A Case Study on Hindi Movie Scripts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
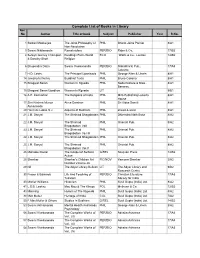
Complete List of Books in Library Acc No Author Title of Book Subject Publisher Year R.No
Complete List of Books in Library Acc No Author Title of book Subject Publisher Year R.No. 1 Satkari Mookerjee The Jaina Philosophy of PHIL Bharat Jaina Parisat 8/A1 Non-Absolutism 3 Swami Nikilananda Ramakrishna PER/BIO Rider & Co. 17/B2 4 Selwyn Gurney Champion Readings From World ECO `Watts & Co., London 14/B2 & Dorothy Short Religion 6 Bhupendra Datta Swami Vivekananda PER/BIO Nababharat Pub., 17/A3 Calcutta 7 H.D. Lewis The Principal Upanisads PHIL George Allen & Unwin 8/A1 14 Jawaherlal Nehru Buddhist Texts PHIL Bruno Cassirer 8/A1 15 Bhagwat Saran Women In Rgveda PHIL Nada Kishore & Bros., 8/A1 Benares. 15 Bhagwat Saran Upadhya Women in Rgveda LIT 9/B1 16 A.P. Karmarkar The Religions of India PHIL Mira Publishing Lonavla 8/A1 House 17 Shri Krishna Menon Atma-Darshan PHIL Sri Vidya Samiti 8/A1 Atmananda 20 Henri de Lubac S.J. Aspects of Budhism PHIL sheed & ward 8/A1 21 J.M. Sanyal The Shrimad Bhagabatam PHIL Dhirendra Nath Bose 8/A2 22 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam VolI 23 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam Vo.l III 24 J.M. Sanyal The Shrimad Bhagabatam PHIL Oriental Pub. 8/A2 25 J.M. Sanyal The Shrimad PHIL Oriental Pub. 8/A2 Bhagabatam Vol.V 26 Mahadev Desai The Gospel of Selfless G/REL Navijvan Press 14/B2 Action 28 Shankar Shankar's Children Art FIC/NOV Yamuna Shankar 2/A2 Number Volume 28 29 Nil The Adyar Library Bulletin LIT The Adyar Library and 9/B2 Research Centre 30 Fraser & Edwards Life And Teaching of PER/BIO Christian Literature 17/A3 Tukaram Society for India 40 Monier Williams Hinduism PHIL Susil Gupta (India) Ltd. -

Writers and Creative Advisors Selected for Drishyam | Sundance Institute Screenwriters Lab in Udaipur, India April 48
FOR IMMEDIATE RELEASE Media contacts: March 23, 2016 Chalena Cadenas 310.360.1981 [email protected] Mauli Singh [email protected] Writers and Creative Advisors Selected for Drishyam | Sundance Institute Screenwriters Lab in Udaipur, India April 48 Lab Recognizes and Supports Six Emerging Independent Filmmakers from India Los Angeles, CA — Sundance Institute and Drishyam Films today announced the artists and creative advisors selected for the second Drishyam | Sundance Institute Screenwriters Lab in Udaipur, India April 48. The Lab supports emerging filmmakers in India, as part of the Institute’s sustained commitment to international artists, which in the last 25 years has included programs in Brazil, Mexico, Jordan, Turkey, Japan, Cuba, Israel and Central Europe. Now in its second year, the fourday Lab is a creative and strategic partnership between Drishyam Films and Sundance Institute, and gives independent screenwriters the opportunity to work intensively on their feature film scripts in an environment that encourages innovation and creative risktaking. The Lab is centered around oneonone story sessions with creative advisors. Screenwriting fellows engage in an artistically rigorous process that offers lessons in craft, a fresh perspective on their work and a platform to fully realize their material. Leading the Lab in India is Drishyam founder, Manish Mundra. He said, “A beautiful heritage city in my hometown of Rajasthan, Udaipur forms an ideal writers retreat, and is the perfect environment for a diverse group of emerging writers and renowned mentors to have a refreshing and productive exchange. Our goal is that the six selected Indian projects, after undergoing a comprehensive mentoring process, will quickly move from script to screen and make their mark globally. -

Movie Aquisitions in 2010 - Hindi Cinema
Movie Aquisitions in 2010 - Hindi Cinema CISCA thanks Professor Nirmal Kumar of Sri Venkateshwara Collega and Meghnath Bhattacharya of AKHRA Ranchi for great assistance in bringing the films to Aarhus. For questions regarding these acquisitions please contact CISCA at [email protected] (Listed by title) Aamir Aandhi Directed by Rajkumar Gupta Directed by Gulzar Produced by Ronnie Screwvala Produced by J. Om Prakash, Gulzar 2008 1975 UTV Spotboy Motion Pictures Filmyug PVT Ltd. Aar Paar Chak De India Directed and produced by Guru Dutt Directed by Shimit Amin 1954 Produced by Aditya Chopra/Yash Chopra Guru Dutt Production 2007 Yash Raj Films Amar Akbar Anthony Anwar Directed and produced by Manmohan Desai Directed by Manish Jha 1977 Produced by Rajesh Singh Hirawat Jain and Company 2007 Dayal Creations Pvt. Ltd. Aparajito (The Unvanquished) Awara Directed and produced by Satyajit Raj Produced and directed by Raj Kapoor 1956 1951 Epic Productions R.K. Films Ltd. Black Bobby Directed and produced by Sanjay Leela Bhansali Directed and produced by Raj Kapoor 2005 1973 Yash Raj Films R.K. Films Ltd. Border Charulata (The Lonely Wife) Directed and produced by J.P. Dutta Directed by Satyajit Raj 1997 1964 J.P. Films RDB Productions Chaudhvin ka Chand Dev D Directed by Mohammed Sadiq Directed by Anurag Kashyap Produced by Guru Dutt Produced by UTV Spotboy, Bindass 1960 2009 Guru Dutt Production UTV Motion Pictures, UTV Spot Boy Devdas Devdas Directed and Produced by Bimal Roy Directed and produced by Sanjay Leela Bhansali 1955 2002 Bimal Roy Productions -

2005 (Pdf, 4.7
2006 Global Citizenship Report Vital Responsible Ethical Global Governance Integrity Technology Product Innovative Reliable Operations Speed Agility Supply Expert Privacy Trustworthy Safety Collaborative Employee Citizenship Diversity Engaging Customer Relationship Accessible Social Meaningful Profitable Public Leadership Optimistic Forward Growth Inventive Essential Report About this report Table of contents GRI indicators* Scope 1. Introduction . 3 2.11-2.13, 2.15 This report describes HP’s HP’s global citizenship priorities . 3 3.19 global citizenship activities L e t t e r f ro m C EO M a r k H u rd . 4 1.1-1.2 worldwide. It charts HP’s progress in fiscal year 2005. H P p ro fi l e . 5 2.1-2.8, 3.7, EC1-EC2 Letter from Diana Bell . 7 1.1-1.2 Reporting year Global citizenship . 8 1.1, 3.6, 3.19 All data are for HP’s fiscal year 2005 (ending October 31, 2005), Economic value . 12 EC3, EC5, EC6, EC8, EC13 unless otherwise noted. 2. Governance and ethics . 15 Corporate governance . 15 3.1-3.2, 3.4, 3.6, 3.8 Currency and measurement All $ references in this document Business ethics . 16 3.7, HR10, SO2, SO7, PR9 are U.S. dollars, unless otherwise 3. Product environmental impacts . 18 3.19, EN14 noted. D e s i g n f o r E nvi ro n m e n t . 18 3.16-3.17, PR6 Measures used in the report are E n e rgy e f fi ci e n c y . 22 EN30 metric, except where stated. -

Media Release Reliance Entertainment and Phantom Films
Media Release Reliance Entertainment and Phantom Films’ Super 30 to release on 23rd Nov, 2018 Directed by Vikas Bahl, “Super 30” will star Hrithik Roshan Mumbai, November 4, 2017: Anil D. Ambani led Reliance Entertainment and Phantom Films’ “Super 30” directed by Vikas Bahl and starring Hrithik Roshan in the lead role will release on 23rd November 2018. Super 30 is a story of a mathematics genius from a modest family in Bihar, Anand Kumar, who was told that only a king’s son can become a king. But he went on to prove how one poor man could create some of the world’s most genius minds. Anand Kumar’s training program is so effective that students post cracking IIT have gone on to become some of the most successful professionals. Many students trained under the Super 30 program have joined some of the top global companies like Adobe, Samsung Research Institute, Amazon etc. Anand Kumar said, “I trust Vikas Bahl with my life story and I believe that he will make a heartfelt film. I am a rooted guy so I feel some level of emotional quotient is required to live my life on screen. I have seen that in Hrithik – on and off screen. I have full faith in his capabilities.” Vikas Bahl, truly inspired by Anand Kumar’s initiative, said, “Super 30 is a story of the struggles of those genius kids who have one opportunity and how those 30 amongst thousands of others redefine success. The film will focus on the Super 30 program that Kumar started, which trains 30 IIT aspirants to crack its entrance test.” Vikas Bahl is one of the most critically and commercially acclaimed directors of our country. -

Anne Hathaway INTE O Rem D’Souza
PVR MOVIES FIRST VOL. 32 YOUR WINDOW INTO THE WORLD OF CINEMA JUNE 2018 21 LITTLE-KNOWN THINGS ABOUt…. GUEST RVIEW ANNE HATHAWAY INTE O REM D’SOUZA THE BEST NEW MOVIES PLAYING THIS MONTH: VEERE DI WEDDING, RACE 3, ISLE OF DOGS AND SANJU GREETINGS ear Movie Lovers, Motwane’s vigilante drama “Bhavesh Joshi” are among the much-awaited films that hit the screen this month. Here’s the June issue of Movies First, your exclusive window to the world of cinema. Meet rising star John Boyega and join us in wishing Hollywood icon Meryl Streep a happy birthday. Take a peek into Colin Trevorrow’s all-new, edgy “Jurassic World,” while also rewinding to its original “Jurassic World” We really hope you enjoy the issue. Wish you a fabulous (2015) the Steven Spielberg adventure that changed the month of movie watching. face of sci-fi forever. Regards All eyes are on director Remo D’Souza, whose revelations about Salman Khan starrer “Race 3” will get your pulse racing. Raj Kumar Hirani’s biographical film “Sanju”, Kareena Gautam Dutta Kapoor’s boisterous “Veere di Wedding” and Vikramaditya CEO, PVR Limited USING THE MAGAZINE We hope you’ll find this magazine easy to use, but here’s a handy guide to the icons used throughout anyway. You can tap the page once at any time to access full contents at the top of the page. PLAY TRAILER SET REMINDER BOOK TICKETS SHARE PVR MOVIES FIRST PAGE 2 CONTENTS Tap for... Tap for... Movie OF THE MONTH UP CLOSE & PERSONAL Tap for.. -

Masaan-Press-Kit.Pdf
MACASSAR PRODUCTIONS, PATHÉ ET AND DRISHYAM FILMS PRÉSENTENT PRESENT Durée Length : 1H43 Photos et dossier de presse téléchargeables sur www.pathefilms.com Material can be downloaded on www.patheinternational.com DISTRIBUTION FRENCH DISTRIBUTION & INTERNATIONAL SALES PATHÉ DISTRIBUTION 2, rue Lamennais – 75008 Paris Tél. : 01 71 72 30 00 www.pathefilms.com www.patheinternational.com À CANNES IN CANNES INTERNATIONAL SALES Boutique Bodyguard Résidences du Grand Hôtel - IBIS Entrance 45, la Croisette Apartement 4 A/E - 4th floor Jardins du Grand Hôtel Tél. : +33 4 93 68 24 31 06400 Cannes [email protected] Tél. : 04 93 99 91 34 RELATIONS PRESSE INTERNATIONAL PRESS LE PUBLIC SYSTÈME CINÉMA Céline PETIT, Clément REBILLAT, Celia MAHISTRE & Anne-Sophie TRINTIGNAC 40, rue Anatole France – 92594 Levallois-Perret Cedex Tél. : 01 41 34 23 50 [email protected] À CANNES IN CANNES RELATIONS PRESSE FRANCE & INTERNATIONAL LE PUBLIC SYSTÈME CINÉMA Céline PETIT, Clément RÉBILLAT, Celia MAHISTRE & Anne-Sophie TRINTIGNAC 29, rue Bivouac Napoléon – 06400 Cannes Tél. : +33 7 86 23 90 85 [email protected] [email protected] [email protected] [email protected] Bénarès, la cité sainte au bord du Gange, punit cruellement ceux qui jouent Benares, the holy city on the banks of the Ganges, reserves a cruel punishment avec les traditions morales. Deepak, un jeune homme issu des quartiers for those who play with moral traditions. Deepak, a young man from a poor pauvres, tombe éperdument amoureux d’une jeune fille qui n’est pas de la neighborhood, falls hopelessly in love with a young girl from a different caste. même caste que lui. -

Conference on "Towards New Visions: Women in Films, Media
Towards New Visions: Women in Films, Media and Beyond Virtual Conference, 11-12 March 2021 http://uoguel.ph/circleconference01 Organizers Aysha Iqbal Viswamohan, Indian Institute of Technology, Madras Sharada Srinivasan, University of Guelph Host Canada India Research Centre for Learning and Engagement (CIRCLE) Sponsor Shastri Indo-Canadian Institute’s Golden Jubilee Conference and Lecture Series Grant (GJCLSG) Day 1, 11 March 2021 7: 00p.m.-12:30a.m. IST/ 8:30a.m.-2:00p.m. EST Opening session 7:00-7:45p.m. Welcome: Dr. Sharada Srinivasan, Director, CIRCLE Introduction to the conference: Dr. Aysha Iqbal Viswamohan Opening remarks: Dr. Charlotte Yates, President & Vice-Chancellor, University of Guelph Opening remarks: Dr. Prachi Kaul, Director, SICI Plenary Session-1 8:00-9:00p.m. Parallel Session-1 9:55- 11:55p.m. Women’s Success Stories in Films and Media Women’s Empowerment on Screen, and New Media: Feminist Screen Chair: Aysha Iqbal Viswamohan Cultures in the Age of Digital Technologies Aswiny Iyer Tiwari Chair: Madhuja Mukherjee Pooja Ladha Surti 1. Collaborative Praxis: Feminisms and Empowerment in Contemporary Popular Bengali Cinema, Smita Bannerjee 2. Indian Women Rising: Female Star Portfolios in the Era of Digital Platforms, Akriti Rastogi 3. No Country for Aunties: A Feminist Inquiry into Intersectional Self- Fashioning in Popular Visual Culture, Shromona Das 4. Rethinking Stereotypes: Embodiment of the Female Aging Self in Select Bengali films, Debashrita Dey 5. Exonerating Disruptive Mothers and Rebellious Daughters: New Discourses of Femininity in Shakuntala Devi and Tribhanga-Tedhi Medhi Crazy, Sanchari Basu Chaudhury Plenary Session-2 9:10-9:45p.m. -

Program in Comparative Literature
Program in Comparative Literature Course numbers, sections, times, and campus locations are listed below in the left margin. For more information see http://complit.rutgers.edu/academics/undergraduate/. COURSE DESCRIPTIONS – FALL 2019 195:101:01 Introduction to World Literature: Study of outstanding works of fiction, plays, and poems from European, CAC North and South American, African, Chinese, Japanese, Indian, and Middle-Eastern parts of the world through MW4 a different theme every semester. Focus on questions of culture, class, gender, colonialism, and on the role of 1:10-2:30pm translation. Fulfills SAS Core Requirement AHp. CA-A1 MU-212 HB- B5 195:101:90 Introduction to World Literature: Study of outstanding works of fiction, plays, and poems from European, Online North and South American, African, Chinese, Japanese, Indian, and Middle-Eastern parts of the world through TBA a different theme every semester. Focus on questions of culture, class, gender, colonialism, and on the role of translation. Hours by Arrangement. $100 Online Course Support Fee. Fulfills SAS Core Requirement AHp. 195:110:01 Heritage Speakers: More than half of the world’s population speaks or understands a minority language in CAC addition to the majority language. This course looks at the way they use and process each of those languages, M2 the effects bilingualism has on their mind, their culture and their place in society. This is a hybrid course that 9:50-11:10am requires completion of a substantial portion of the work online. The goals of the course are to analyze the FH-A1 degree to which the bilingual experience shape a person's perspectives on the world and the world’s Sanchez perspective on individuals; to examine what perspective bilingualism brings to human experience and cultural production; and to understand the nature of human languages and their speakers through the lens of bilingualism. -

Big Synergy and Phantom Films Enter Into an Alliance to Create a Content Production Powerhouse Across Tv and Digital Media
BIG SYNERGY AND PHANTOM FILMS ENTER INTO AN ALLIANCE TO CREATE A CONTENT PRODUCTION POWERHOUSE ACROSS TV AND DIGITAL MEDIA Mumbai, 1st July , 2016: Big Synergy Media and Phantom Films have forged an alliance to create a content production powerhouse, to deliver relevant and impactful entertainment content across TV and Digital Media. With the new alliance, both Big Synergy and Phantoms Films will benefit from each other’s core expertise to expand their businesses. Big Synergy will now have access to the tremendous creative talent resource of Phantom Films to expand their offering into the fiction segment for both TV and Digital Media. Phantom Films will build on Big Synergy’s well-established leadership in factual entertainment to expand their business in the TV and Digital Media. Phantom Films will also now have access to Big Synergy’s expertise and reach in production of regional language content across seven languages in the fiction & non-fiction space. BIG Synergy, promoted by Siddhartha Basu and Anita Kaul Basu, has built its reputation as a leader in the field of factual entertainment, starting off as one of the country's first independent television production houses in 1988. Big Synergy has since then been at the helm of producing some of the country’s most critically acclaimed and popular television programmes. Keeping abreast of constantly changing viewership and growth of regional markets, Big Synergy has incorporated top of the line technology and state-of the art techniques, creating content and programme ideas in sync with market demands across India. Phantom Films, established in 2011 by four prolific filmmakers , Anurag Kashyap, Vikas Bahl ,Vikramaditya Motwane and Madhu Mantena has earned a reputation for producing some of India’s most path breaking and engaging films in recent times. -

Automatically Generated PDF from Existing Images
Investor Presentation Q3 & 9M FY2015 Disclaimer Certain statements in this document may be forward-looking statements. Such forward- looking statements are subject to certain risks and uncertainties like government actions, local political or economic developments, technological risks, and many other factors that could cause its actual results to differ materially from those contemplated by the relevant forward-looking statements. Balaji Telefilms Limited (BTL) will not be in any way responsible for any action taken based on such statements and undertakes no obligation to publicly update these forward-looking statements to reflect subsequent events or circumstances. The content mentioned in the report are not to be used or re- produced anywhere without prior permission of BTL. 2 Table of Contents Financials 4 - 19 About Balaji Telefilms 20 - 21 Television 22 - 24 Motion Picture 25 - 29 3 Performance Overview – Q3 & 9M FY15 Financial & Operating Highlights Q3 & 9M FY15 (Standalone) Results for Q3 FY15 • Revenues stood at ` 57,27 lacs {` 37,80 lacs in Q3 FY14} • EBITDA is at ` 4,25 lacs {` 2,01 lacs in Q3 FY14} • Depreciation higher by ` 45,44 lacs due to revised schedule II • PAT is at ` 3,09 lacs {` 1,66 lacs in Q3 FY14} Contd…. 5 Financial & Operating Highlights Q3 & 9M FY15 (Standalone) Results for 9M FY15 • Revenues stood at ` 146,25 lacs {` 89,59 lacs in 9M FY14} • The Company has investments in Optically Convertible Debentures (OCD’s) in two Private Limited Companies aggregating ` 4,65.81 lacs. These investments are strategic and non-current (long-term) in nature. However, considering the current financial position of the respective investee companies, the Company, out of abundant caution, has, during the quarter provided for these investments considering the diminution in their respective values. -

The India Toy Fair Virtual-2021 27 Feb- 2 Mar-2021
THE INDIA TOY FAIR VIRTUAL-2021 27 FEB- 2 MAR-2021 1 THE INDIA TOY FAIR VIRTUAL-2021 27 FEB- 2 MAR-2021 PARTICIPANTS PROFILE 2Teeth Kidswear Address : 168, Arulandhanammalnagar, Pudukottai main Road, Thanjavur, Thanjavur - 613007 (TAMIL NADU) Contact Number : 8610225174, Email : [email protected] , Contact Person : Suganthan Product Category : Baby & Toddler Toys 3LININVOVATIONS Address : 448, BHARATHIYAR RD, PAPA NAICKENPALAYAM, COIMBATORE - 641037 (TAMIL NADU) Contact Number : 9791330359, Email : [email protected] , Contact Person : BALAJI Product Category : Action & Toy Figures 7 Star Toys Industrial Corportaion, Address : G1-1287, RIICO Industrial Area, Phase-V, Bhiwadi, Distt- Alwar, BHIWADI - 301019 (RAJASTHAN) Contact Number : 9873433143, Email : [email protected] , Contact Person : Mr MukulMehndiratta- Partner Product Category : Action & Toy Figures A K Enterprise Address : K 704 Maple Tree, B/s. Manichandra Bungalows, Nr. Surdhara Circle, Sal Hospital Road, Memnagar, Ahmedabad - (Gujarat) Contact Number : 9898812211, Email : [email protected], [email protected] , Contact Person : Kalpesh Bhatia Product Category : Bikes, Skates & Ride-Ons A STAR MARKETING PVT LTD Address : GALI NO 4, JAWAHAR COMPOUND 186, JAKARIA BUNDER RD, SHIWDI WEST, MUMBAI - 400015 (MAHARASHTRA) Contact Number : 9820644540, Email : [email protected] , Contact Person : DIPESH SAVLA Product Category : Action & Toy Figures A. JERALD SHOBAN Address : 29, Near Arul Theatre, Pookara Matha Kobil,Street, Tanjore- DCH - 613501 (TAMIL NADU) Contact Number : 9360936022, Email : [email protected] , Contact Person : A.Jerald Shoban Product Category : Traditional Toys 2 THE INDIA TOY FAIR VIRTUAL-2021 27 FEB- 2 MAR-2021 A2Z PAMTY DECCE PVT. LTD. Address : 25, 36 GOVIND NAGAR ,SODAULA LANE,BORAWALI EAST, MUMBAI - 400092 (MAHARASHTRA) Contact Number : 8104804075, Email : [email protected] , Contact Person : JAYESH M.