Identification of Latent Oncogenes with a Network Embedding Method and Random Forest
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microgenomics of Ameloblastoma
RESEARCH REPORTS Biological P. DeVilliers1, C. Suggs2, D. Simmons2, V. Murrah3, and J.T. Wright2* Microgenomics of 1Department of Pathology, University of Alabama at Ameloblastoma Birmingham; 2Department of Pediatric Dentistry, CB #7450, and 3Department of Oral Pathology, University of North Carolina at Chapel Hill, NC 27599, USA; *corresponding author, [email protected] J Dent Res 90(4):463-469, 2011 ABSTRACT INTRODUCTION Gene expression profiles of human ameloblastoma microdissected cells were characterized with the meloblastoma is an aggressive tumor of odontogenic epithelial origin, purpose of identifying genes and their protein Awith devastating morbidity if left untreated, due to its unlimited growth products that could be targeted as diagnostic and potential. It is characterized by a high rate of recurrence (up to 70%, depend- prognostic markers as well as for potential thera- ing on the treatment modality) and potential to undergo malignant transfor- peutic interventions. Five formalin-fixed, decalci- mation and to metastasize (up to 2% of cases). Malignant ameloblastoma is fied, paraffin-embedded samples of ameloblastoma defined as a histologically benign-appearing ameloblastoma with metastasis were subjected to laser capture microdissection, (Goldenberg et al., 2004; Cardoso et al., 2009). Surgical resection is the treat- linear mRNA amplification, and hybridization to ment of choice, which can cause further morbidity to the craniofacial com- oligonucleotide human 41,000 RNA arrays and plex, with loss of function and esthetics (Olasoji and Enwere, 2003). compared with universal human reference RNA, Gene expression profiling of tumor cell populations has advanced our to determine the gene expression signature. understanding of the pathogenesis of human tumors (Naderi et al., 2004). -

(12) Patent Application Publication (10) Pub. No.: US 2006/0088532 A1 Alitalo Et Al
US 20060O88532A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2006/0088532 A1 Alitalo et al. (43) Pub. Date: Apr. 27, 2006 (54) LYMPHATIC AND BLOOD ENDOTHELIAL Related U.S. Application Data CELL GENES (60) Provisional application No. 60/363,019, filed on Mar. (76) Inventors: Kari Alitalo, Helsinki (FI); Taija 7, 2002. Makinen, Helsinki (FI); Tatiana Petrova, Helsinki (FI); Pipsa Publication Classification Saharinen, Helsinki (FI); Juha Saharinen, Helsinki (FI) (51) Int. Cl. A6IR 48/00 (2006.01) Correspondence Address: A 6LX 39/395 (2006.01) MARSHALL, GERSTEIN & BORUN LLP A6II 38/18 (2006.01) 233 S. WACKER DRIVE, SUITE 6300 (52) U.S. Cl. .............................. 424/145.1: 514/2: 514/44 SEARS TOWER (57) ABSTRACT CHICAGO, IL 60606 (US) The invention provides polynucleotides and genes that are (21) Appl. No.: 10/505,928 differentially expressed in lymphatic versus blood vascular endothelial cells. These genes are useful for treating diseases (22) PCT Filed: Mar. 7, 2003 involving lymphatic vessels, such as lymphedema, various inflammatory diseases, and cancer metastasis via the lym (86). PCT No.: PCT/USO3FO6900 phatic system. Patent Application Publication Apr. 27, 2006 Sheet 1 of 2 US 2006/0088532 A1 integrin O9 integrin O1 KIAAO711 KAAO644 ApoD Fig. 1 Patent Application Publication Apr. 27, 2006 Sheet 2 of 2 US 2006/0088532 A1 CN g uueleo-gº US 2006/0O88532 A1 Apr. 27, 2006 LYMPHATIC AND BLOOD ENDOTHELLAL CELL lymphatic vessels, such as lymphangiomas or lymphang GENES iectasis. Witte, et al., Regulation of Angiogenesis (eds. Goldber, I. D. & Rosen, E. M.) 65-112 (Birkauser, Basel, BACKGROUND OF THE INVENTION Switzerland, 1997). -

Genomic Sequence Analysis of a Potential QTL Region for Fat Trait on Pig Chromosome 6I
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Genomics 87 (2006) 218 – 224 www.elsevier.com/locate/ygeno Genomic sequence analysis of a potential QTL region for fat trait on pig chromosome 6i Kyung-Tai Lee a,b,1, Eung-Woo Park a,1, Sunjin Moon c,1, Hye-Sook Park a, Hyung-Yong Kim a, Gil-Won Jang a, Bong-Hwan Choi a, H.Y. Chung a, Ji-Woong Lee a, Il-Cheong Cheong a, Sung-Jong Oh a, Heebal Kim c, Dong-Sang Suh b, Tae-Hun Kim a,* a Division of Animal Genomics and Bioinformatics, National Livestock Research Institute, Rural Development Administration, Omokchun-dong 564, Kwonsun-gu, Suwon, Korea b Department of Genetic Engineering, Sungkyunkwan University, Chunchun-dong 300, Jangan-gu, Suwon, Korea c School of Agricultural Biotechnology, Seoul National University San 56-1, Sillim-dong, Gwanak-gu, Seoul 151-742, Korea Received 1 June 2005; accepted 3 September 2005 Available online 2 December 2005 Abstract On pig chromosome 6, the SW71 microsatellite is located in the region corresponding to several quantitative trait loci (QTL), such as those for intramuscular fat content and for body weight at 4 weeks of age. The genomic sequence of approximately 909 kb was obtained from seven BAC clones encompassing the SW71 region corresponding to human 18q11.21–q11.22. By searching the NCBI GenBank using BLASTX and BLASTN, this 909-kb segment was found to contain eight genes, RAB31, TXNDC2, VAPA, APCDD1, NAPG, FAM38B, C18orf30, and C18orf58, and one putative gene (DN119777). -
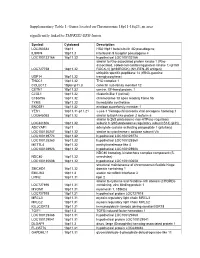
Supplementary Table 1: Genes Located on Chromosome 18P11-18Q23, an Area Significantly Linked to TMPRSS2-ERG Fusion
Supplementary Table 1: Genes located on Chromosome 18p11-18q23, an area significantly linked to TMPRSS2-ERG fusion Symbol Cytoband Description LOC260334 18p11 HSA18p11 beta-tubulin 4Q pseudogene IL9RP4 18p11.3 interleukin 9 receptor pseudogene 4 LOC100132166 18p11.32 hypothetical LOC100132166 similar to Rho-associated protein kinase 1 (Rho- associated, coiled-coil-containing protein kinase 1) (p160 LOC727758 18p11.32 ROCK-1) (p160ROCK) (NY-REN-35 antigen) ubiquitin specific peptidase 14 (tRNA-guanine USP14 18p11.32 transglycosylase) THOC1 18p11.32 THO complex 1 COLEC12 18pter-p11.3 collectin sub-family member 12 CETN1 18p11.32 centrin, EF-hand protein, 1 CLUL1 18p11.32 clusterin-like 1 (retinal) C18orf56 18p11.32 chromosome 18 open reading frame 56 TYMS 18p11.32 thymidylate synthetase ENOSF1 18p11.32 enolase superfamily member 1 YES1 18p11.31-p11.21 v-yes-1 Yamaguchi sarcoma viral oncogene homolog 1 LOC645053 18p11.32 similar to BolA-like protein 2 isoform a similar to 26S proteasome non-ATPase regulatory LOC441806 18p11.32 subunit 8 (26S proteasome regulatory subunit S14) (p31) ADCYAP1 18p11 adenylate cyclase activating polypeptide 1 (pituitary) LOC100130247 18p11.32 similar to cytochrome c oxidase subunit VIc LOC100129774 18p11.32 hypothetical LOC100129774 LOC100128360 18p11.32 hypothetical LOC100128360 METTL4 18p11.32 methyltransferase like 4 LOC100128926 18p11.32 hypothetical LOC100128926 NDC80 homolog, kinetochore complex component (S. NDC80 18p11.32 cerevisiae) LOC100130608 18p11.32 hypothetical LOC100130608 structural maintenance -

Reverse Engineering of Modified Genes by Bayesian Network Analysis Defines Olecm Ular Determinants Critical to the Development of Glioblastoma Brian W
Florida International University FIU Digital Commons Robert Stempel College of Public Health & Social Environmental Health Sciences Work 5-30-2013 Reverse Engineering of Modified Genes by Bayesian Network Analysis Defines olecM ular Determinants Critical to the Development of Glioblastoma Brian W. Kunkle Department of Environmental Health Sciences, Florida International University Changwon Yoo Department of Biostatistics, Florida International University, [email protected] Deodutta Roy Department of Environmental Health Sciences, Florida International University, [email protected] Follow this and additional works at: https://digitalcommons.fiu.edu/eoh_fac Part of the Medicine and Health Sciences Commons Recommended Citation Kunkle BW, Yoo C, Roy D (2013) Reverse Engineering of Modified Genes by Bayesian Network Analysis Defines Molecular Determinants Critical to the Development of Glioblastoma. PLoS ONE 8(5): e64140. https://doi.org/10.1371/ journal.pone.0064140 This work is brought to you for free and open access by the Robert Stempel College of Public Health & Social Work at FIU Digital Commons. It has been accepted for inclusion in Environmental Health Sciences by an authorized administrator of FIU Digital Commons. For more information, please contact [email protected]. Reverse Engineering of Modified Genes by Bayesian Network Analysis Defines Molecular Determinants Critical to the Development of Glioblastoma Brian W. Kunkle1, Changwon Yoo2, Deodutta Roy1* 1 Department of Environmental and Occupational Health, Florida International University, Miami, Florida, United States of America, 2 Department of Biostatistics, Florida International University, Miami, Florida, United States of America Abstract In this study we have identified key genes that are critical in development of astrocytic tumors. Meta-analysis of microarray studies which compared normal tissue to astrocytoma revealed a set of 646 differentially expressed genes in the majority of astrocytoma. -

A Network Inference Approach to Understanding Musculoskeletal
A NETWORK INFERENCE APPROACH TO UNDERSTANDING MUSCULOSKELETAL DISORDERS by NIL TURAN A thesis submitted to The University of Birmingham for the degree of Doctor of Philosophy College of Life and Environmental Sciences School of Biosciences The University of Birmingham June 2013 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Musculoskeletal disorders are among the most important health problem affecting the quality of life and contributing to a high burden on healthcare systems worldwide. Understanding the molecular mechanisms underlying these disorders is crucial for the development of efficient treatments. In this thesis, musculoskeletal disorders including muscle wasting, bone loss and cartilage deformation have been studied using systems biology approaches. Muscle wasting occurring as a systemic effect in COPD patients has been investigated with an integrative network inference approach. This work has lead to a model describing the relationship between muscle molecular and physiological response to training and systemic inflammatory mediators. This model has shown for the first time that oxygen dependent changes in the expression of epigenetic modifiers and not chronic inflammation may be causally linked to muscle dysfunction. -

Table S1. 103 Ferroptosis-Related Genes Retrieved from the Genecards
Table S1. 103 ferroptosis-related genes retrieved from the GeneCards. Gene Symbol Description Category GPX4 Glutathione Peroxidase 4 Protein Coding AIFM2 Apoptosis Inducing Factor Mitochondria Associated 2 Protein Coding TP53 Tumor Protein P53 Protein Coding ACSL4 Acyl-CoA Synthetase Long Chain Family Member 4 Protein Coding SLC7A11 Solute Carrier Family 7 Member 11 Protein Coding VDAC2 Voltage Dependent Anion Channel 2 Protein Coding VDAC3 Voltage Dependent Anion Channel 3 Protein Coding ATG5 Autophagy Related 5 Protein Coding ATG7 Autophagy Related 7 Protein Coding NCOA4 Nuclear Receptor Coactivator 4 Protein Coding HMOX1 Heme Oxygenase 1 Protein Coding SLC3A2 Solute Carrier Family 3 Member 2 Protein Coding ALOX15 Arachidonate 15-Lipoxygenase Protein Coding BECN1 Beclin 1 Protein Coding PRKAA1 Protein Kinase AMP-Activated Catalytic Subunit Alpha 1 Protein Coding SAT1 Spermidine/Spermine N1-Acetyltransferase 1 Protein Coding NF2 Neurofibromin 2 Protein Coding YAP1 Yes1 Associated Transcriptional Regulator Protein Coding FTH1 Ferritin Heavy Chain 1 Protein Coding TF Transferrin Protein Coding TFRC Transferrin Receptor Protein Coding FTL Ferritin Light Chain Protein Coding CYBB Cytochrome B-245 Beta Chain Protein Coding GSS Glutathione Synthetase Protein Coding CP Ceruloplasmin Protein Coding PRNP Prion Protein Protein Coding SLC11A2 Solute Carrier Family 11 Member 2 Protein Coding SLC40A1 Solute Carrier Family 40 Member 1 Protein Coding STEAP3 STEAP3 Metalloreductase Protein Coding ACSL1 Acyl-CoA Synthetase Long Chain Family Member 1 Protein -

GAPVD1 and ANKFY1 Mutations Implicate RAB5 Regulation in Nephrotic Syndrome
BASIC RESEARCH www.jasn.org GAPVD1 and ANKFY1 Mutations Implicate RAB5 Regulation in Nephrotic Syndrome Tobias Hermle,1,2 Ronen Schneider,1 David Schapiro,1 Daniela A. Braun,1 Amelie T. van der Ven,1 Jillian K. Warejko,1 Ankana Daga,1 Eugen Widmeier,1 Makiko Nakayama,1 Tilman Jobst-Schwan,1 Amar J. Majmundar,1 Shazia Ashraf,1 Jia Rao,1 Laura S. Finn,3 Velibor Tasic,4 Joel D. Hernandez,5 Arvind Bagga,6 Sawsan M. Jalalah,7 Sherif El Desoky,8 Jameela A. Kari,8 Kristen M. Laricchia,9 Monkol Lek,9 Heidi L. Rehm,9 Daniel G. MacArthur,9 Shrikant Mane,10 Richard P. Lifton,10,11 Shirlee Shril,1 and Friedhelm Hildebrandt1 Due to the number of contributing authors, the affiliations are listed at the end of this article. ABSTRACT Background Steroid-resistant nephrotic syndrome (SRNS) is a frequent cause of CKD. The discovery of monogenic causes of SRNS has revealed specific pathogenetic pathways, but these monogenic causes do not explain all cases of SRNS. Methods To identify novel monogenic causes of SRNS, we screened 665 patients by whole-exome se- quencing. We then evaluated the in vitro functional significance of two genes and the mutations therein that we discovered through this sequencing and conducted complementary studies in podocyte-like Drosophila nephrocytes. Results We identified conserved, homozygous missense mutations of GAPVD1 in two families with early- onset NS and a homozygous missense mutation of ANKFY1 in two siblings with SRNS. GAPVD1 and ANKFY1 interact with the endosomal regulator RAB5. Coimmunoprecipitation assays indicated interaction between GAPVD1 and ANKFY1 proteins, which also colocalized when expressed in HEK293T cells. -

Rab Gtpases: Switching to Human Diseases
cells Review Rab GTPases: Switching to Human Diseases Noemi Antonella Guadagno and Cinzia Progida * Department of Biosciences, University of Oslo, 0316 Oslo, Norway * Correspondence: [email protected]; Tel.: +47-22-85-44-41 Received: 30 June 2019; Accepted: 14 August 2019; Published: 16 August 2019 Abstract: Rab proteins compose the largest family of small GTPases and control the different steps of intracellular membrane traffic. More recently, they have been shown to also regulate cell signaling, division, survival, and migration. The regulation of these processes generally occurs through recruitment of effectors and regulatory proteins, which control the association of Rab proteins to membranes and their activation state. Alterations in Rab proteins and their effectors are associated with multiple human diseases, including neurodegeneration, cancer, and infections. This review provides an overview of how the dysregulation of Rab-mediated functions and membrane trafficking contributes to these disorders. Understanding the altered dynamics of Rabs and intracellular transport defects might thus shed new light on potential therapeutic strategies. Keywords: GTPases; Rab proteins; membrane trafficking; neurodegeneration; cancer; intracellular pathogens 1. Introduction Intracellular membrane trafficking is essential for the transport of membranes and cargoes between the different compartments in eukaryotic cells. It uses vesicular or tubular carriers that travel along the endocytic and exocytic pathways and it is regulated by complex protein machineries [1]. Rab GTPases are evolutionarily conserved regulators of vesicular transport, with more than 60 members described in humans [2,3]. They are localized to different membrane compartments in order to control both the specificity and the directionality of membrane trafficking. -

Enrichment of Neurodegenerative Microglia Signature in Brain-Derived 2 Extracellular Vesicles Isolated from Alzheimer's Disease Mouse Model 3
bioRxiv preprint doi: https://doi.org/10.1101/2020.11.05.369728; this version posted November 6, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Enrichment of neurodegenerative microglia signature in brain-derived 2 extracellular vesicles isolated from Alzheimer's disease mouse model 3 4 Satoshi Muraoka1, Mark P. Jedrychowski2, Naotoshi Iwahara1, Mohammad Abdullah1, 5 Kristen D. Onos3, Kelly J. Keezer3, Jianqiao Hu1, Seiko Ikezu1, Gareth R. Howell3, Steven 6 P. Gygi2, Tsuneya Ikezu1,4,5* 7 1Department of Pharmacology & Experimental Therapeutics, Boston University School of 8 Medicine, Boston, MA, USA; [email protected] (S.M.); [email protected] (N.I.); 9 [email protected] (M.A.); [email protected] (J.H.); [email protected] (S.I.) 10 2Department of Cell Biology, Harvard Medical School, Boston, MA, USA; 11 [email protected] (M.P.J.); [email protected] (S.P.G.) 12 3The Jackson Laboratory, Bar Harbor, Maine, ME, USA; [email protected] (K.O.); 13 [email protected] (K.J.K); [email protected] (G.H.) 14 4Department of Neurology, Alzheimer’s Disease Center, Boston University School of Medicine, 15 Boston, MA, USA 16 5Center for Systems Neuroscience, Boston University, Boston, MA, USA 17 18 #Correspondence author: Tsuneya Ikezu, MD, PhD 19 Boston University School of Medicine, 72 East Concord St, L-606B, Boston, MA 02118, 20 USA. Email: [email protected] Phone: 617-358-9575 Fax: 617-358-9574 21 22 Running title: Protein profiling of CAST.APP/PS1 mouse brain-derived EVs 23 24 bioRxiv preprint doi: https://doi.org/10.1101/2020.11.05.369728; this version posted November 6, 2020. -

Oncogenic Effect of the Novel Fusion Gene VAPA-Rab31 in Lung
International Journal of Molecular Sciences Article Oncogenic Effect of the Novel Fusion Gene VAPA-Rab31 in Lung Adenocarcinoma 1, 1, 2 1 1, Daseul Yoon y, Kieun Bae y, Jin-Hee Kim , Yang-Kyu Choi and Kyong-Ah Yoon * 1 College of Veterinary Medicine, Konkuk University, Seoul 05029, Korea; [email protected] (D.Y.); [email protected] (K.B.); [email protected] (Y.-K.C.) 2 College of Health Science, Cheongju University, Cheongju 28503, Korea; [email protected] * Correspondence: [email protected]; Tel.: +82-2-450-3789 These authors are equally contributed to this work. y Received: 25 April 2019; Accepted: 8 May 2019; Published: 10 May 2019 Abstract: Fusion genes have been identified as oncogenes in several solid tumors including lung, colorectal, and stomach cancers. Here, we characterized the fusion gene, VAPA-Rab31, discovered from RNA-sequencing data of a patient with lung adenocarcinoma who did not harbor activating mutations in EGFR, KRAS and ALK. This fusion gene encodes a protein comprising the N-terminal region of vesicle-associated membrane protein (VAMP)-associated protein A (VAPA) fused to the C-terminal region of Ras-related protein 31 (Rab31). Exogenous expression of VAPA-Rab31 in immortalized normal bronchial epithelial cells demonstrated the potential transforming effects of this fusion gene, including increased colony formation and cell proliferation in vitro. Also, enhanced tumorigenicity upon VAPA-Rab31 was confirmed in vivo using a mouse xenograft model. Metastatic tumors were also detected in the liver and lungs of xenografted mice. Overexpression of VAPA-Rab31 upregulated anti-apoptotic protein Bcl-2 and phosphorylated CREB both in cells and xenograft tumors. -

Supporting Information
Supporting Information Miller et al. 10.1073/pnas.0914257107 SI Materials and Methods files with 20 to 40 samples and 5,629 to 9,731 genes each and 20 Data Set Acquisition and Filtering. All data sets were downloaded mouse expression files with 18 and 44 samples and 5,176 to 6,157 from the GEO database, and consisted of experiments run on genes each. All preprocessed data files (as well as the resulting either mouse or human brain tissue (Fig. 1A). We filtered out all network data and some associated code and support files) are but a core collection of data sets that were similar enough for available at the WGCNA group Web site (www.genetics.ucla.edu/ useful bioinformatic comparison. First, we removed all data sets labs/horvath/CoexpressionNetwork/MouseHumanBrain). that were not run on an Affymetrix platform, leaving three From these preprocessed expression files we created a human platforms in human (HG-U95A, HG-U133A, HG-U133 Plus 2) and a mouse consensus network (method modified from ref. 4). and two in mouse (MG-U74A, MG-U430A). Second, we ex- For each consensus network we first created correlation matrices cluded all samples in each data set that were not taken from from each data set (obtained by calculating the Pearson correla- brain tissue (for example, in one expression atlas study, more tions between all variable probe sets across all subjects in each than 80% of the samples were excluded). Third, to make the data set), and then weighted them based on the number of sam- correlations between genes more comparable across studies, we ples used in that data set.