Social Scientists' Satisfaction with Data Reuse
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
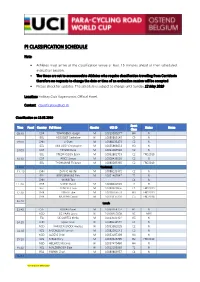
Pi Classification Schedule
PI CLASSIFICATION SCHEDULE Note: • Athletes must arrive at the classification venue at least 15 minutes ahead of their scheduled evaluation session. • The times are set to accommodate Athletes who require classification travelling from Corridonia therefore no requests to change the date or time of an evaluation session will be accepted. • Please check for updates. The schedule is subject to change until Sunday 12 May 2019 Location: Holiday Club Vayamundo, Official Hotel. Contact: [email protected] Classification on 13.05.2019 Sport Time Panel Country Full Name Gender UCI ID Status Notes Class 08:30 GBR TOWNSEND Joseph M 10019380277 H4 N BEL HOSSELET Catheline W 10089809149 C5 N 09:00 CHN LI Shan M 10088133473 C2 N BEL VAN LOOY Christophe M 10055886633 H3 N 10:00 GBR TAYLOR Ryan M 10093387540 C2 N BEL FREDRIKSSON Bjorn M 10062802733 C2 FRD2019 10:30 GBR PRICE Simon M 10008436556 C2 R BEL THOMANNE Thibaud M 10080285365 C2 FRD2019 11:00 Tea break 11 :10 CHN ZHANG Haofei M 10088133372 C2 N BEL KRIECKEMANS Dirk M 10091467647 T2 N CHN WANG Tao C4 N 11 :40 GBR STONE David M 10008440903 T2 R BEL CLINCKE Louis M 10080303856 C4 FRD2019 12:10 GBR JONES Luke M 10018766551 H3 FRD2019 GBR MURPHY David M 10019315310 C5 FRD2018 12:40 Lunch 13:40 CZE KOVAR Pavel M 10063464757 H1 N NED DE VAAN Laura W 10008465858 NE MRR ITA DE CORTES Mirko M 10013021424 H5 N 14:10 CHN QIAO Yuxin W 10088133574 C4 N NED VAN DEN BROEK Andrea W 10093581035 C2 N 14:40 NZL MCCALLUM Hamish M 10082591541 C3 N NED ALBERS Chiel M 10053197309 H4 N 15:10 NZL MEAD Rory M 10059646795 -

VMAA-Performance-Sta
Revised June 18, 2019 U.S. Department of Veterans Affairs (VA) Veteran Monthly Assistance Allowance for Disabled Veterans Training in Paralympic and Olympic Sports Program (VMAA) In partnership with the United States Olympic Committee and other Olympic and Paralympic entities within the United States, VA supports eligible service and non-service-connected military Veterans in their efforts to represent the USA at the Paralympic Games, Olympic Games and other international sport competitions. The VA Office of National Veterans Sports Programs & Special Events provides a monthly assistance allowance for disabled Veterans training in Paralympic sports, as well as certain disabled Veterans selected for or competing with the national Olympic Team, as authorized by 38 U.S.C. 322(d) and Section 703 of the Veterans’ Benefits Improvement Act of 2008. Through the program, VA will pay a monthly allowance to a Veteran with either a service-connected or non-service-connected disability if the Veteran meets the minimum military standards or higher (i.e. Emerging Athlete or National Team) in his or her respective Paralympic sport at a recognized competition. In addition to making the VMAA standard, an athlete must also be nationally or internationally classified by his or her respective Paralympic sport federation as eligible for Paralympic competition. VA will also pay a monthly allowance to a Veteran with a service-connected disability rated 30 percent or greater by VA who is selected for a national Olympic Team for any month in which the Veteran is competing in any event sanctioned by the National Governing Bodies of the Olympic Sport in the United State, in accordance with P.L. -

1 Data Policies of Highly-Ranked Social Science
1 Data policies of highly-ranked social science journals1 Mercè Crosas2, Julian Gautier2, Sebastian Karcher3, Dessi Kirilova3, Gerard Otalora2, Abigail Schwartz2 Abstract By encouraging and requiring that authors share their data in order to publish articles, scholarly journals have become an important actor in the movement to improve the openness of data and the reproducibility of research. But how many social science journals encourage or mandate that authors share the data supporting their research findings? How does the share of journal data policies vary by discipline? What influences these journals’ decisions to adopt such policies and instructions? And what do those policies and instructions look like? We discuss the results of our analysis of the instructions and policies of 291 highly-ranked journals publishing social science research, where we studied the contents of journal data policies and instructions across 14 variables, such as when and how authors are asked to share their data, and what role journal ranking and age play in the existence and quality of data policies and instructions. We also compare our results to the results of other studies that have analyzed the policies of social science journals, although differences in the journals chosen and how each study defines what constitutes a data policy limit this comparison. We conclude that a little more than half of the journals in our study have data policies. A greater share of the economics journals have data policies and mandate sharing, followed by political science/international relations and psychology journals. Finally, we use our findings to make several recommendations: Policies should include the terms “data,” “dataset” or more specific terms that make it clear what to make available; policies should include the benefits of data sharing; journals, publishers, and associations need to collaborate more to clarify data policies; and policies should explicitly ask for qualitative data. -

Research Impact Report 2020
RESEARCH IMPACT REPORT 2020 Research Impact Report 2020 College of Business and Economic Development RESEARCH IMPACT REPORT 2020 21 EXECUTIVE SUMMARY FACULTY AND STAFF PROFILE 40 tenure-track faculty 85 total faculty and staff 11 Assistant Professors 52 Scholarly Academics (SA) 19 Associate Professors 4 Practice Academics (PA) 10 Professors 2 Scholarly Practitioners (SP) 23 Instructional Practitioners (IP) 60 Participating and 25 Supporting 4 Other 2019-20 IMPACT HIGHLIGHTS 350 scholarly contributions produced 51 peer-reviewed publications in 38 different journals 24% of the publications were featured in premier/significant and A*/A journals according to Cabell’s Classification Index (CCI), Australian Business Deans Council (ABDC) or Association of Business Schools (ABS) classifications. Average impact factor = 2.897 Average acceptance rate = 18% Average h-index = 33 Research funding 6 faculty were awarded a total of $2,019,091 in external grant funding across 12 projects. 17 faculty were awarded a total of $84,900 in competitive research grants for summer 2020. 8 faculty received research awards from the Business Advisory Council in 2020. Service to the academy 5 faculty members are editors of peer-reviewed journals. 8 faculty members serve on an editorial review board. 24 faculty serve as reviewers for 74 different peer-reviewed journals. Faculty publication impact Top 10 faculty by h-index in Google Scholar cited a total of 15,870 times Top 10 faculty by h-index in ISI Web of Science cited a total of 4,601 times Top 10 faculty by h-index in Scopus cited a total of 6,012 times “Century Club”: 45 faculty publications now have over 100 citations in Google Scholar. -

Get Instruction Manual
We strive to ensure that our produc ts are of the highest quality and free of manufacturing defec ts or missing par ts. Howeve r, if you have any problems with your new product, please contact us toll free at: 1-88 8 - 577 - 4460 [email protected] Or w r it e t o: Victory Tailgate Customer Service Departmen t 2437 E Landstreet Rd Orlando,FL 32824 www.victorytailgate.com Please have your model number when inquiring about parts. When con t ac ting Escalade S por t s please provide your model numbe r , date code (i f applicable ), and pa rt nu mbe r i f reque sting a repla c emen t pa rt. The s e nu mbe rs a re loc ated on the p rodu ct, pa ckaging , and in thi s owne rs manual . Your Model Number : M01530W Date Code: 2-M01530W- -JL Purchase Date: PLEASE RETAIN THIS INSTRUCTION MANUAL FOR FUTURE REFERENCE All Rights Reserved © 2019 Escalade Spor ts 1 For Customer Service Call 1-888-577-4460 IMPORTANT! READ EACH STEP IN THIS MANUAL BEFORE YOU BEGIN THE ASSEMBLY. TWO (2) ADU LTS ARE REQUIRED TO ASSEMBLE THISDOUBLE SHOOTOUT Tools Needed: Allen Wrench (provided)Phillips Screwdriver Plyers ! Make sure you understand the following tips before you begin to assemble your basketball shootout. 1.This game (with Mechanical Scoring Arm) can be played outdoors in dry weather - but must be stored indoors. 2.Tighten hardware as instructed. 3.Do not over tighten hardware,as you could crush the tubing. 4.Some drawings or images in this manual may not look exactly like your product. -

Human Resource Management Journal : a Look to the Past, Present, and Future of the Journal and HRM Scholarship
This is a repository copy of Human Resource Management Journal : A look to the past, present, and future of the journal and HRM scholarship. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/162027/ Version: Published Version Article: Farndale, E., McDonnell, A., Scholarios, D. et al. (1 more author) (2020) Human Resource Management Journal : A look to the past, present, and future of the journal and HRM scholarship. Human Resource Management Journal, 30 (1). pp. 1-12. ISSN 0954-5395 https://doi.org/10.1111/1748-8583.12275 Reuse This article is distributed under the terms of the Creative Commons Attribution (CC BY) licence. This licence allows you to distribute, remix, tweak, and build upon the work, even commercially, as long as you credit the authors for the original work. More information and the full terms of the licence here: https://creativecommons.org/licenses/ Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Received: 4 December 2019 Accepted: 4 December 2019 DOI: 10.1111/1748-8583.12275 EDITORIAL Human Resource Management Journal: A look to the past, present, and future of the journal and HRM scholarship Abstract This editorial lays out 30 years of history of Human Resource Management Journal (HRMJ), charting the journal's roots, reflecting on HRM scholarship today and guiding authors on potential contribu- tions to the journal in the future. -

D2.2: Research Data Exchange Solution
H2020-ICT-2018-2 /ICT-28-2018-CSA SOMA: Social Observatory for Disinformation and Social Media Analysis D2.2: Research data exchange solution Project Reference No SOMA [825469] Deliverable D2.2: Research Data exchange (and transparency) solution with platforms Work package WP2: Methods and Analysis for disinformation modeling Type Report Dissemination Level Public Date 30/08/2019 Status Final Authors Lynge Asbjørn Møller, DATALAB, Aarhus University Anja Bechmann, DATALAB, Aarhus University Contributor(s) See fact-checking interviews and meetings in appendix 7.2 Reviewers Noemi Trino, LUISS Datalab, LUISS University Stefano Guarino, LUISS Datalab, LUISS University Document description This deliverable compiles the findings and recommended solutions and actions needed in order to construct a sustainable data exchange model for stakeholders, focusing on a differentiated perspective, one for journalists and the broader community, and one for university-based academic researchers. SOMA-825469 D2.2: Research data exchange solution Document Revision History Version Date Modifications Introduced Modification Reason Modified by v0.1 28/08/2019 Consolidation of first DATALAB, Aarhus draft University v0.2 29/08/2019 Review LUISS Datalab, LUISS University v0.3 30/08/2019 Proofread DATALAB, Aarhus University v1.0 30/08/2019 Final version DATALAB, Aarhus University 30/08/2019 Page | 1 SOMA-825469 D2.2: Research data exchange solution Executive Summary This report provides an evaluation of current solutions for data transparency and exchange with social media platforms, an account of the historic obstacles and developments within the subject and a prioritized list of future scenarios and solutions for data access with social media platforms. The evaluation of current solutions and the historic accounts are based primarily on a systematic review of academic literature on the subject, expanded by an account on the most recent developments and solutions. -

A Comprehensive Analysis of the Journal Evaluation System in China
A comprehensive analysis of the journal evaluation system in China Ying HUANG1,2, Ruinan LI1, Lin ZHANG1,2,*, Gunnar SIVERTSEN3 1School of Information Management, Wuhan University, China 2Centre for R&D Monitoring (ECOOM) and Department of MSI, KU Leuven, Belgium 3Nordic Institute for Studies in Innovation, Research and Education, Tøyen, Oslo, Norway Abstract Journal evaluation systems are important in science because they focus on the quality of how new results are critically reviewed and published. They are also important because the prestige and scientific impact of journals is given attention in research assessment and in career and funding systems. Journal evaluation has become increasingly important in China with the expansion of the country’s research and innovation system and its rise as a major contributor to global science. In this paper, we first describe the history and background for journal evaluation in China. Then, we systematically introduce and compare the most influential journal lists and indexing services in China. These are: the Chinese Science Citation Database (CSCD); the journal partition table (JPT); the AMI Comprehensive Evaluation Report (AMI); the Chinese STM Citation Report (CJCR); the “A Guide to the Core Journals of China” (GCJC); the Chinese Social Sciences Citation Index (CSSCI); and the World Academic Journal Clout Index (WAJCI). Some other lists published by government agencies, professional associations, and universities are briefly introduced as well. Thereby, the tradition and landscape of the journal evaluation system in China is comprehensively covered. Methods and practices are closely described and sometimes compared to how other countries assess and rank journals. Keywords: scientific journal; journal evaluation; peer review; bibliometrics 1 1. -

Downloaded Manually1
The Journal Coverage of Web of Science and Scopus: a Comparative Analysis Philippe Mongeon and Adèle Paul-Hus [email protected]; [email protected] Université de Montréal, École de bibliothéconomie et des sciences de l'information, C.P. 6128, Succ. Centre-Ville, H3C 3J7 Montréal, Qc, Canada Abstract Bibliometric methods are used in multiple fields for a variety of purposes, namely for research evaluation. Most bibliometric analyses have in common their data sources: Thomson Reuters’ Web of Science (WoS) and Elsevier’s Scopus. This research compares the journal coverage of both databases in terms of fields, countries and languages, using Ulrich’s extensive periodical directory as a base for comparison. Results indicate that the use of either WoS or Scopus for research evaluation may introduce biases that favor Natural Sciences and Engineering as well as Biomedical Research to the detriment of Social Sciences and Arts and Humanities. Similarly, English-language journals are overrepresented to the detriment of other languages. While both databases share these biases, their coverage differs substantially. As a consequence, the results of bibliometric analyses may vary depending on the database used. Keywords Bibliometrics, citations indexes, Scopus, Web of Science, research evaluation Introduction Bibliometric and scientometric methods have multiple and varied application realms, that goes from information science, sociology and history of science to research evaluation and scientific policy (Gingras, 2014). Large scale bibliometric research was made possible by the creation and development of the Science Citation Index (SCI) in 1963, which is now part of Web of Science (WoS) alongside two other indexes: the Social Science Citation Index (SSCI) and the Arts and Humanities Citation Index (A&HCI) (Wouters, 2006). -

ELIGIBILITY Para-Cycling Athletes: Must Be a United States Citizen With
ELIGIBILITY Para-cycling Athletes: Must be a United States citizen with a USA racing nationality. LICENSING National Championships: Riders may have a current International or Domestic USA Cycling license (USA citizenship) or Foreign Federation license showing a USA racing nationality to register. World Championships Selection: Riders must have a current International USA Cycling license with a USA racing nationality on or before June 20, 2019 in order to be selected for the Team USA roster for the 2019 UCI Para-cycling Road World Championships. Selection procedures for the World Championships can be found on the U.S. Paralympics Cycling Website: https://www.teamusa.org/US- Paralympics/Sports/Cycling/Selection-Procedures REGULATIONS General: All events conducted under UCI Regulations, including UCI equipment regulations. Road Race and Time Trials: • No National Team Kit or National championship uniforms are allowed. • For the Road Race, only neutral service and official’s cars are allowed in the caravan. • For the Time Trial, bicycles and handcycles must be checked 15 minutes before the athlete’s assigned start time. Courtesy checks will be available from 1 hour before the first start. No follow vehicles are allowed. • For all sport classes in the road race, athletes are required to wear a helmet in the correct sport class color, or use an appropriately color helmet cover, as follows: RED MC5, WC5, MT2, MH4, WH4, MB WHITE MC4, WC4, MH3, WH3, WB, WT2 BLUE MC3, WC3, MH2, WT1 BLACK MH5, WH5, MC2, WC2, MT1 YELLOW MC1, WC1, WH2 GREEN MH1 ORANGE WH1 Handcycle Team Relay (TR): New National Championship event run under UCI and special regulations below: • Team Requirements: Teams eligible for the National Championship Team Relay, must be respect the following composition: o Teams of three athletes o Using the table below, the total of points for the three TR athletes may not be more than six (6) points which must include an athlete with a scoring point value of 1. -

Engineered Class Poles Including Steel SW, SWR, Concrete and Hybrid
Engineered Class Poles Including Steel SW, SWR, Concrete and Hybrid Expanded Standard Poles: Concrete Structure designs to 140’ heights and 20,000 lbs. tip load. Steel Hybrid As the need for wood alternative poles increases, now more than ever is the time to switch to Valmont Newmark steel, concrete and hybrid poles. Why Valmont Newmark? Recognized as an industry leader for quality and reliability, Valmont has been supplying utility structures since the 1970’s. Dependable structures are a priority and we utilize a proprietary design software, developed in-house and based on extensive testing, for all of our structural designs. We take great care in each step of the design and manufacturing process to ensure that our customers receive the highest quality product and on time delivery. By sharing manufacturing and engineering practices across our global network, we are better able to leverage our existing products, facilities and processes. As a result, we are the only company in the industry that provides a comprehensive product selection from a single source. Table of Contents Introduction ........................................................................... 2 - 3 Product Attributes ...................................................................... 4 Features and Benefits ................................................................. 5 Rapid Response Series ............................................................... 6 Ground Line Moment Quick Tables ....................................... 7 - 8 Standard Pole Classifications -

Using Expert Judgments to Rank 45 Latin American Business Journals
302 RAE-Revista de Administração de Empresas | FGV/EAESP ARTICLES Submitted 06.30.2015. Approved 01.04.2016 Evaluated by double blind review process. Scientific Editor: Roberto Patrus DOI: http://dx.doi.org/10.1590/S0034-759020160304 USING EXPERT JUDGMENTS TO RANK 45 LATIN AMERICAN BUSINESS JOURNALS Utilizando avaliações de especialistas para classificar 45 publicações latino- americanas de negócios Usando los juicios de expertos para ranquear 45 revistas latinoamericanas de negocios ABSTRACT This article presents the results of a study on the perception of quality of Latin American business journals based on the judgment of relevant experts – senior professors with knowledge of Latin Ame- rican research and journals. Forty-five journals were included in the study. The highest perceived quality scores were given to Academia (CLADEA – Uniandes), RAE (Fundação Getulio Vargas), and Innovar (Universidad Nacional de Colombia). When perceived quality was weighted by awareness, Academia, LABR-Latin American Business Review (University of San Diego – Coppead), and Innovar had the highest scores. Results complement a recent study by Ruiz-Torres, Penkova, and Villafane (2012) that focused on management journals published in Spanish. Analysis of results suggests that language and branding have an effect on the perception of journal quality. Implications for editors/ publishers, tenure, promotion, research grant committees, and authors are provided. KEYWORDS | Scientifics journals, ranking, Latin America, scientific production, business research. RESUMO Este artigo apresenta os resultados de um estudo sobre a percepção da qualidade de publicações latino-americanas de negócios com base nas avaliações de importantes especialistas – docentes de alto nível com conhecimento de pesquisas latino-americanas e publicações científicas.