Quantum Probes for Minimum Length Estimation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Quantum Mechanics
Quantum Mechanics Richard Fitzpatrick Professor of Physics The University of Texas at Austin Contents 1 Introduction 5 1.1 Intendedaudience................................ 5 1.2 MajorSources .................................. 5 1.3 AimofCourse .................................. 6 1.4 OutlineofCourse ................................ 6 2 Probability Theory 7 2.1 Introduction ................................... 7 2.2 WhatisProbability?.............................. 7 2.3 CombiningProbabilities. ... 7 2.4 Mean,Variance,andStandardDeviation . ..... 9 2.5 ContinuousProbabilityDistributions. ........ 11 3 Wave-Particle Duality 13 3.1 Introduction ................................... 13 3.2 Wavefunctions.................................. 13 3.3 PlaneWaves ................................... 14 3.4 RepresentationofWavesviaComplexFunctions . ....... 15 3.5 ClassicalLightWaves ............................. 18 3.6 PhotoelectricEffect ............................. 19 3.7 QuantumTheoryofLight. .. .. .. .. .. .. .. .. .. .. .. .. .. 21 3.8 ClassicalInterferenceofLightWaves . ...... 21 3.9 QuantumInterferenceofLight . 22 3.10 ClassicalParticles . .. .. .. .. .. .. .. .. .. .. .. .. .. .. 25 3.11 QuantumParticles............................... 25 3.12 WavePackets .................................. 26 2 QUANTUM MECHANICS 3.13 EvolutionofWavePackets . 29 3.14 Heisenberg’sUncertaintyPrinciple . ........ 32 3.15 Schr¨odinger’sEquation . 35 3.16 CollapseoftheWaveFunction . 36 4 Fundamentals of Quantum Mechanics 39 4.1 Introduction .................................. -

Electric Polarizability in the Three Dimensional Problem and the Solution of an Inhomogeneous Differential Equation
Electric polarizability in the three dimensional problem and the solution of an inhomogeneous differential equation M. A. Maizea) and J. J. Smetankab) Department of Physics, Saint Vincent College, Latrobe, PA 15650 USA In previous publications, we illustrated the effectiveness of the method of the inhomogeneous differential equation in calculating the electric polarizability in the one-dimensional problem. In this paper, we extend our effort to apply the method to the three-dimensional problem. We calculate the energy shift of a quantum level using second-order perturbation theory. The energy shift is then used to calculate the electric polarizability due to the interaction between a static electric field and a charged particle moving under the influence of a spherical delta potential. No explicit use of the continuum states is necessary to derive our results. I. INTRODUCTION In previous work1-3, we employed the simple and elegant method of the inhomogeneous differential equation4 to calculate the energy shift of a quantum level in second-order perturbation theory. The energy shift was a result of an interaction between an applied static electric field and a charged particle moving under the influence of a one-dimensional bound 1 potential. The electric polarizability, , was obtained using the basic relationship ∆퐸 = 휖2 0 2 with ∆퐸0 being the energy shift and is the magnitude of the applied electric field. The method of the inhomogeneous differential equation devised by Dalgarno and Lewis4 and discussed by Schwartz5 can be used in a large variety of problems as a clever replacement for conventional perturbation methods. As we learn in our introductory courses in quantum mechanics, calculating the energy shift in second-order perturbation using conventional methods involves a sum (which can be infinite) or an integral that contains all possible states allowed by the transition. -

Revisiting Double Dirac Delta Potential
Revisiting double Dirac delta potential Zafar Ahmed1, Sachin Kumar2, Mayank Sharma3, Vibhu Sharma3;4 1Nuclear Physics Division, Bhabha Atomic Research Centre, Mumbai 400085, India 2Theoretical Physics Division, Bhabha Atomic Research Centre, Mumbai 400085, India 3;4Amity Institute of Applied Sciences, Amity University, Noida, UP, 201313, India∗ (Dated: June 14, 2016) Abstract We study a general double Dirac delta potential to show that this is the simplest yet versatile solvable potential to introduce double wells, avoided crossings, resonances and perfect transmission (T = 1). Perfect transmission energies turn out to be the critical property of symmetric and anti- symmetric cases wherein these discrete energies are found to correspond to the eigenvalues of Dirac delta potential placed symmetrically between two rigid walls. For well(s) or barrier(s), perfect transmission [or zero reflectivity, R(E)] at energy E = 0 is non-intuitive. However, earlier this has been found and called \threshold anomaly". Here we show that it is a critical phenomenon and we can have 0 ≤ R(0) < 1 when the parameters of the double delta potential satisfy an interesting condition. We also invoke zero-energy and zero curvature eigenstate ( (x) = Ax + B) of delta well between two symmetric rigid walls for R(0) = 0. We resolve that the resonant energies and the perfect transmission energies are different and they arise differently. arXiv:1603.07726v4 [quant-ph] 13 Jun 2016 ∗Electronic address: 1:[email protected], 2: [email protected], 3: [email protected], 4:[email protected] 1 I. INTRODUCTION The general one-dimensional Double Dirac Delta Potential (DDDP) is written as [see Fig. -
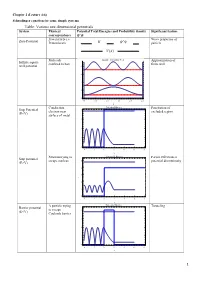
Table: Various One Dimensional Potentials System Physical Potential Total Energies and Probability Density Significant Feature Correspondence Free Particle I.E
Chapter 2 (Lecture 4-6) Schrodinger equation for some simple systems Table: Various one dimensional potentials System Physical Potential Total Energies and Probability density Significant feature correspondence Free particle i.e. Wave properties of Zero Potential Proton beam particle Molecule Infinite Potential Well Approximation of Infinite square confined to box finite well well potential 8 6 4 2 0 0.0 0.5 1.0 1.5 2.0 2.5 x Conduction Potential Barrier Penetration of Step Potential 4 electron near excluded region (E<V) surface of metal 3 2 1 0 4 2 0 2 4 6 8 x Neutron trying to Potential Barrier Partial reflection at Step potential escape nucleus 5 potential discontinuity (E>V) 4 3 2 1 0 4 2 0 2 4 6 8 x Α particle trying Potential Barrier Tunneling Barrier potential to escape 4 (E<V) Coulomb barrier 3 2 1 0 4 2 0 2 4 6 8 x 1 Electron Potential Barrier No reflection at Barrier potential 5 scattering from certain energies (E>V) negatively 4 ionized atom 3 2 1 0 4 2 0 2 4 6 8 x Neutron bound in Finite Potential Well Energy quantization Finite square well the nucleus potential 4 3 2 1 0 2 0 2 4 6 x Aromatic Degenerate quantum Particle in a ring compounds states contains atomic rings. Model the Quantization of energy Particle in a nucleus with a and degeneracy of spherical well potential which is or states zero inside the V=0 nuclear radius and infinite outside that radius. -

LESSON PLAN B.Sc
DEPARTMENT OF PHYSICS AND NANOTECHNOLOGY LESSON PLAN B.Sc. – THIRD YEAR (2015-2016 REGULATION) FIFTH SEMESTER . SRM UNIVERSITY FACULTY OF SCIENCE AND HUMANITIES SRM NAGAR, KATTANKULATHUR – 603 203 SRM UNIVERSITY FACULTY OF SCIENCE AND HUMANITIES DEPARTMENT OF PHYSICS AND NANOTECHNOLOGY Third Year B.Sc Physics (2015-2016 Regulation) Course Code: UPY15501 Course Title: Quantum Mechanics Semester: V Course Time: JUL 2016 – DEC 2017 Location: S.R.M. UNIVERSITY OBJECTIVES 1. To understand the dual nature of matter wave. 2. To apply the Schrodinger equation to different potential. 3. To understand the Heisenberg Uncertainty Relation and its application. 4. To emphasize the significance of Harmonic Oscillator Potential and Hydrogen atom. Assessment Details: Cycle Test – I : 10 Marks Cycle Test – II : 10 Marks Model Exam : 20 Marks Assignments : 5 Marks Attendance : 5 Marks SRM UNIVERSITY FACULTY OF SCIENCE AND HUMANITIES DEPARTMENT OF PHYSICS AND NANOTECHNOLOGY Third Year B.Sc Physics (2015-2016 Regulation) Total Course Semester Course Title L T P of C Code LTP II UPY15501 QUANTUM MECHANICS 4 1 - 5 4 UNIT I - WAVE NATURE OF MATTER Inadequacy of classical mechanics - Black body radiation - Quantum theory – Photo electric effect -Compton effect -Wave nature of matter-Expressions for de-Broglie wavelength - Davisson and Germer's experiment - G.P. Thomson experiment - Phase and group velocity and relation between them - Wave packet - Heisenberg's uncertainity principle – Its consequences (free electron cannot reside inside the nucleus and gamma ray microscope). UNIT II - QUANTUM POSTULATES Basic postulates of quantum mechanics - Schrodinger's equation - Time Independent -Time Dependant - Properties of wave function - Operator formalism – Energy - Momentum and Hamiltonian Operators - Interpretation of Wave Function - Probability Density and Probability - Conditions for Physical Acceptability of Wave Function -. -

Piecewise Potentials II
Physics 342 Lecture 13 Piecewise Potentials II Lecture 13 Physics 342 Quantum Mechanics I Monday, February 25th, 2008 We have seen a few different types of behavior for the stationary states of piecewise potentials { we can have oscillatory solutions on one or both sides of a potential discontinuity, we can also have growing and decaying exponentials. In general, we will select between the oscillatory and decaying exponential by choosing an energy scale for the stationary state. Our final pass at this subject will begin with a finite step, where we set up some matrix machinery to avoid the tedious algebra that accompanies boundary matching. Aside from the result, the important observation is that the matrix form we develop is independent of the potential, so that we can apply this type of approach to any potential, provided it does not extend to infinity. Remember the process we are going through over and over (and over): Given a potential, find the stationary states, use those to form the general solution to Schr¨odinger'sequation by appending the appropriate temporal factor −i E t (e ~ ), and exploit completeness to decompose some initial ¯(x) waveform. In practice, as should be evident from our studies so far, this program is sensible but difficult. The initial distribution of choice, a Gaussian, has unwieldy decomposition in bases other than ei k x (the natural, Fourier set) { is there another/easier way to get a basic idea of what an initial Gaussian distribution does when evolved in time under the influence of a potential? Yes, and we discuss the simplest possible numerical solution at the end. -

Chapter 4 Time–Independent Schrödinger Equation
Chapter 4 Time{Independent Schr¨odinger Equation 4.1 Stationary States We consider again the time dependent Schr¨odingerequation (Prop. 2.1) @ 2 i (t; x) = − ~ ∆ + V (x) (t; x) = H (t; x) ; (4.1) ~ @t 2m where the potential in the Hamiltonian is assumed to be time independent V = V (x). We calculate the solutions of this equation by using the method of separation of variables, i.e. we make the following ansatz for the solution (t; x): (t; x) = (x) f(t) (4.2) and insert it into the time dependent Schr¨odingerequation, Eq. (4.1), @ f(t) 2 @2 (x) 1 i (x) = − ~ f(t) + V (x) (x)f(t) j · ~ @t 2m @x2 (x) f(t) 1 df(t) 2 1 d2 (x) i = − ~ + V (x) : (4.3) ~ f(t) dt 2m (x) dx2 Since now the left hand side in Eq. (4.3) is only dependent on t and the right hand side only on x, both sides must be equal to a constant, which we will call E, and we can thus solve each side independently. The left side yields 1 df(t) df i i~ = E ) = − E dt f(t) dt f ~ i ) ln(f) = − E t + const. ) f = const. e−i E t =~ : (4.4) ~ The constant in Eq. (4.4) will later on be absorbed into (x). 69 70 CHAPTER 4. TIME{INDEPENDENT SCHRODINGER¨ EQUATION Then multiplying the right side of Eq. (4.3) with (x) we get 2 1 d2 (x) 2 d2 (x) − ~ + V (x) = E ) − ~ + V (x) (x) = E (x) : (4.5) 2m (x) dx2 2m dx2 | {z } H (x) The operators on the left express the Hamiltonian H acting on (x), which represents the time independent Schr¨odingerequation. -

Quantum Mechanics Exercises Notes
Quantum Mechanics Exercises Notes Elijan Mastnak Winter Semester 2020-2021 About These Notes These are my notes from the Exercises portion of the class Kvanta Mehanika (Quantum Mechanics), a required course for third-year physics students at the Faculty of Math and Physics in Ljubljana, Slovenia. The exact problem sets herein are specific to the physics program at the University of Ljubljana, but the content is fairly standard for a late- undergraduate quantum mechanics course. I am making the notes publically available in the hope that they might help others learning similar material|the most recent version can be found on GitHub. Navigation: For easier document navigation, the table of contents is \clickable", meaning you can jump directly to a section by clicking the colored section names in the table of contents. Unfortunately, the clickable links do not work in most online or mobile PDF viewers; you have to download the file first. On Authorship: The exercises are led by Asst. Prof. TomaˇzRejec, who has assembled the problem sets and guides us through the solutions. Accordingly, credit for the problems in these notes goes to Prof. Rejec. I have merely typeset the problems and provided an additional explanation or two where I saw fit. Disclaimer: Mistakes|both trivial typos and legitimate errors|are likely. Keep in mind that these are the notes of an undergraduate student in the process of learning the material himself|take what you read with a grain of salt. If you find mistakes and feel like telling me, by Github pull request, email or some other means, I'll be happy to hear from you, even for the most trivial of errors. -

The Finite Spherical Well Analog of 1-1-DD Finite Potential Well
Quantum Mechanics and Atomic Physics Lecture 15: Angular momentum and Central Potentials http: //www.p hys ics.rutgers.e du /ugra d/361 Prof. Sean Oh Last time S. E. in 3D and in spherical coordinates For a mass μ moving in a central potential V( r) Solutions separated into angular and radial parts Rewrite this in terms of angular momentum of the system Angular Solutions Magnetic quantum number Associated Legendre functions Orbital angular quantum number Spherical harmonic functions Space Quantization The maggqnetic quantum number mll exppqresses the quantization of direction of L So L can assume only certain angles, given above, with respect to the zz--axis.axis. This is called space quantization. Example For a particle with l=2, what are the possible angels that L can make with the z -axis? Plot of Spherical harmonics “3D” plots of: 2 θ is measured from thihe +z axis Independent of φ So rotationally symmetric around zz--axisaxis These man ifest themselves as the ppyrobability distributions Summary: Quantization of L, Lz and space Reed: Chapter 6 Radial Solutions To find radial solutions: This is called the radial equation Solving the radial equation Note: Let’s introduce the auxiliary function: And plug it in above The Total Wavefunction The total wavefunction We will soon define n to be the quantum number that dictates the quantization of energy First let’s solve this for two simple cases Infinite and finite spherical wells Spher ica l ana logs o f par tic le in a box Interest in nuclear physics: nuclei modeled -

Particle in an Infinite Potential Well
PARTICLE IN AN INFINITE POTENTIAL WELL CYL100 2013{14 September 2013 We will now look at the solutions of a particle of mass m confined to move along the x-axis between 0 to L. This is achieved by making the potential 0 between x = 0 and x = L and V = 1 for x < 0 and x > L (see Figure 1). In quantum mechanics this model is referred to as particle in a box (PIB) of length L. Figure 1: The one-dimensional infinite potential well of length L. It is divided into three regions, with regions I and III having V = 1 and region II having V = 0 Before we set up and solve the Schr¨odingerequation let us apply de Broglie's approach to this problem. de Broglie associates a wave with every material particle traveling with momentum p. The wavelength of the wave is h λ = : dB p The classical analog of a particle in a box is a string that is fixed at both ends. When such a string is plucked, we know that the amplitude of the oscillations at the fixed ends is zero. In other words, an integer number of half-wavelengths must fit in the length of the box. Applying this idea to the present case, we find that λ h n dB = n = L n = 1; 2; ··· 2 2p Solving for p we get nh p = 2L The particle feels no potential energy so all its energy is in the form of kinetic energy. As a result p2 E = : 2m Substituting for p, we get n2h2 E = n = 1; 2; ··· n 8mL2 Let us now proceed to analyze this problem quantum mechanically. -
3. Some One-Dimensional Potentials This “Tillegg” Is a Supplement to Sections 3.1, 3.3 and 3.5 in Hemmer’S Book
TFY4215/FY1006 | Tillegg 3 1 TILLEGG 3 3. Some one-dimensional potentials This \Tillegg" is a supplement to sections 3.1, 3.3 and 3.5 in Hemmer's book. Sections marked with *** are not part of the introductory courses (FY1006 and TFY4215). 3.1 General properties of energy eigenfunctions (Hemmer 3.1, B&J 3.6) For a particle moving in a one-dimensional potential V (x), the energy eigenfunctions are the acceptable solutions of the time-independent Schr¨odingerequation Hc = E : h¯2 @2 ! d2 2m − + V (x) = E ; or = [V (x) − E] : (T3.1) 2m @x2 dx2 h¯2 3.1.a Energy eigenfunctions can be chosen real Locally, this second-order differential equation has two independent solutions. Since V (x) and E both are real, we can notice that if a solution (x) (with energy E) of this equation is complex, then both the real and the imaginary parts of this solution, 1 1 <e[ (x)] = [ (x) + ∗(x)] and =m[ (x)] = [ (x) − ∗(x)]; 2 2i will satisfy (T3.1), for the energy E. This means that we can choose to work with two independent real solutions, if we wish (instead of the complex solutions (x) and ∗(x)). An example: For a free particle (V (x) = 0), 1 p (x) = eikx; with k = 2mE h¯ is a solution with energy E. But then also ∗(x) = exp(−ikx) is a solution with the same energy. If we wish, we can therefore choose to work with the real and imaginary parts of (x), which are respectively cos kx and sin kx, cf particle in a box. -

PHY202 – Quantum Mechanics Summary of Topic 4: the Finite Potential Well
PHY202 { Quantum Mechanics Summary of Topic 4: The Finite Potential Well The quantum well In a sandwich of two semiconductors, e.g. AlGaAs-GaAs, in the conduction zone one can have an effective potential well. When V0 is very large, we have the limit of the infinite potential well. Otherwise we have a finite potential well. The Finite Potential Well A particle in the potential 8 L V0 x < − 2 < L L V (x) = 0 − 2 ≤ x ≤ 2 : L V0 x > 2 When E > V0: unbound states, total energy E is continuous (not quantized). When E < V0 { bound states. Find them by solving the TISE: • −L=2 < x < L=2 (Region I): 00 2 2 2mE (x) = −k (x), where k = 2 > 0. A general solution is I (x) = A sin kx + B cos kx ~ (A; B { arbitrary constants). • x > L=2 (Region II): 00 2 2 2m(V0−E) −αx αx (x) = α (x), where α = 2 > 0. A general solution is II (x) = Ce + De ~ (C; D { arbitrary constants). Must put D = 0, otherwise (x) not square integrable (blows up at large +ve x). L • x < − 2 (Region III): −αx αx like in region II. A general solution is III (x) = F e + Ge Must put F = 0, otherwise (x) not square integrable (blows up at large -ve x). Note in regions II and III, total E = PE + KE = V0 + KE, but E < V0 hence KE < 0! The potential is symmetric w.r.t. to x = 0 ) expect symmetric (even-parity) and antisym- metric (odd-parity) states Even parity solutions Consider even-parity solutions only: I (x) = B cos kx.