WO 2016/164463 Al 13 October 2016 (13.10.2016) P O P C T
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

DNA Damage Activates a Spatially Distinct Late Cytoplasmic Cell-Cycle Checkpoint Network Controlled by MK2-Mediated RNA Stabilization
DNA Damage Activates a Spatially Distinct Late Cytoplasmic Cell-Cycle Checkpoint Network Controlled by MK2-Mediated RNA Stabilization The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Reinhardt, H. Christian, Pia Hasskamp, Ingolf Schmedding, Sandra Morandell, Marcel A.T.M. van Vugt, XiaoZhe Wang, Rune Linding, et al. “DNA Damage Activates a Spatially Distinct Late Cytoplasmic Cell-Cycle Checkpoint Network Controlled by MK2-Mediated RNA Stabilization.” Molecular Cell 40, no. 1 (October 2010): 34–49.© 2010 Elsevier Inc. As Published http://dx.doi.org/10.1016/j.molcel.2010.09.018 Publisher Elsevier B.V. Version Final published version Citable link http://hdl.handle.net/1721.1/85107 Terms of Use Article is made available in accordance with the publisher's policy and may be subject to US copyright law. Please refer to the publisher's site for terms of use. Molecular Cell Article DNA Damage Activates a Spatially Distinct Late Cytoplasmic Cell-Cycle Checkpoint Network Controlled by MK2-Mediated RNA Stabilization H. Christian Reinhardt,1,6,7,8 Pia Hasskamp,1,10,11 Ingolf Schmedding,1,10,11 Sandra Morandell,1 Marcel A.T.M. van Vugt,5 XiaoZhe Wang,9 Rune Linding,4 Shao-En Ong,2 David Weaver,9 Steven A. Carr,2 and Michael B. Yaffe1,2,3,* 1David H. Koch Institute for Integrative Cancer Research, Department of Biology, Massachusetts Institute of Technology, Cambridge, MA 02132, USA 2Broad Institute of MIT and Harvard, Cambridge, MA 02132, USA 3Center for Cell Decision Processes, -

An Order Estimation Based Approach to Identify Response Genes
AN ORDER ESTIMATION BASED APPROACH TO IDENTIFY RESPONSE GENES FOR MICRO ARRAY TIME COURSE DATA A Thesis Presented to The Faculty of Graduate Studies of The University of Guelph by ZHIHENG LU In partial fulfilment of requirements for the degree of Doctor of Philosophy September, 2008 © Zhiheng Lu, 2008 Library and Bibliotheque et 1*1 Archives Canada Archives Canada Published Heritage Direction du Branch Patrimoine de I'edition 395 Wellington Street 395, rue Wellington Ottawa ON K1A0N4 Ottawa ON K1A0N4 Canada Canada Your file Votre reference ISBN: 978-0-494-47605-5 Our file Notre reference ISBN: 978-0-494-47605-5 NOTICE: AVIS: The author has granted a non L'auteur a accorde une licence non exclusive exclusive license allowing Library permettant a la Bibliotheque et Archives and Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par telecommunication ou par Plntemet, prefer, telecommunication or on the Internet, distribuer et vendre des theses partout dans loan, distribute and sell theses le monde, a des fins commerciales ou autres, worldwide, for commercial or non sur support microforme, papier, electronique commercial purposes, in microform, et/ou autres formats. paper, electronic and/or any other formats. The author retains copyright L'auteur conserve la propriete du droit d'auteur ownership and moral rights in et des droits moraux qui protege cette these. this thesis. Neither the thesis Ni la these ni des extraits substantiels de nor substantial extracts from it celle-ci ne doivent etre imprimes ou autrement may be printed or otherwise reproduits sans son autorisation. -

| Hai Lala at Matalamitaka Huoleht I
|HAI LALA AT MATALAMITAKAUS009816096B2 HUOLEHT I (12 ) United States Patent (10 ) Patent No. : US 9 ,816 , 096 B2 Heintz et al. (45 ) Date of Patent: Nov . 14 , 2017 ( 54 ) METHODS AND COMPOSITIONS FOR 6 , 143 , 566 A 11/ 2000 Heintz et al. TRANSLATIONAL PROFILING AND 6 , 156 , 574 A 12 / 2000 Heintz et al. 6 , 252 , 130 B1 6 / 2001 Federoff MOLECULAR PHENOTYPING 6 , 270, 969 B1 8 / 2001 Hartley et al. 6 , 403 ,374 B1 6 / 2002 Tsien et al. (71 ) Applicant: THE ROCKEFELLER 6 , 410 , 317 B1 6 /2002 Farmer UNIVERSITY , New York , NY (US ) 6 , 441 , 269 B1 8 / 2002 Serafini et al . 6 , 485 , 912 B1 11/ 2002 Heintz et al. @ 6 , 495 , 318 B2 12 / 2002 Harney ( 72 ) Inventors: Nathaniel Heintz , Pelham Manor, NY 6 ,635 ,422 B2 10 / 2003 Keene et al. (US ) ; Paul Greengard , New York , NY 6 , 821, 759 B1 11/ 2004 Heintz et al . (US ) ; Myriam Heiman , New York , NY 7 , 098, 031 B2B2 8 /2006 Choulika et al . (US ) ; Anne Schaefer , New York , NY 7 ,297 ,482 B2 11 /2007 Anderson et al . (US ) ; Joseph P . Doyle , New York , NY 7 , 393 , 632 B2 7 / 2008 Cheo et al. 2003 /0119104 A1 6 /2003 Perkins et al . (US ) ; Joseph D . Dougherty , St. Louis , 2004 / 0023256 A1 2 / 2004 Puglisi et al . MO (US ) 2005 / 0009028 Al 1 /2005 Heintz et al. 2006 /0183147 AL 8 /2006 Meyer - Franke (73 ) Assignee : THE ROCKEFELLER 2011/ 0314565 Al 12 /2011 Heintz et al . UNIVERSITY , New York , NY (US ) FOREIGN PATENT DOCUMENTS ( * ) Notice : Subject to any disclaimer , the term of this patent is extended or adjusted under 35 EP 1132479 A1 9 / 2001 WO WO -01 / 48480 A1 7 /2001 U . -

(12) Patent Application Publication (10) Pub. No.: US 2012/0264.634 A1 Amersdorfer Et Al
US 20120264.634A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2012/0264.634 A1 Amersdorfer et al. (43) Pub. Date: Oct. 18, 2012 (54) MARKER SEQUENCES FOR PANCREATIC Publication Classification CANCER DISEASES, PANCREATIC (51) Int. Cl. CARCINOMIA AND USE THEREOF C40B 30/04 (2006.01) GOIN 2L/64 (2006.01) (75) Inventors: Peter Amersdorfer, Graz (AT); GOIN 27/72 (2006.01) Annabel Höpfner, Dortmund (DE); C07K I4/435 (2006.01) Angelika Lueking, Bochum (DE) C40B 40/06 (2006.01) C40B 40/10 (2006.01) CI2N 5/09 (2010.01) (73) Assignee: PROTAGEN Aktiengesellschaft, C7H 2L/04 (2006.01) Dortmund (DE) GOIN 33/574 (2006.01) GOIN 27/62 (2006.01) (21) Appl. No.: 13/498,964 (52) U.S. Cl. ........... 506/9:436/501; 435/6.14; 435/7.92; 506/16:506/18: 435/2:536/23.1; 530/350 (22) PCT Filed: Sep. 29, 2010 (57) ABSTRACT The present invention relates to novel marker sequences for (86). PCT No.: PCT/EP2010/064510 pancreatic cancer diseases, pancreatic carcinoma and the diagnostic use thereof together with a method for Screening of S371 (c)(1), potential active Substances for pancreatic cancer diseases, (2), (4) Date: Jun. 22, 2012 pancreatic carcinoma by means of these marker sequences. Furthermore, the invention relates to a diagnostic device con (30) Foreign Application Priority Data taining Such marker sequences for pancreatic cancer diseases, pancreatic carcinoma, in particular a protein biochip and the Sep. 29, 2009 (EP) .................................. O9171690.2 use thereof. Patent Application Publication Oct. 18, 2012 US 2012/0264.634 A1 US 2012/0264.634 A1 Oct. -

Fine Mapping Studies of Quantitative Trait Loci for Baseline Platelet Count in Mice and Humans
Fine mapping studies of quantitative trait loci for baseline platelet count in mice and humans A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Melody C Caramins December 2010 University of New South Wales ORIGINALITY STATEMENT ‘I hereby declare that this submission is my own work and to the best of my knowledge it contains no materials previously published or written by another person, or substantial proportions of material which have been accepted for the award of any other degree or diploma at UNSW or any other educational institution, except where due acknowledgement is made in the thesis. Any contribution made to the research by others, with whom I have worked at UNSW or elsewhere, is explicitly acknowledged in the thesis. I also declare that the intellectual content of this thesis is the product of my own work, except to the extent that assistance from others in the project's design and conception or in style, presentation and linguistic expression is acknowledged.’ Signed …………………………………………….............. Date …………………………………………….............. This thesis is dedicated to my father. Dad, thanks for the genes – and the environment! ACKNOWLEDGEMENTS “Nothing can come out of nothing, any more than a thing can go back to nothing.” - Marcus Aurelius Antoninus A PhD thesis is never the work of one person in isolation from the world at large. I would like to thank the following people, without whom this work would not have existed. Thank you firstly, to all my teachers, of which there have been many. Undoubtedly, the greatest debt is owed to my supervisor, Dr Michael Buckley. -

Supplementary Table S2
1-high in cerebrotropic Gene P-value patients Definition BCHE 2.00E-04 1 Butyrylcholinesterase PLCB2 2.00E-04 -1 Phospholipase C, beta 2 SF3B1 2.00E-04 -1 Splicing factor 3b, subunit 1 BCHE 0.00022 1 Butyrylcholinesterase ZNF721 0.00028 -1 Zinc finger protein 721 GNAI1 0.00044 1 Guanine nucleotide binding protein (G protein), alpha inhibiting activity polypeptide 1 GNAI1 0.00049 1 Guanine nucleotide binding protein (G protein), alpha inhibiting activity polypeptide 1 PDE1B 0.00069 -1 Phosphodiesterase 1B, calmodulin-dependent MCOLN2 0.00085 -1 Mucolipin 2 PGCP 0.00116 1 Plasma glutamate carboxypeptidase TMX4 0.00116 1 Thioredoxin-related transmembrane protein 4 C10orf11 0.00142 1 Chromosome 10 open reading frame 11 TRIM14 0.00156 -1 Tripartite motif-containing 14 APOBEC3D 0.00173 -1 Apolipoprotein B mRNA editing enzyme, catalytic polypeptide-like 3D ANXA6 0.00185 -1 Annexin A6 NOS3 0.00209 -1 Nitric oxide synthase 3 SELI 0.00209 -1 Selenoprotein I NYNRIN 0.0023 -1 NYN domain and retroviral integrase containing ANKFY1 0.00253 -1 Ankyrin repeat and FYVE domain containing 1 APOBEC3F 0.00278 -1 Apolipoprotein B mRNA editing enzyme, catalytic polypeptide-like 3F EBI2 0.00278 -1 Epstein-Barr virus induced gene 2 ETHE1 0.00278 1 Ethylmalonic encephalopathy 1 PDE7A 0.00278 -1 Phosphodiesterase 7A HLA-DOA 0.00305 -1 Major histocompatibility complex, class II, DO alpha SOX13 0.00305 1 SRY (sex determining region Y)-box 13 ABHD2 3.34E-03 1 Abhydrolase domain containing 2 MOCS2 0.00334 1 Molybdenum cofactor synthesis 2 TTLL6 0.00365 -1 Tubulin tyrosine ligase-like family, member 6 SHANK3 0.00394 -1 SH3 and multiple ankyrin repeat domains 3 ADCY4 0.004 -1 Adenylate cyclase 4 CD3D 0.004 -1 CD3d molecule, delta (CD3-TCR complex) (CD3D), transcript variant 1, mRNA. -

ARP36414 P050) Data Sheet
SNRNP200 antibody - N-terminal region (ARP36414_P050) Data Sheet Product Number ARP36414_P050 Product Name SNRNP200 antibody - N-terminal region (ARP36414_P050) Size 50ug Gene Symbol SNRNP200 Alias Symbols ASCC3L1; BRR2; FLJ11521; HELIC2; RP33; U5-200KD Nucleotide Accession# NM_014014 Protein Size (# AA) 2136 amino acids Molecular Weight 244kDa Product Format Lyophilized powder NCBI Gene Id 23020 Host Rabbit Clonality Polyclonal Official Gene Full Name Small nuclear ribonucleoprotein 200kDa (U5) This is a rabbit polyclonal antibody against SNRNP200. It was validated on Western Blot by Aviva Systems Biology. At Aviva Systems Biology we manufacture rabbit polyclonal antibodies on a large scale (200-1000 Description products/month) of high throughput manner. Our antibodies are peptide based and protein family oriented. We usually provide antibodies covering each member of a whole protein family of your interest. We also use our best efforts to provide you antibodies recognize various epitopes of a target protein. For availability of antibody needed for your experiment, please inquire (). Peptide Sequence Synthetic peptide located within the following region: GDEDVYGEVREEASDDDMEGDEAVVRCTLSANLVASGELMSSKKKDLHPR Pre-mRNA splicing is catalyzed by the spliceosome, a complex of specialized RNA and protein subunits that removes introns from a transcribed pre-mRNA segment. The spliceosome consists of small nuclear RNA proteins (snRNPs) U1, U2, U4, U5 and U6, together with approximately 80 conserved proteins. U5 snRNP Description of Target contains nine specific proteins. This gene encodes one of the U5 snRNP-specific proteins. This protein belongs to the DEXH-box family of putative RNA helicases. It is a core component of U4/U6-U5 snRNPs and appears to catalyze an ATP-dependent unwinding of U4/U6 RNA duplices. -

RNA Dynamics in Alzheimer's Disease
molecules Review RNA Dynamics in Alzheimer’s Disease Agnieszka Rybak-Wolf 1,* and Mireya Plass 2,3,4,* 1 Max Delbrück Center for Molecular Medicine (MDC), Berlin Institute for Medical Systems Biology (BIMSB), 10115 Berlin, Germany 2 Gene Regulation of Cell Identity, Regenerative Medicine Program, Bellvitge Institute for Biomedical Research (IDIBELL), L’Hospitalet del Llobregat, 08908 Barcelona, Spain 3 Program for Advancing Clinical Translation of Regenerative Medicine of Catalonia, P-CMR[C], L’Hospitalet del Llobregat, 08908 Barcelona, Spain 4 Center for Networked Biomedical Research on Bioengineering, Biomaterials and Nanomedicine (CIBER-BBN), 28029 Madrid, Spain * Correspondence: [email protected] (A.R.-W.); [email protected] (M.P.) Abstract: Alzheimer’s disease (AD) is the most common age-related neurodegenerative disorder that heavily burdens healthcare systems worldwide. There is a significant requirement to understand the still unknown molecular mechanisms underlying AD. Current evidence shows that two of the major features of AD are transcriptome dysregulation and altered function of RNA binding proteins (RBPs), both of which lead to changes in the expression of different RNA species, including microRNAs (miRNAs), circular RNAs (circRNAs), long non-coding RNAs (lncRNAs), and messenger RNAs (mRNAs). In this review, we will conduct a comprehensive overview of how RNA dynamics are altered in AD and how this leads to the differential expression of both short and long RNA species. We will describe how RBP expression and function are altered in AD and how this impacts the expression of different RNA species. Furthermore, we will also show how changes in the abundance Citation: Rybak-Wolf, A.; Plass, M. -
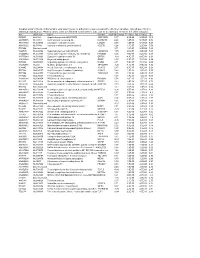
Supplementary File 2A Revised
Supplementary file 2A. Differentially expressed genes in aldosteronomas compared to all other samples, ranked according to statistical significance. Missing values were not allowed in aldosteronomas, but to a maximum of five in the other samples. Acc UGCluster Name Symbol log Fold Change P - Value Adj. P-Value B R99527 Hs.8162 Hypothetical protein MGC39372 MGC39372 2,17 6,3E-09 5,1E-05 10,2 AA398335 Hs.10414 Kelch domain containing 8A KLHDC8A 2,26 1,2E-08 5,1E-05 9,56 AA441933 Hs.519075 Leiomodin 1 (smooth muscle) LMOD1 2,33 1,3E-08 5,1E-05 9,54 AA630120 Hs.78781 Vascular endothelial growth factor B VEGFB 1,24 1,1E-07 2,9E-04 7,59 R07846 Data not found 3,71 1,2E-07 2,9E-04 7,49 W92795 Hs.434386 Hypothetical protein LOC201229 LOC201229 1,55 2,0E-07 4,0E-04 7,03 AA454564 Hs.323396 Family with sequence similarity 54, member B FAM54B 1,25 3,0E-07 5,2E-04 6,65 AA775249 Hs.513633 G protein-coupled receptor 56 GPR56 -1,63 4,3E-07 6,4E-04 6,33 AA012822 Hs.713814 Oxysterol bining protein OSBP 1,35 5,3E-07 7,1E-04 6,14 R45592 Hs.655271 Regulating synaptic membrane exocytosis 2 RIMS2 2,51 5,9E-07 7,1E-04 6,04 AA282936 Hs.240 M-phase phosphoprotein 1 MPHOSPH -1,40 8,1E-07 8,9E-04 5,74 N34945 Hs.234898 Acetyl-Coenzyme A carboxylase beta ACACB 0,87 9,7E-07 9,8E-04 5,58 R07322 Hs.464137 Acyl-Coenzyme A oxidase 1, palmitoyl ACOX1 0,82 1,3E-06 1,2E-03 5,35 R77144 Hs.488835 Transmembrane protein 120A TMEM120A 1,55 1,7E-06 1,4E-03 5,07 H68542 Hs.420009 Transcribed locus 1,07 1,7E-06 1,4E-03 5,06 AA410184 Hs.696454 PBX/knotted 1 homeobox 2 PKNOX2 1,78 2,0E-06 -

Aneuploidy: Using Genetic Instability to Preserve a Haploid Genome?
Health Science Campus FINAL APPROVAL OF DISSERTATION Doctor of Philosophy in Biomedical Science (Cancer Biology) Aneuploidy: Using genetic instability to preserve a haploid genome? Submitted by: Ramona Ramdath In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical Science Examination Committee Signature/Date Major Advisor: David Allison, M.D., Ph.D. Academic James Trempe, Ph.D. Advisory Committee: David Giovanucci, Ph.D. Randall Ruch, Ph.D. Ronald Mellgren, Ph.D. Senior Associate Dean College of Graduate Studies Michael S. Bisesi, Ph.D. Date of Defense: April 10, 2009 Aneuploidy: Using genetic instability to preserve a haploid genome? Ramona Ramdath University of Toledo, Health Science Campus 2009 Dedication I dedicate this dissertation to my grandfather who died of lung cancer two years ago, but who always instilled in us the value and importance of education. And to my mom and sister, both of whom have been pillars of support and stimulating conversations. To my sister, Rehanna, especially- I hope this inspires you to achieve all that you want to in life, academically and otherwise. ii Acknowledgements As we go through these academic journeys, there are so many along the way that make an impact not only on our work, but on our lives as well, and I would like to say a heartfelt thank you to all of those people: My Committee members- Dr. James Trempe, Dr. David Giovanucchi, Dr. Ronald Mellgren and Dr. Randall Ruch for their guidance, suggestions, support and confidence in me. My major advisor- Dr. David Allison, for his constructive criticism and positive reinforcement. -

Análise Correlacional Entre a Expressão Dos Fatores De Splicing E a Ocorrência De Splicing Alternativo Em Tecidos Humanos E De Camundongos
ANÁLISE CORRELACIONAL ENTRE A EXPRESSÃO DOS FATORES DE SPLICING E A OCORRÊNCIA DE SPLICING ALTERNATIVO EM TECIDOS HUMANOS E DE CAMUNDONGOS JULIO CÉSAR NUNES Dissertação apresentada à Fundação Antônio Prudente para a obtenção do título de Mestre em Ciências Área de Concentração: Oncologia Orientador: Dr. Sandro José de Souza São Paulo 2008 Livros Grátis http://www.livrosgratis.com.br Milhares de livros grátis para download. FICHA CATALOGRÁFICA Preparada pela Biblioteca da Fundação Antônio Prudente Nunes, Julio César Análise correlacional entre a expressão dos fatores de splicing e a ocorrência de splicing alternativo em tecidos humanos e de camundongos / Julio César Nunes – São Paulo, 2008. 79p. Dissertação (Mestrado) - Fundação Antônio Prudente. Curso de Pós-Graduação em Ciências - Área de concentração: Oncologia. Orientador: Sandro José Souza Descritores: 1. SPLICING ALTERNATIVO 2. BIOLOGIA MOLECULAR COMPUTACIONAL 3. CÂNCER 4. GENOMICA. AGRADECIMENTOS Agradeço à FAPESP e CAPES pela bolsa de Mestrado. Ao Sandro José de Souza agradeço toda orientação e conhecimento oferecido. Meus especiais agradecimentos ao Pedro Alexandre Favoretto Galante que dedicou atenção a minha formação no processo de Pós-Graduação na Fundação Antônio Prudente, bem como pela sua oficiosa co-orientação ao projeto de pesquisa. À grande família e amigos pela dedicação e incentivo a minha formação acadêmica. À Fundação Antônio Prudente, Hospital do Câncer e Instituto Ludwig de Pesquisa sobre o Câncer dedico os meus nobres agradecimentos finais. RESUMO Nunes JC. Análise correlacional entre a expressão dos fatores de splicing e a ocorrência de splicing alternativo em tecidos humanos e de camundongos. São Paulo; 2007. [Dissertacão de Mestrado - Fundação Antônio Prudente] Splicing alternativo desempenha uma significante função no aumento da complexidade genômica, produzindo um extenso número de mRNA e isoformas protéicas. -

Binding Specificities of Human RNA Binding Proteins Towards Structured
bioRxiv preprint doi: https://doi.org/10.1101/317909; this version posted March 1, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Binding specificities of human RNA binding proteins towards structured and linear 2 RNA sequences 3 4 Arttu Jolma1,#, Jilin Zhang1,#, Estefania Mondragón4,#, Teemu Kivioja2, Yimeng Yin1, 5 Fangjie Zhu1, Quaid Morris5,6,7,8, Timothy R. Hughes5,6, Louis James Maher III4 and Jussi 6 Taipale1,2,3,* 7 8 9 AUTHOR AFFILIATIONS 10 11 1Department of Medical Biochemistry and Biophysics, Karolinska Institutet, Solna, Sweden 12 2Genome-Scale Biology Program, University of Helsinki, Helsinki, Finland 13 3Department of Biochemistry, University of Cambridge, Cambridge, United Kingdom 14 4Department of Biochemistry and Molecular Biology and Mayo Clinic Graduate School of 15 Biomedical Sciences, Mayo Clinic College of Medicine and Science, Rochester, USA 16 5Department of Molecular Genetics, University of Toronto, Toronto, Canada 17 6Donnelly Centre, University of Toronto, Toronto, Canada 18 7Edward S Rogers Sr Department of Electrical and Computer Engineering, University of 19 Toronto, Toronto, Canada 20 8Department of Computer Science, University of Toronto, Toronto, Canada 21 #Authors contributed equally 22 *Correspondence: [email protected] 23 24 25 SUMMARY 26 27 Sequence specific RNA-binding proteins (RBPs) control many important 28 processes affecting gene expression. They regulate RNA metabolism at multiple 29 levels, by affecting splicing of nascent transcripts, RNA folding, base modification, 30 transport, localization, translation and stability. Despite their central role in most 31 aspects of RNA metabolism and function, most RBP binding specificities remain 32 unknown or incompletely defined.