Opinion Extraction and Summarization on the Web Minqing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Presentation
Preprint, 18th Conference on Numerical Weather Prediction American Meteorological Society, Park City, UT 1B.4 Analysis and Prediction of 8 May 2003 Oklahoma City Tornadic Thunderstorm and Embedded Tornado using ARPS with Assimilation of WSR-88D Radar Data Ming Hu1 and Ming Xue1,2* 1Center for Analysis and Prediction of Storms, University of Oklahoma 2School of Meteorology, University of Oklahoma Kalman filter (EnKF) data assimilation, (Snyder 1. Introduction * and Zhang 2003; Wicker and Dowell 2004; Zhang et al. 2004; Tong and Xue 2005; Xue et al. 2006). As a powerful tool in meteorological research Although both 4DVAR and EnKF demonstrate and weather forecast, numerical simulation was great advantages in the radar data assimilation for used by many researchers in the past three storms, their high computational cost hampers decays to study the tornado and tornadogenesis. their application in the operation and with a large Trough 2-dimensional axisymemetric vortex domain. models and three-dimensional asymmetric vortex Another efficient way to assimilate multiple models (Rotunno 1984; Lewellen 1993; Lewellen radar volume scans is to employ intermittent et al. 2000), the dynamics of the vortex flow near assimilation cycles with fast analysis methods, the tornado core were studied under the such as using ARPS (Advanced Regional environment that guarantees tornado formation. Prediction System, Xue et al. 1995; 2000; 2001) To include the effect of tornado parent three dimensional variational (3DVAR) analysis mesocyclone and study the tornado formation and (Gao et al. 2002; 2004) to analyze the radar evolution, different fully three-dimensional models radial velocity data and other conventional data with moist physics and turbulence were used by and the ARPS complex cloud analysis to retrieve Grasso and Cotton (Grasso and Cotton 1995) and thermodynamic and microphysical fields from the Wicker and Wilhelmson (Wicker and Wilhelmson reflectivity according to semi-empirical rules 1995) to simulate tornado vortices produced in a (Zhang et al. -

Curriculum Vitae
CHAO GUO School of Social Policy and Practice Phone: (215) 898-5532 University of Pennsylvania Fax: (215) 573-2099 3701 Locust Walk Email: [email protected] Philadelphia, PA 19104-6214 Web: http://www.drchaoguo.net Education Ph.D., Public Administration, 2003 University of Southern California (Advisor: Terry L. Cooper) B.A., International Relations, 1993 Renmin University of China Recent Awards and Honors Best Conference Paper Award, Association for Research on Nonprofit Organizations and Voluntary Action, Washington DC, 2016. Nonresident Senior Fellow, Fox Leadership International, University of Pennsylvania, 2015- present. Penn Fellow, University of Pennsylvania, 2015-present. Best Conference Paper Award, Association for Research on Nonprofit Organizations and Voluntary Action, Denver, 2014. Finalist, Indiana Public Service Award, Indiana Chapter of the American Society for Public Administration, 2013. Top Research Paper Award, Public Relations Division, National Communication Association, Orlando, 2012. Recognition for greatly contributing to the career development of the University of Georgia (UGA) students. Given by the UGA Career Center. 2011. The Inaugural IDEA Award (Research Promise), Entrepreneurship Division, Academy of Management, Anaheim, 2008. David Stevenson Faculty Fellowship, Nonprofit Academic Centers Council, 2005-2006. Kellogg Scholar Award, Association for Research on Nonprofit Organizations and Voluntary Action’s 32nd Annual Conference, Denver, 2003. Chao Guo Emerging Scholar Award, Association for Research on Nonprofit Organizations and Voluntary Action’s 30th Annual Conference, Miami, 2001. Dean’s Merit Scholarship, School of Policy, Planning and Development, University of Southern California, 1995-2000. Outstanding Leadership Award, Office of International Services, University of Southern California, 1997. Academic Experience Associate Professor, School of Social Policy and Practice, University of Pennsylvania, 2013- present. -

A Study of Modality System in Chinese-English Legal Translation from the Perspective of SFG*
ISSN 1799-2591 Theory and Practice in Language Studies, Vol. 4, No. 3, pp. 497-503, March 2014 © 2014 ACADEMY PUBLISHER Manufactured in Finland. doi:10.4304/tpls.4.3.497-503 A Study of Modality System in Chinese-English Legal Translation from the Perspective of SFG* Zhangjun Lian School of Foreign Languages, Southwest University, Chongqing, China Ting Jiang School of Foreign Languages, Chongqing University, Chongqing, China Abstract—As a special genre, legislative discourse reflects the power of a state through the usage of unusual forms of expressions in choosing words and making sentences. Based on the theory of modality in Systemic Functional Grammar (SFG) and the theory of legislative language in forensic linguistics, this study is designed to analyze the modality system in English translation of Chinese legislative discourses in its attempt to explore its translation problems. Through qualitative and quantitative analyses with the aid of Parallel Corpus of China’s Legal Documents, it is found that there are three prominent anomic features in English translation of modality system in Chinese legislative discourses. These features reveal that translators of Chinese legislative discourse pursue language diversity at the cost of accuracy and authority of the law. A summary of some tactics and suggestions are also presented to deal with the translation of modality system in Chinese legislative discourses from Chinese into English. Index Terms— modality system, Chinese legislative discourses, Systemic Functional Grammar (SFG) I. INTRODUCTION Translation of Chinese laws and regulations is an important component of international exchange of Chinese legal culture. Based on the theoretical ideas of functional linguistics, translation is not only a pure interlingual conversion activity, but, more important, “a communicative process which takes place within a social context” (Hatim & Mason, 2002, p. -

General Pre-‐Departure Information
LIU GLOBAL • CHINA CENTER 4.14.16 GENERAL PRE-DEPARTURE INFORMATION VISA 1. If you have not applied for your Chinese visa, please do so ASAP. 2. Please refer to Important Visa Information document to check the visa application details. BUY AIR TICKETS LIU Global students are encouraged to book air tickets well in advance of their departure. We recommend that students traveling to China for the first time fly directly into Hangzhou Xiaoshan International Airport (HGH) on a domestic or international flight, although this may not be the least expensive options. Students with sufficient international travel experience may also fly directly to the Shanghai Pudong International Airport (PVG) or Shanghai Hongqiao International Airport (SHA) and arrange other transportation to Hangzhou by train or bus. For students arriving in China independently, there are several cities in China that have international connections with the United States and European countries, including Beijing, Shanghai and Hong Kong. Hangzhou Xiaoshan International Airport (HGH) has international connections to Hong Kong, Tokyo, Osaka, Seoul, Bangkok and Singapore. ITEMS TO BRING AND NOT TO BRING REQUESTED SUGGESTED DO NOT ² Passport ü Prescription Medications × Illicit narcotic and ² Valid Chinese Visa (All ü Laptop psychotropic drugs students are required to ü Feminine Hygiene Products × Pornographic material of arrange a student visa ü Non-Prescription Drugs you typically any kind prior to departure for use to control cold, flu, cough, × Religious or political China) allergies, and indigestion, such as material ² A valid Health Insurance aspirin and ibuprofen, Tums, × Cold cuts or fresh fruit Policy Robitussin ü Research books ü Dictionaries ü Winter coat CONTACT INFO 1. -

Social Mobility in China, 1645-2012: a Surname Study Yu (Max) Hao and Gregory Clark, University of California, Davis [email protected], [email protected] 11/6/2012
Social Mobility in China, 1645-2012: A Surname Study Yu (Max) Hao and Gregory Clark, University of California, Davis [email protected], [email protected] 11/6/2012 The dragon begets dragon, the phoenix begets phoenix, and the son of the rat digs holes in the ground (traditional saying). This paper estimates the rate of intergenerational social mobility in Late Imperial, Republican and Communist China by examining the changing social status of originally elite surnames over time. It finds much lower rates of mobility in all eras than previous studies have suggested, though there is some increase in mobility in the Republican and Communist eras. But even in the Communist era social mobility rates are much lower than are conventionally estimated for China, Scandinavia, the UK or USA. These findings are consistent with the hypotheses of Campbell and Lee (2011) of the importance of kin networks in the intergenerational transmission of status. But we argue more likely it reflects mainly a systematic tendency of standard mobility studies to overestimate rates of social mobility. This paper estimates intergenerational social mobility rates in China across three eras: the Late Imperial Era, 1644-1911, the Republican Era, 1912-49 and the Communist Era, 1949-2012. Was the economic stagnation of the late Qing era associated with low intergenerational mobility rates? Did the short lived Republic achieve greater social mobility after the demise of the centuries long Imperial exam system, and the creation of modern Westernized education? The exam system was abolished in 1905, just before the advent of the Republic. Exam titles brought high status, but taking the traditional exams required huge investment in a form of “human capital” that was unsuitable to modern growth (Yuchtman 2010). -

The Case of Wang Wei (Ca
_full_journalsubtitle: International Journal of Chinese Studies/Revue Internationale de Sinologie _full_abbrevjournaltitle: TPAO _full_ppubnumber: ISSN 0082-5433 (print version) _full_epubnumber: ISSN 1568-5322 (online version) _full_issue: 5-6_full_issuetitle: 0 _full_alt_author_running_head (neem stramien J2 voor dit article en vul alleen 0 in hierna): Sufeng Xu _full_alt_articletitle_deel (kopregel rechts, hier invullen): The Courtesan as Famous Scholar _full_is_advance_article: 0 _full_article_language: en indien anders: engelse articletitle: 0 _full_alt_articletitle_toc: 0 T’OUNG PAO The Courtesan as Famous Scholar T’oung Pao 105 (2019) 587-630 www.brill.com/tpao 587 The Courtesan as Famous Scholar: The Case of Wang Wei (ca. 1598-ca. 1647) Sufeng Xu University of Ottawa Recent scholarship has paid special attention to late Ming courtesans as a social and cultural phenomenon. Scholars have rediscovered the many roles that courtesans played and recognized their significance in the creation of a unique cultural atmosphere in the late Ming literati world.1 However, there has been a tendency to situate the flourishing of late Ming courtesan culture within the mainstream Confucian tradition, assuming that “the late Ming courtesan” continued to be “integral to the operation of the civil-service examination, the process that re- produced the empire’s political and cultural elites,” as was the case in earlier dynasties, such as the Tang.2 This assumption has suggested a division between the world of the Chinese courtesan whose primary clientele continued to be constituted by scholar-officials until the eight- eenth century and that of her Japanese counterpart whose rise in the mid- seventeenth century was due to the decline of elitist samurai- 1) For important studies on late Ming high courtesan culture, see Kang-i Sun Chang, The Late Ming Poet Ch’en Tzu-lung: Crises of Love and Loyalism (New Haven: Yale Univ. -

China's Newsmakers
China’s Newsmakers: How Media Power is Shifting in the Xi Jinping Era Supplemental Appendix December 21, 2015 Contents A Appendix: Volume of Content by Provincial Newspaper 2 B Appendix: Individual Newsmakers 4 C Appendix: Organizational Newsmakers 7 D Appendix: Entity Count Share Hu Jintao vs. Xi Jinping 10 E Appendix: Media Power Relative to Politburo Standing Committee 12 1 A Appendix: Volume of Content by Provincial Newspa- per 2 Figure 1: Number of Articles Per Day by Newspaper Beijing Chongqing Fujian Gansu 500 500 500 500 400 400 400 400 300 300 300 300 Count Articles Count Articles Count Articles Count Articles 200 200 200 200 100 100 100 100 0 0 0 0 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 Date (2006 − 2015) Date (2006 − 2015) Date (2006 − 2015) Date (2006 − 2015) Guangdong Guangxi Hainan Heilongjiang 500 500 500 500 400 400 400 400 300 300 300 300 Count Articles Count Articles Count Articles Count Articles 200 200 200 200 100 100 100 100 0 0 0 0 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 Date (2006 − 2015) Date (2006 − 2015) Date (2006 − 2015) Date (2006 − 2015) Henan Hubei Hunan Jiangxi 500 500 500 500 400 400 400 400 300 300 300 300 Count Articles Count Articles Count Articles Count Articles 200 200 200 200 100 100 100 100 0 0 0 0 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 2006 2008 2010 2012 2014 Date (2006 − 2015) Date (2006 − 2015) Date (2006 − 2015) Date (2006 − 2015) Jilin -

Yuan Zeng Postdoctoral Researcher Dept. of Bioagricultural Sciences
Yuan Zeng Postdoctoral Researcher Dept. of Bioagricultural Sciences and Pest Management 307 University Ave, Colorado State University, Fort Collins, CO 80523-1177 Email: [email protected], Cell: (334)332-8386 Education and Training Colorado State University Plant Pathology 2017-present Auburn University Entomology/Microbiology PhD in 2017 Auburn University Probability and Statistics M.S. in 2017 Auburn University Forest Health M.S. in 2012 Beijing Forestry University Forest Resources Conservation and Recreation B.S. in 2008 Beijing Forestry University Computer Science B.S. minor in 2007 Professional Appointments August 2017-Present Postdoctoral researcher, Dept. of Bioagricultural Sciences and Pest Management, Colorado State University May 2017-August 2017 Entomologist/Biologist II, Infectious Diseases & Outbreaks Division, Alabama Department of Public Health May 2012-May 2017 Graduate Research Assistant, Dept. of Entomology and Plant Pathology, Auburn University (AU) August 2009-May 2012 Graduate Research Assistant, School of Forestry and Wildlife Sciences, AU August 2006-August 2008 Undergraduate Research Assistant, College of Forestry, Beijing Forestry University, China Peer-Reviewed Journal Publications since 2016 1. Zeng, Y., Cordova, A.M., Charkowski, A.O., and Fulladolsa, A.C. Evaluation of chemical soil treatment on the incidence of powdery scab and Potato mop-top virus in potato. (in preparation, submit in August) 2. Zeng, Y., Abdo, Z., Charkowski, A.O., Stewart, J.E., Frost, K. 2019. Responses of bacterial and fungal community structure to different rates of 1,3-dichloropropene fumigation. Phytobiomes Journal. https://doi.org/10.1094/PBIOMES-11-18-0055-R. 3. Zeng, Y., Fulladolsa, A.C., Houser, A., and Charkowski, A.O. 2019. -

Origin Narratives: Reading and Reverence in Late-Ming China
Origin Narratives: Reading and Reverence in Late-Ming China Noga Ganany Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2018 © 2018 Noga Ganany All rights reserved ABSTRACT Origin Narratives: Reading and Reverence in Late Ming China Noga Ganany In this dissertation, I examine a genre of commercially-published, illustrated hagiographical books. Recounting the life stories of some of China’s most beloved cultural icons, from Confucius to Guanyin, I term these hagiographical books “origin narratives” (chushen zhuan 出身傳). Weaving a plethora of legends and ritual traditions into the new “vernacular” xiaoshuo format, origin narratives offered comprehensive portrayals of gods, sages, and immortals in narrative form, and were marketed to a general, lay readership. Their narratives were often accompanied by additional materials (or “paratexts”), such as worship manuals, advertisements for temples, and messages from the gods themselves, that reveal the intimate connection of these books to contemporaneous cultic reverence of their protagonists. The content and composition of origin narratives reflect the extensive range of possibilities of late-Ming xiaoshuo narrative writing, challenging our understanding of reading. I argue that origin narratives functioned as entertaining and informative encyclopedic sourcebooks that consolidated all knowledge about their protagonists, from their hagiographies to their ritual traditions. Origin narratives also alert us to the hagiographical substrate in late-imperial literature and religious practice, wherein widely-revered figures played multiple roles in the culture. The reverence of these cultural icons was constructed through the relationship between what I call the Three Ps: their personas (and life stories), the practices surrounding their lore, and the places associated with them (or “sacred geographies”). -
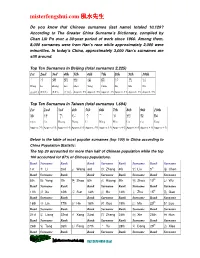
Misterfengshui.Com 風水先生
misterfengshui.com 風水先生 Do you know that Chinese surnames (last name) totaled 10,129? According to The Greater China Surname’s Dictionary, compiled by Chan Lik Pu over a 30-year period of work since 1960. Among them, 8,000 surnames were from Han’s race while approximately 2,000 were minorities. In today’s China, approximately 3,000 Han’s surnames are still around. Top Ten Surnames In Beijing (total surnames 2,225) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 王 李 張 劉 趙 楊 陳 徐 馬 吳 Wang Li Zhang Liu Zhao Yang Chen Xu Ma Wu (10.6% ) (9.6%) (9.6%) (7.7% ) Approx. 5% Approx. 5% Approx. 4% Approx. 4% Approx. 4% Approx. 3% Top Ten Surnames In Taiwan (total surnames 1,694) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 陳 林 黃 張 李 王 吳 劉 蔡 楊 Chen Lin Huang Zhang Li Wang Wux. Liu Cai Yang Approx .7% Approx 6 % Approx 6 % Approx 6 % Approx. 5% Approx 5 % Approx 4 % Approx 4 % Approx 4 % Approx 4 % Below is the table of most popular surnames (top 100) in China according to China Population Statistic: The top 20 accounted for more than half of Chinese population while the top 100 accounted for 87% of Chinese populations. Rank Surname Rank Rank Surname Rank Surname Rank Surname 1st 李 Li 2nd 王 Wang 3rd 張 Zhang 4th 劉 Liu 5th 陳 Chen Rank Surname Rank Rank Surname Rank Surname Rank Surname 6th 楊 Yang 7th 趙 Zhao 8th 黃 Huang 9th 周 Zhou 10 th 吳 Wu Rank Surname Rank Rank Surname Rank Surname Rank Surname 11th 徐 Xu 12th 孫 Sun 13th 胡 Hu 14th 朱 Zhu 15 th 高 Gao Rank Surname Rank Rank Surname Rank Surname Rank Surname 16th 林 Lin 17th 何 He 18th 郭 Guo 19th 馬 Ma 20 th 羅 Luo Rank -

Names of Chinese People in Singapore
101 Lodz Papers in Pragmatics 7.1 (2011): 101-133 DOI: 10.2478/v10016-011-0005-6 Lee Cher Leng Department of Chinese Studies, National University of Singapore ETHNOGRAPHY OF SINGAPORE CHINESE NAMES: RACE, RELIGION, AND REPRESENTATION Abstract Singapore Chinese is part of the Chinese Diaspora.This research shows how Singapore Chinese names reflect the Chinese naming tradition of surnames and generation names, as well as Straits Chinese influence. The names also reflect the beliefs and religion of Singapore Chinese. More significantly, a change of identity and representation is reflected in the names of earlier settlers and Singapore Chinese today. This paper aims to show the general naming traditions of Chinese in Singapore as well as a change in ideology and trends due to globalization. Keywords Singapore, Chinese, names, identity, beliefs, globalization. 1. Introduction When parents choose a name for a child, the name necessarily reflects their thoughts and aspirations with regards to the child. These thoughts and aspirations are shaped by the historical, social, cultural or spiritual setting of the time and place they are living in whether or not they are aware of them. Thus, the study of names is an important window through which one could view how these parents prefer their children to be perceived by society at large, according to the identities, roles, values, hierarchies or expectations constructed within a social space. Goodenough explains this culturally driven context of names and naming practices: Department of Chinese Studies, National University of Singapore The Shaw Foundation Building, Block AS7, Level 5 5 Arts Link, Singapore 117570 e-mail: [email protected] 102 Lee Cher Leng Ethnography of Singapore Chinese Names: Race, Religion, and Representation Different naming and address customs necessarily select different things about the self for communication and consequent emphasis. -

Chinese Hereditary Mathematician Families of the Astronomical Bureau, 1620-1850
City University of New York (CUNY) CUNY Academic Works All Dissertations, Theses, and Capstone Projects Dissertations, Theses, and Capstone Projects 2-2015 Chinese Hereditary Mathematician Families of the Astronomical Bureau, 1620-1850 Ping-Ying Chang Graduate Center, City University of New York How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gc_etds/538 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] CHINESE HEREDITARY MATHEMATICIAN FAMILIES OF THE ASTRONOMICAL BUREAU, 1620–1850 by PING-YING CHANG A dissertation submitted to the Graduate Faculty in History in partial fulfillment of the requirements for the degree of Doctor of Philosophy, The City University of New York 2015 ii © 2015 PING-YING CHANG All Rights Reserved iii This manuscript has been read and accepted for the Graduate Faculty in History in satisfaction of the dissertation requirement for the degree of Doctor of Philosophy. Professor Joseph W. Dauben ________________________ _______________________________________________ Date Chair of Examining Committee Professor Helena Rosenblatt ________________________ _______________________________________________ Date Executive Officer Professor Richard Lufrano Professor David Gordon Professor Wann-Sheng Horng Supervisory Committee THE CITY UNIVERSITY OF NEW YORK iv Abstract CHINESE HEREDITARY MATHEMATICIAN FAMILIES OF THE ASTRONOMICAL BUREAU, 1620–1850 by Ping-Ying Chang Adviser: Professor Joseph W. Dauben This dissertation presents a research that relied on the online Archive of the Grand Secretariat at the Institute of History of Philology of the Academia Sinica in Taiwan and many digitized archival materials to reconstruct the hereditary mathematician families of the Astronomical Bureau in Qing China.