The 14Th Workshop on Mobile Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Goodwill Impairment Test of the Cellular Segment June 30Th, 2019
Bezeq The Israel Telecommunication Corporation Limited Goodwill Impairment Test of the Cellular Segment June 30th, 2019 August 2019 14 Kreminitzky St., Tel Aviv 6789912 I Tel.: 03-5617801 I Fax: 077-3181607 Introduction and Limit of Liability • We were retained by Bezeq The Israel Telecommunication Corp. Ltd. (hereunder “Bezeq” and/or “Bezeq Group” and/or the ”Client”) to prepare a goodwill impairment test report (the “Report”) of the cellular business unit (hereunder: “Pelephone” and/or the “Cellular Segment”) as of June 30th, 2019. • The Report intended solely for the use of the Client and is . This Report may not be reproduced, in whole or in part, and the findings of this Report may not be used by a third party for any purpose, without our expressed written consent. Notwithstanding any of the above, this Report may be included in the Client’s financial statements of as of June. 30, 2017. • For the purpose of preparing this Report, we relied upon financial and other information including prospective financial information obtained from the Company and/or the Client and/or anyone on their behalf (the “Information”). We assumed that the Information is credible and therefore did not perform an independent audit of the information. In addition, nothing suggesting that the Information may be unreasonable has come to our attention. The Information has not been examined in an independent manner, and therefore this Report does not constitute a verification of the Information’s correctness, completeness and accuracy. If the case that the Information is not complete nor accurate or credible, the results of this valuation might change. -

Cellcom Israel Ltd
UNITED STATES SECURITIES AND EXCHANGE COMMISSION WASHINGTON, D.C. 20549 FORM 20–F ☐ REGISTRATION STATEMENT PURSUANT TO SECTION 12(b) OR (g) OF THE SECURITIES EXCHANGE ACT OF 1934 OR ☒ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2020 OR ☐ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from___________ to __________________ OR ☐ SHELL COMPANY REPORT PURSUANT TO SECTION 13 OR 15 (d) OF THE SECURITIES EXCHANGE ACT OF 1934 Date of event requiring this shell company report ……………………………. Commission file number 001-33271 CELLCOM ISRAEL LTD. (Exact name of Registrant as specified in its charter and translation of Registrant’s name into English) ISRAEL (Jurisdiction of incorporation or organization) 10 Hagavish Street, Netanya 4250708, Israel (Address of principal executive offices) Liat Menahemi Stadler, 972-52-9989595 (phone), 972-98607986 (fax), [email protected], 10 Hagavish Street, Netanya 4250708, Israel (Name, Telephone, E-mail and/or Facsimile number and Address of Company Contact Person) Securities registered or to be registered pursuant to Section 12(b) of the Act. Title of each class Trading Symbol Name of each exchange on which registered Ordinary Shares, par value NIS 0.01 per share (CEL) New York Stock Exchange (“NYSE”)*1 Securities registered or to be registered pursuant to Section 12(g) of the Act. None (Title of Class) Securities for which there is a reporting obligation pursuant to Section 15(d) of the Act. None (Title of Class) * We voluntarily delisted our ordinary shares from the NYSE on February 8, 2021. -
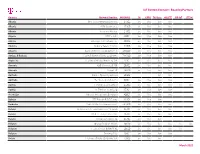
Iot Custom Connect - Roaming Partners
IoT Custom Connect - Roaming Partners Country Column1 Network Provider Column2MCCMNCColumn10 Column32G Column4GPRS Column53G Data Column64G/LTE Column7NB-IoT LTE-M Albania One Telecommunications sh.a 27601 live live live live Albania ALBtelecom sh.a. 27603 live live live live Albania Vodafone Albania 27602 live live live live Algeria ATM Mobilis 60301 live live live live Algeria Wataniya Telecom Algerie 60303 live live live live Andorra Andorra Telecom S.A.U. 21303 live live live live Anguilla Cable and Wireless (Anguilla) Ltd 365840 live live live live Antigua & Barbuda Cable & Wireless (Antigua) Limited 344920 live live live live Argentina Telefónica Móviles Argentina S.A. 72207 live live live live Armenia VEON Armenia CJSC 28301 live live live live Armenia Ucom LLC 28310 live live live live Australia SingTel Optus Pty Limited 50502 live live Australia Telstra Corporation Ltd 50501 live live live live Austria T-Mobile Austria GmbH 23203 live live live live live live Austria A1 Telekom Austria AG 23201 live live live live Azerbaijan Bakcell Limited Liable Company 40002 live live live live Bahrain STC Bahrain B.S.C Closed 42604 live live live Barbados Cable & Wireless Barbados Ltd. 342600 live live live live Belarus Belarusian Telecommunications Network 25704 live live live live Belarus Mobile TeleSystems JLLC 25702 live live live live Belarus Unitary Enterprise A1 25701 live live live Belgium Orange Belgium NV/SA 20610 live live live live live live Belgium Telenet Group BVBA/SPRL 20620 live live live live live Belgium Proximus PLC 20601 live live live live Bolivia Telefonica Celular De Bolivia S.A. 73603 live live live March 2021 IoT Custom Connect - Roaming Partners Country Column1 Network Provider Column2MCCMNCColumn10 Column32G Column4GPRS Column53G Data Column64G/LTE Column7NB-IoT LTE-M Bosnia and Herzegovina PUBLIC ENTERPRISE CROATIAN TELECOM Ltd. -

Designing the Future of the 5G Revolution
DESIGNING THE FUTURE OF THE 5G REVOLUTION NOVEMBER 17-18, 2020 VIRTUAL EXPO Mobile 5G Innovation Israel event, initiated by the Israel Export Institute and the Foreign Trade Administration at the Ministry of Economy and Industry is our first biggest virtual Mobile Technology Expo. The virtual Expo will be held on November 17-18, 2020 and will stay LIVE till January! This event will include Israel’s leading companies presenting the latest technology for: 5G, MEC, Connected Car, XR, IoT, Smart City, Smart Home, Telehealth, Industry 4.0, AI & Machine Learning, Big Data & Analytics, FinTech and much more. We invite you to join us and schedule 1:1 meetings with the most innovative companies in Israel. Contents The Israel Export & International Cooperation Institute 3 The Foreign Trade Administration 4 Index by Company 5 Index by Category 17 Company Profiles 25 Contents 2 The Israel Export & International Cooperation Institute ISRAEL EXPORT INSTITUTE The Israel Export & International Cooperation Institute, supported by member firms, private sector bodies and the government of Israel, advances business relationships between Israeli exporters and overseas businesses and organizations. By providing a wide range of export-oriented services to Israeli companies and complementary services to the international business community, the Institute helps build successful joint ventures, strategic alliances and trade partnerships. The IEICI’s High Tech Department is the leader in business matching between the more than 1,500 companies in the Israeli high tech industry and worldwide business partners at all levels. It has a proven ability to identify and match suitable potential business partners, organize one-on-one business meetings, and is a focal point for contacts with the government as well as with industry. -

Regulatory Story Go to Market News Section
4/4/2018 Agreement with HOT Mobile - RNS - London Stock Exchange Regulatory Story Go to market news section Mobile Tornado Group PLC - MBT Agreement with HOT Mobile Released 07:00 04-Oct-2017 RNS Number : 6189S Mobile Tornado Group PLC 04 October 2017 Mobile Tornado Group plc ("Mobile Tornado" or the "Company") Cooperaon Agreement to Provide PTToC services to HOT Mobile Customers The new technology enables Push-To-Talk (PTT) services on 3G and 4G networks and Wi-Fi networks Mobile Tornado, a leading provider of carrier grade professional end-to-end Push-to- Talk soluons over any IP network, and HOT Mobile, the fastest growing cellular Company in Israel, announces it has recently signed an agreement under which Mobile Tornado will provide its advanced Push-To-Talk over Cellular (PTToC) soluons to HOT Mobile customers in Israel. As part of the agreement, HOT Mobile will offer Mobile Tornado's PTToC services to customers of its MIRS network as well as other customers with PTT needs. Mobile Tornado's carrier-grade PTT technology enables PTT over cellular networks and the Internet, enabling individual users as well as large user groups to use push-to-talk (PTT), push-to-locate (PTL), push-to-alert (PTA) and push-to-message (PTM) services. The PTT services are used by government agencies, security organisaons, security companies, ulies and infrastructure companies, as well as manufacturing and service companies. Onboarding takes place via the MIRS 4G app, which is also available on Google Play and in the App Store. The app can be installed on smart devices as well as a wide range of rugged devices. -

International Broadband Data Report )
Federal Communications Commission DA 16-97 Before the Federal Communications Commission Washington, D.C. 20554 In the Matter of ) ) International Comparison Requirements Pursuant ) GN Docket No. 15-191 to the Broadband Data Improvement Act ) ) International Broadband Data Report ) FIFTH REPORT Adopted: January 28, 2016 Released: January 29, 2016 By the Chief, International Bureau: TABLE OF CONTENTS Heading Paragraph # I. INTRODUCTION .................................................................................................................................. 1 II. BACKGROUND .................................................................................................................................... 2 III. DISCUSSION ...................................................................................................................................... 13 A. Fixed Broadband Coverage Comparison with Europe .................................................................. 14 B. Broadband Subscription (OECD Countries) .................................................................................. 22 C. Fixed Broadband Speeds ................................................................................................................ 26 D. Broadband Pricing Plans ................................................................................................................ 32 E. Other Relevant Information and International Developments ....................................................... 43 IV. CONCLUSION ................................................................................................................................... -

Management's Discussion and Analysis Altice
MANAGEMENT’S DISCUSSION AND ANALYSIS ALTICE INTERNATIONAL S.à r.l. FOR THE THREE MONTHS ENDED MARCH 31, 2020 Contents Chapter page 1 Overview 2 2 Strategy and performance 8 3 Basis of presentation 9 4 Group financial review 10 5 Revenue 14 6 Adjusted EBITDA 17 7 Operating profit of the Group 18 8 Result of the Group - items below operating expenses 19 9 Liquidity and capital resources 21 10 Capital Expenditures 23 11 Key operating measures 24 12 Other disclosures 25 13 Key Statement of Income items 26 1 1 OVERVIEW 1.1 Group Business 1.1.1 Overview of the Group’s business The Group is a multinational group operating across two sectors: (i) telecom (broadband and mobile communications) and (ii) content and media. The Group operates in Portugal, Israel and the Dominican Republic. The Group also has a global presence through its online advertising business Teads. The parent company of the Group is Altice International S.à r.l. (the “Company”). The Group had expanded internationally in previous years through several acquisitions of telecommunications businesses, including: MEO in Portugal; HOT in Israel; and Altice in the Dominican Republic. The Group’s acquisition strategy has allowed it to target cable, FTTH or mobile operators with what it believes to be high-quality networks in markets the Group finds attractive from an economic, competitive and regulatory perspective. Furthermore, the Group is focused on growing the businesses that it acquired organically, by focusing on cost optimization, increasing economies of scale and operational synergies and improving quality of its network and services. -

Afikim Public Transportation Ltd. E Israel Airbnb Inc. E United States American Israeli Gas Corporation Ltd
Afikim Public Transportation Ltd. E Israel Airbnb Inc. E United States American Israeli Gas Corporation Ltd. E, G Israel Amir Marketing and Investments in Agriculture Ltd. G Israel Amos Hadar Properties and Investments Ltd. G Israel Angel Bakeries E, G Israel Archivists Ltd. G Israel Ariel Properties Group E Israel Ashtrom Industries Ltd. G Israel Ashtrom Properties Ltd. G Israel Avgol Industries 1953 Ltd. G Israel Bank Hapoalim B.M. E, F Israel Bank Leumi Le-Israel B.M. E, F Israel Bank of Jerusalem Ltd. E, F Israel Beit Haarchiv Ltd. G Israel Bezeq, the Israel Telecommunication Corp Ltd. E, G Israel Booking.com B.V. E Netherlands C Mer Industries Ltd. B Israel Café Café Israel Ltd. E, G Israel Caliber 3 D, G Israel Cellcom Israel Ltd. E, G Israel Cherriessa Ltd. G Israel Chish Nofei Israel Ltd. G Israel Citadis Israel Ltd. E, G Israel Comasco Ltd. A Israel Darban Investments Ltd. G Israel Delek Group Ltd. E, G Israel Delta Israel G Israel Dor Alon Energy in Israel 1988 Ltd. E, G Israel Egis Rail E France Egged, Israel Transportation Cooperative Society Ltd. E Israel Energix Renewable Energies Ltd. G Israel EPR Systems Ltd. E, G Israel Extal Ltd. G Israel Expedia Group Inc. E United States Field Produce Ltd. G Israel Field Produce Marketing Ltd. G Israel First International Bank of Israel Ltd. E, F Israel Galshan Shvakim Ltd. E, D Israel General Mills Israel Ltd. G Israel Hadiklaim Israel Date Growers Cooperative Ltd. G Israel Hot Mobile Ltd. E Israel Hot Telecommunications Systems Ltd. -

Israel Technology, Public Sphere and Journalism
MEDIA INFLUENCE MATRIX: ISRAEL TECHNOLOGY, PUBLIC SPHERE AND JOURNALISM Author: Roni Dorot Editor: Marius Dragomir 2021 | MARCH PUBLISHED BY CEU CENTER FOR MEDIA, DATA AND SOCIETY About CMDS About the authors The Center for Media, Data and Society Roni Dorot is a researcher for the Center for Media, (CMDS) is a research center for the study Data and Society. She received her PhD in Social and of media, communication, and Political Sciences from the European University information policy and its impact on Institute, Florence, and holds a MA in Public Policy society and practice. Founded in 2004 as from Tel-Aviv University. She was a postdoctoral the Center for Media and Communication fellow at the Center of Conflict, Negotiation and Studies, CMDS is part of Central Recovery, at the School of Public Policy, CEU. Her European University’s Democracy dissertation, “Dead End: Israeli Militarism and the Institute and serves as a focal point for an Dynamics of State Retribution”, examines the history international network of acclaimed of political revenge and the genealogy of retaliation scholars, research institutions and discourses in the Jewish press within the context of the activists. Palestinian-Israeli conflict. Her previous research analyzed the governmental outcomes of Israeli municipalities from a comparative perspective. She is a CMDS ADVISORY BOARD recipient of the Sapir Price for municipal studies (in Israel), the Istituto Italiano di Cultura scholarship and Clara-Luz Álvarez the EUI excellence fellowship. She currently writes for Floriana Fossato Haaretz newspaper her blog ‘Documania’ where she Ellen Hume critically analyses documentaries from a cultural and Monroe Price sociological perspective. -
Global Mobile Network Experience Awards 2020 Report
Author Sam Fenwick, Senior Analyst Data Collection — Jan 1 - Jun 28, 2019 & 2020 Global Winners Global Leaders Global Rising Stars Total Devices Total Measurements Years of Opensignal 6 29 71 95,867,800 403,023,311,230 10 Opensignal is the independent global standard for analyzing consumer mobile experience. Our industry reports are the definitive guide to understanding the true experience consumers receive on wireless networks. 10 years ago, the telecommunications industry was in a very different place — back then 4G was still in its infancy and Opensignal was just starting out. We’ve come a long way since our humble beginnings and our 10 year anniversary feels liKe the perfect occasion to taKe a broader looK across the rapidly changing mobile landscape. In this report we are providing a comprehensive comparison of mobile networK experience globally across five Key measures of mobile networK experience — Video Experience, Voice App Experience, Download Speed Experience, Upload Speed Experience and 4G Availability, for the very first time. As the telecoms industry is in a continual state of change we have also analyzed the degree to which the world’s operators have improved their users’ mobile networK experience over the last year. During this period operators around the world have been navigating many unforeseen challenges — not least an ever greater reliance on communications as a result of the COVID-19 pandemic — which maKes the improvements we have measured even more impressive. We’d like to take this opportunity to thank you, our audience, for your continued support and we looK forward to the next 10 years of providing operators, regulators, analysts and millions of consumers around the world with insights on the real world mobile networK experience as we move into the 5G era. -
Coverage and Rates
Country Country Operator GSM 3G Frequency Voice Rate/minute Text Data rate/per MB Code ALL CALLS Message Rate / per message sent Afghan Wireless 900/1800/ 3G 2100 $3.50 $0.99 $12.00 Etisalat 900/1800/ 3G 2100 $3.50 $0.99 $12.00 Afghanistan AFG MTN 900/1800/ 3G 2100 $3.50 $0.99 $12.00 ROSHAN 900/1800/ 3G 2100 $3.50 $0.99 $12.00 Alcom 900/ 3G 2100 $2.50 $0.99 $8.00 Aland Islands FIN Sonera 900/1800/ 3G 2100 $2.50 $0.99 $8.00 ALBtelecom 900/1800/ 3G 2100 $2.50 $0.99 $8.00 Albania ALB ONE AL 900/1800/ 3G 2100 $2.50 $0.99 $8.00 Vodafone 900/1800/ 3G 2100 $2.50 $0.99 $8.00 Djezzy 900/1800/ 3G 2100 $4.00 $0.99 $16.00 Algeria DZA Mobilis 900/1800/ 3G 2100 $4.00 $0.99 $16.00 ooredoo 900/1800/ 3G 2100 $4.00 $0.99 $16.00 American Samoa ASM blue sky 850/1900/ 3G 850 $3.50 $0.99 $12.00 Andorra AND Andorra Telecom 900/1800/ 3G 1900/2100 $2.50 $0.99 $8.00 Angola Movicel 900/1800/ 3G 900 $4.00 $0.99 $16.00 AGO Unitel 900/ 3G 2100 $4.00 $0.99 $16.00 CAR Digicel 900/1900/ 3G 850 $2.50 $0.99 $8.00 Anguilla AIA FLOW 850/1900/ 3G 850 $2.50 $0.99 $8.00 ATG APUA 3G 1900 $2.50 $0.99 $8.00 Antigua & Barbuda CAR Digicel 850/1900/ 3G 850 $2.50 $0.99 $8.00 ATG FLOW 850/1800/ 3G 850 $2.50 $0.99 $8.00 Claro 850/1900/ 3G 850/1900 $3.50 $0.99 $12.00 Argentina ARG Movistar 850/1900/ 3G 850/1900 $3.50 $0.99 $12.00 Personal 1900/ 3G 850/1900 $3.50 $0.99 $12.00 Ucom 900/1800/ 3G 2100 $3.50 $0.99 $12.00 Armenia ARM VEON Armenia 900/1800/ 3G 2100 $3.50 $0.99 $12.00 VivaCell-MTS 900/1800/ 3G 1900/2100 $3.50 $0.99 $12.00 CAR Digicel 900/1900/ 3G 2100 $2.50 $0.99 $8.00 Aruba -
Mobile Advertising Guide
Mobile Advertising Guide Authors: Ralph Ruckman & Ryan Gray Owners: IMGrind | Revived Media | iMobiTrax Copyright 2013 Internet Marketing Grind LLC DISCLAIMER THE CONTENTS OF THIS MANUAL REFLECT THE AUTHOR’S VIEWS ACQUIRED THROUGH HIS EXPERIENCE ON THE TOPIC UNDER DISCUSSION. THE AUTHOR OR PUBLISHER DISCLAIMS ANY PERSONAL LOSS OR LIABILITY CAUSED BY THE UTILIZATION OF ANY INFORMATION PRESENTED HEREIN. THE AUTHOR IS NOT ENGAGED IN RENDERING ANY LEGAL OR PROFESSIONAL ADVICE. THE SERVICES OF A PROFESSIONAL PERSON ARE RECOMMENDED IF LEGAL ADVICE OR ASSISTANCE IS NEEDED. WHILE THE SOURCES MENTIONED HEREIN ARE ASSUMED TO BE RELIABLE AT THE TIME OF WRITING, THE AUTHOR AND PUBLISHER, OR THEIR AFFILIATES, ARE NOT RESPONSIBLE FOR THEIR ACTIVITIES. FROM TIME TO TIME, SOURCES MAY TERMINATE OR MOVE AND PRICES MAY CHANGE WITHOUT NOTICE. SOURCES CAN ONLY BE CONFIRMED RELIABLE AT THE TIME OF ORIGINAL PUBLICATION OF THIS MANUAL. THIS MANUAL IS A GUIDE ONLY AND, AS SUCH, SHOULD BE CONSIDERED SOLELY FOR BASIC INFORMATION. EARNINGS OR PROFITS DERIVED FROM PARTICIPATING IN THE FOLLOWING PROGRAM ARE ENTIRELY GENERATED BY THE AMBITIONS, MOTIVATION, DESIRES, AND ABILITIES OF THE INDIVIDUAL READER. NO PART OF THIS MANUAL MAY BE ALTERED, COPIED, OR DISTRIBUTED, WITHOUT PRIOR WRITTEN PERMISSION OF THE AUTHOR OR PUBLISHER. ALL PRODUCT NAMES, LOGOS, AND TRADEMARKS ARE PROPERTY OF THEIR RESPECTIVE OWNERS WHO HAVE NOT NECESSARILY ENDORSED, SPONSORED, OR APPROVED THIS PUBLICATION. TEXT AND IMAGES AVAILABLE OVER THE INTERNET AND USED IN THIS MANUAL MAY BE SUBJECT TO INTELLECTUAL RIGHTS AND MAY NOT BE COPIED FROM THIS MANUAL. Copyright 2013 Internet Marketing Grind LLC Foreword Dear Mobile Marketers, I'll be upfront and straight to the point here.