Gif2video: Color Dequantization and Temporal Interpolation of GIF Images
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Indexed Color
Indexed Color A browser may support only a certain number of specific colors, creating a palette from which to choose Figure 3.11 The Netscape color palette 1 QUIZ How many bits are needed to represent this palette? Show your work. 2 How to digitize a picture • Sample it → Represent it as a collection of individual dots called pixels • Quantize it → Represent each pixel as one of 224 possible colors (TrueColor) Resolution = The # of pixels used to represent a picture 3 Digitized Images and Graphics Whole picture Figure 3.12 A digitized picture composed of many individual pixels 4 Digitized Images and Graphics Magnified portion of the picture See the pixels? Hands-on: paste the high-res image from the previous slide in Paint, then choose ZOOM = 800 Figure 3.12 A digitized picture composed of many individual pixels 5 QUIZ: Images A low-res image has 200 rows and 300 columns of pixels. • What is the resolution? • If the pixels are represented in True-Color, what is the size of the file? • Same question in High-Color 6 Two types of image formats • Raster Graphics = Storage on a pixel-by-pixel basis • Vector Graphics = Storage in vector (i.e. mathematical) form 7 Raster Graphics GIF format • Each image is made up of only 256 colors (indexed color – similar to palette!) • But they can be a different 256 for each image! • Supports animation! Example • Optimal for line art PNG format (“ping” = Portable Network Graphics) Like GIF but achieves greater compression with wider range of color depth No animations 8 Bitmap format Contains the pixel color -

A New Steganographic Method for Palette-Based Images
IS&T's 1999 PICS Conference A New Steganographic Method for Palette-Based Images Jiri Fridrich Center for Intelligent Systems, SUNY Binghamton, Binghamton, New York Abstract messages. The gaps in human visual and audio systems can be used for information hiding. In the case of images, the In this paper, we present a new steganographic technique human eye is relatively insensitive to high frequencies. This for embedding messages in palette-based images, such as fact has been utilized in many steganographic algorithms, GIF files. The new technique embeds one message bit into which modify the least significant bits of gray levels in one pixel (its pointer to the palette). The pixels for message digital images or digital sound tracks. Additional bits of embedding are chosen randomly using a pseudo-random information can also be inserted into coefficients of image number generator seeded with a secret key. For each pixel transforms, such as discrete cosine transform, Fourier at which one message bit is to be embedded, the palette is transform, etc. Transform techniques are typically more searched for closest colors. The closest color with the same robust with respect to common image processing operations parity as the message bit is then used instead of the original and lossy compression. color. This has the advantage that both the overall change The steganographer’s job is to make the secretly hidden due to message embedding and the maximal change in information difficult to detect given the complete colors of pixels is smaller than in methods that perturb the knowledge of the algorithm used to embed the information least significant bit of indices to a luminance-sorted palette, except the secret embedding key.* This so called such as EZ Stego.1 Indeed, numerical experiments indicate Kerckhoff’s principle is the golden rule of cryptography and that the new technique introduces approximately four times is often accepted for steganography as well. -

Understanding Image Formats and When to Use Them
Understanding Image Formats And When to Use Them Are you familiar with the extensions after your images? There are so many image formats that it’s so easy to get confused! File extensions like .jpeg, .bmp, .gif, and more can be seen after an image’s file name. Most of us disregard it, thinking there is no significance regarding these image formats. These are all different and not cross‐ compatible. These image formats have their own pros and cons. They were created for specific, yet different purposes. What’s the difference, and when is each format appropriate to use? Every graphic you see online is an image file. Most everything you see printed on paper, plastic or a t‐shirt came from an image file. These files come in a variety of formats, and each is optimized for a specific use. Using the right type for the right job means your design will come out picture perfect and just how you intended. The wrong format could mean a bad print or a poor web image, a giant download or a missing graphic in an email Most image files fit into one of two general categories—raster files and vector files—and each category has its own specific uses. This breakdown isn’t perfect. For example, certain formats can actually contain elements of both types. But this is a good place to start when thinking about which format to use for your projects. Raster Images Raster images are made up of a set grid of dots called pixels where each pixel is assigned a color. -

Amiga Graphics Reference Card 2Nd Edition
Quick reference information for graphics, video, 2nd Edition desktop publishing, Covers new Amiga animation, and image 3000 graphics processing on the modes, 24-bit color Commodore Amiga hardware, DOS 2.0 personal computer. Reference Card overscan, and PAL. ) COLOR MODELS Additive Color Mixing Subtractive Color Mixing Red-Green-Blue Cube Hue-Saturation-Value Cone Cyan Value White Blue Blue] Axis Yellow Black ~reen Axis When mixi'hgpigments, cyan, yellow, Red When mixing light, red, green, and blue and magenta are primaries. Example: are primaries. Yell ow is formed by To get blue, mix cyan and magenta. Shades of gray are on the long Cyan pigment absorbs red, magenta adding red and green, for example. diagonal between black and white. pigment absorbs green, so the only component of white light that gets re The Visible Electromagnetic Spectrum flected is blue. 380 420 470 495 535 575 wavelength (nanometers) 770 Hue: Color; spectral position. Often measured in degrees; red=0°, yellow=60°, magenta=300°, etc. Hue is undefined for shades of gray. (ultraviolet) Purple Violet yellowish Red (infrared) Saturation: Color purity. A highly-saturated color is nearly Blue Orange monochromatic, i.e., contains only one color from the spectrum. White, black, and shades of gray have zero saturation. Value: The darkness of a color. How much black it contain's. DELUXE PAINT Ill KEYBOARD COMMANDS White has a value of one, black has a value of zero. Brush Painting Modes Page and Screen Commands While an animation is playing: ; ana, move brush along fixed axis -
The Rendering Pipeline
The Rendering Pipeline Framebuffers • Framebuffer is the interface between the device and the computer’s notion of an image • A memory array in which the computer stores an image – On most computers, separate memory bank from main memory – Many different variations, motivated by cost of memory Framebuffers: True-Color • A true-color (aka 24-bit or 32-bit) framebuffer stores one byte each for red, green, and blue • Each pixel can thus be one of 224 colors • Pay attention to Endian-ness • How can 24-bit and 32-bit mean the same thing here? Framebuffers: Indexed-Color • An indexed-color (8-bit or PseudoColor) framebuffer stores one byte per pixel (also: GIF image format) • This byte indexes into a color map: • How many colors can a pixel be? • Common on low-end displays (cell phones, PDAs, GameBoys) Framebuffers: Indexed Color Illustration of how an indexed palette works A 2-bit indexed-color image. The color of each pixel is represented by a number; each number corresponds to a color in the palette. Image credits: Wikipedia Framebuffers: Hi-Color • Hi-Color is (was?) a popular PC SVGA standard • Packs pixels into 16 bits: – 5 Red, 6 Green, 5 Blue (why would green get more?) – Sometimes just 5,5,5 • Each pixel can be one of 216 colors • Hi-color images can exhibit worse quantization artifacts than a well-mapped 8-bit image Color Quantization A process that reduces the number of distinct colors used in an image Intention that the new image should be as visually similar as possible to the original image Image credits: Wikipedia The Rendering -

AN5072: Introduction to Embedded Graphics – Application Note
Freescale Semiconductor Document Number: AN5072 Application Note Rev 0, 02/2015 Introduction to Embedded Graphics with Freescale Devices by: Luis Olea and Ioseph Martinez Contents 1 Introduction 1 Introduction................................................................1 The purpose of this application note is to explain the basic 1.1 Graphics basic concepts.............. ...................1 concepts and requirements of embedded graphics applications, 2 Freescale graphics devices.............. ..........................7 helping software and hardware engineers easily understand the fundamental concepts behind color display technology, which 2.1 MPC5606S.....................................................7 is being expected by consumers more and more in varied 2.2 MPC5645S.....................................................8 applications from automotive to industrial markets. 2.3 Vybrid.............................................................8 This section helps the reader to familiarize with some of the most used concepts when working with graphics. Knowing 2.4 MAC57Dxx....................... ............................ 8 these definitions is basic for any developer that wants to get 2.5 Kinetis K70......................... ...........................8 started with embedded graphics systems, and these concepts apply to any system that handles graphics irrespective of the 2.6 QorIQ LS1021A................... ......................... 9 hardware used. 2.7 i.MX family........................ ........................... 9 2.8 Quick -

Lynx Express 2D Multimedia Mobile Display Controller Datasheet
L Y N X F A M I L Y SM750 Lynx Express 2D Multimedia Mobile Display Controller Datasheet Revision: 1.4 Updated: September 27, 2012 SM750 Datasheet Notice Silicon Motion, Inc. has made its best efforts to ensure that the information contained in this document is accurate and reliable. However, the information is subject to change without notice. No responsibility is assumed by Silicon Motion, Inc. for the use of this information, nor for infringements of patents or other rights of third parties. Copyright Copyright 2012, Silicon Motion, Inc. All rights reserved. No part of this publication may Notice be reproduced, photocopied, or transmitted in any form, without the prior written consent of Silicon Motion, Inc. Silicon Motion, Inc. reserves the right to make changes to the product specification without reservation and without notice to our users. Revision No. Date Note 0.1 June 2009 First release 0.2 Dec 2009 Second release 0.3 April 2010 Third release 0.4 June 2010 Forth release 0.5 Dec 2010 Design CD update 1.0 May 2011 Add marking and ordering information 1.1 Aug 2011 - Update Figure 12, the ending address of the 2D Engine Data Port change to “0x120000” from “0x150000” - Update CSR08 register descriptions and power-on default value - Add MVDD and MVDD2 DC characteristics in Table 18 and Table 19 1.2 Jan 2012 - Added Standard VGA Register in 2.3. 1.3 Jun 2012 - Updated Top Marking in 13.2 - Updated Product Ordering Information in 14 1.4 Sep 2012 - Fixed bit names in 2.2, 3.2, 4.1, 6.2, 7, and 9.3 All rights strictly reserved. -

Getting Started
_______________________________ Getting Started Version 3.0 Getting Started with PMView Pro Installation & Setup If you are reading this file, you have likely already been through the installation process of PMView Pro. This section is intended to guide you through any subsequent installations and further setup procedures necessary to ensure PMView Pro is working properly on your system. Starting PMView Pro Starting PMView Pro can be as easy as double-clicking any image file. You were given the option during installation to install a shortcut to the desktop and/or the Start Menu as well. On the Start Menu, you will also notice that you can access this file, the Online Help file and PMView itself. PMView Pro also includes potentially unlimited startup options when started using the combination of command line options and script files. You can learn more about command line options and script files from the included help file. File Associations A common issue that may arise at some point after the installation of PMView Pro is the loss of file associations. You will recall that during installation you were presented with a list of file formats to associate with PMView. Even if you selected all formats, other programs may adjust those settings during their installation. The easiest way to have PMView reclaim those associations is to run the PMView Pro installation file again. If you only need to reclaim one or several of those associations, you can do this through the Windows operating system settings. By opening Windows Explorer from the start menu and selection Tools->Folder Options, you will be able to access the system File Type settings. -

Displays and Frame Buffers
Displays and Framebuffers University of Texas at Austin CS384G - Computer Graphics Fall 2010 Don Fussell Reading Required Angel, pp.19-34 [reader 153-168]. Hearn & Baker, pp. 35-49 [reader 83-90]. OpenGL Programming Guide (available online): First four sections of chapter 2 First section of chapter 6 Optional Foley et al., sections 1.5, 4.2-4.5 I.E. Sutherland. Sketchpad: a man-machine graphics communication system. Proceedings of the Spring Join Computer Conference, p. 329-346, 1963. T.H. Myer & I.E. Sutherland. On the design of display processors. Communications of the ACM 11(6): 410-414, 1968. University of Texas at Austin CS384G - Computer Graphics Fall 2010 Don Fussell History Whirlwind Computer - MIT, 1950 CRT display First real-time graphics SAGE air-defense system - middle 1950’s “Whirlwind II” light pens Long-lived (1958 – 1983!) University of Texas at Austin CS384G - Computer Graphics Fall 2010 Don Fussell History Sketchpad - 1963, Ivan Sutherland first interactive graphics system constraint-based interaction techniques for choosing, pointing, drawing Lightpen, buttons, knobs data structures for replicating components hierarchical modeling University of Texas at Austin CS384G - Computer Graphics Fall 2010 Don Fussell Modern graphics systems Current graphics systems consist of: • An application, which talks to a… • Graphics library (e.g., OpenGL or Direct3D), which talks to the… • Graphics hardware The graphics hardware can do a lot of fancy work these days. At a minimum, it contains a framebuffer to drive a display… University of Texas at Austin CS384G - Computer Graphics Fall 2010 Don Fussell Cathode ray tubes (CRTs) Consists of: electron gun electron focusing lens deflection plates/coils electron beam anode with phosphor coating University of Texas at Austin CS384G - Computer Graphics Fall 2010 Don Fussell CRTs, cont. -

Design of False Color Palettes for Grayscale Reproduction
Design of false color palettes for grayscale reproduction Filip A. Sala Warsaw University of Technology, Faculty of Physics, Koszykowa 75, 00-662 Warsaw, Poland Abstract Design of false color palette is quite easy but some effort has to be done to achieve good dynamic range, contrast and overall appearance of the palette. Such palettes, for instance, are commonly used in scientific papers for presenting the data. However, to lower the cost of the paper most scientists decide to let the data to be printed in grayscale. The same applies to e-book readers based on e-ink where most of them are still grayscale. For majority of false color palettes reproducing them in grayscale results in ambiguous mapping of the colors and may be misleading for the reader. In this article design of false color palettes suitable for grayscale reproduction is described. Due to the monotonic change of luminance of these palettes grayscale representation is very similar to the data directly presented with a grayscale palette. Some suggestions and examples how to design such palettes are provided. Keywords: false-color palettes; data visualization; False color palettes are used to display information in variety of fields like physical sciences (e.g. astronomy, optics)[1, 2, 3], medicine (e.g. in different imaging systems)[4] and industry [5]. In most applications palettes are optimized for better contrast, dynamic range and overall appearance of the palette [6, 7]. They are adjusted for particular data that have to be presented. There is no unique algorithm or easy rules to make a good false color palette. -

Differentiable GIF Encoding Framework
GIFnets: Differentiable GIF Encoding Framework Innfarn Yoo, Xiyang Luo, Yilin Wang, Feng Yang, and Peyman Milanfar Google Research - Mountain View, California [innfarn, xyluo, yilin, fengyang, milanfar]@google.com Abstract Graphics Interchange Format (GIF) is a widely used im- age file format. Due to the limited number of palette col- ors, GIF encoding often introduces color banding artifacts. Traditionally, dithering is applied to reduce color banding, but introducing dotted-pattern artifacts. To reduce artifacts and provide a better and more efficient GIF encoding, we introduce a differentiable GIF encoding pipeline, which in- cludes three novel neural networks: PaletteNet, DitherNet, and BandingNet. Each of these three networks provides an (a) Original (b) Palette important functionality within the GIF encoding pipeline. PaletteNet predicts a near-optimal color palette given an input image. DitherNet manipulates the input image to re- duce color banding artifacts and provides an alternative to traditional dithering. Finally, BandingNet is designed to detect color banding, and provides a new perceptual loss specifically for GIF images. As far as we know, this is the first fully differentiable GIF encoding pipeline based on deep neural networks and compatible with existing GIF de- coders. User study shows that our algorithm is better than Floyd-Steinberg based GIF encoding. (c) Floyd-Steinberg (d) Our Method Figure 1: Comparison of our method against GIF encod- 1. Introduction ing with no dithering and Floyd-Steinberg dithering. Com- pared to GIF without dithering (b) and Floyd-Steinberg (c), GIF is a widely used image file format. At its core, GIF our method (d) shows less banding artifacts as well as less represents an image by applying color quantization. -
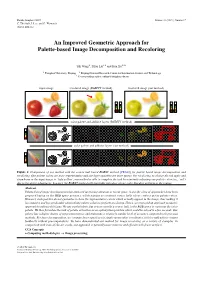
An Improved Geometric Approach for Palette-Based Image Decomposition and Recoloring
Pacific Graphics 2019 Volume 38 (2019), Number 7 C. Theobalt, J. Lee, and G. Wetzstein (Guest Editors) An Improved Geometric Approach for Palette-based Image Decomposition and Recoloring Yili Wang1, Yifan Liu1;2 and Kun Xu1;2∗ 1 Tsinghua University, Beijing 2 Beijing National Research Center for Information Science and Technology ∗ Corresponding author, [email protected] input image recolored image (RGBXY method) recolored image (our method) color palette and additive layers (RGBXY method) color palette and additive layers (our method) Figure 1: Comparison of our method with the convex hull based RGBXY method [TEG18] for palette based image decomposition and recoloring. Our palette colors are more representative and our layer opacities are more sparse. For recoloring, to change the red apple and strawberry in the input image to ‘light yellow’, our method is able to complete the task by intuitively adjusting one palette color (i.e., ‘red’) due to the above advantages, however, the RGBXY method will inevitably introduce strong color bleeding artifacts to the orange. Abstract Palette-based image decomposition has attracted increasing attention in recent years. A specific class of approaches have been proposed basing on the RGB-space geometry, which manage to construct convex hulls whose vertices act as palette colors. However, such palettes do not guarantee to have the representative colors which actually appear in the image, thus making it less intuitive and less predictable when editing palette colors to perform recoloring. Hence, we proposed an improved geometric approach to address this issue. We use a polyhedron, but not necessarily a convex hull, in the RGB space to represent the color palette.