K236: Basis of Data Analytics Lecture 7: Classification and Prediction Decision Tree Induction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
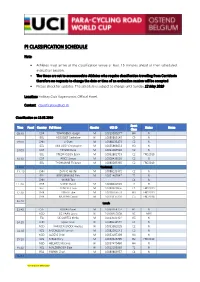
Pi Classification Schedule
PI CLASSIFICATION SCHEDULE Note: • Athletes must arrive at the classification venue at least 15 minutes ahead of their scheduled evaluation session. • The times are set to accommodate Athletes who require classification travelling from Corridonia therefore no requests to change the date or time of an evaluation session will be accepted. • Please check for updates. The schedule is subject to change until Sunday 12 May 2019 Location: Holiday Club Vayamundo, Official Hotel. Contact: [email protected] Classification on 13.05.2019 Sport Time Panel Country Full Name Gender UCI ID Status Notes Class 08:30 GBR TOWNSEND Joseph M 10019380277 H4 N BEL HOSSELET Catheline W 10089809149 C5 N 09:00 CHN LI Shan M 10088133473 C2 N BEL VAN LOOY Christophe M 10055886633 H3 N 10:00 GBR TAYLOR Ryan M 10093387540 C2 N BEL FREDRIKSSON Bjorn M 10062802733 C2 FRD2019 10:30 GBR PRICE Simon M 10008436556 C2 R BEL THOMANNE Thibaud M 10080285365 C2 FRD2019 11:00 Tea break 11 :10 CHN ZHANG Haofei M 10088133372 C2 N BEL KRIECKEMANS Dirk M 10091467647 T2 N CHN WANG Tao C4 N 11 :40 GBR STONE David M 10008440903 T2 R BEL CLINCKE Louis M 10080303856 C4 FRD2019 12:10 GBR JONES Luke M 10018766551 H3 FRD2019 GBR MURPHY David M 10019315310 C5 FRD2018 12:40 Lunch 13:40 CZE KOVAR Pavel M 10063464757 H1 N NED DE VAAN Laura W 10008465858 NE MRR ITA DE CORTES Mirko M 10013021424 H5 N 14:10 CHN QIAO Yuxin W 10088133574 C4 N NED VAN DEN BROEK Andrea W 10093581035 C2 N 14:40 NZL MCCALLUM Hamish M 10082591541 C3 N NED ALBERS Chiel M 10053197309 H4 N 15:10 NZL MEAD Rory M 10059646795 -

Get Instruction Manual
We strive to ensure that our produc ts are of the highest quality and free of manufacturing defec ts or missing par ts. Howeve r, if you have any problems with your new product, please contact us toll free at: 1-88 8 - 577 - 4460 [email protected] Or w r it e t o: Victory Tailgate Customer Service Departmen t 2437 E Landstreet Rd Orlando,FL 32824 www.victorytailgate.com Please have your model number when inquiring about parts. When con t ac ting Escalade S por t s please provide your model numbe r , date code (i f applicable ), and pa rt nu mbe r i f reque sting a repla c emen t pa rt. The s e nu mbe rs a re loc ated on the p rodu ct, pa ckaging , and in thi s owne rs manual . Your Model Number : M01530W Date Code: 2-M01530W- -JL Purchase Date: PLEASE RETAIN THIS INSTRUCTION MANUAL FOR FUTURE REFERENCE All Rights Reserved © 2019 Escalade Spor ts 1 For Customer Service Call 1-888-577-4460 IMPORTANT! READ EACH STEP IN THIS MANUAL BEFORE YOU BEGIN THE ASSEMBLY. TWO (2) ADU LTS ARE REQUIRED TO ASSEMBLE THISDOUBLE SHOOTOUT Tools Needed: Allen Wrench (provided)Phillips Screwdriver Plyers ! Make sure you understand the following tips before you begin to assemble your basketball shootout. 1.This game (with Mechanical Scoring Arm) can be played outdoors in dry weather - but must be stored indoors. 2.Tighten hardware as instructed. 3.Do not over tighten hardware,as you could crush the tubing. 4.Some drawings or images in this manual may not look exactly like your product. -

ELIGIBILITY Para-Cycling Athletes: Must Be a United States Citizen With
ELIGIBILITY Para-cycling Athletes: Must be a United States citizen with a USA racing nationality. LICENSING National Championships: Riders may have a current International or Domestic USA Cycling license (USA citizenship) or Foreign Federation license showing a USA racing nationality to register. World Championships Selection: Riders must have a current International USA Cycling license with a USA racing nationality on or before June 20, 2019 in order to be selected for the Team USA roster for the 2019 UCI Para-cycling Road World Championships. Selection procedures for the World Championships can be found on the U.S. Paralympics Cycling Website: https://www.teamusa.org/US- Paralympics/Sports/Cycling/Selection-Procedures REGULATIONS General: All events conducted under UCI Regulations, including UCI equipment regulations. Road Race and Time Trials: • No National Team Kit or National championship uniforms are allowed. • For the Road Race, only neutral service and official’s cars are allowed in the caravan. • For the Time Trial, bicycles and handcycles must be checked 15 minutes before the athlete’s assigned start time. Courtesy checks will be available from 1 hour before the first start. No follow vehicles are allowed. • For all sport classes in the road race, athletes are required to wear a helmet in the correct sport class color, or use an appropriately color helmet cover, as follows: RED MC5, WC5, MT2, MH4, WH4, MB WHITE MC4, WC4, MH3, WH3, WB, WT2 BLUE MC3, WC3, MH2, WT1 BLACK MH5, WH5, MC2, WC2, MT1 YELLOW MC1, WC1, WH2 GREEN MH1 ORANGE WH1 Handcycle Team Relay (TR): New National Championship event run under UCI and special regulations below: • Team Requirements: Teams eligible for the National Championship Team Relay, must be respect the following composition: o Teams of three athletes o Using the table below, the total of points for the three TR athletes may not be more than six (6) points which must include an athlete with a scoring point value of 1. -

Engineered Class Poles Including Steel SW, SWR, Concrete and Hybrid
Engineered Class Poles Including Steel SW, SWR, Concrete and Hybrid Expanded Standard Poles: Concrete Structure designs to 140’ heights and 20,000 lbs. tip load. Steel Hybrid As the need for wood alternative poles increases, now more than ever is the time to switch to Valmont Newmark steel, concrete and hybrid poles. Why Valmont Newmark? Recognized as an industry leader for quality and reliability, Valmont has been supplying utility structures since the 1970’s. Dependable structures are a priority and we utilize a proprietary design software, developed in-house and based on extensive testing, for all of our structural designs. We take great care in each step of the design and manufacturing process to ensure that our customers receive the highest quality product and on time delivery. By sharing manufacturing and engineering practices across our global network, we are better able to leverage our existing products, facilities and processes. As a result, we are the only company in the industry that provides a comprehensive product selection from a single source. Table of Contents Introduction ........................................................................... 2 - 3 Product Attributes ...................................................................... 4 Features and Benefits ................................................................. 5 Rapid Response Series ............................................................... 6 Ground Line Moment Quick Tables ....................................... 7 - 8 Standard Pole Classifications -

United States Olympic Committee and U.S. Department of Veterans Affairs
SELECTION STANDARDS United States Olympic Committee and U.S. Department of Veterans Affairs Veteran Monthly Assistance Allowance Program The U.S. Olympic Committee supports Paralympic-eligible military veterans in their efforts to represent the USA at the Paralympic Games and other international sport competitions. Veterans who demonstrate exceptional sport skills and the commitment necessary to pursue elite-level competition are given guidance on securing the training, support, and coaching needed to qualify for Team USA and achieve their Paralympic dreams. Through a partnership between the United States Department of Veterans Affairs and the USOC, the VA National Veterans Sports Programs & Special Events Office provides a monthly assistance allowance for disabled Veterans of the Armed Forces training in a Paralympic sport, as authorized by 38 U.S.C. § 322(d) and section 703 of the Veterans’ Benefits Improvement Act of 2008. Through the program the VA will pay a monthly allowance to a Veteran with a service-connected or non-service-connected disability if the Veteran meets the minimum VA Monthly Assistance Allowance (VMAA) Standard in his/her respective sport and sport class at a recognized competition. Athletes must have established training and competition plans and are responsible for turning in monthly and/or quarterly forms and reports in order to continue receiving the monthly assistance allowance. Additionally, an athlete must be U.S. citizen OR permanent resident to be eligible. Lastly, in order to be eligible for the VMAA athletes must undergo either national or international classification evaluation (and be found Paralympic sport eligible) within six months of being placed on the allowance pay list. -

The Intentions of International Tourists to Attend the 2016 Rio Summer Olympic and Paralympic Games: a Study of the Image of Rio De Janeiro and Brazil
Ann Appl Sport Sci 8(3): e798, 2020. http://www.aassjournal.com; e-ISSN: 2322–4479; p-ISSN: 2476–4981. 10.29252/aassjournal.798 ORIGINAL ARTICLE The Intentions of International Tourists to Attend the 2016 Rio Summer Olympic and Paralympic Games: A Study of the Image of Rio de Janeiro and Brazil Leonardo Jose Mataruna-Dos-Santos* College of Business Administration, American University in the Emirates, Dubai, UAE. Submitted 22 September 2019; Accepted in final form 27 February 2020. ABSTRACT Background. This paper investigates how hosting a mega sports event such as the 2016 Rio Games – Olympic and Paralympic influence the Rio de Janeiro and Brazil image’ like popular destinations among tourists. Objectives. The following hypotheses guided our research to identify the more positive image of Brazil as a tourism destination. Methods. A mixed research design combining both qualitative and quantitative approaches was used. Participants were recruited at the Technische Universität München and in the city center of Munich, Germany. The two dimensions (cognitive and affective) of the tourism destination image were considered to elaborate a questionnaire survey, which mixes both qualitative and quantitative methods. Results. The significant factors influencing the intentions of a person to attend the Games in Brazil are the positive portrayed image of the country and their sport interest. According to the multiple regression conducted, the only variables, which have influenced people’s intention to go to Brazil for the Olympics, were the image of the country as a tourism destination (β = 0.404, p < 0.05) and sports interests (β = 0.259, p < 0.05). -

(VA) Veteran Monthly Assistance Allowance for Disabled Veterans
Revised May 23, 2019 U.S. Department of Veterans Affairs (VA) Veteran Monthly Assistance Allowance for Disabled Veterans Training in Paralympic and Olympic Sports Program (VMAA) In partnership with the United States Olympic Committee and other Olympic and Paralympic entities within the United States, VA supports eligible service and non-service-connected military Veterans in their efforts to represent the USA at the Paralympic Games, Olympic Games and other international sport competitions. The VA Office of National Veterans Sports Programs & Special Events provides a monthly assistance allowance for disabled Veterans training in Paralympic sports, as well as certain disabled Veterans selected for or competing with the national Olympic Team, as authorized by 38 U.S.C. 322(d) and Section 703 of the Veterans’ Benefits Improvement Act of 2008. Through the program, VA will pay a monthly allowance to a Veteran with either a service-connected or non-service-connected disability if the Veteran meets the minimum military standards or higher (i.e. Emerging Athlete or National Team) in his or her respective Paralympic sport at a recognized competition. In addition to making the VMAA standard, an athlete must also be nationally or internationally classified by his or her respective Paralympic sport federation as eligible for Paralympic competition. VA will also pay a monthly allowance to a Veteran with a service-connected disability rated 30 percent or greater by VA who is selected for a national Olympic Team for any month in which the Veteran is competing in any event sanctioned by the National Governing Bodies of the Olympic Sport in the United State, in accordance with P.L. -

Tokyo 2020 Paralympic Games Medal Events and Athlete Quotas
Tokyo 2020 Paralympic Games Medal events and athlete quotas 4 September 2017 International Paralympic Committee Adenauerallee 212-214 Tel. +49 228 2097-200 www.paralympic.org 53113 Bonn, Germany Fax +49 228 2097-209 [email protected] Archery • Medal events: 9 (3 men’s, 3 women’s and 3 mixed) • Athlete slots: 140 (80 men and 60 women) • Archery has same number of medals events and athletes as Rio 2016 and the medal events are unchanged. Men’s events (3) Women’s events (3) Mixed events (3) Individual W1 Individual W1 Team W1 Individual Compound Individual Compound Team Compound Individual Recurve Individual Recurve Team Recurve Tokyo 2020 Paralympic Games medal event programme and athlete quotas 2 Athletics • Medal events: 168 (93 men’s, 74 women’s and 1 mixed) • Athlete slots: 1,100 (660 men and 440 women) • The sport will have nine less medal events than Rio 2016 but the same number of athletes • The sport will publish it detailed medal event programme in 2018. Men’s events (93) Women’s events (74) Mixed events (1) To be published in 2018 To be published in 2018 To be published in 2018 Tokyo 2020 Paralympic Games medal event programme and athlete quotas 3 Badminton • Medal events: 14 (7 men’s, 6 women’s and 1 mixed) • Athlete slots: 90 (44 men and 46 women) • Badminton will make its debut at Tokyo 2020. Men’s events (7) Women’s events (6) Mixed events (1) Singles WH1 Singles WH1 Doubles SL/SU Singles WH2 Singles WH2 Singles SL3 Singles SL4 Singles SL4 Singles SU5 Singles SU5 Doubles WH Singles SS6 Doubles SL/SU Doubles WH Tokyo 2020 Paralympic Games medal event programme and athlete quotas 4 Boccia • Medal events: 7 (7 mixed) • Athlete slots: 116 (0 men, 32 women and 84 gender free) • The sport has the same number of medal events as Rio 2016 but 8 more athlete slots as part of the IPC’s aspiration to increase the number of competition opportunities for athletes with high support needs. -

The Paralympic Athlete Dedicated to the Memory of Trevor Williams Who Inspired the Editors in 1997 to Write This Book
This page intentionally left blank Handbook of Sports Medicine and Science The Paralympic Athlete Dedicated to the memory of Trevor Williams who inspired the editors in 1997 to write this book. Handbook of Sports Medicine and Science The Paralympic Athlete AN IOC MEDICAL COMMISSION PUBLICATION EDITED BY Yves C. Vanlandewijck PhD, PT Full professor at the Katholieke Universiteit Leuven Faculty of Kinesiology and Rehabilitation Sciences Department of Rehabilitation Sciences Leuven, Belgium Walter R. Thompson PhD Regents Professor Kinesiology and Health (College of Education) Nutrition (College of Health and Human Sciences) Georgia State University Atlanta, GA USA This edition fi rst published 2011 © 2011 International Olympic Committee Blackwell Publishing was acquired by John Wiley & Sons in February 2007. Blackwell’s publishing program has been merged with Wiley’s global Scientifi c, Technical and Medical business to form Wiley-Blackwell. Registered offi ce: John Wiley & Sons, Ltd, The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, UK Editorial offi ces: 9600 Garsington Road, Oxford, OX4 2DQ, UK The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, UK 111 River Street, Hoboken, NJ 07030-5774, USA For details of our global editorial offi ces, for customer services and for information about how to apply for permission to reuse the copyright material in this book please see our website at www.wiley.com/wiley-blackwell The right of the author to be identifi ed as the author of this work has been asserted in accordance with the UK Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, except as permitted by the UK Copyright, Designs and Patents Act 1988, without the prior permission of the publisher. -

Social Scientists' Satisfaction with Data Reuse
Ixchel M. Faniel OCLC Research Adam Kriesberg University of Michigan Elizabeth Yakel University of Michigan Social Scientists’ Satisfaction with Data Reuse Note: This is a preprint of an article accepted for publication in Journal of the Association for Information Science and Technology copyright © 2015. Abstract: Much of the recent research on digital data repositories has focused on assessing either the trustworthiness of the repository or quantifying the frequency of data reuse. Satisfaction with the data reuse experience, however, has not been widely studied. Drawing from the information systems and information science literatures, we develop a model to examine the relationship between data quality and data reusers’ satisfaction. Based on a survey of 1,480 journal article authors who cited Inter-University Consortium for Political and Social Research (ICPSR) data in published papers from 2008 – 2012, we found several data quality attributes - completeness, accessibility ease of operation, and credibility – had significant positive associations with data reusers’ satisfaction. There was also a significant positive relationship between documentation quality and data reusers’ satisfaction. © 2015 OCLC Online Computer Library Center, Inc. 6565 Kilgour Place Dublin, Ohio 43017-3395 This work is licensed under a Creative Commons Attribution 4.0 International License. http://creativecommons.org/licenses/by/4.0/ Suggested citation: Faniel, I. M., Kriesberg, A. and Yakel, E. (2015). Social scientists' satisfaction with data reuse. Journal of the Association for Information Science and Technology. doi: 10.1002/asi.23480 Social Scientists’ Satisfaction with Data Reuse 1 Introduction In the past decade, digital data repositories in a variety of disciplines have increased in number and scope (Hey, Tansley, & Tolle, 2009). -

Annual Report 2016 & Financial Statements
ANNUAL REPORT 2016 & FINANCIAL STATEMENTS ANNUAL REPORT 2016 & FINANCIAL STATEMENTS REPORT 2016 ANNUAL 2016 PARALYMICS IRELAND PARALYMICS PAGE // 1 ANNUAL REPORT 2016 & FINANCIAL STATEMENTS ANNUAL REPORT 2016 & FINANCIAL STATEMENTS Table of Contents 3.3. Sport Science & Medicine Programme //13 1. Introduction //04 3.4. Coaching Support Programmes //13 2. Rio 2016 Paralympic Games //06 3.5. Performance Plan Development 2.1. ROCOG / IPC //07 2017-2020 //14 2.2. Chef de Mission Report //08 3.6. Recommended changes to Paralympics Ireland performance programme //14 2.3. Preparation Programme: Rio 2016 //08 4. Organisation & Structure //15 2.4. Preparation Programme: Multisport Camps //08 4.1. Governance Review //15 2.5. Irish Paralympic Team Selection //09 4.2. Board of Directors //16 2.6. Team HQ Operations and 4.3. Staffing //16 Games Logistics //09 4.4. Membership //16 2.7. Games Performance Targets //10 4.5. Finance //17 2.8. Games Performance Report //10 4.6. Legal Issues //17 2.9. Paralympics Ireland Guest Hospitality Programme //11 4.7. Strategic Planning //17 2.10. Ticketing //11 5. Policy Formation & Development //18 2.11. Rio 2016 Review Report //11 5.1. Governance Code //19 3. Performance Programme //12 5.2. IPC Licensing //19 3.1. 2016 Paralympics Ireland 5.3. Classification //19 Performance Programme //12 5.4. Safeguarding //19 3.2. 2016 Performance Summary (excluding Rio 2016) //13 6. Commercial Strategy //20 PAGE // 2 ANNUAL REPORT 2016 & FINANCIAL STATEMENTS 6.1. Sponsor Recruitment Programme //20 9. Other Activities //29 6.2. Commercial Advisory Group //20 10. Acknowledgements //30 6.3. Fundraising Programme //21 11. -

Para-Cycling Nomination Criteria
NOMINATION CRITERIA 2020 PARALYMPIC GAMES NOMINATION CRITERIA 2020 Paralympic Games 24 August – 5 September 2021, Tokyo, Japan 1. DEFINITIONS AND INTERPRETATIONS 1.1. Definitions Unless otherwise defined below, capitalised terms in this Nomination Criteria have the meaning given to them in the Paralympics Australia General Selection Criteria – Australian Paralympic Team, certain of which have been reproduced below for the sake of convenience. PA means the Australian Paralympic Committee Limited, Paralympics Australia and any of its officers, employees or agents and any committee it convenes including the PA Selection Committee. PA General Selection Criteria – Australian Paralympic Team means the document adopted by the Executive which governs, among other things, the nomination and selection of Athletes to a team for a Paralympic Games or Paralympic Winter Games. PA Selection Committee means the committee established by PA to send athletes and appoint officials to the Australian Paralympic Team for the Games. PA Selection Criteria means the criteria adopted by PA in respect of the Games which outlines the requirements for an athlete to be selected by PA to participate in the Games. Athlete means a person who: a) participates in the Sport; and b) is recognised by the National Federation or PA as eligible for nomination to PA for selection to the Team pursuant to this Nomination Criteria. Disciplines mean Track and Road cycling. Classification means the criteria, rules, policies and processes, including athlete assessment and allocation