Transaction / Regular Paper Title
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

American Meteorological Society Early Online
AMERICAN METEOROLOGICAL SOCIETY Bulletin of the American Meteorological Society EARLY ONLINE RELEASE This is a preliminary PDF of the author-produced manuscript that has been peer-reviewed and accepted for publication. Since it is being posted so soon after acceptance, it has not yet been copyedited, formatted, or processed by AMS Publications. This preliminary version of the manuscript may be downloaded, distributed, and cited, but please be aware that there will be visual differences and possibly some content differences between this version and the final published version. The DOI for this manuscript is doi: 10.1175/BAMS-D-13-00155.1 The final published version of this manuscript will replace the preliminary version at the above DOI once it is available. © 2014 American Meteorological Society Generated using version 3.2 of the official AMS LATEX template 1 Somewhere over the rainbow: How to make effective use of colors 2 in meteorological visualizations ∗ 3 Reto Stauffer, Georg J. Mayr and Markus Dabernig Institute of Meteorology and Geophysics, University of Innsbruck, Innsbruck, Austria 4 Achim Zeileis Department of Statistics, Faculty of Economics and Statistics, University of Innsbruck, Innsbruck, Austria ∗Reto Stauffer, Institute of Meteorology and Geophysics, University of Innsbruck, Innrain 52, A{6020 Innsbruck E-mail: reto.stauff[email protected] 1 5 CAPSULE 6 Effective visualizations have a wide scope of challenges. The paper offers guidelines, a 7 perception-based color space alternative to the famous RGB color space and several tools to 8 more effectively convey graphical information to viewers. 9 ABSTRACT 10 Results of many atmospheric science applications are processed graphically. -

Verfahren Zur Farbanpassung F ¨Ur Electronic Publishing-Systeme
Verfahren zur Farbanpassung f ¨ur Electronic Publishing-Systeme Von dem Fachbereich Elektrotechnik und Informationstechnik der Universit¨atHannover zur Erlangung des akademischen Grades Doktor-Ingenieur genehmigte Dissertation von Dipl.-Ing. Wolfgang W¨olker geb. am 7. Juli 1957, in Herford 1999 Referent: Prof. Dr.-Ing. C.-E. Liedtke Korreferent: Prof. Dr.-Ing. K. Jobmann Tag der Promotion: 18.01.1999 Kurzfassung Zuk ¨unftigePublikationssysteme ben¨otigenleistungsstarke Verfahren zur Farb- bildbearbeitung, um den hohen Durchsatz insbesondere der elektronischen Me- dien bew¨altigenzu k¨onnen. Dieser Beitrag beschreibt ein System f ¨urdie automatisierte Farbmanipulation von Einzelbildern. Die derzeit vorwiegend manuell ausgef ¨uhrtenAktionen wer- den durch hochsprachliche Vorgaben ersetzt, die vom System interpretiert und ausgef ¨uhrtwerden. Basierend auf einem hier vorgeschlagenen Grundwortschatz zur Farbmanipulation sind Modifikationen und Erweiterungen des Wortschat- zes durch neue abstrakte Begriffe m¨oglich.Die Kombination mehrerer bekannter Begriffe zu einem neuen abstrakten Begriff f ¨uhrtdabei zu funktionserweitern- den, komplexen Aktionen. Dar ¨uberhinaus pr¨agendiese Erg¨anzungenden in- dividuellen Wortschatz des jeweiligen Anwenders. Durch die hochsprachliche Schnittstelle findet eine Entkopplung der Benutzervorgaben von der technischen Umsetzung statt. Die farbverarbeitenden Methoden lassen sich so im Hinblick auf die verwendeten Farbmodelle optimieren. Statt der bisher ¨ublichenmedien- und ger¨atetechnischbedingten Farbmodelle kann nun z.B. das visuell adaptierte CIE(1976)-L*a*b*-Modell genutzt werden. Die damit m¨oglichenfarbverarbeiten- den Methoden erlauben umfangreiche und wirksame Eingriffe in die Farbdar- stellung des Bildes. Zielsetzung des Verfahrens ist es, unter Verwendung der vorgeschlagenen Be- nutzerschnittstelle, die teilweise wenig anschauliche Parametrisierung bestimm- ter Farbmodelle, durch einen hochsprachlichen Zugang zu ersetzen, der den An- wender bei der Farbbearbeitung unterst ¨utztund den Experten entlastet. -

Measuring Perceived Color Difference Using YIQ NTSC Transmission Color Space in Mobile Applications
Programación Matemática y Software (2010) Vol.2. Num. 2. Dirección de Reservas de Derecho: 04-2009-011611475800-102 Measuring perceived color difference using YIQ NTSC transmission color space in mobile applications Yuriy Kotsarenko, Fernando Ramos TECNOLÓGICO DE DE MONTERREY, CAMPUS CUERNAVACA. Resumen. En este trabajo varias formulas están introducidas que permiten calcular la medir la diferencia entre colores de forma perceptible, utilizando el espacio de colores YIQ. Las formulas clásicas y sus derivados que utilizan los espacios CIELAB y CIELUV requieren muchas transformaciones aritméticas de valores entrantes definidos comúnmente con los componentes de rojo, verde y azul, y por lo tanto son muy pesadas para su implementación en dispositivos móviles. Las formulas alternativas propuestas en este trabajo basadas en espacio de colores YIQ son sencillas y se calculan rápidamente, incluso en tiempo real. La comparación está incluida en este trabajo entre las formulas clásicas y las propuestas utilizando dos diferentes grupos de experimentos. El primer grupo de experimentos se enfoca en evaluar la diferencia perceptible utilizando diferentes formulas, mientras el segundo grupo de experimentos permite determinar el desempeño de cada una de las formulas para determinar su velocidad cuando se procesan imágenes. Los resultados experimentales indican que las formulas propuestas en este trabajo son muy cercanas en términos perceptibles a las de CIELAB y CIELUV, pero son significativamente más rápidas, lo que los hace buenos candidatos para la medición de las diferencias de colores en dispositivos móviles y aplicaciones en tiempo real. Abstract. An alternative color difference formulas are presented for measuring the perceived difference between two color samples defined in YIQ color space. -

Color Spaces YCH and Ysch for Color Specification and Image Processing in Multi-Core Computing and Mobile Systems
Programación Matemática y Software (2012) Vol. 4. No 2. ISSN: 2007-3283 Recibido: 14 de septiembre del 2011 Aceptado: 3 de enero del 2012 Publicado en línea: 8 de enero del 2013 Color spaces YCH and YScH for color specification and image processing in multi-core computing and mobile systems Yuriy Kotsarenko, Fernando Ramos Tecnológico de Monterrey, Campus Cuernavaca [email protected], [email protected] Resumen. En este trabajo dos nuevos espacios de color se describen para especificación de colores y procesamiento de imágenes utilizando la forma cilíndrica del espacio de color YIQ. Los espacios de colores clásicos tales como HSL y HSV no toman en cuenta la visión humana y son perceptualmente inexactos. Los espacios de colores perceptualmente uniformes como CIELAB y CIELUV son muy costosos computacionalmente para aplicaciones interactivas de tiempo real y son difíciles de implementar. Las alternativas propuestas, por otro lado, tienen un balance entre uniformidad perceptual, desempeño y simplicidad de cálculo. Estos espacios modelan colores de forma más exacta y son rápidos de calcular. Los resultados experimentales en este trabajo comparan espacios de colores clásicos con los propuestos en términos de uniformidad, riqueza de colores y desempeño, incluyendo numerosas pruebas de rapidez en procesadores de varios núcleos y sistemas móviles tales como ultra portátiles y los tablets tipo iPad. Los resultados evidencian que los espacios de colores propuestos son mejores alternativas para la industria de computación donde actualmente se utilicen los espacios de colores clásicos. Abstract. Two novel color spaces are described for color specification and image processing using cylindrical variants of YIQ color space. -

Polychrome: Creating and Assessing Qualitative Palettes with Many Colors
bioRxiv preprint doi: https://doi.org/10.1101/303883; this version posted April 18, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. JSS Journal of Statistical Software MMMMMM YYYY, Volume VV, Code Snippet II. http://www.jstatsoft.org/ Polychrome: Creating and Assessing Qualitative Palettes With Many Colors Kevin R. Coombes Guy Brock Zachary B. Abrams The Ohio State University The Ohio State University The Ohio State University Lynne V. Abruzzo The Ohio State University Abstract Although R includes numerous tools for creating color palettes to display continuous data, facilities for displaying categorical data primarily use the RColorBrewer package, which is, by default, limited to 12 colors. The colorspace package can produce more colors, but it is not immediately clear how to use it to produce colors that can be reliably distingushed in different kinds of plots. However, applications to genomics would be enhanced by the ability to display at least the 24 human chromosomes in distinct colors, as is common in technologies like spectral karyotyping. In this article, we describe the Polychrome package, which can be used to construct palettes with at least 24 colors that can be distinguished by most people with normal color vision. Polychrome includes a variety of visualization methods allowing users to evaluate the proposed palettes. In addition, we review the history of attempts to construct qualitative color palettes with many colors. Keywords: color, palette, categorical data, spectral karyotyping, R. -

Quality Measurement of Existing Color Metrics Using Hexagonal Color Fields Yuriy Kotsarenko1, Fernando Ramos1
Quality Measurement of Existing Color Metrics using Hexagonal Color Fields Yuriy Kotsarenko1, Fernando Ramos1 1 Instituto Tecnológico de Estudios Superiores de Monterrey Abstract. In the area of colorimetry there are many color metrics developed, such as those based on the CIELAB color space, which measure the perceptual difference between two colors. However, in software applications the typical images contain hundreds of different colors. In the case where many colors are seen by human eye, the perceived result might be different than if looking at only two of these colors at once. This work presents an alternative approach for measuring the perceived quality of color metrics by comparing several neighboring colors at once. The colors are arranged in a two dimensional board using hexagonal shapes, for every new element its color is compared to all currently available neighbors and the closest match is used. The board elements are filled from the palette with specific color set. The overall result can be judged visually on any monitor where output is sRGB compliant. Keywords: color metric, perceptual quality, color neighbors, quality estimation. 1. Introduction In the software applications there are applications where several colors need to be compared in order to determine the color that better matches the given sample. For instance, in stereo vision the colors from two separate cameras are compared to determine the visible depth. In image compression algorithms the colors of neighboring pixels are compared to determine what information should be discarded or preserved. Another example is color dithering – an approach, where color pixels are accommodated in special way to improve the overall look of the image. -

Transforming Thermal Images to Visible Spectrum Images Using Deep Learning
Master of Science Thesis in Electrical Engineering Department of Electrical Engineering, Linköping University, 2018 Transforming Thermal Images to Visible Spectrum Images using Deep Learning Adam Nyberg Master of Science Thesis in Electrical Engineering Transforming Thermal Images to Visible Spectrum Images using Deep Learning Adam Nyberg LiTH-ISY-EX–18/5167–SE Supervisor: Abdelrahman Eldesokey isy, Linköpings universitet David Gustafsson FOI Examiner: Per-Erik Forssén isy, Linköpings universitet Computer Vision Laboratory Department of Electrical Engineering Linköping University SE-581 83 Linköping, Sweden Copyright © 2018 Adam Nyberg Abstract Thermal spectrum cameras are gaining interest in many applications due to their long wavelength which allows them to operate under low light and harsh weather conditions. One disadvantage of thermal cameras is their limited visual inter- pretability for humans, which limits the scope of their applications. In this the- sis, we try to address this problem by investigating the possibility of transforming thermal infrared (TIR) images to perceptually realistic visible spectrum (VIS) im- ages by using Convolutional Neural Networks (CNNs). Existing state-of-the-art colorization CNNs fail to provide the desired output as they were trained to map grayscale VIS images to color VIS images. Instead, we utilize an auto-encoder ar- chitecture to perform cross-spectral transformation between TIR and VIS images. This architecture was shown to quantitatively perform very well on the problem while producing perceptually realistic images. We show that the quantitative differences are insignificant when training this architecture using different color spaces, while there exist clear qualitative differences depending on the choice of color space. Finally, we found that a CNN trained from day time examples generalizes well on tests from night time. -

CIC24 Twenty-Fourth Color and Imaging Conference Preliminary
P November 7-11, 2016 R San Diego, CA E L CIC24 I Twenty-fourth Color and Imaging M I Conference Color Science and Engineering Systems, Technologies, and N Applications A R Y P R O G R A M Early Registration Deadline: October 9, 2016 www.imaging.org/color IS&T Sponsored by Society for Imaging Science and Technology imaging.org November 7 – 11, 2016 • San Diego, CA Table of Contents Sponsors Conference At-a-Glance . 1 Google Inc. Hewlett-Packard Company Venue Information . 1 Image Engineering GmbH Short Course Program . 2 IS&T Sustaining Corporate Members Short Courses At-a-Glance . 5 Adobe Systems Inc. CIC24 Technical Program . 14 HCL America CIC24 Workshops . 19 Hewlett-Packard Company Qualcomm Technologies, Inc. ICC DevCon 2016 . 22 Samsung Electronics Company Ltd. Hotel and Transportation Info . 23 Xerox Corporation Conference Registration . 24 Cooperating Societies • Associazione Italiana Colore • Inter-Society Color Council (ISCC) • Comité de Color • IOP Printing and Graphics Science Group • The Colour Group (Great Britain) • Swedish Colour Centre Foundation • Deutsche Gesellschaft für Angewandte Optik, DGaO • The Royal Photographic Society of Great Britain • Flemish Innovation Centre for Graphic Communications • Society of Motion Picture and Television Engineers VIGC (SMPTE) • German Society for Color Science and Application (DfwG) • Society of Photographic Science and Technology of • Imaging Society of Japan (ISJ) Japan (SPSTJ) Program Committee General Chair Workshop Chairs CIC Steering Committee Philipp Urban Nicolas Bonnier Vien Cheung Fraunhofer Institute for Apple Inc. (USA) University of Leeds (UK) Computer Graphics Research Maria Vanrell Graham Finlayson IGD (Germany) Universitat Autònoma de University of East Anglia (UK) Barcelona (Spain) Suzanne Grinnan Technical Program Chairs IS&T (USA) Michael J. -
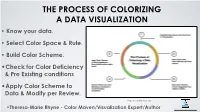
Know Your Data. • Select Color Space & Rule. • Build Color
THE PROCESS OF COLORIZING A DATA VISUALIZATION • Know your data. • Select Color Space & Rule. • Build Color Scheme. •Check for Color Deficiency & Pre Existing conditions •Apply Color Scheme to Data & Modify per Review. Image: Theresa-Marie Rhyne 2021 •Theresa-Marie Rhyne - Color Maven/Visualization1 Expert/Author [email protected] (1) KNOW OR IDENTIFY THE NATURE OF YOUR DATA • Nominal - name/no order-e.g. eye color. • Ordinal - rank - low, medium, high - no info on degree of difference. • Interval - differentiated by degree of difference - numerical values have positive, negative or zero. • Ratio - data distinguished by the degree of difference - Age, Height, Duration • Discrete - only whole numbers & some kind of count • Continuous - data take any value - computational Chart prepared by Georges Hattab, see: Ten simple rules to colorize biological data visualization by Hattab, Rhyne & Heider, model https://journals.plos.org/ploscompbiol/article?id=10.1371/ journal.pcbi.1008259 Binary/Dichotomous - 2 possible values- Yes or No • 2 [email protected] (1) KNOW OR IDENTIFY THE NATURE OF YOUR DATA For the example I will work through in this talk: I want to build a set of bar charts using the 5 point Likert scale of Strongly Agree, Agree, Neutral, Disagree and Strongly Disagree. Magenta is my Key Color. • Ordinal - categorical attributes of a Image: Theresa-Marie Rhyne 2021 variable differentiated by order (rank, scale, or position) Getting it Right in Black & White. • Key Color: Magenta (#FC56FF in Hex Code) 3 [email protected] (2A) SELECT COLOR SPACE & RULE: 3 CLASSIC MODELS RGB adds with lights. CMYK subtracts for printing. RYB subtracts to mix paints. -

How to Make Effective Use of Colors in Meteorological Visualizations
Escaping RGBland: How to make effective use of colors in meteorological visualizations Reto Stauffer1, Achim Zeileis2, Georg J. Mayr1, Markus Dabernig1 University of Innsbruck INTRODUCTION EXAMPLE II: WARNING MAP AUSTRIA In meteorology, visualizations are an essential part of the everyday work. Most figures are contain- (A.1) (B.1) ing colors. The Red-Green-Blue (RGB) based color palettes provided as default by most common software packages can lead to various problems. An alternative is the Hue-Chroma-Luminance (HCL) color space. The HCL color space is based on how we perceive colors. Based on HCL palettes one can strongly improve the visual output with barely no additional effort and help the end-user to gather complex data as easy as possible. (A.2) (B.2) HOW COLORS SHOULD BE natural & simpel: no highly-saturated colors; manageable number of colors (A.3) (B.3) guiding: help the reader to gather the information; guide to most important parts supportive: lead the reader; reproduce well-known patterns (e.g. water is blue) appealing & relaxing: if not: reader can get lost, very strenuous for the eye customized: who has to interpret the image? regarding visual constraints? Figure 3: A severe weather alert map (high amounts of precipitation) for Austria, 31th of Mai 2013. Label (A) for the work everywhere: screen, projector, color- and gray-scale printers original colors, label (B) for the modified HCL version. From 1 to 3: colorized version; desaturated version; simulated version for people with Deuteranopia (red-green blindness). Source: www.uwz.ch, UBIMET GmbH. The second example shows an alert map for Austria. -

Choosing Color Palettes for Statistical Graphics
ePubWU Institutional Repository Achim Zeileis and Kurt Hornik Choosing Color Palettes for Statistical Graphics Paper Original Citation: Zeileis, Achim and Hornik, Kurt ORCID: https://orcid.org/0000-0003-4198-9911 (2006) Choosing Color Palettes for Statistical Graphics. Research Report Series / Department of Statistics and Mathematics, 41. Department of Statistics and Mathematics, WU Vienna University of Economics and Business, Vienna. This version is available at: https://epub.wu.ac.at/1404/ Available in ePubWU: October 2006 ePubWU, the institutional repository of the WU Vienna University of Economics and Business, is provided by the University Library and the IT-Services. The aim is to enable open access to the scholarly output of the WU. http://epub.wu.ac.at/ Choosing Color Palettes for Statistical Graphics Achim Zeileis, Kurt Hornik Department of Statistics and Mathematics Wirtschaftsuniversität Wien Research Report Series Report 41 October 2006 http://statmath.wu-wien.ac.at/ Choosing Color Palettes for Statistical Graphics Achim Zeileis and Kurt Hornik Wirtschaftsuniversit¨at Wien, Austria Abstract Statistical graphics are often augmented by the use of color coding information contained in some variable. When this involves the shading of areas (and not only points or lines)— e.g., as in bar plots, pie charts, mosaic displays or heatmaps—it is important that the colors are perceptually based and do not introduce optical illusions or systematic bias. Here, we discuss how the perceptually-based Hue-Chroma-Luminance (HCL) color space can be used for deriving suitable color palettes for coding categorical data (qualitative palettes) and numerical variables (sequential and diverging palettes). Keywords: qualitative palette, sequential palette, diverging palette, HCL colors, HSV colors, perceptually-based color space. -

Book IX Composition
D DD DD Composition DDDDon.com DDDD Basic Photography in 180 Days Book IX - Composition Editor: Ramon F. aeroramon.com Contents 1 Day 1 1 1.1 Composition (visual arts) ....................................... 1 1.1.1 Elements of design ...................................... 1 1.1.2 Principles of organization ................................... 3 1.1.3 Compositional techniques ................................... 4 1.1.4 Example ............................................ 8 1.1.5 See also ............................................ 9 1.1.6 References .......................................... 9 1.1.7 Further reading ........................................ 9 1.1.8 External links ......................................... 9 1.2 Elements of art ............................................ 9 1.2.1 Form ............................................. 10 1.2.2 Line ............................................. 10 1.2.3 Color ............................................. 10 1.2.4 Space ............................................. 10 1.2.5 Texture ............................................ 10 1.2.6 See also ............................................ 10 1.2.7 References .......................................... 10 1.2.8 External links ......................................... 11 2 Day 2 12 2.1 Visual design elements and principles ................................. 12 2.1.1 Design elements ........................................ 12 2.1.2 Principles of design ...................................... 15 2.1.3 See also ...........................................