Routing Algorithms 363
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
View Document
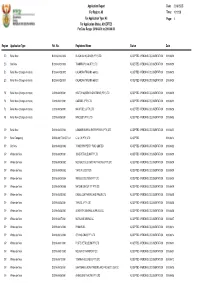
Application Report Date: 2016/05/05 For Region: All Time: 10:19:28 For Application Type: All Page: 1 For Application Status: ACCEPTED For Date Range: 2016/04/01 to 2016/04/30 Region Application Type Ref. No. Registered Name Status Date EC Retail New B/2016/04/20/0002 BLACK OIL HOLDINGS (PTY) LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/20 EC Site New B/2016/04/20/0001 TRAKPROPS 146 (PTY) LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/20 EC Retail New (Change-of-Hands) B/2016/04/25/0002 CALANDRA TRADING 669 CC ACCEPTED - PENDING DOCUMENTATION 2016/04/25 EC Retail New (Change-of-Hands) B/2016/04/25/0001 CALANDRA TRADING 669 CC ACCEPTED - PENDING DOCUMENTATION 2016/04/25 FS Retail New (Change-of-Hands) C/2016/04/29/0001 HECTOR AUSTIN ENGINEERING (PTY) LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/29 FS Retail New (Change-of-Hands) C/2016/04/21/0001 DAIZEBEL (PTY) LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/21 FS Retail New (Change-of-Hands) C/2016/04/26/0001 MAJA FUELS (PTY) LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/26 FS Retail New (Change-of-Hands) C/2016/04/08/0001 MINOZEST (PTY) LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/08 GP Retail New D/2016/04/22/0003 LAMANI BUSINESS ENTERPRISES (PTY) LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/22 GP Retail Temporary D/2006/08/17/0015/T16/1 CJ & CK (PTY) LTD ACCEPTED 2016/04/14 GP Site New D/2016/04/22/0002 TOWER PROPERTY FUND LIMITED ACCEPTED - PENDING DOCUMENTATION 2016/04/22 GP Wholesale New D/2016/04/29/0001 JUNE PETROLEUM PTY LTD ACCEPTED - PENDING DOCUMENTATION 2016/04/29 GP Wholesale New -
System/370 Model 145 Reference Summary
System/370 Model 145 Reference Summary S229-2239-1 IBM Corporation, Field Support Documentation, Dept 927, Rochester, Minnesota 55901 PREFACE This publication is primarily intended for customer engineers servicing System/370 Model 145. Second Edition (September 1972) This is a major revision of, and makes 8229-2239-0 obsolete. Address any comments concerning the contents of this publication to: IBM, Field Support Documentation, Dept 927, Rochester, Minnesota 55901 © International Business Machines Corporation 1972 CONTENTS Section 1 - Control Words Branch and Module Switch Word "O" . 1. 1 Branch Word . 1.2 GA Function Charts . 1.3 GA Function Charts . 1.4 GA Function Charts . 1.5 Branch and Link or Return Word . 1.6 Word Move Word Version"O" . 1. 7 Word Move Word Version "1" . 1.8 Storage Word, Non K-Addressable . 1.9 Storage Word, K-Addressable . 1.10 Arithmetic Word 10 Byte Version 1.11 Arithmetic Word, Fullword Version 1.12 Arithmetic Word, 11 Direct ByteVersion . 1.13 Arithmetic Word, 10/11 Indirect Byte Version . 1.14 ALU Entry Gating 1.15 Stat Set Symbols . 1.15 BranchSymbols . 1.15 Arithmetic Word Chart Selection 1.16 Address Formation Chart 1.16 Control Word Chart Selection 1.16 Section 2 - CPU 3145 CPU Data Flow . 2.1 I-Cycles Data Flow . 2.2 I-Cycles . 2.3 PSW Locations . 2.3 Expanded Local Storage . 2.3 I-Cycles . 2.3 I-Cycles Control Line Generation . 2.4 Control Word . 2.4 Control Register Decode . 2.4 iii ECCL Board Layout ............ 2.5 Data Bit Location Chart .......... 2.5 Common Test Points ........... -
![ILK]: Driver Should Make Sure the First 3D Command After the Engine Switch from BLT Not to Be 1](https://docslib.b-cdn.net/cover/0297/ilk-driver-should-make-sure-the-first-3d-command-after-the-engine-switch-from-blt-not-to-be-1-330297.webp)
ILK]: Driver Should Make Sure the First 3D Command After the Engine Switch from BLT Not to Be 1
Intel® OpenSource HD Graphics PRM Volume 1 Part 5: Graphics Core - Blitter Engine For the all new 2010 Intel Core Processor Family Programmer’s Reference Manual (PRM) March 2010 Revision 1.0 Doc Ref #: IHD_OS_V1Pt5_3_10 Creative Commons License You are free: to Share — to copy, distribute, display, and perform the work Under the following conditions: Attribution. You must attribute the work in the manner specified by the author or licensor (but not in any way that suggests that they endorse you or your use of the work). No Derivative Works. You may not alter, transform, or build upon this work. INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL’S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Sandy Bridge chipset family, Havendale/Auburndale chipset family, Intel® 965 Express Chipset Family, Intel® G35 Express Chipset, and Intel® 965GMx Chipset Mobile Family Graphics Controller may contain design defects or errors known as errata which may cause the product to deviate from published specifications. -

The New Tourism Lexicon: Rewriting Our Industry's Narrative
POLICY BRIEF THE NEW TOURISM LEXICON: REWRITING OUR INDUSTRY'S NARRATIVE Last year, Destinations International released a policy "Washington is the problem. Remind voters again and brief entitled, “Advocacy in the Face of Ideology,” which again about Washington spending, Washington waste, made the case that relying on ROI numbers to defend Washington taxation, Washington bureaucracy, the value and relevancy of a destination organization Washington rules and Washington regulations." was no longer a viable advocacy strategy. Instead, we Luntz also suggested replacing "drilling for oil" with argued, destination organizations need to support the "exploring for energy," "undocumented workers" with message of ROI in terms of dollars and cents with an "illegal aliens," and "estate tax" with "death tax." The ideological and value-based appeal to convince political substitutions often work — an Ipsos/NPR poll found that leaders that without a destination organization, these support for abolishing the estate tax jumps to 76% from returns will inevitably vanish. 65% when you call it the death tax. Our industry has unfortunately fallen for what George Lakoff, a professor of Cognitive Science and Linguistics at the University of California at Berkeley, dubs the “Enlightenment Fallacy.” According to this viewpoint, you simply need to tell people the facts in clear language and they’ll reason to the right, true conclusions. The problem, as Lakoff puts it is, “The cognitive and brain sciences have shown this is false… it’s false in every single detail.” The reality is that people tend to frame political arguments, and the facts behind them, in terms of their own values. -

Advanced Ipv6 Security in the LAN Gilles Roy, Technical Leader BRKSEC-3003 in 2015, 55% of Attacks Are from the Inside! *
Advanced IPv6 Security in the LAN Gilles Roy, Technical Leader BRKSEC-3003 In 2015, 55% of attacks are from the inside! * Source: 2015 IBM Cyber Security Report 3 There is a lot happening on the LAN, it can be difficult to follow everything, lets break it down. 1. Operations 2. Attacks 3. Mitigations 4. Use cases 4 Use cases Enterprise SP Access Datacenter Address Allocation ✔ ✖ ✖ Duplicate Address Detection ✔ ✔ ✔ Address Resolution ✔ ✖ ✔ Operation Neighbor Unreachability Detection ✔ ✖ ✔ Prefix Allocation ✖ ✔ ✖ Making Default Router Discovery ✔ ✖ ✔ sense of Denial of Link Operations ✔ ✖ ✔ Denial of Address Resolution ✔ ✖ ✔ YOUR Router Theft ✔ ✔ ✔ Attacks Address Theft ✔ ✖ ✔ setup. Denial of Address Configuration ✔ ✔ ✖ Denial of Address Assignment ✔ ✖ ✖ RA Guard ✔ ✔ ✔ DHCP Guard ✔ ✔ ✖ Mitigation Source Guard ✔ ✖ ✔ Destination Guard ✔ ✖ ✖ Binding Guard ✔ ✖ ✔ 5 Abstract summary and pre-requisite • This session focuses on IPv6 security within the layer-2 domain • With a multi-dimensional approach: operations, vulnerabilities, mitigations and use-cases • It introduces security features at the First Hop, such RA Guard, Source Guard, Destination guard, etc • Requirements: Knowledge of IPv6 and IPv6 Neighbor Discovery 6 Agenda • IPv6 in the layer-2 domain: operations and protocols • IPv6 in the layer-2 domain: vulnerabilities • Attack Demonstration • Mitigating Vulnerabilities • Use cases overview 7 Some background on layer-2 & IPv6 • Layer-2: what is it? • Layer-2 domain: also “broadcast domain”, link, lan, vlan, segment • Nodes: hosts, routers, -

The (Many) Paths to “Destination X”
Blog The (many) paths to “Destination X” Michelle Batten Head of Global Marketing, Mobile Division, Amadeus According to Amadeus’ new whitepaper, Better travel in the Live Travel Space “Get ready for Destination X,” today’s travel sellers have a golden opportunity to Destination X also offers enormous tap into destination services, a growing untapped potential to market and sell marketplace set to reach $183 billion by ancillary destination services to travelers. 2020. Drawing on survey results from It’s a place where travel agents, corporate more than a thousand CheckMyTrip by travel programs, and other providers of Amadeus mobile app users, the research flights, hotels and cars can continue identifies emerging trends about business servicing travelers at their final destination. and leisure travelers destined for Whether traveling on business, leisure or Destination X, one of the most important bleisure, mobile provides the perfect revenue-generating stops on a traveler’s platform to offer these destination services journey. on the move. Take me to travel nirvana Amadeus is helping travel providers better understand and address these challenges The Amadeus research poses questions and opportunities. Using the Amadeus such as, “Are travelers prepared as they Travel Platform, the Live Travel Space arrive to Destination X?” Are their needs aggregates all content into one platform, for add-on destination services like airport making it easier for travel sellers to find transfers, local activities and restaurant what they need, and provide the level of reservations being met? The paper personalization their travelers demand. explores eight trends regarding the challenges and opportunities travel sellers Are you ready to service customers more face in the post-booking ancillary game fully when they reach Destination X? and how you can win travelers trust in Download the whitepaper today at that arena. -

Towards Coordinated, Network-Wide Traffic
Towards Coordinated, Network-Wide Traffic Monitoring for Early Detection of DDoS Flooding Attacks by Saman Taghavi Zargar B.Sc., Computer Engineering (Software Engineering), Azad University of Mashhad, 2004 M.Sc., Computer Engineering (Software Engineering), Ferdowsi University of Mashhad, 2007 Submitted to the Graduate Faculty of the School of Information Sciences in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Pittsburgh 2014 UNIVERSITY OF PITTSBURGH SCHOOL OF INFORMATION SCIENCES This dissertation was presented by Saman Taghavi Zargar It was defended on June 3, 2014 and approved by James Joshi, Ph.D., Associate Professor, School of Information Sciences David Tipper, Ph.D., Associate Professor, School of Information Sciences Prashant Krishnamurthy, Ph.D., Associate Professor, School of Information Sciences Konstantinos Pelechrinis, Ph.D., Assistant Professor, School of Information Sciences Yi Qian, Ph.D., Associate Professor, College of Engineering, Dissertation Advisors: James Joshi, Ph.D., Associate Professor, School of Information Sciences, David Tipper, Ph.D., Associate Professor, School of Information Sciences ii Copyright c by Saman Taghavi Zargar 2014 iii Towards Coordinated, Network-Wide Traffic Monitoring for Early Detection of DDoS Flooding Attacks Saman Taghavi Zargar, PhD University of Pittsburgh, 2014 DDoS flooding attacks are one of the biggest concerns for security professionals and they are typically explicit attempts to disrupt legitimate users' access to services. Developing a com- prehensive defense mechanism against such attacks requires a comprehensive understanding of the problem and the techniques that have been used thus far in preventing, detecting, and responding to various such attacks. In this thesis, we dig into the problem of DDoS flooding attacks from four directions: (1) We study the origin of these attacks, their variations, and various existing defense mecha- nisms against them. -

Socomo Marketing for Travel and Tourism: Empowering Co-Creation of Value
Journal of Destination Marketing & Management 4 (2015) 151–161 Contents lists available at ScienceDirect Journal of Destination Marketing & Management journal homepage: www.elsevier.com/locate/jdmm SoCoMo marketing for travel and tourism: Empowering co-creation of value Dimitrios Buhalis n, Marie Foerste School of Tourism Bournemouth University, United Kingdom article info abstract Article history: Advanced technology enables users to amalgamate information from various sources on their mobile Received 18 June 2014 devices, personalise their profile through applications and social networks, as well as interact Accepted 6 April 2015 dynamically with their context. Context-based marketing uses information and communication Available online 5 May 2015 technologies (ICTs) that recognise the physical environment of their users. Tourism marketers are Keywords: increasingly becoming aware of those cutting-edge ICTs that provide tools to respond more accurately to Personalisation the context within and around their users. This paper connects the different concepts of context-based Mobile context-awareness marketing, social media and personalisation, as well as mobile devices. It proposes social context mobile Social media marketing (SoCoMo) marketing as a new framework that enables marketers to increase value for all stakeholders at Mobile technologies the destination. Contextual information is increasingly relevant, as big data collected by a wide range of Co-creation sensors in a smart destination provide real-time information that can influence the tourist experience. SoCoMo marketing introduces a new paradigm for travel and tourism. It enables tourism organisations and destinations to revolutionise their offering and to co-create products and services dynamically with their consumers. The proposed SoCoMo conceptual model explores the emerging opportunities and challenges for all stakeholders. -

A Key-Based Routing System for P4-Programmable Networks
electronics Article P4-KBR: A Key-Based Routing System for P4-Programmable Networks Pilar Manzanares-Lopez * , Juan Pedro Muñoz-Gea and Josemaria Malgosa-Sanahuja Department of Information Technologies and Communications, Universidad Politecnica de Cartagena, E-30202 Cartagena, Spain; [email protected] (J.P.M.-G.); [email protected] (J.M.-S.) * Correspondence: [email protected]; Tel.: +34-968-326534 Abstract: Software-defined networking (SDN) architecture has provided well-known advantages in terms of network programmability, initially offering a standard, open, and vendor-agnostic interface (e.g., OpenFlow) to instruct the forwarding behavior of network devices from different vendors. However, in the last few years, data plane programmability has emerged as a promising approach to extend the network management allowing the definition and programming of customized and non-standardized protocols, as well as specific packet processing pipelines. In this paper, we propose an in-network key-based routing protocol called P4-KBR, in which end-points (hosts, contents or services) are identified by virtual identifiers (keys) instead of IP addresses, and where P4 network elements are programmed to be able to route the packets adequately. The proposal was implemented and evaluated using bmv2 P4 switches, verifying how data plane programmability offers a powerful tool to overcome continuing challenges that appear in SDN networks. Keywords: P4; routing; KBR; SDN Citation: Manzanares-Lopez, P.; Muñoz-Gea, J.P.; Malgosa-Sanahuja, J. 1. Introduction P4-KBR: A Key-Based Routing The idea of decoupling end-points (hosts, contents or services) from network ad- System for P4-Programmable dresses has been demanded in the last few years to provide support to enhanced services Networks. -

Mbr Crew Take a Week at Destination X
f e at u r e marks the spot ‘Destination X’ is a mountain bike holiday promising the best of natural Alpine singletrack — but would an epic hut-to-hut challenge prove a little too much of a good thing? Words: Ben Smith Photos: Roo Fowler 78 mbr april 2014 april 2014 mbr 79 hat goes up refuge adventure. Our guide, Oli, explained that f e at u r e must come it would be a challenge and a totally different down. that was experience from our trip thus far — there would the mantra that be less of the perfect singletrack we’d been riding, was repeating more uphill grind and a healthy dose of carrying, itself in my brain but that would be balanced by an sense of real as my aching legs/ remoteness, with stunning views and a huge back/arms/neck sense of achievement. Most of the group politely struggled their declined, but for the eight of us who were ‘in’, a way slowly up yet sense of nervous excitement started to take over. another almost- the next day we were up and away early. With sheer rock face, our trailpacks stuffed to bursting with food and cleated shoes slipping fresh kit we were on the first bus out of town for and sliding on smooth rock, 30lb of mountain the only bit of assisted climbing for two days. bike balanced precariously across my back, sweat from the nearby town of les Saises we hit a fire- pouring off my face. Mountain biking is meant to road climb that dragged us away from civilisation. -

Does Migration Destination Affect the Mortality Advantage of Mexican Immigrants? a Comparison of Traditional, New, and Emerging Destinations
Does Migration Destination Affect the Mortality Advantage of Mexican Immigrants? A comparison of Traditional, New, and Emerging Destinations Andrew Fenelon1 1National Center for Health Statistics, 3311 Toledo Road, Hyattsville, MD 20782 Abstract Health declines for immigrants with greater exposure to the United States, but the specific characteristics of the migration and assimilation processes that contribute to this pattern are less clear. As the Mexican population in the US has grown, it has expanded outside traditional gateways in California and Texas to new destinations throughout the US. This study examines the mortality of Mexican immigrants in Traditional versus New and Emerging destinations in the US. Using National Health Interview Survey data between 1989 and 2009 the analysis finds that Mexican immigrants in New and Emerging destinations have a significant survival advantage over their counterparts in traditional established destinations. This advantage may reflect selective migration to new destinations, superior employment prospects, or slower behavioral assimilation. US-born Mexicans do not benefit from this advantage. The results suggest that the spatial characteristics of the assimilation process are important when considering the health of immigrants. Introduction The Hispanic mortality advantage refers to the finding that the Hispanic-origin population in the United States experiences lower adult mortality rates than the non-Hispanic white population, despite lower average socioeconomic status among Hispanics. The “Hispanic Paradox” calls attention to the fact that Hispanics resemble African-Americans in terms of socioeconomic indicators but non-Hispanic whites in health and mortality indicators (Hummer, et al., 2000, Markides and Eschbach, 2011). In many studies, Hispanics exhibit higher life expectancy than non-Hispanic whites, as well as more favorable profiles with respect to non-fatal conditions such as cancer incidence and severity, heart disease, and hypertension (Eschbach, et al., 2005, Singh and Siahpush, 2002). -

Strategic Communication in Tourism
STRATEGIC COMMUNICATION IN TOURISM DEPARTMENT OF DESIGN AND COMMUNICATION CENTRE FOR TOURISM, INNOVATION AND CULTURE (TIC) Bodil Stilling Blichfeldt Strategic Communication in Tourism Background, conceptualizations, introduction to analysis and relations to sustainable tourism and tourism innovation TIC TALKS no. 5, September 2017 1 Author info Associate Professor, Ph.D. Bodil Stilling Blichfeldt, TIC and Department of Design and Communication, University of Southern Denmark. Email: [email protected] Place of publication TIC is University of Southern Denmark’s multidisciplinary research center in tourism, innovation and culture. The center is located at the Kolding campus. TIC strives to transform the university to an engaged, collaborative institution where academics and students pursue an unrelenting examination of knowledge, its sources and its uses. TIC defines the university as a center for higher order knowledge creation and for collaboration with, and for, society at large. We do this through research-based education, education-based research and collaborative engagement with society. We aim to charter new territory in international academe, as well as in multi-level collaboration based on interdisciplinary research with a strong foundation in the Humanities. TIC engages in research dialogues through both a traditional peer-review publication strategy and through involvement in securing free access to knowledge. Supplementing traditional journal articles, TIC TALKS is one of TIC’s contributions to open access sharing and collaborative development of knowledge. TIC TALKS are provided by Centre for Tourism, Innovation and Culture, University of Southern Denmark Universitetsparken 1, Kolding, DK-6000 http://www.sdu.dk/en/Om_SDU/Institutter_centre/C_Tik.aspx The present manuscript qualifies as unfinished work-in-progress and the reader should bear in mind that the manuscript is quite likely to contain a series of errors, flaws and weaknesses.