain Plasma peptidase 23 Membrane ADAM29 5.58E-03 3.463 ADAM metallopeptidase domain Plasma peptidase 29 Membrane ADAMTS17 2.67E-04 3.051 ADAM metallopeptidase with Extracellular other thrombospondin type 1 motif, 17 Space ADCYAP1R1 1.20E-02 1.848 adenylate cyclase activating Plasma G-protein polypeptide 1 (pituitary) receptor Membrane coupled type I receptor ADH6 (includes 4.02E-02 −1.845 alcohol dehydrogenase 6 (class Cytoplasm enzyme EG:130) V) AHSA2 1.54E-04 −1.6 AHA1, activator of heat shock unknown other 90kDa protein ATPase homolog 2 (yeast) AK5 3.32E-02 1.658 adenylate kinase 5 Cytoplasm kinase AK7 -
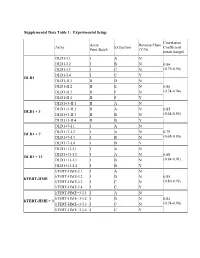
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

Download 20190410); Fragmentation for 20 S
ARTICLE https://doi.org/10.1038/s41467-020-17387-y OPEN Multi-layered proteomic analyses decode compositional and functional effects of cancer mutations on kinase complexes ✉ Martin Mehnert 1 , Rodolfo Ciuffa1, Fabian Frommelt 1, Federico Uliana1, Audrey van Drogen1, ✉ ✉ Kilian Ruminski1,3, Matthias Gstaiger1 & Ruedi Aebersold 1,2 fi 1234567890():,; Rapidly increasing availability of genomic data and ensuing identi cation of disease asso- ciated mutations allows for an unbiased insight into genetic drivers of disease development. However, determination of molecular mechanisms by which individual genomic changes affect biochemical processes remains a major challenge. Here, we develop a multilayered proteomic workflow to explore how genetic lesions modulate the proteome and are trans- lated into molecular phenotypes. Using this workflow we determine how expression of a panel of disease-associated mutations in the Dyrk2 protein kinase alter the composition, topology and activity of this kinase complex as well as the phosphoproteomic state of the cell. The data show that altered protein-protein interactions caused by the mutations are asso- ciated with topological changes and affected phosphorylation of known cancer driver pro- teins, thus linking Dyrk2 mutations with cancer-related biochemical processes. Overall, we discover multiple mutation-specific functionally relevant changes, thus highlighting the extensive plasticity of molecular responses to genetic lesions. 1 Department of Biology, Institute of Molecular Systems Biology, ETH Zurich, -

New Insights on Human Essential Genes Based on Integrated Multi
bioRxiv preprint doi: https://doi.org/10.1101/260224; this version posted February 5, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. New insights on human essential genes based on integrated multi- omics analysis Hebing Chen1,2, Zhuo Zhang1,2, Shuai Jiang 1,2, Ruijiang Li1, Wanying Li1, Hao Li1,* and Xiaochen Bo1,* 1Beijing Institute of Radiation Medicine, Beijing 100850, China. 2 Co-first author *Correspondence: [email protected]; [email protected] Abstract Essential genes are those whose functions govern critical processes that sustain life in the organism. Comprehensive understanding of human essential genes could enable breakthroughs in biology and medicine. Recently, there has been a rapid proliferation of technologies for identifying and investigating the functions of human essential genes. Here, according to gene essentiality, we present a global analysis for comprehensively and systematically elucidating the genetic and regulatory characteristics of human essential genes. We explain why these genes are essential from the genomic, epigenomic, and proteomic perspectives, and we discuss their evolutionary and embryonic developmental properties. Importantly, we find that essential human genes can be used as markers to guide cancer treatment. We have developed an interactive web server, the Human Essential Genes Interactive Analysis Platform (HEGIAP) (http://sysomics.com/HEGIAP/), which integrates abundant analytical tools to give a global, multidimensional interpretation of gene essentiality. bioRxiv preprint doi: https://doi.org/10.1101/260224; this version posted February 5, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. -

Network-Based Method for Drug Target Discovery at the Isoform Level
www.nature.com/scientificreports OPEN Network-based method for drug target discovery at the isoform level Received: 20 November 2018 Jun Ma1,2, Jenny Wang2, Laleh Soltan Ghoraie2, Xin Men3, Linna Liu4 & Penggao Dai 1 Accepted: 6 September 2019 Identifcation of primary targets associated with phenotypes can facilitate exploration of the underlying Published: xx xx xxxx molecular mechanisms of compounds and optimization of the structures of promising drugs. However, the literature reports limited efort to identify the target major isoform of a single known target gene. The majority of genes generate multiple transcripts that are translated into proteins that may carry out distinct and even opposing biological functions through alternative splicing. In addition, isoform expression is dynamic and varies depending on the developmental stage and cell type. To identify target major isoforms, we integrated a breast cancer type-specifc isoform coexpression network with gene perturbation signatures in the MCF7 cell line in the Connectivity Map database using the ‘shortest path’ drug target prioritization method. We used a leukemia cancer network and diferential expression data for drugs in the HL-60 cell line to test the robustness of the detection algorithm for target major isoforms. We further analyzed the properties of target major isoforms for each multi-isoform gene using pharmacogenomic datasets, proteomic data and the principal isoforms defned by the APPRIS and STRING datasets. Then, we tested our predictions for the most promising target major protein isoforms of DNMT1, MGEA5 and P4HB4 based on expression data and topological features in the coexpression network. Interestingly, these isoforms are not annotated as principal isoforms in APPRIS. -

Defining the Genetic Basis of Three Hereditary Neurological Conditions in Families from the Indian Subcontinent
RETA LILA WESTON INSTITUTE OF NEUROLOGICAL STUDIES INSTITUTE OF NEUROLOGY UNIVERSITY COLLEGE LONDON DEFINING THE GENETIC BASIS OF THREE HEREDITARY NEUROLOGICAL CONDITIONS IN FAMILIES FROM THE INDIAN SUBCONTINENT Dr Vafa Alakbarzade PhD Thesis 2016 1 DEFINING THE GENETIC BASIS OF THREE HEREDITARY NEUROLOGICAL CONDITIONS IN FAMILIES FROM THE INDIAN SUBCONTINENT Submitted by Dr Vafa Alakbarzade, MBBS, MRCP (UK), MSc University College London Student Number: 1028294 to University College London as a thesis for the degree of Doctor of Philosophy, January 2016 This thesis is available for Library use on the understanding that it is copyright material and that no quotation from the thesis may be published without proper acknowledgement I confirm that the work presented in this thesis is my own and information derived from other sources has been indicated in the thesis (Signature) …………………………………………………… 2 ACKNOWLEDGEMENTS Foremost I would like to thank the families who took part in these studies. I am sincerely grateful to Professor Tom Warner and Professor Andrew Crosby, without whom I would never have had all the wonderful experiences this PhD brought me. They have always supported and encouraged me in whatever scientific endeavours I have followed. Dr. Barry Chioza and Dr. Sreekantan-Nair Ajith provided invaluable support and advice throughout my PhD; I am hugely appreciative of their guidance and encouragement. None of the work in this thesis would have been possible without guidance of Dr. Barry Chioza. I would specifically like to appreciate contribution of the team of Prof. David Silver and Dr. Kulkarni Abhijit who provided functional follow up of our genetic findings and Dr.