Gene Duplication and an Accelerated Evolutionary Rate in 11S Globulin Genes Are Associated with Higher Protein Synthesis in Dicots As Compared to Monocots
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Evolutionary Perspective on Human Cross-Sensitivity to Tree Nut and Seed Allergens," Aliso: a Journal of Systematic and Evolutionary Botany: Vol
Aliso: A Journal of Systematic and Evolutionary Botany Volume 33 | Issue 2 Article 3 2015 An Evolutionary Perspective on Human Cross- sensitivity to Tree Nut and Seed Allergens Amanda E. Fisher Rancho Santa Ana Botanic Garden, Claremont, California, [email protected] Annalise M. Nawrocki Pomona College, Claremont, California, [email protected] Follow this and additional works at: http://scholarship.claremont.edu/aliso Part of the Botany Commons, Evolution Commons, and the Nutrition Commons Recommended Citation Fisher, Amanda E. and Nawrocki, Annalise M. (2015) "An Evolutionary Perspective on Human Cross-sensitivity to Tree Nut and Seed Allergens," Aliso: A Journal of Systematic and Evolutionary Botany: Vol. 33: Iss. 2, Article 3. Available at: http://scholarship.claremont.edu/aliso/vol33/iss2/3 Aliso, 33(2), pp. 91–110 ISSN 0065-6275 (print), 2327-2929 (online) AN EVOLUTIONARY PERSPECTIVE ON HUMAN CROSS-SENSITIVITY TO TREE NUT AND SEED ALLERGENS AMANDA E. FISHER1-3 AND ANNALISE M. NAWROCKI2 1Rancho Santa Ana Botanic Garden and Claremont Graduate University, 1500 North College Avenue, Claremont, California 91711 (Current affiliation: Department of Biological Sciences, California State University, Long Beach, 1250 Bellflower Boulevard, Long Beach, California 90840); 2Pomona College, 333 North College Way, Claremont, California 91711 (Current affiliation: Amgen Inc., [email protected]) 3Corresponding author ([email protected]) ABSTRACT Tree nut allergies are some of the most common and serious allergies in the United States. Patients who are sensitive to nuts or to seeds commonly called nuts are advised to avoid consuming a variety of different species, even though these may be distantly related in terms of their evolutionary history. -

(12) United States Patent (10) Patent No.: US 7,537,914 B1 Roux Et Al
USOO7537914B1 (12) United States Patent (10) Patent No.: US 7,537,914 B1 ROux et al. (45) Date of Patent: May 26, 2009 (54) NUCLEICACID AND ALLERGENIC (58) Field of Classification Search ................ 435/69.1, POLYPEPTIDESENCODED THEREBY IN 435/252.3,320.1; 530/350; 536/23.5 CASHEW NUTS (ANACARDIUM See application file for complete search history. OCCIDENTALE) (56) References Cited (75) Inventors: Kenneth Roux, Tallahassee, FL (US); U.S. PATENT DOCUMENTS Shridhar K. Sathe, Tallahassee, FL (US); Jason M. Robotham, Tallahassee, 6,362,399 B1* 3/2002 Kinney et al. ............... 800/312 FL (US); Suzanne S. Teuber, Davis, CA (US) OTHER PUBLICATIONS Wang etal, J Allergy Clin Immunol 110: 160-6, 2002.* (73) Assignee: Florida State University Research Chica et al. Curr Opin Biotechnol 16(4):378-84. Aug. 2005.* Foundation, Inc., Tallahassee, FL (US) Witkowski et al. Biochemistry 38(36): 11643-50, Sep. 7, 1999.* Stanley et al. Arch Biochem Biophys 342(2): 244-53, Jun. 1997.* (*) Notice: Subject to any disclaimer, the term of this patent is extended or adjusted under 35 * cited by examiner U.S.C. 154(b) by 323 days. Primary Examiner Phuong Huynh (74) Attorney, Agent, or Firm Allen, Dyer, Doppelt, (21) Appl. No.: 10/529,602 Milbrath & Gilchrist, PA. (22) PCT Filed: Nov. 4, 2003 (57) ABSTRACT (86). PCT No.: PCT/USO3F34960 The invention describes an isolated nucleic acid sequence S371 (c)(1), comprising the nucleotide sequence of SEQ ID NO:1 or a (2), (4) Date: Mar. 30, 2005 degenerate variant of SEQ ID NO:1. The nucleic acid sequence encodes an Ig-Ebinding immunogenic polypeptide (87) PCT Pub. -

Impact of High Pressure Processing on Immunoreactivity and Some Physico-Chemical Properties of Almond Milk THESIS Presented in P
Impact of High Pressure Processing on Immunoreactivity and Some Physico-chemical Properties of Almond Milk THESIS Presented in Partial Fulfillment of the Requirements for the Degree Master of Science in the Graduate School of The Ohio State University By Santosh Dhakal Graduate Program in Food Science and Technology The Ohio State University 2013 Master's Examination Committee: Professor V. M. Balasubramaniam, Advisor Professor Sheryl Barringer Professor Monica Giusti Copyrighted by Santosh Dhakal 2013 ABSTRACT Almond milk as a beverage has recently gained attention with increase in consumer awareness about health benefits of plant based beverages. The objective of this research was to investigate the influence of high pressure processing (HPP) on residual mmunoreactivity, protein solubility, and other selected quality attributes. Almond milk was prepared by disintegrating 10% almonds with water and were subjected to high pressure processing (HPP; 450 and 600 MPa at 30oC up to 600 s) and thermal processing (TP; 72, 85 and 99 oC, 0.1 MPa up to 600 s). After HPP (for all holding times), amandin, a key thermally resistant almond allergen, can no longer be detected by the anti-conformational epitopes MAb in ELISA while signal generated from the anti-linear epitopes MAb was reduced by half (P < 0.05). On the other hand, most TP samples did not show significant reductions in immunoreactivity (P > 0.05) unless processed at 85 and 99 °C for 300 s. Western blot (applicable for soluble proteins) and dot blot (applicable for soluble and insoluble proteins) also confirmed the loss of immunoreactivity by both antibodies for HPP almond milk. -

Structural Characterization of Bacterial Defense Complex Marko Nedeljković
Structural characterization of bacterial defense complex Marko Nedeljković To cite this version: Marko Nedeljković. Structural characterization of bacterial defense complex. Biomolecules [q-bio.BM]. Université Grenoble Alpes, 2017. English. NNT : 2017GREAV067. tel-03085778 HAL Id: tel-03085778 https://tel.archives-ouvertes.fr/tel-03085778 Submitted on 22 Dec 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. THÈSE Pour obtenir le grade de DOCTEUR DE LA COMMUNAUTE UNIVERSITE GRENOBLE ALPES Spécialité : Biologie Structurale et Nanobiologie Arrêté ministériel : 25 mai 2016 Présentée par Marko NEDELJKOVIĆ Thèse dirigée par Andréa DESSEN préparée au sein du Laboratoire Institut de Biologie Structurale dans l'École Doctorale Chimie et Sciences du Vivant Caractérisation structurale d'un complexe de défense bactérienne Structural characterization of a bacterial defense complex Thèse soutenue publiquement le 21 décembre 2017, devant le jury composé de : Monsieur Herman VAN TILBEURGH Professeur, Université Paris Sud, Rapporteur Monsieur Laurent TERRADOT Directeur de Recherche, Institut de Biologie et Chimie des Protéines, Rapporteur Monsieur Patrice GOUET Professeur, Université Lyon 1, Président Madame Montserrat SOLER-LOPEZ Chargé de Recherche, European Synchrotron Radiation Facility, Examinateur Madame Andréa DESSEN Directeur de Recherche, Institut de Biologie Structurale , Directeur de These 2 Contents ABBREVIATIONS .............................................................................................................................. -

TWO NOVEL MECHANISMS of MHC CLASS I DOWN- REGULATION in HUMAN CANCER: ACCELERATED DEGRADATION of TAP-1 Mrna and DISRUPTION of TAP-1 PROTEIN FUNCTION
TWO NOVEL MECHANISMS OF MHC CLASS I DOWN- REGULATION IN HUMAN CANCER: ACCELERATED DEGRADATION OF TAP-1 mRNA AND DISRUPTION OF TAP-1 PROTEIN FUNCTION DISSERTATION Presented in Partial Fulfillment of the Requirement for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University by Tianyu Yang * * * * * The Ohio State University 2004 Dissertation Committee: Approved by Professor Pan Zheng, Adviser Professor Yang Liu Professor Joan Durbin Professor Xuefeng Bai Adviser Department of Pathology Professor William Lafuse ABSTRACT Both viruses and tumors evade cytotoxic T lymphocyte (CTL)-mediated host immunity by down-regulation of major histocompatibility complex (MHC) class I antigen presentation machinery. The transporter associated with antigen processing (TAP), a heterodimer of TAP-1 and TAP-2, plays essential role in the MHC class I- restricted antigen presentation pathway by translocating antigenic peptides from cytosol into the ER lumen, where the assembly of MHC class I complex takes place. TAP deficiency is a frequent observation in human cancers, which is one of the causes of MHC class I down-regulation. However, the underlying molecular mechanism has been limited. In search for novel mechanisms of TAP deficiency and MHC class I down- regulation in human cancer cells, we characterized an MHC class I-deficient melanoma cell line SK-MEL-19. The expression of TAP-1 mRNA was found deficient in this cell line even after interferon-gamma (IFN-γ) stimulation, despite its active transcription. This abnormality is caused by a single nucleotide deletion at position +1489 of the TAP- 1 gene, which results in rapid degradation of the TAP-1 mRNA. -

Allergenic Cross-Reactivity Between Cashew and Pistachio Nuts Pallavi D
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2004 Allergenic Cross-Reactivity Between Cashew and Pistachio Nuts Pallavi D. Tawde Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES ALLERGENIC CROSS-REACTIVITY BETWEEN CASHEW AND PISTACHIO NUTS By PALLAVI D TAWDE A Thesis submitted to the Department of Biological Science in partial fulfillment of the requirements for the degree of Master of Science Degree Awarded: Fall Semester, 2004 The members of the Committee approve the Thesis of Pallavi D Tawde defended on Nov 15, 2004. Kenneth Roux Professor Directing Thesis Shridhar Sathe Outside Committee Member Tom Keller Committee Member Approved: Timothy Moerland, Chair, Department of Biological Science The Office of Graduate Studies has verified and approved the above named committee members. ii For my parents iii ACKNOWLEDGEMENTS First and foremost, I would like to thank Florida State University and the Department of Biology for providing me with the opportunity to conduct the research of my interest. I would like to offer my gratitude to my committee members, Dr. Shridhar Sathe, and Dr. Tom Keller for their consistent support and advice on this project. Dr. Sathe and his lab provided us with valuable tree nut protein samples, which formed an essential component of this research. Most importantly, I would like to thank my committee members for being highly accommodative and having agreed to read my submitted thesis in less than a week’s time. For having provided me with tree nut allergic patients sera, I would like to thank Dr. -
Pomwisedr1207.Pdf (3.927Mb)
STUDIES OF PEPTIDE MIMICRY OF THE GROUP B STREPTOCOCCUS TYPE III CAPSULAR POLYSACCHARIDE ANTIGEN by Rattanaruji Pomwised A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Microbiology MONTANA STATE UNIVERSITY Bozeman, Montana August 2007 © COPYRIGHT by Rattanaruji Pomwised 2007 All Rights Reserve ii APPROVAL of a dissertation submitted by Rattanaruji Pomwised This dissertation has been read by each member of the dissertation committee and has been found to be satisfactory regarding content, English usage, format, citations, bibliographic style, and consistency, and is ready for submission to the Division of Graduate Education. Dr. Mark Young Approved for the Department of Microbiology Dr. Tim Ford Approved for the Division of Graduate Education Dr. Carl A. Fox iii STATEMENT OF PERMISSION TO USE In presenting this dissertation in partial fulfillment of the requirements for a doctoral degree at Montana State University, I agree that the library shall make it available to borrowers under rules of the Library. I further agree that copying of this dissertation is allowable only for scholarly purposes, consistent with “fair use” as prescribed in the U.S. Copyright Law. Requests for extensive copying or reproduction of this dissertation should be referred to ProQuest Information and Learning, 300 North Zeeb Road, Ann Arbor, Michigan 48106, to whom I have granted “the exclusive right to reproduce and distribute my dissertation in and from microform along with the non- exclusive right to reproduce and distribute my abstract in any format in whole or in part.” Rattanaruji Pomwised August, 2007 iv ACKNOWLEDGEMENTS I would first like to thank my parents, Damnern and Samroum, and my brother, Natthakon for all the unconditional love and support during my graduate studies. -

Characterization of the 11S Globulin Gene Family in the Castor Plant Ricinus Communis L
272 J. Agric. Food Chem. 2010, 58, 272–281 DOI:10.1021/jf902970p Characterization of the 11S Globulin Gene Family in the Castor Plant Ricinus communis L. TARIK CHILEH,BELEN ESTEBAN-GARCI´A,DIEGO LoPEZ ALONSO, AND FEDERICO GARCI´A-MAROTO* Grupo de Biotecnologı´a de Productos Naturales (BIO279), Facultad de Ciencias Experimentales, Universidad de Almerı´a, Campus de La Canada~ 04120, Spain The 11S globulin (legumin) gene family has been characterized in the castor plant Ricinus communis L. Phylogenetic analysis reveals the presence of two diverged subfamilies (RcLEG1 and RcLEG2) comprising a total of nine genes and two putative pseudogenes. The expression of castor legumin genes has been studied, indicating that it is seed specific and developmentally regulated, with a maximum at the stage when cellular endosperm reaches its full expansion (around 40-45 DAP). However, conspicuous differences are appreciated in the expression timing of individual genes. A characterization of the 50-proximal regulatory regions for two genes, RcLEG1-1 and RcLEG2-1, representative of the two legumin subfamilies, has also been performed by fusion to the GUS reporter gene. The results obtained from heterologous expression in tobacco and transient expression in castor, indicating seed-specific regulation, support the possible utility of these promoters for biotechnological purposes. KEYWORDS: 11S globulins; legumins; castor bean; Ricinus communis; seed development; storage proteins; crystalloid proteins INTRODUCTION Legumins are specifically expressed in the storage tissues of The castor plant (Ricinus communis L.) is an important oil-seed seeds, i.e., the endosperm or the embryo (7). In the castor bean, crop that produces a very unique oil, enriched in ricinoleic acid the endosperm forms the major storage tissue, surrounding (12-hydroxyoleate). -

MICROBIAL BIOTECHNOLOGY: Fundamentals of Applied Microbiology, Second Edition
This page intentionally left blank P1: JZP 0521842107pre CUFX119/Glazer 0 521 84210 7 June 21, 2007 19:13 MICROBIAL BIOTECHNOLOGY Knowledge in microbiology is growing exponentially through the determination of genomic sequences of hundreds of microorganisms and the invention of new technologies, such as genomics, transcriptomics, and proteomics, to deal with this avalanche of information. These genomic data are now exploited in thousands of applications, rang- ing from medicine, agriculture, organic chemistry, public health, and biomass conversion, to biomining. Microbial Biotechnology focuses on uses of major soci- etalimportance,enablinganin-depthanalysisofthesecriticallyimportantappli- cations. Some, such as wastewater treatment, have changed only modestly over time; others, such as directed molecular evolution, or “green” chemistry, are as current as today’s headlines. Thisfullyrevisedsecondeditionprovidesanexcitinginterdisciplinaryjourney through the rapidly changing landscape of discovery in microbial biotechnology. An ideal text for courses in applied microbiology and biotechnology, this book will also serve as an invaluable overview of recent advances in this field for pro- fessional life scientists and for the diverse community of other professionals with interests in biotechnology. Alexander N. Glazer is a biochemist and molecular biologist and has been on the faculty of the University of California since 1964. He is a Professor of the Graduate School in the Department of Molecular and Cell Biology at the University of Cali- fornia, Berkeley. Dr. Glazer is a member of the National Academy of Sciences and a Fellow of the American Academy of Arts and Sciences, the American Academy of Microbiology, the American Association for the Advancement of Science, and the California Academy of Sciences. He was twice the recipient of a Guggenheim Fellowship. -

Complement Activation in Peritoneal Dialysis–Induced Arteriolopathy
CLINICAL RESEARCH www.jasn.org Complement Activation in Peritoneal Dialysis–Induced Arteriolopathy Maria Bartosova,1 Betti Schaefer,1 Justo Lorenzo Bermejo,2 Silvia Tarantino,3 Felix Lasitschka,4 Stephan Macher-Goeppinger,5 Peter Sinn,4 Bradley A. Warady,6 Ariane Zaloszyc,7 Katja Parapatics,8 Peter Májek,8 Keiryn L. Bennett,8 Jun Oh,9 Christoph Aufricht,3 Franz Schaefer,1 Klaus Kratochwill,3,10 and Claus Peter Schmitt1 1Division of Pediatric Nephrology, Center for Pediatric and Adolescent Medicine, 2Department of Medical Biometry, Institute of Medical Biometry and Informatics, and 4Department of General Pathology, Institute of Pathology, University of Heidelberg, Heidelberg, Germany; 3Department of Pediatrics and Adolescent Medicine and 10Christian Doppler Laboratory for Molecular Stress Research in Peritoneal Dialysis, Medical University of Vienna, Vienna, Austria; 5Department of Pathology, University Medical Center Mainz, Mainz, Germany; 6Division of Pediatric Nephrology, Children’s Mercy Hospital, University of Missouri- Kansas City School of Medicine, Kansas City, Missouri; 7Department of Pediatrics 1, University Hospital of Strasbourg, Strasbourg, France; 8CeMM Research Center for Molecular Medicine of the Austrian Academy of Sciences, Vienna, Austria; and 9Department of Pediatric Nephrology, University Medical Center Hamburg-Eppendorf, Hamburg, Germany ABSTRACT Cardiovascular disease (CVD) is the leading cause of increased mortality in patients with CKD and is further aggravated by peritoneal dialysis (PD). Children are devoid of preexisting CVD and provide unique insight into specificuremia-andPD-inducedpathomechanismsofCVD.We obtained peritoneal specimens from children with stage 5 CKD at time of PD catheter insertion (CKD5 group), children with established PD (PD group), and age-matched nonuremic controls (n=6/group). We microdissected omental arterioles from tissue layers not directly exposed to PD fluid and used adjacent sections of four arterioles per patient for transcriptomic and proteomic analyses. -

Identification, Characterization, and Epitope Mapping of Tree Nut Allergens Jason M
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2006 Identification, Characterization, and Epitope Mapping of Tree Nut Allergens Jason M. Robotham Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES IDENTIFICATION, CHARACTERIZATION, AND EPITOPE MAPPING OF TREE NUT ALLERGENS By JASON M. ROBOTHAM A Dissertation submitted to the Department of Biological Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy Degree Awarded: Spring Semester, 2006 Copyright © 2006 Jason Robotham All Rights Reserved The members of the Committee approve the Dissertation of Jason M. Robotham defended on January 27, 2006. __________________________ Kenneth H. Roux Professor Directing Dissertation __________________________ Shridhar K. Sathe Outside Committee Member __________________________ Peter G. Fajer Committee Member __________________________ Thomas C.S. Keller III Committee Member __________________________ Kenneth A. Taylor Committee Member Approved: __________________________ Timothy S. Moerland, Chair, Department of Biological Science __________________________ Joseph Travis, Dean, College of Arts and Sciences The Office of Graduate Studies has verified and approved the above named committee members ii ACKNOWLEDGEMENTS I would like to thank Kenneth Roux for being a patient advisor, mentor, and most importantly a good friend over the course of my dissertation work. I would like to thank my committee members Shridhar Sathe, Thomas Keller, Peter Fajer, and Kenneth Taylor for their assistance in my development as a scientist. Dr. Suzanne Teuber made much of my research possible through a fruitful collaboration. I am also grateful to Drs. Kirsten Beyer and Hugh Sampson for their generosity in supplying our lab with sera and general advice and Dr. -
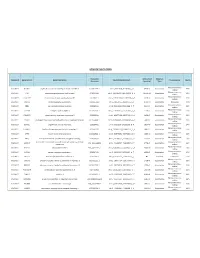
Somatic Mutations
SOMATIC MUTATIONS Transcript Amino Acid Mutation Sample ID Gene Symbol Gene Description Nucleotide (genomic) Consequence Mut % Accession (protein) Type Nonsynonymous PGDX11T ACSBG2 acyl-CoA synthetase bubblegum family member 2 CCDS12159.1 chr19_6141628_6141628_C_A 654A>D Substitution 46% coding Nonsynonymous PGDX11T ATR ataxia telangiectasia and Rad3 related CCDS3124.1 chr3_143721232_143721232_G_A 1451R>W Substitution 32% coding Nonsynonymous PGDX11T C1orf183 chromosome 1 open reading frame 183 CCDS841.1 chr1_112071336_112071336_C_T 224R>Q Substitution 22% coding PGDX11T CMYA5 cardiomyopathy associated 5 NM_153610 chr5_79063455_79063455_C_A 1037C>X Substitution Nonsense 34% Nonsynonymous PGDX11T CNR1 cannabinoid receptor 1 (brain) CCDS5015.1 chr6_88911646_88911646_C_T 23V>M Substitution 35% coding Nonsynonymous PGDX11T COL4A4 collagen; type IV; alpha 4 CCDS42828.1 chr2_227681807_227681807_G_A 227R>C Substitution 20% coding Nonsynonymous PGDX11T CYBASC3 cytochrome b; ascorbate dependent 3 CCDS8004.1 chr11_60877136_60877136_G_A 149R>C Substitution 34% coding Nonsynonymous PGDX11T DYRK3 dual-specificity tyrosine-(Y)-phosphorylation regulated kinase 3 CCDS30999.1 chr1_204888091_204888091_G_A 309V>I Substitution 44% coding Nonsynonymous PGDX11T ELMO1 engulfment and cell motility 1 CCDS5449.1 chr7_37239295_37239295_G_A 160T>M Substitution 24% coding Nonsynonymous PGDX11T FAM83H family with sequence similarity 83; member H CCDS6410.2 chr8_144884473_144884473_C_A 90G>C Substitution 53% coding Nonsynonymous PGDX11T KPTN kaptin (actin binding protein)