Navigation of Uncertain Terrain by Fusion of Information from Real and Synthetic Imagery Damian M
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Cognitive Approach to Vision for a Mobile Robot Paul Benjamin Pace University
Fordham University Masthead Logo DigitalResearch@Fordham Faculty Publications Robotics and Computer Vision Laboratory 4-2013 A Cognitive Approach to Vision for a Mobile Robot Paul Benjamin Pace University Christopher Funk Pace University Damian M. Lyons Fordham University Follow this and additional works at: https://fordham.bepress.com/frcv_facultypubs Part of the Robotics Commons Recommended Citation Benjamin, Paul; Funk, Christopher; and Lyons, Damian M., "A Cognitive Approach to Vision for a Mobile Robot" (2013). Faculty Publications. 34. https://fordham.bepress.com/frcv_facultypubs/34 This Article is brought to you for free and open access by the Robotics and Computer Vision Laboratory at DigitalResearch@Fordham. It has been accepted for inclusion in Faculty Publications by an authorized administrator of DigitalResearch@Fordham. For more information, please contact [email protected]. A Cognitive Approach to Vision for a Mobile Robot D. Paul Benjamin Christopher Funk Pace University, 1 Pace Plaza, New York, New York 10038, 212-346-1012 [email protected] Damian Lyons Fordham University, 340 JMH, 441 E. Fordham Rd., Bronx, NY 10458, 718-817-4485 [email protected] ABSTRACT We describe a cognitive vision system for a mobile robot. This system works in a manner similar to the human vision system, using saccadic, vergence and pursuit movements to extract information from visual input. At each fixation, the system builds a 3D model of a small region, combining information about distance, shape, texture and motion. These 3D models are embedded within an overall 3D model of the robot's environment. This approach turns the computer vision problem into a search problem, with the goal of constructing a physically realistic model of the entire environment. -

Saturday, May 7, 2016 One Pace Plaza, Pace University, New York
PACE UNIVERSITY PSYCHOLOGY CONFERENCE Saturday, May 7, 2016 One Pace Plaza, Pace University, New York, NY 10038 Spruce Street Entrance (Go up to first level B and turn left to the Conference Registration Table) http://www.pace.edu/dyson/psych-conference-2016 Sponsored by: a Pace University Dyson College of Arts and Sciences a Pace University NYC - Psychology Department a Confucius Institute at Pace University a Psi Chi (Pace University Chapter) a Office of Multicultural Affairs (Pace University) a APA Division 52 (International Psychology) a New York State Psychological Association § Academic Division a New York Academy of Sciences - Psychology Section a Manhattan Psychological Association a The John Templeton Foundation a The Social Cognition and Imagination Lab 24th Annual Pace University Psychology Conference page 1 PROGRAM 8:30am – 2:00pm Registration (Free; ID required) Level B (near Spruce Street entrance) 8:30am – 9:20am BREAKFAST and BEVERAGES Bianco Room 8:30am – 9:00am Poster Session I Set-up Schimmel Lobby (See pages 6-11 for assigned poster numbers.) 9:00am – 9:15am WELCOME ADDRESS Bianco Room Sonia Suchday, Ph.D. Chair, Psychology Department (NYC), Pace University 9:20 – 10:20pm POSTER SESSION I Schimmel Lobby (Posters should be set up no later than 9:00 am) 10:30 – 11:00pm Panel Discussion on Global Psychology Bianco Room 11:00 – 12:00pm KEYNOTE ADDRESS: Dr. Michael Cunningham Bianco Room TITLE: “Old issues and new directions for adolescent development” Conferral of the FLORENCE L. DENMARK Award 12:00pm – 1:10pm Poster Session -

Powerpoint Slides
1 2 3 4 5 NYSAC Thanks our Workshop Sponsor: Higher Education in the Age of Covid-19 A Presentation for the New York State Association of Counties Mary Beth Labate, CICU President October 1, 2020 Adelphi University • Albany College of Pharmacy and Health Sciences • Albany Law School • Albany Medical College • Alfred University • American Academy McAllister Institute • American Museum of Natural History, Richard Gilder Graduate School • Bank Street College of Education • Bard College • Barnard College • The Belanger School of Nursing • Boricua College • Brooklyn Law School • Canisius College • Cazenovia College • Clarkson University • Cochran School of Nursing • Cold Spring Harbor Laboratory, Watson School of Biological Sciences • Colgate University • College of Mount Saint Vincent • The College of New Rochelle • The College of Saint Rose • Columbia University • Concordia College • The Cooper Union for the Advancement of Science and Art • Cornell University • The Culinary Institute of America • Daemen College • Dominican College • D’Youville College • Elmira College • Excelsior College • Fei Tian College • Finger Lakes Health College of Nursing • Fordham University • Hamilton College • Hartwick College • Helene Fuld College of Nursing • Hilbert College • Hobart and William Smith Colleges • Hofstra University • Houghton College • Iona College100+ • Ithaca College private, • The Jewish Theological Seminarynot • Keuka-for College- • Theprofit King’s College • Le Moyne College • Long Island University • Manhattan College • Manhattan School -
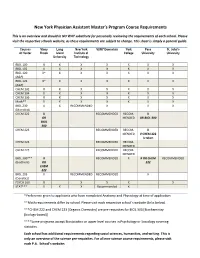
New York Physician Assistant Master's Program Course Requirements
New York Physician Assistant Master’s Program Course Requirements This is an overview and should in NO WAY substitute for personally reviewing the requirements of each school. Please visit the respective schools website, as these requirements are subject to change. This sheet is simply a general guide. Courses Stony Long New York SUNY Downstate York Pace St. John’s At Hunter Brook Island Institute of College University University University Technology BIOL 100 X X X X X X X BIOL 102 X X X X X X X BIOL 120 X* X X X X X X (A&P) BIOL 122 X* X X X X X X (A&P) CHEM 102 X X X X X X X CHEM 104 X X X X X X X CHEM 106 X X X X X X X Math** X X X X X X X BIOL 230 X X RECOMMENDED X X X (MicroBiol) CHEM 222 X RECOMMENDED RECOM- X OR MENDED OR BIOL 300 BIOL 300 CHEM 223 RECOMMENDED RECOM- X MENDED if CHEM 222 is taken CHEM 224 RECOMMENDED RECOM- MENDED CHEM 225 RECOMMENDED RECOM- MENDED BIOL 300*** X RECOMMENDED X X OR CHEM RECOMMENDED (BioChem) OR 222 CHEM 222 BIOL 203 X RECOMMENDED RECOMMENDED X (Genetics) PSYCH 100 X X X X X STAT*** X X X Recommended X *Preference given to applicants who have completed Anatomy and Physiology at time of application **Math requirements differ by school. Please visit each respective school’s website (links below). ***CHEM 222 and CHEM 223 [Organic Chemistry] are pre-requisites for BIOL 300 [Biochemistry (biology-based)] ****Some programs accept Biostatistics or upper level courses in Psychology or Sociology covering statistics. -

Programs in Occupational Therapy 2020-2021
Columbia University Bulletin The Faculty of Medicine Programs in Occupational Therapy 2020-2021 To communicate with the Program ADDRESS INQUIRIES TO: Columbia University Programs in Occupational Therapy Georgian Building th rd 617 West 168 Street, 3 floor New York, NY 10032 TELEPHONE: 212-305-5267 FAX: 212-305-4569 EMAIL: [email protected] Limitations of Bulletin This bulletin is intended to provide information to guide Columbia University students. While every effort has been made to ensure the accuracy of the information contained herein, accuracy cannot be absolutely guaranteed, and anyone who needs to rely on any particular matter is advised to verify it independently. The contents of this bulletin are subject to change, and the Programs reserve the right to depart without notice from any policy or procedure referred to in this bulletin, or to revise and amend this bulletin in whole or in part at any time. This bulletin is not intended to and should not be regarded as a contract between the University and any student or other person. 1 TABLE OF CONTENTS ADMINISTRATION AND FACULTY 4 PROGRAMS IN OCCUPATIONAL THERAPY 8 COLUMBIA UNIVERSITY IRVING MEDICAL CENTER 8 HISTORY 8 OCCUPATIONAL THERAPY 9 ADMISSION PROCEDURES 11 ACCEPTANCE FEE 11 HEALTH EXAMINATION AND LIABILITY 11 INTERNATIONAL STUDENTS 12 MASTER OF SCIENCE DEGREE (ENTRY-LEVEL) 12 NATIONAL ASSOCIATION AND ACCREDITATION 13 CERTIFICATION AND LICENSURE 13 ADMISSION REQUIREMENTS AND PROCEDURES 14 ARTICULATION (3-2) PROGRAMS 15 TRANSFER POLICY 15 DEGREE REQUIREMENTS -

Pace University, Pleasantville and New York, New York and Rockland Community College, Suffern,New York
Dual Admission Agreement Pace University, Pleasantville and New York, New York And Rockland Community College, Suffern,New York Effective July 2020 Pace University, a New York State not-for-profit education corporation ("Pace" or the "University") and Rockland Community College ("RCC" or the "College") hereby enter into the following agreement governing the matriculation of College students at the University's Baccalaureate Program. WHEREAS, the College and the University wish to collaborate to ensure degree completion and to facilitate the transferprocess through joint advising and recruitment, NOW, THEREFORE, in consideration of the foregoingpremises, and of other good and valuable consideration, the exchange, receipt, and adequacy ofwhich are hereby acknowledged, the College and the University hereby covenant and agree as follows: Admission and Guaranteed Acceptance: 1. Students ofthe College who complete the Associate ofArts (A.A.), Associate ofScience (A.S.) or Associate ofApplied Science (A.A.S.) degree with a minimum Gradefoint Average of2.50 shall be guaranteedacceptance to the University and shall transferwith Junior standing. 2. Students admitted to Pace andwho elect to matriculate at RCC beforehandmust sign an RCC- Pace Intent to Enroll Form. Such students shall have dual admission tb both RCC and Pace upon completion of the Intent to EnrollForm. 3. Applicants to Pace who do not meet the University'srequirements for a?mission must sign an RCC-Pace Intent to Enroll Form if they plan to transferto Pace afterearning an RCC associate degree. Upon completion of the Intent to Enroll they shall have dual admission to both RCC and Pace. 4. In all events matriculated students at RCC who intend to transfer to Pace must complete an RCC-Pace Intent to Enroll Formprior to the completion of thirty (30) credits at RCC. -

School Profile 2020-21
School Profile 2020-21 Mr David Tongue, [email protected] Principal Mr Paul Ryan, [email protected] Head of Senior School Ms Helen Andrew, [email protected] IB Coordinator , [email protected] Ms Sarah Cassell CEEB Code: 748560 Director of University Guidance, Careers and Alumni IB School Code: 000817 1958 910 84 37 Year Founded Students Enrolled Nationalities Represented Average IB Score (2020) St George’s British International School is one ACCREDITATION of the leading British-curriculum schools in St George’s is accredited by ISI and is a member of continental Europe, educating children from COBIS, ECIS, CIS and HMC, an exclusive group of ages 3 to 18. It is an inclusive, non-selective private schools in Britain and overseas. St George’s school supporting pupils of all abilities. It offers a has been an IB World School since 1996. broad and rigorous academic programme, a range of co-curricular activities and a strong pastoral system that looks to develop all facets of each pupil’s personality so that they can take their place in the world as confident, caring and ambitious individuals. Founded in 1958 as the original British international school in Rome, the main campus is a spacious 14-acre site in the north-west of the city, with a further Junior School campus located close to the Vatican in central Rome. ENROLMENT The pupils at St George’s represent 84 nationalities. The annual graduating cohort is typically 75 students. An average class size for students in the IB Diploma Programme is 14. -

University Wide Common Data Set 2020-2021 (PDF)
Common Data Set 2020-2021 A. General Information A0 Respondent Information (Not for Publication) Name: Evelyn Krivorotova Title: Institutional Research Analyst Office: OPAIR Mailing Address: 100 Summit Lake Drive 3rd Floor City/State/Zip/Country: Valhalla, NY 10595 Phone: 9149232633 Fax: E-mail Address: [email protected] Are your responses to the CDS posted for x Yes reference on your institution's Web site? No If yes, please provide the URL of the corresponding Web page: https://www.pace.edu/administration/strategic-initiatives/opair/university-facts-and-figures A0A We invite you to indicate if there are items on the CDS for which you cannot use the requested analytic convention, cannot provide data for the cohort requested, whose methodology is unclear, or about which you have questions or comments in general. This information will not be published but will help the publishers further refine CDS items. A1 Address Information Name of College/University: Pace University Mailing Address: One Pace Plaza City/State/Zip/Country: New York, NY 10038 Street Address (if different): City/State/Zip/Country: Main Phone Number: 866-722-3338 WWW Home Page Address: www.pace.edu Admissions Phone Number: 212-346-1323 Admissions Toll-Free Phone Number: 800-874-7223 Admissions Office Mailing Address: One Pace Plaza City/State/Zip/Country: New York, NY 10038 Admissions Fax Number: 212-346-1040 Admissions E-mail Address: [email protected] If there is a separate URL for your school’s online application, please specify: https://admission.pace.edu/apply/ If you have a mailing address other than the above to which applications should be sent, please provide: 861 Bedford Road, Pleasantville, NY 10570-2799 A2 Source of institutional control (Check only one): Public x Private (nonprofit) Proprietary A3 Classify your undergraduate institution: x Coeducational college Men's college Women's college A4 Academic year calendar: x Semester If your academic year has changed because of the Quarter COVID-19 pandemic, please indicate as other Trimester below. -

Ibm Launch Accelerator
THE COLUMBIA | IBM LAUNCH ACCELERATOR Information Session October 2020 Agenda Introductions Background on the partnership between Columbia University and IBM • The Columbia | IBM Center for Blockchain and Data Transparency • Launch Accelerator Program Launch Program Overview • Eligibility & expectations • Benefits • Structure • Timeline Q&A Agenda Introductions Background on the partnership between Columbia University and IBM • The Columbia | IBM Center for Blockchain and Data Transparency • Launch Accelerator Program Launch Program Overview • Eligibility & expectations • Benefits • Structure • Timeline Q&A Columbia Lab-to-Market Accelerator Network (L2M): Breakthrough Inventions Life-Saving and Life-Improving Products Life Sciences Physical Sciences & Engineering TBD? 9 cycles 6 cycles 4 cycles 3 cycles 1 cycle Columbia-BBI Alliance 2 cycles Launch Accelerator (Data,BC, Deep Tech) 4 cycles Takeda-Columbia-NYU Alliance 1 cycle COMBINE Deerfield HHI Alliance 5 cycles 1 cycle 984 applications 376 teams through programs 212 cash awards totaling $15.9M 40+ commercial launches $152M in external follow-on funding raised by those teams* * last updated Aug 2020 It Takes a (digital) village Core team Jack Steele Dmytro Pokhylko Carter Schmitt Program Manager, Program Administrator, Director, Columbia L2M Columbia L2M Columbia L2M Agenda Introductions Background on the partnership between Columbia University and IBM • The Columbia | IBM Center for Blockchain and Data Transparency • Launch Accelerator Program Launch Program Overview • Eligibility & expectations • Benefits • Structure • Timeline Q&A Columbia University and IBM are partnering on blockchain, data transparency, big data, AI/ML, cybersecurity and related fields in deep tech Columbia University and IBM announced a new Center devoted to research, education, and innovation in blockchain technology and data transparency. -

CATHOLIC Guide/2019
September 12, 2019 CATHOLIC NEW YORK 15 SEEKING KNOWLEDGE—Ryan Jaquez, a member of the Class of 2019 at St. Raymond High School for Boys in the Bronx, raises his hand during the school’s Guidance Day last October. Ryan is now a freshman at Brown University in Providence, R.I. CATHOLIC Finding the Right School high school For Every Student Short profi les including pertinent information about each of the 44 Catholic high schools in the archdiocese are contained on the inside pages of this pullout section. Compiled data on course offerings, clubs and activities, athletic programs, guide/2019 tuition costs and open house dates will give your family a good start on making the right choice for your student. The schools represented range geographically from Staten Island to Dutchess County as well as many points in between. PHOTO COURTESY OF LIFETOUCH 16 CATHOLIC NEW YORK September 12, 2019 September 12, 2019 CATHOLIC NEW YORK 17 Maria r. Bastone clt ASS Ac S—the choir of John F. Kennedy Catholic High school in somers, under the direction of ines Wilhelm-Boston, raises their voices in song april 4 at the Mass for the Class of 2019 at st. Patrick’s Cathedral. Cardinal Dolan offered the Mass for graduating seniors from Catholic high schools across the archdiocese. tary schools. The sports program includes basketball, and the new AP Capstone Research Program. Bronx softball, step, volleyball and cheerleading. Students can take special courses from the Gilder AcAdemy of mount St. urSulA Enrollment: 325; 100 percent of graduates are ac- Lehrman School of American History and Gilder Founded by the Ursuline Sisters in 1855, the Acad- cepted into college and 99 percent attend. -

Summer 2020 Newsletter (PDF)
4• ! nner -city scholarship fund A Child. A Chance. A Future. Newsletter of Inner-City Scholarship Fund | Summer 2020 INNER-CITY CELEBRATES THE CLASS OF 2020 CONTENTS This June marked the end of a unique school 73% of the students at Inner-City year, abruptly changed midway through for supported Catholic schools live near or students across the country. Especially below the poverty line, and 53% are raised COVER STORY 1 hard hit were seniors, who found many of by a single parent, but 99% graduate and the milestones that they had spent years 98% are accepted to college. MESSAGE FROM THE working toward suddenly taken away, EXECUTIVE DIRECTOR 2 and were forced to make one of the most This fall, Catholic high school graduates important decisions of their young lives in will attend some of the most prestigious VIRTUAL GALA 3 a time of great uncertainty. colleges and universities across the nation, including Howard University, In light of all this, Inner-City Scholarship Fund Syracuse University, the University of IN THE NEWS 4-5 commends the class of 2020 all the more. Notre Dame, and Yale University. Inner-City They have spent their lives overcoming congratulates all the members of the INNER-CITY obstacles, and their perseverance in the face class of 2020, and wishes them the best FAMILY ALBUM 6-7 of unprecedented changes is a testament to in college and beyond. their resilience and to the Catholic schools FRIENDS OF where they have learned so much. To learn more about the class of 2020 INNER-CITY 8-9 please visit page 11. -

International Students & Scholars
Spring 2021 International Students & Scholars F1 students Pre-Arrival Guide New York City Campus 1 Congratulations on your acceptance to Pace University! This pre-arrival orientation is designed to help you prepare for your journey and your future as a student of Pace University. It will answer questions about what to do before you leave your home country for the U.S., and what you can expect when you arrive. New International Student Orientation will be held on January 11, 2021 via Zoom. Zoom details (link and password) will be provided on our website. We hope that we will see you all on campus for the spring 2021 semester; however, given the uncertainty with the current travel bans and suspended visa services due to Covid-19, we understand that not everyone will be able to join us physically on campus. Whether you are able to join us in NYC or will be attending classes remotely from your home countries, we will continue to keep in touch with you during the spring semester. We hope that you and your families stay safe and healthy during these challenging times. PACE UNIVERSITY NEW YORK PRE-ARRIVAL GUIDE FOR INTERNATIONAL STUDENTS Page Contents 2 Before You Arrive & NYC Campus Map 3 Entry into the United States 5 Arriving in the U.S. 5 Getting to Your Destination 6 International Student Immigration Sessions and Orientations 6 International Student Mandatory Check-In 7 International Buddy Program 7 Connect with us on Social Media 8 The New York City Campus 10 Money & Banking 11 New York, NY 12 Weather: Four Seasons of Fun! 12 In Closing…