Dissertation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(12) Patent Application Publication (10) Pub. No.: US 2012/0264.634 A1 Amersdorfer Et Al
US 20120264.634A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2012/0264.634 A1 Amersdorfer et al. (43) Pub. Date: Oct. 18, 2012 (54) MARKER SEQUENCES FOR PANCREATIC Publication Classification CANCER DISEASES, PANCREATIC (51) Int. Cl. CARCINOMIA AND USE THEREOF C40B 30/04 (2006.01) GOIN 2L/64 (2006.01) (75) Inventors: Peter Amersdorfer, Graz (AT); GOIN 27/72 (2006.01) Annabel Höpfner, Dortmund (DE); C07K I4/435 (2006.01) Angelika Lueking, Bochum (DE) C40B 40/06 (2006.01) C40B 40/10 (2006.01) CI2N 5/09 (2010.01) (73) Assignee: PROTAGEN Aktiengesellschaft, C7H 2L/04 (2006.01) Dortmund (DE) GOIN 33/574 (2006.01) GOIN 27/62 (2006.01) (21) Appl. No.: 13/498,964 (52) U.S. Cl. ........... 506/9:436/501; 435/6.14; 435/7.92; 506/16:506/18: 435/2:536/23.1; 530/350 (22) PCT Filed: Sep. 29, 2010 (57) ABSTRACT The present invention relates to novel marker sequences for (86). PCT No.: PCT/EP2010/064510 pancreatic cancer diseases, pancreatic carcinoma and the diagnostic use thereof together with a method for Screening of S371 (c)(1), potential active Substances for pancreatic cancer diseases, (2), (4) Date: Jun. 22, 2012 pancreatic carcinoma by means of these marker sequences. Furthermore, the invention relates to a diagnostic device con (30) Foreign Application Priority Data taining Such marker sequences for pancreatic cancer diseases, pancreatic carcinoma, in particular a protein biochip and the Sep. 29, 2009 (EP) .................................. O9171690.2 use thereof. Patent Application Publication Oct. 18, 2012 US 2012/0264.634 A1 US 2012/0264.634 A1 Oct. -

Análise Correlacional Entre a Expressão Dos Fatores De Splicing E a Ocorrência De Splicing Alternativo Em Tecidos Humanos E De Camundongos
ANÁLISE CORRELACIONAL ENTRE A EXPRESSÃO DOS FATORES DE SPLICING E A OCORRÊNCIA DE SPLICING ALTERNATIVO EM TECIDOS HUMANOS E DE CAMUNDONGOS JULIO CÉSAR NUNES Dissertação apresentada à Fundação Antônio Prudente para a obtenção do título de Mestre em Ciências Área de Concentração: Oncologia Orientador: Dr. Sandro José de Souza São Paulo 2008 Livros Grátis http://www.livrosgratis.com.br Milhares de livros grátis para download. FICHA CATALOGRÁFICA Preparada pela Biblioteca da Fundação Antônio Prudente Nunes, Julio César Análise correlacional entre a expressão dos fatores de splicing e a ocorrência de splicing alternativo em tecidos humanos e de camundongos / Julio César Nunes – São Paulo, 2008. 79p. Dissertação (Mestrado) - Fundação Antônio Prudente. Curso de Pós-Graduação em Ciências - Área de concentração: Oncologia. Orientador: Sandro José Souza Descritores: 1. SPLICING ALTERNATIVO 2. BIOLOGIA MOLECULAR COMPUTACIONAL 3. CÂNCER 4. GENOMICA. AGRADECIMENTOS Agradeço à FAPESP e CAPES pela bolsa de Mestrado. Ao Sandro José de Souza agradeço toda orientação e conhecimento oferecido. Meus especiais agradecimentos ao Pedro Alexandre Favoretto Galante que dedicou atenção a minha formação no processo de Pós-Graduação na Fundação Antônio Prudente, bem como pela sua oficiosa co-orientação ao projeto de pesquisa. À grande família e amigos pela dedicação e incentivo a minha formação acadêmica. À Fundação Antônio Prudente, Hospital do Câncer e Instituto Ludwig de Pesquisa sobre o Câncer dedico os meus nobres agradecimentos finais. RESUMO Nunes JC. Análise correlacional entre a expressão dos fatores de splicing e a ocorrência de splicing alternativo em tecidos humanos e de camundongos. São Paulo; 2007. [Dissertacão de Mestrado - Fundação Antônio Prudente] Splicing alternativo desempenha uma significante função no aumento da complexidade genômica, produzindo um extenso número de mRNA e isoformas protéicas. -
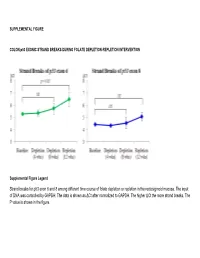
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Análise Correlacional Entre a Expressão Dos Fatores De Splicing E a Ocorrência De Splicing Alternativo Em Tecidos Humanos E De Camundongos
ANÁLISE CORRELACIONAL ENTRE A EXPRESSÃO DOS FATORES DE SPLICING E A OCORRÊNCIA DE SPLICING ALTERNATIVO EM TECIDOS HUMANOS E DE CAMUNDONGOS JULIO CÉSAR NUNES Dissertação apresentada à Fundação Antônio Prudente para a obtenção do título de Mestre em Ciências Área de Concentração: Oncologia Orientador: Dr. Sandro José de Souza São Paulo 2008 FICHA CATALOGRÁFICA Preparada pela Biblioteca da Fundação Antônio Prudente Nunes, Julio César Análise correlacional entre a expressão dos fatores de splicing e a ocorrência de splicing alternativo em tecidos humanos e de camundongos / Julio César Nunes – São Paulo, 2008. 79p. Dissertação (Mestrado) - Fundação Antônio Prudente. Curso de Pós-Graduação em Ciências - Área de concentração: Oncologia. Orientador: Sandro José Souza Descritores: 1. SPLICING ALTERNATIVO 2. BIOLOGIA MOLECULAR COMPUTACIONAL 3. CÂNCER 4. GENOMICA. AGRADECIMENTOS Agradeço à FAPESP e CAPES pela bolsa de Mestrado. Ao Sandro José de Souza agradeço toda orientação e conhecimento oferecido. Meus especiais agradecimentos ao Pedro Alexandre Favoretto Galante que dedicou atenção a minha formação no processo de Pós-Graduação na Fundação Antônio Prudente, bem como pela sua oficiosa co-orientação ao projeto de pesquisa. À grande família e amigos pela dedicação e incentivo a minha formação acadêmica. À Fundação Antônio Prudente, Hospital do Câncer e Instituto Ludwig de Pesquisa sobre o Câncer dedico os meus nobres agradecimentos finais. RESUMO Nunes JC. Análise correlacional entre a expressão dos fatores de splicing e a ocorrência de splicing alternativo em tecidos humanos e de camundongos. São Paulo; 2007. [Dissertacão de Mestrado - Fundação Antônio Prudente] Splicing alternativo desempenha uma significante função no aumento da complexidade genômica, produzindo um extenso número de mRNA e isoformas protéicas. -

Copyright by Yen-I Grace Chen 2007
Copyright by Yen-I Grace Chen 2007 The Dissertation Committee for Yen-I Grace Chen Certifies that this is the approved version of the following dissertation: Proteomic Analysis of the Pre-mRNA Splicing Machinery Utilizing Chromosomal Locus Epitope Tagging in Metazoans Committee: Scott Stevens, Supervisor Henry Bose Robert Krug Arlen Johnson David Hoffman Proteomic Analysis of the Pre-mRNA Splicing Machinery Utilizing Chromosomal Locus Epitope Tagging in Metazoans by Yen-I Grace Chen, M.D. Dissertation Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy The University of Texas at Austin August, 2007 Dedication To my loving family Acknowledgements I offer sincere thanks to my advisor, Professor Scott Stevens for providing me the opportunity to join his laboratory. His enthusiasm and patience contributed to the success of my research. I also wish to acknowledge professors Robert Krug, Henry Bose, Arlen Johnson, and David Hoffman for serving as my dissertation committee and for their constructive comments and expertise during my dissertation work; professors Phil Tucker and Karen Artzt for helpful conversations, and William Kuziel for plasmids. I would especially thank Shanna Maika and Deb Surman for their persistence and painstaking work in generating our transgenic mice, breeding, and maintenance; Xin Yao and Chad McKee for technical assistance. I also wish to thank all my colleagues in the Stevens lab: Josh Combs, Adam Roth, Champ Gupton, Rea Lardelli, Jennifer Hennigan and former members Dannialle Clayton and Colin Chu, for helpful discussions and establishing a fun environment for research. -

PDF Download
Snrp116 Polyclonal Antibody Catalog No : YT4357 Reactivity : Human,Mouse Applications : WB,IHC-p,IF(paraffin section),ELISA Gene Name : EFTUD2 Protein Name : 116 kDa U5 small nuclear ribonucleoprotein component Human Gene Id : 9343 Human Swiss Prot Q15029 No : Mouse Gene Id : 20624 Mouse Swiss Prot O08810 No : Immunogen : The antiserum was produced against synthesized peptide derived from human EFTUD2. AA range:321-370 Specificity : Snrp116 Polyclonal Antibody detects endogenous levels of Snrp116 protein. Formulation : Liquid in PBS containing 50% glycerol, 0.5% BSA and 0.02% sodium azide. Source : Rabbit Dilution : Western Blot: 1/500 - 1/2000. Immunohistochemistry: 1/100 - 1/300. ELISA: 1/40000. Not yet tested in other applications. Purification : The antibody was affinity-purified from rabbit antiserum by affinity- chromatography using epitope-specific immunogen. Concentration : 1 mg/ml Storage Stability : -20°C/1 year Molecularweight : 109436 1 / 3 Observed Band : 109 Cell Pathway : Spliceosome, Background : elongation factor Tu GTP binding domain containing 2(EFTUD2) Homo sapiens This gene encodes a GTPase which is a component of the spliceosome complex which processes precursor mRNAs to produce mature mRNAs. Mutations in this gene are associated with mandibulofacial dysostosis with microcephaly. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Apr 2012], Function : function:Component of the U5 snRNP complex required for pre-mRNA splicing.,PTM:Phosphorylated upon DNA damage, -

Microarray Bioinformatics and Its Applications to Clinical Research
Microarray Bioinformatics and Its Applications to Clinical Research A dissertation presented to the School of Electrical and Information Engineering of the University of Sydney in fulfillment of the requirements for the degree of Doctor of Philosophy i JLI ··_L - -> ...·. ...,. by Ilene Y. Chen Acknowledgment This thesis owes its existence to the mercy, support and inspiration of many people. In the first place, having suffering from adult-onset asthma, interstitial cystitis and cold agglutinin disease, I would like to express my deepest sense of appreciation and gratitude to Professors Hong Yan and David Levy for harbouring me these last three years and providing me a place at the University of Sydney to pursue a very meaningful course of research. I am also indebted to Dr. Craig Jin, who has been a source of enthusiasm and encouragement on my research over many years. In the second place, for contexts concerning biological and medical aspects covered in this thesis, I am very indebted to Dr. Ling-Hong Tseng, Dr. Shian-Sehn Shie, Dr. Wen-Hung Chung and Professor Chyi-Long Lee at Change Gung Memorial Hospital and University of Chang Gung School of Medicine (Taoyuan, Taiwan) as well as Professor Keith Lloyd at University of Alabama School of Medicine (AL, USA). All of them have contributed substantially to this work. In the third place, I would like to thank Mrs. Inge Rogers and Mr. William Ballinger for their helpful comments and suggestions for the writing of my papers and thesis. In the fourth place, I would like to thank my swim coach, Hirota Homma. -

The Tumor Suppressor P53 Provides
Aus der Klinik für Innere Medizin, Schwerpunkt Hämatologie, Onkologie & Immunologie Direktor: Prof. Dr. Andreas Neubauer des Fachbereichs Medizin der Philipps-Universität Marburg Einfluss der DNA-Bindungskooperativität von p53 auf die Tumorsuppressoraktivität & Beobachtung der Entwicklungsdynamik von Tumorklonen in vitro & in vivo mittels sekretierter Luciferasen Inaugural-Dissertation zur Erlangung des Doktorgrades der Naturwissenschaften dem Fachbereich Medizin der Philipps-Universität Marburg vorgelegt von Joël Pierre Alexandre Charles aus Wiesbaden Marburg, 2015 Angenommen vom Fachbereich Medizin der Philipps-Universität Marburg am: Gedruckt mit Genehmigung des Fachbereichs. Dekan: Herr Prof. Dr. Helmut Schäfer Referent: Herr Prof. Dr. Thorsten Stiewe 1. Korreferent: Frau Prof. Dr. Uta-Maria Bauer Für meine Eltern INHALTSVERZEICHNIS Inhaltsverzeichnis Inhaltsverzeichnis ............................................................................................. I Zusammenfassung .......................................................................................... III Summary ........................................................................................................... V 1. EINLEITUNG .................................................................................................. 1 1.1. Krebs ................................................................................................................. 1 1.2. Tumorentwicklung........................................................................................... -

Chromosomal Breakpoints in Primary Colon Cancer Cluster at Sites of Structural Variants in the Genome
Research Article Chromosomal Breakpoints in Primary Colon Cancer Cluster at Sites of Structural Variants in the Genome Jordi Camps,1 Marian Grade,1,3 Quang Tri Nguyen,1 Patrick Ho¨rmann,1 Sandra Becker,1 Amanda B. Hummon,1 Virginia Rodriguez,2 Settara Chandrasekharappa,2 Yidong Chen,1 Michael J. Difilippantonio,1 Heinz Becker,3 B. Michael Ghadimi,3 and Thomas Ried1 1Genetics Branch, Center for Cancer Research, National Cancer Institute/NIH; 2Genome Technology Branch, National Human Genome Research Institute/NIH, Bethesda, Maryland; and 3Department of General and Visceral Surgery, University Medicine Go¨ttingen, Go¨ttingen, Germany Abstract 8q, 13, and 20q as well as losses of chromosomes 4q, 8p, 17p, and 18q (2). Genomic aberrations on chromosome 8 are common in colon cancer, and are associated with lymph node and distant Within the last decade, microarray technology has been metastases as well as with disease susceptibility. This extensively applied to survey the cellular transcriptome of common prompted us to generate a high-resolution map of genomic solid tumors, including colorectal cancer, and for colon cancers, imbalances of chromosome 8 in 51 primary colon carcinomas gene expression signatures were subsequently correlated with using a custom-designed genomic array consisting of a tiling clinical outcome (for reviews, see refs. 3–5). However, high- path of BAC clones. This analysis confirmed the dominant role resolution mapping of chromosomal copy number changes has of this chromosome. Unexpectedly, the position of the break- only recently been achieved using BAC or cDNA clone-based arrays points suggested colocalization with structural variants in the (6–10). -

WO 2016/164463 Al 13 October 2016 (13.10.2016) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2016/164463 Al 13 October 2016 (13.10.2016) P O P C T (51) International Patent Classification: (81) Designated States (unless otherwise indicated, for every C07H 21/04 (2006.01) C12N 15/113 (2010.01) kind of national protection available): AE, AG, AL, AM, C07H 21/00 (2006.01) AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, (21) Number: International Application DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, PCT/US20 16/0262 18 HN, HR, HU, ID, IL, IN, IR, IS, JP, KE, KG, KN, KP, KR, (22) International Filing Date: KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, MG, 6 April 2016 (06.04.2016) MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SA, SC, (25) Filing Language: English SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, (26) Publication Language: English TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (30) Priority Data: (84) Designated States (unless otherwise indicated, for every 62/144,219 7 April 2015 (07.04.2015) kind of regional protection available): ARIPO (BW, GH, 62/168,528 29 May 2015 (29.05.2015) GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, ST, SZ, 62/181,083 17 June 2015 (17.06.2015) TZ, UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, RU, TJ, TM), European (AL, AT, BE, BG, CH, CY, CZ, DE, (71) Applicant: THE GENERAL HOSPITAL CORPORA¬ DK, EE, ES, FI, FR, GB, GR, HR, HU, IE, IS, IT, LT, LU, TION [US/US]; 55 Fruit Street, Boston, Massachusetts LV, MC, MK, MT, NL, NO, PL, PT, RO, RS, SE, SI, SK, 021 14 (US). -

Dissertation
DISSERTATION Understanding human mitotic protein complex organisation and phospho-regulation using a combined proteomics and chemical biology approach angestrebter akademischer Grad Doktor der Naturwissenschaften (Dr. rer.nat.) Verfasser: Björn Hegemann Matrikel-Nummer: 0547126 Dissertationsgebiet: A 091 490 (Molekulare Biologie) Betreuer: Dr. Jan-Michael Peters Wien, am 02. Mai 2008 Table of Contents Table of Contents Table of Contents 1 Zusammenfassung 5 Abstract 7 1 Introduction 9 1.1 The cell cycle 9 1.2 Mechanisms of cell cycle control 11 1.3 Sister chromatid cohesion 13 1.4 Protein complexes in mitotic progression 14 1.4.1 How to detect protein complexes? 15 1.5 Mitotic protein kinases 17 1.5.1 How to find mitotic kinases substrates? 18 1.6 Aim of this study 20 2 Results 23 2.1 Manuscript in preparation: Systematic analysis of mitotic protein complexes using tandem affinity purification and mass spectrometry discovers 71 novel potential mitotic protein complexes 24 2.1.1 Abstract 24 2.1.2 Introduction 25 2.1.3 Results 27 2.1.3.1 Bait selection 27 2.1.3.2 Purification and LC-MS/MS analysis 28 2.1.3.3 Complex detection 29 2.1.3.4 Characterisation of novel complexes 33 2.1.3.5 Identification of ANAPC16 as a novel subunit of human APC/C 35 2.1.4 Discussion 38 2.1.5 Materials and methods 41 2.1.5.1 Cell culture and siRNA depletion 41 2.1.5.2 Protein extraction, purification and MS 41 2.1.5.3 Sucrose density gradients 43 2.1.5.4 Ubiquitination assay 43 2.1.5.5 Data processing and clustering analysis 43 2.1.5.6 Antibodies 44 2.1.5.7 Immunofluorescence -

TSSC4 Is a Component of U5 Snrnp That Promotes Tri-Snrnp Formation
ARTICLE https://doi.org/10.1038/s41467-021-23934-y OPEN TSSC4 is a component of U5 snRNP that promotes tri-snRNP formation Klára Klimešová 1,6, Jitka Vojáčková 1,6, Nenad Radivojević 1, Franck Vandermoere 2, ✉ Edouard Bertrand 3,4,5, Celine Verheggen 3,4,5 & David Staněk 1 U5 snRNP is a complex particle essential for RNA splicing. U5 snRNPs undergo intricate biogenesis that ensures that only a fully mature particle assembles into a splicing competent 1234567890():,; U4/U6•U5 tri-snRNP and enters the splicing reaction. During splicing, U5 snRNP is sub- stantially rearranged and leaves as a U5/PRPF19 post-splicing particle, which requires re- generation before the next round of splicing. Here, we show that a previously uncharacterized protein TSSC4 is a component of U5 snRNP that promotes tri-snRNP formation. We provide evidence that TSSC4 associates with U5 snRNP chaperones, U5 snRNP and the U5/PRPF19 particle. Specifically, TSSC4 interacts with U5-specific proteins PRPF8, EFTUD2 and SNRNP200. We also identified TSSC4 domains critical for the interaction with U5 snRNP and the PRPF19 complex, as well as for TSSC4 function in tri-snRNP assembly. TSSC4 emerges as a specific chaperone that acts in U5 snRNP de novo biogenesis as well as post-splicing recycling. 1 Institute of Molecular Genetics, Czech Academy of Sciences, Prague, Czech Republic. 2 Institut de Génomique Fonctionnelle, University of Montpellier, CNRS, INSERM, Montpellier, France. 3 Institut de Gené tiqué Moleculairé de Montpellier, University of Montpellier, CNRS, Montpellier, France. 4 Equipe labélisée Ligue Nationale Contre le Cancer, Montpellier, France. 5Present address: Institut de Génétique Humaine, Montpellier, France.