Open Science – Towards Reproducible Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Book Self-Publishing Best Practices
Montana Tech Library Digital Commons @ Montana Tech Graduate Theses & Non-Theses Student Scholarship Fall 2019 Book Self-Publishing Best Practices Erica Jansma Follow this and additional works at: https://digitalcommons.mtech.edu/grad_rsch Part of the Communication Commons Book Self-Publishing Best Practices by Erica Jansma A project submitted in partial fulfillment of the requirements for the degree of M.S. Technical Communication Montana Tech 2019 ii Abstract I have taken a manuscript through the book publishing process to produce a camera-ready print book and e-book. This includes copyediting, designing layout templates, laying out the document in InDesign, and producing an index. My research is focused on the best practices and standards for publishing. Lessons learned from my research and experience include layout best practices, particularly linespacing and alignment guidelines, as well as the limitations and capabilities of InDesign, particularly its endnote functionality. Based on the results of this project, I can recommend self-publishers to understand the software and distribution platforms prior to publishing a book to ensure the required specifications are met to avoid complications later in the process. This document provides details on many of the software, distribution, and design options available for self-publishers to consider. Keywords: self-publishing, publishing, books, ebooks, book design, layout iii Dedication I dedicate this project to both of my grandmothers. I grew up watching you work hard, sacrifice, trust, and love with everything you have; it was beautiful; you are beautiful; and I hope I can model your example with a fraction of your grace and fruitfulness. Thank you for loving me so well. -

The Realized Benefits from Bioprospecting in the Wake of the Convention on Biological Diversity
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Washington University St. Louis: Open Scholarship Washington University Journal of Law & Policy Volume 47 Intellectual Property: From Biodiversity to Technical Standards 2015 The Realized Benefits from Bioprospecting in the Wake of the Convention on Biological Diversity James S. Miller Missouri Botanical Garden Follow this and additional works at: https://openscholarship.wustl.edu/law_journal_law_policy Part of the Ecology and Evolutionary Biology Commons, Environmental Law Commons, and the Plant Sciences Commons Recommended Citation James S. Miller, The Realized Benefits from Bioprospecting in the Wake of the Convention on Biological Diversity, 47 WASH. U. J. L. & POL’Y 051 (2015), https://openscholarship.wustl.edu/law_journal_law_policy/vol47/iss1/10 This Article is brought to you for free and open access by the Law School at Washington University Open Scholarship. It has been accepted for inclusion in Washington University Journal of Law & Policy by an authorized administrator of Washington University Open Scholarship. For more information, please contact [email protected]. The Realized Benefits from Bioprospecting in the Wake of the Convention on Biological Diversity James S. Miller MISSOURI BOTANICAL GARDEN In the mid-1980s, the convergence of several technological advances led to a serious resurgence of interest in surveying plant species for drug development. The emergence of methods to miniaturize in-vitro bioassays (a test used to quantify the biological effect of a chemical compound or extract against a specific disease target) run the bioassays with robotic equipment, and isolate and identify active compounds with a speed and precision never before possible. -

When Is Open Access Not Open Access?
Editorial When Is Open Access Not Open Access? Catriona J. MacCallum ince 2003, when PLoS Biology Box 1. The Bethesda Statement on Open-Access Publishing was launched, there has been This is taken from http:⁄⁄www.earlham.edu/~peters/fos/bethesda.htm. a spectacular growth in “open- S 1 access” journals. The Directory of An Open Access Publication is one that meets the following two conditions: Open Access Journals (http:⁄⁄www. 1. The author(s) and copyright holder(s) grant(s) to all users a free, irrevocable, doaj.org/), hosted by Lund University worldwide, perpetual right of access to, and a license to copy, use, distribute, transmit Libraries, lists 2,816 open-access and display the work publicly and to make and distribute derivative works, in any digital journals as this article goes to press medium for any responsible purpose, subject to proper attribution of authorship2, as (and probably more by the time you well as the right to make small numbers of printed copies for their personal use. read this). Authors also have various 2. A complete version of the work and all supplemental materials, including a copy of “open-access” options within existing the permission as stated above, in a suitable standard electronic format is deposited subscription journals offered by immediately upon initial publication in at least one online repository that is supported traditional publishers (e.g., Blackwell, by an academic institution, scholarly society, government agency, or other well- Springer, Oxford University Press, and established organization that seeks to enable open access, unrestricted distribution, many others). In return for a fee to interoperability, and long-term archiving (for the biomedical sciences, PubMed Central the publisher, an author’s individual is such a repository). -

Sci-Hub Provides Access to Nearly All Scholarly Literature
Sci-Hub provides access to nearly all scholarly literature A DOI-citable version of this manuscript is available at https://doi.org/10.7287/peerj.preprints.3100. This manuscript was automatically generated from greenelab/scihub-manuscript@51678a7 on October 12, 2017. Submit feedback on the manuscript at git.io/v7feh or on the analyses at git.io/v7fvJ. Authors • Daniel S. Himmelstein 0000-0002-3012-7446 · dhimmel · dhimmel Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania · Funded by GBMF4552 • Ariel Rodriguez Romero 0000-0003-2290-4927 · arielsvn · arielswn Bidwise, Inc • Stephen Reid McLaughlin 0000-0002-9888-3168 · stevemclaugh · SteveMcLaugh School of Information, University of Texas at Austin • Bastian Greshake Tzovaras 0000-0002-9925-9623 · gedankenstuecke · gedankenstuecke Department of Applied Bioinformatics, Institute of Cell Biology and Neuroscience, Goethe University Frankfurt • Casey S. Greene 0000-0001-8713-9213 · cgreene · GreeneScientist Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania · Funded by GBMF4552 PeerJ Preprints | https://doi.org/10.7287/peerj.preprints.3100v2 | CC BY 4.0 Open Access | rec: 12 Oct 2017, publ: 12 Oct 2017 Abstract The website Sci-Hub provides access to scholarly literature via full text PDF downloads. The site enables users to access articles that would otherwise be paywalled. Since its creation in 2011, Sci- Hub has grown rapidly in popularity. However, until now, the extent of Sci-Hub’s coverage was unclear. As of March 2017, we find that Sci-Hub’s database contains 68.9% of all 81.6 million scholarly articles, which rises to 85.2% for those published in toll access journals. -

From Coalition to Commons: Plan S and the Future of Scholarly Communication
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Copyright, Fair Use, Scholarly Communication, etc. Libraries at University of Nebraska-Lincoln 2019 From Coalition to Commons: Plan S and the Future of Scholarly Communication Rob Johnson Research Consulting Follow this and additional works at: https://digitalcommons.unl.edu/scholcom Part of the Intellectual Property Law Commons, Scholarly Communication Commons, and the Scholarly Publishing Commons Johnson, Rob, "From Coalition to Commons: Plan S and the Future of Scholarly Communication" (2019). Copyright, Fair Use, Scholarly Communication, etc.. 157. https://digitalcommons.unl.edu/scholcom/157 This Article is brought to you for free and open access by the Libraries at University of Nebraska-Lincoln at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Copyright, Fair Use, Scholarly Communication, etc. by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Insights – 32, 2019 Plan S and the future of scholarly communication | Rob Johnson From coalition to commons: Plan S and the future of scholarly communication The announcement of Plan S in September 2018 triggered a wide-ranging debate over how best to accelerate the shift to open access. The Plan’s ten principles represent a call for the creation of an intellectual commons, to be brought into being through collective action by funders and managed through regulated market mechanisms. As it gathers both momentum and critics, the coalition must grapple with questions of equity, efficiency and sustainability. The work of Elinor Ostrom has shown that successful management of the commons frequently relies on polycentricity and adaptive governance. The Plan S principles must therefore function as an overarching framework within which local actors retain some autonomy, and should remain open to amendment as the scholarly communication landscape evolves. -

Market Power in the Academic Publishing Industry
Market Power in the Academic Publishing Industry What is an Academic Journal? • A serial publication containing recent academic papers in a certain field. • The main method for communicating the results of recent research in the academic community. Why is Market Power important to think about? • Commercial academic journal publishers use market power to artificially inflate subscription prices. • This practice drains the resources of libraries, to the detriment of the public. How Does Academic Publishing Work? • Author writes paper and submits to journal. • Paper is evaluated by peer reviewers (other researchers in the field). • If accepted, the paper is published. • Libraries pay for subscriptions to the journal. The market does not serve the interests of the public • Universities are forced to “double-pay”. 1. The university funds research 2. The results of the research are given away for free to journal publishers 3. The university library must pay to get the research back in the form of journals Subscription Prices are Outrageous • The highest-priced journals are those in the fields of science, technology, and medicine (or STM fields). • Since 1985, the average price of a journal has risen more than 215 percent—four times the average rate of inflation. • This rise in prices, combined with the CA budget crisis, has caused UC Berkeley’s library to cancel many subscriptions, threatening the library’s reputation. A Comparison Why are prices so high? Commercial publishers use market power to charge inflated prices. Why do commercial publishers have market power? • They control the most prestigious, high- quality journals in many fields. • Demand is highly inelastic for high-quality journals. -

A Critique of John Stuart Mill Chris Daly
Southern Illinois University Carbondale OpenSIUC Honors Theses University Honors Program 5-2002 The Boundaries of Liberalism in a Global Era: A Critique of John Stuart Mill Chris Daly Follow this and additional works at: http://opensiuc.lib.siu.edu/uhp_theses Recommended Citation Daly, Chris, "The Boundaries of Liberalism in a Global Era: A Critique of John Stuart Mill" (2002). Honors Theses. Paper 131. This Dissertation/Thesis is brought to you for free and open access by the University Honors Program at OpenSIUC. It has been accepted for inclusion in Honors Theses by an authorized administrator of OpenSIUC. For more information, please contact [email protected]. r The Boundaries of Liberalism in a Global Era: A Critique of John Stuart Mill Chris Daly May 8, 2002 r ABSTRACT The following study exanunes three works of John Stuart Mill, On Liberty, Utilitarianism, and Three Essays on Religion, and their subsequent effects on liberalism. Comparing the notion on individual freedom espoused in On Liberty to the notion of the social welfare in Utilitarianism, this analysis posits that it is impossible for a political philosophy to have two ultimate ends. Thus, Mill's liberalism is inherently flawed. As this philosophy was the foundation of Mill's progressive vision for humanity that he discusses in his Three Essays on Religion, this vision becomes paradoxical as well. Contending that the neo-liberalist global economic order is the contemporary parallel for Mill's religion of humanity, this work further demonstrates how these philosophical flaws have spread to infect the core of globalization in the 21 st century as well as their implications for future international relations. -

Open Access Publishing
Open Access The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Suber, Peter. 2012. Open access. Cambridge, Mass: MIT Press. [Updates and Supplements: http://cyber.law.harvard.edu/hoap/ Open_Access_(the_book)] Published Version http://mitpress.mit.edu/books/open-access Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:10752204 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA OPEN ACCESS The MIT Press Essential Knowledge Series Information and the Modern Corporation, James Cortada Intellectual Property Strategy, John Palfrey Open Access, Peter Suber OPEN ACCESS PETER SUBER TheMIT Press | Cambridge, Massachusetts | London, England © 2012 Massachusetts Institute of Technology This work is licensed under the Creative Commons licenses noted below. To view a copy of these licenses, visit creativecommons.org. Other than as provided by these licenses, no part of this book may be reproduced, transmitted, or displayed by any electronic or mechanical means without permission from the publisher or as permitted by law. This book incorporates certain materials previously published under a CC-BY license and copyright in those underlying materials is owned by SPARC. Those materials remain under the CC-BY license. Effective June 15, 2013, this book will be subject to a CC-BY-NC license. MIT Press books may be purchased at special quantity discounts for business or sales promotional use. -

Will Sci-Hub Kill the Open Access Citation Advantage and (At Least for Now) Save Toll Access Journals?
Will Sci-Hub Kill the Open Access Citation Advantage and (at least for now) Save Toll Access Journals? David W. Lewis October 2016 © 2016 David W. Lewis. This work is licensed under a Creative Commons Attribution 4.0 International license. Introduction It is a generally accepted fact that open access journal articles enjoy a citation advantage.1 This citation advantage results from the fact that open access journal articles are available to everyone in the word with an Internet collection. Thus, anyone with an interest in the work can find it and use it easily with no out-of-pocket cost. This use leads to citations. Articles in toll access journals on the other hand, are locked behind paywalls and are only available to those associated with institutions who can afford the subscription costs, or who are willing and able to purchase individual articles for $30 or more. There has always been some slippage in the toll access journal system because of informal sharing of articles. Authors will usually send copies of their work to those who ask and sometime post them on their websites even when this is not allowable under publisher’s agreements. Stevan Harnad and his colleagues proposed making this type of author sharing a standard semi-automated feature for closed articles in institutional repositories.2 The hashtag #ICanHazPDF can be used to broadcast a request for an article that an individual does not have access to.3 Increasingly, toll access articles are required by funder mandates to be made publically available, though usually after an embargo period. -
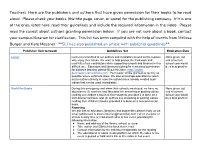
Teachers: Here Are the Publishers and Authors That Have Given Permission for Their Books to Be Read Aloud. Please Check Your Bo
Teachers: Here are the publishers and authors that have given permission for their books to be read aloud. Please check your books (the title page, cover, or spine) for the publishing company. If it is one of the ones listed here, read their guidelines and include the required information in the video. Please read the caveat about authors granting permission below. If you are not sure about a book, contact your campus librarian for clarification. This list has been compiled with the help of tweets from Melissa Burger and Kate Messner. **SLJ has also published an article with publisher guidelines** Publisher (link to tweet) Guidelines Set Expiration Date Lerner Lerner is committed to our authors and illustrators as well as the readers None given, but who enjoy their books. We want to help protect the hard work and end of current creativity of our contributors while supporting schools and libraries in this school year would difficult time. Educators and librarians looking for read-aloud permission be a best practice for distance learning, please fill out this form: https://rights- permissions.lernerbooks.com . Permission will be granted as quickly as possible where contracts allow. We also encourage educators to reach out to authors directly in case the authors have already created such videos that can be used immediately. MacMillan Books During this emergency and when their schools are closed, we have no None given, but objection to (1) teachers and librarians live streaming or posting videos end of current reading our children’s books to their students, provided it is done on a school year would noncommercial basis, and (2) authors live streaming or posting videos be a best practice reading their children’s books, provided it is done on a noncommercial basis. -

ORCID: Connecting the Research Community April 30, 2020 Introductions
ORCID: Connecting the Research Community April 30, 2020 Introductions Shawna Sadler Sheila Rabun Lori Ann M. Schultz https://orcid.org/0000-0002-6103-5034 https://orcid.org/0000-0002-1196-6279 https://orcid.org/0000-0002-1597-8189 Engagement Manager ORCID US Community Sr. Director of Research, Americas, Specialist, Innovation & Impact, ORCID LYRASIS University of Arizona Agenda 1. What is ORCID? 2. ORCID US Community Consortium 3. Research Impact & Global Connections 4. ORCID for Research Administrators 5. Questions What is ORCID? ORCID’S VISION IS A WORLD WHERE ALL WHO PARTICIPATE IN RESEARCH, SCHOLARSHIP, AND INNOVATION ARE UNIQUELY IDENTIFIED AND CONNECTED TO THEIR CONTRIBUTIONS AND AFFILIATIONS ACROSS TIME, DISCIPLINES, AND BORDERS. History ● ORCID was first announced in 2009 ● A collaborative effort by the research community "to resolve the author name ambiguity problem in scholarly communication" ● Independent nonprofit organization ● Offering services in 2012 ORCID An non-profit organization that provides: 1. ORCID iDs to people 2. ORCID records for people 3. Infrastructure to share research data between organizations ORCID for Researchers Free Unique Identifier Sofia Maria Hernandez Garcia ORCID iD https://orcid.org/0000-0001-5727-2427 ORCID Record: ORCID Record: ORCID Record: What is ORCID? https://vimeo.com/97150912 ORCID for Research Organizations Researcher ORCID Your Organization 1) Researcher creates ORCID iD All records are saved in the API Transfer Member data 2) Populates record ORCID Registry to your CRIS System Current -

Business of Publishing
Final Syllabus: The Business of Publishing This course is structured to provide students working knowledge of the publishing industry - Newspapers, Magazines and Books. We will explore traditional business models and how disruptive forces including digitalization, consumer generated content, low barriers to entry and changing media consumption patterns are reshaping the industry. At the end of the course one should be able to 1. Understand the operations of media companies 2. Speak to the opportunities and challenges facing the industry 3. Engage in discussions on the economics, terms and metrics 4. Explain emerging business models Grading • Class participation 20% • Individual Paper (two) 40% • Group presentation 40% • Total 100% Readings • Cases/readings (Required) – Coursepack set up on Harvard Business Case website (https://cb.hbsp.harvard.edu/cbmp/access/34701829) o The Newspaper Industry in Crisis [David J. Collis, Peter W. Olson, Mary Furey] o The Economist [Felix Oberholzer-Gee, Bharat N. Anand, Lizzie Gomez] o Book Publishing in 2010 [Stephen P. Bradley, Nancy Bartlett] Suggested additional o Competing for the Free Newspaper Industry in Spain: Metro vs Que [Josep Valor, Luis Vives] o Zinio: "Byting" into a Paper World [Julian Villanueva, Jose Luis Nueno, Jordan Mitchell] o The Random House Response to the Kindle [Bharat N. Anand, Peter W. Olson] o eReading: Amazon's Kindle [Bharat N. Anand, Peter W. Olson, Mary Tripsas] • Books (Suggested) o Book Business: Publishing Past, Present, and Future [Jason Epstein] o -30-: The Collapse of the Great American Newspaper [Charles M. Madigan] o Magazines (Media Industries) [David E. Sumner; Shirrel Rhoades] Session 1 (Jan 29th): Overview of the publishing industry • History • Where do newspapers, magazines and books fall in the spectrum • Recent trends: newspapers, magazines and books o Information overload .