A Fast Branch and Bound Algorithm for the Perfect Tumor Phylogeny Reconstruction Problem
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Table S1 the Four Gene Sets Derived from Gene Expression Profiles of Escs and Differentiated Cells
Table S1 The four gene sets derived from gene expression profiles of ESCs and differentiated cells Uniform High Uniform Low ES Up ES Down EntrezID GeneSymbol EntrezID GeneSymbol EntrezID GeneSymbol EntrezID GeneSymbol 269261 Rpl12 11354 Abpa 68239 Krt42 15132 Hbb-bh1 67891 Rpl4 11537 Cfd 26380 Esrrb 15126 Hba-x 55949 Eef1b2 11698 Ambn 73703 Dppa2 15111 Hand2 18148 Npm1 11730 Ang3 67374 Jam2 65255 Asb4 67427 Rps20 11731 Ang2 22702 Zfp42 17292 Mesp1 15481 Hspa8 11807 Apoa2 58865 Tdh 19737 Rgs5 100041686 LOC100041686 11814 Apoc3 26388 Ifi202b 225518 Prdm6 11983 Atpif1 11945 Atp4b 11614 Nr0b1 20378 Frzb 19241 Tmsb4x 12007 Azgp1 76815 Calcoco2 12767 Cxcr4 20116 Rps8 12044 Bcl2a1a 219132 D14Ertd668e 103889 Hoxb2 20103 Rps5 12047 Bcl2a1d 381411 Gm1967 17701 Msx1 14694 Gnb2l1 12049 Bcl2l10 20899 Stra8 23796 Aplnr 19941 Rpl26 12096 Bglap1 78625 1700061G19Rik 12627 Cfc1 12070 Ngfrap1 12097 Bglap2 21816 Tgm1 12622 Cer1 19989 Rpl7 12267 C3ar1 67405 Nts 21385 Tbx2 19896 Rpl10a 12279 C9 435337 EG435337 56720 Tdo2 20044 Rps14 12391 Cav3 545913 Zscan4d 16869 Lhx1 19175 Psmb6 12409 Cbr2 244448 Triml1 22253 Unc5c 22627 Ywhae 12477 Ctla4 69134 2200001I15Rik 14174 Fgf3 19951 Rpl32 12523 Cd84 66065 Hsd17b14 16542 Kdr 66152 1110020P15Rik 12524 Cd86 81879 Tcfcp2l1 15122 Hba-a1 66489 Rpl35 12640 Cga 17907 Mylpf 15414 Hoxb6 15519 Hsp90aa1 12642 Ch25h 26424 Nr5a2 210530 Leprel1 66483 Rpl36al 12655 Chi3l3 83560 Tex14 12338 Capn6 27370 Rps26 12796 Camp 17450 Morc1 20671 Sox17 66576 Uqcrh 12869 Cox8b 79455 Pdcl2 20613 Snai1 22154 Tubb5 12959 Cryba4 231821 Centa1 17897 -

HMGB1 in Health and Disease R
Donald and Barbara Zucker School of Medicine Journal Articles Academic Works 2014 HMGB1 in health and disease R. Kang R. C. Chen Q. H. Zhang W. Hou S. Wu See next page for additional authors Follow this and additional works at: https://academicworks.medicine.hofstra.edu/articles Part of the Emergency Medicine Commons Recommended Citation Kang R, Chen R, Zhang Q, Hou W, Wu S, Fan X, Yan Z, Sun X, Wang H, Tang D, . HMGB1 in health and disease. 2014 Jan 01; 40():Article 533 [ p.]. Available from: https://academicworks.medicine.hofstra.edu/articles/533. Free full text article. This Article is brought to you for free and open access by Donald and Barbara Zucker School of Medicine Academic Works. It has been accepted for inclusion in Journal Articles by an authorized administrator of Donald and Barbara Zucker School of Medicine Academic Works. Authors R. Kang, R. C. Chen, Q. H. Zhang, W. Hou, S. Wu, X. G. Fan, Z. W. Yan, X. F. Sun, H. C. Wang, D. L. Tang, and +8 additional authors This article is available at Donald and Barbara Zucker School of Medicine Academic Works: https://academicworks.medicine.hofstra.edu/articles/533 NIH Public Access Author Manuscript Mol Aspects Med. Author manuscript; available in PMC 2015 December 01. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: Mol Aspects Med. 2014 December ; 0: 1–116. doi:10.1016/j.mam.2014.05.001. HMGB1 in Health and Disease Rui Kang1,*, Ruochan Chen1, Qiuhong Zhang1, Wen Hou1, Sha Wu1, Lizhi Cao2, Jin Huang3, Yan Yu2, Xue-gong Fan4, Zhengwen Yan1,5, Xiaofang Sun6, Haichao Wang7, Qingde Wang1, Allan Tsung1, Timothy R. -

DNA Supercoiling with a Twist Edwin Kamau Louisiana State University and Agricultural and Mechanical College, [email protected]
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2005 DNA supercoiling with a twist Edwin Kamau Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Recommended Citation Kamau, Edwin, "DNA supercoiling with a twist" (2005). LSU Doctoral Dissertations. 999. https://digitalcommons.lsu.edu/gradschool_dissertations/999 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. DNA SUPERCOILING WITH A TWIST A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Biological Sciences By Edwin Kamau B.S. Horticulture, Egerton University, Kenya, 1996, May, 2005 DEDICATIONS I would like to dedicate this dissertation to my son, Ashford Kimani Kamau. Your age marks the life of my graduate school career. I have been a weekend dad, broke and with enormous financial responsibilities; it kills me to see how sometimes you cry your heart out on Sunday evening when our weekend time together is over. I miss you too every moment, you have encouraged me to be a better person, a better dad so that I can make you proud. At your tender age, I have learned a lot from you. We will soon spend all the time in the world we need together; travel, sports, music, pre-historic discoveries and adventures; the road is wide open. -

DNMT Inhibitors Increase Methylation at Subset of Cpgs in Colon
bioRxiv preprint doi: https://doi.org/10.1101/395467; this version posted August 25, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Title: DNMT inhibitors increase methylation at subset of CpGs in colon, bladder, lymphoma, 2 breast, and ovarian, cancer genome 3 Running title: Decitabine/azacytidine increases DNA methylation 4 Anil K Giri1, Tero Aittokallio1,2 5 1Institute for Molecular Medicine Finland, FIMM, University of Helsinki, Helsinki, Finland. 6 2Department of Mathematics and Statistics, University of Turku, Turku, Finland. 7 Correspondence to 8 Dr. Anil K Giri 9 Institute for Molecular Medicine Finland FIMM, University of Helsinki, Helsinki, Finland. 10 Email: [email protected] 11 Financial disclosure: This work was funded by the Academy of Finland (grants 269862, 292611, 12 310507 and 313267), Cancer Society of Finland, and the Sigrid Juselius Foundation. 13 Ethical disclosure: This study is an independent analysis of existing data available in the public 14 domain and does not involve any animal or human samples that have been collected by the authors 15 themselves. 16 Author contribution: AKG conceptualized, analyzed the data and wrote the manuscript. TA 17 critically revised and edited the manuscript. The authors report no conflict of interest. 18 19 Word count: 20 Figure number: 5 21 Table number: 1 22 23 Abstract 24 Background: DNA methyltransferase inhibitors (DNMTi) decitabine and azacytidine are approved 25 therapies for acute myeloid leukemia and myelodysplastic syndrome. -

Non-Traditional Platinum Compounds for Improved Accumulation, Oral Bioavailability, and Tumor Targeting
Non-traditional platinum compounds for improved accumulation, oral bioavailability, and tumor targeting The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Lovejoy, Katherine S., and Stephen J. Lippard. “Non-traditional platinum compounds for improved accumulation, oral bioavailability, and tumor targeting.” Dalton Transactions, no. 48 (2009): 10651. As Published http://dx.doi.org/10.1039/b913896j Publisher Royal Society of Chemistry, The Version Author's final manuscript Citable link http://hdl.handle.net/1721.1/82144 Terms of Use Creative Commons Attribution-Noncommercial-Share Alike 3.0 Detailed Terms http://creativecommons.org/licenses/by-nc-sa/3.0/ NIH Public Access Author Manuscript Dalton Trans. Author manuscript; available in PMC 2010 December 28. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: Dalton Trans. 2009 December 28; (48): 10651–10659. doi:10.1039/b913896j. Non-Traditional Platinum Compounds for Improved Accumulation, Oral Bioavailability, and Tumor Targeting Katherine S. Lovejoy and Stephen J. Lippard Department of Chemistry, Massachusetts Institute of Technology Cambridge, Massachusetts 02139, USA Peter Sadler Summary The five platinum anticancer compounds currently in clinical use conform to structure-activity relationships formulated1 shortly after the discovery2 that cis-diamminedichloroplatinum(II), cisplatin, has antitumor activity in mice. These compounds are neutral, platinum(II) species with two am(m)ine ligands or one bidentate chelating diamine and two additional ligands that can be replaced by water through aquation reactions. The resulting cations ultimately form bifunctional adducts on DNA. Information about the chemistry of these platinum compounds and correlations of their structures with anticancer activity have provided guidance for the design of novel anticancer drug candidates based on proposed mechanisms of action. -

HMGB4 Is Expressed by Neuronal Cells and Affects the Expression Of
www.nature.com/scientificreports OPEN HMGB4 is expressed by neuronal cells and affects the expression of genes involved in neural Received: 14 August 2015 Accepted: 18 August 2016 differentiation Published: 09 September 2016 Ari Rouhiainen1,2, Xiang Zhao1,3, Päivi Vanttola1, Kui Qian4, Evgeny Kulesskiy1,5, Juha Kuja- Panula1, Kathleen Gransalke1, Mikaela Grönholm2, Emmanual Unni6, Marvin Meistrich7, Li Tian1,8, Petri Auvinen4 & Heikki Rauvala1 HMGB4 is a new member in the family of HMGB proteins that has been characterized in sperm cells, but little is known about its functions in somatic cells. Here we show that HMGB4 and the highly similar rat Transition Protein 4 (HMGB4L1) are expressed in neuronal cells. Both proteins had slow mobility in nucleus of living NIH-3T3 cells. They interacted with histones and their differential expression in transformed cells of the nervous system altered the post-translational modification statuses of histones in vitro. Overexpression of HMGB4 in HEK 293T cells made cells more susceptible to cell death induced by topoisomerase inhibitors in an oncology drug screening array and altered variant composition of histone H3. HMGB4 regulated over 800 genes in HEK 293T cells with a p-value ≤0.013 (n = 3) in a microarray analysis and displayed strongest association with adhesion and histone H2A –processes. In neuronal and transformed cells HMGB4 regulated the expression of an oligodendrocyte marker gene PPP1R14a and other neuronal differentiation marker genes. In conclusion, our data suggests that HMGB4 is a factor that regulates chromatin and expression of neuronal differentiation markers. HMGB-proteins are less than 30 kDa in size and bind to DNA in a manner that is dependent on the structure of the DNA and mainly independent of the sequence of the DNA1. -

Supplementary Information
Supplementary Information Ten-eleven translocation 1 Mediated-DNA Hydroxymethylation is Required for Myelination and Remyelination in the Mouse Brain Ming Zhang1, Jian Wang1, Kaixiang Zhang1, Guozhen Lu1, Yuming Liu1, Keke Ren1, Wenting Wang1, Dazhuan Xin2, Lingli Xu3, Honghui Mao1, Junlin Xing1, Xingchun Gao4, Weilin Jin5, Kalen 2 6 1, 2, 1, Berry , Katsuhiko Mikoshiba , Shengxi Wu *, Q. Richard Lu * and Xianghui Zhao * 1 Supplementary figures: Supplementary Fig. 1 Distribution pattern of genomic 5hmCs is associated with the transition from NPCs to OPCs (a-c) Examples of OL lineage-specific genes expressed in different OL stages. Fragments per kilobase of transcript per million mapped reads (FPKMs) of representative genes highly expressed in OPCs (a), iOLs (b), and OLs (c). Diagrams were made from http://jiaqianwulab. org/braincell/RNASeq.html. (d) The level of 5hmC in certain gene loci is identified by qPCR assay. Validation of loci specific 5hmC modification in OPC and NPC cultures by qPCR analysis of OPC associated genes, immature OLs (iOL) associated genes, mOL associated genes and negative regulators of OPC differentiation. Data are Means ± SEM (n = 3 independent cultures per group). *, p<0.05, **, p<0.01, ***, p<0.001, compared to NPC. Two-tailed unpaired t test. Cspg4: t = -5.867, df = 4, p = 0.004; Slc22a3: t = -10.100, df = 4, p = 0.001; Wnt10a: t = -20.501, df = 4, p = 0.000033; Kndc1: t = -13.045, df = 4, p = 0.000199; Olfr279: t = -4.221, df = 4, p = 0.013; Zdhhc12: t = -5.173, df = 4, p = 0.007; Mag: t = -32.333, df = 4, p = 0.000005; Elovl7: t = -4.274, df = 4, p = 0.013; Arl2: t = -4.319, df = 4, p = 0.012; Cdc42ep2: t = -3.081, df = 4, p = 0.037; Ngf: t = 27.294, df = 4, p = 0.037; Zfp28: t = 5.877, df = 4, p = 0.004. -

Supporting Information
Supporting Information Machida et al. 10.1073/pnas.0807390106 SI Methods Plasmids, Lentivirus, and Retrovirus Vectors. The NS5A expression plasmid was constructed by inserting HCV NS5A cDNA behind the Cells. Huh7 cells were plated at 3 ϫ 105 or 2 ϫ 106 cells per 6-well CMV promoter in pCDNA3.1 (Invitrogen). Lentivirus vectors were or 10-cm dish and transfected with expression plasmids and a prepared by standard procedures in HEK293T cells. Three plas- reporter construct. mids, packaging vector pPAX2 (Addgene), ecotropic envelope gene expression vector pMDV (Addgene), and the cassettes of Histology and Immunohistochemistry. Mouse livers from different shRNA were transfected in HEK293T cells by lipid-based trans- genetic and treatment groups were fixed in neutral-buffered 4% fection reagent FuGene6 (Roche). The retroviral expression vec- paraformaldehyde at 4°C and processed for paraffin embedding. tors for shRNA of TLR4 and Nanog were obtained from Open Five-micrometer sections were stained with hematoxylin and eosin. Biosystems. Retrovirus expressing TLR4 was produced in Phoenix Immunohistochemistry staining of cryosections or paraffin sections cells (10). After 72 hours of transfection, the virus supernatants was performed by using antibodies against TLR4 (HTA125; eBio- were harvested and mixed with polybrene (4 g/mL) and used to science), phospho-JNK (Santa Cruz Biotechnology), phospho-IB infect Huh7 cells. More detailed states of the patients are depicted (Cell Signaling Technology), TNF-␣ (RM9011; CALTAG), or in SI Methods. Nanog (Abcam) based on the standard protocol with mounting Statistical Analysis. Statistical analysis of the data in Tables S1–S3 media, including DAPI for nuclei counterstaining (Vector Labo- was performed by the 2 test or Student’s t test. -

Repair Shielding of Platinum-DNA Lesions in Testicular Germ Cell Tumors by High-Mobility Group Box Protein 4 Imparts Cisplatin Hypersensitivity
Repair shielding of platinum-DNA lesions in testicular germ cell tumors by high-mobility group box protein 4 imparts cisplatin hypersensitivity Samuel G. Awuaha, Imogen A. Riddella, and Stephen J. Lipparda,b,1 aDepartment of Chemistry, Massachusetts Institute of Technology, Cambridge, MA 02139; and bKoch Institute for Integrative Cancer Research, Massachusetts Institute of Technology, Cambridge, MA 02139 Contributed by Stephen J. Lippard, November 28, 2016 (sent for review June 8, 2016; reviewed by Cynthia J. Burrows, Paul W. Doetsch, and Aziz Sancar) Cisplatin is the most commonly used anticancer drug for the intrastrand cross-links (23). These cysteines can form a disulfide treatment of testicular germ cell tumors (TGCTs). The hypersensi- bond under mild oxidizing conditions, which significantly reduces tivity of TGCTs to cisplatin is a subject of widespread interest. their ability to bind to cisplatin-modified DNA (24). Because the Here, we show that high-mobility group box protein 4 (HMGB4), a intracellular redox potential, buffered by glutathione, will generate protein preferentially expressed in testes, uniquely blocks excision a mixture of oxidized and reduced forms of HMGB1, HMGB1 repair of cisplatin-DNA adducts, 1,2-intrastrand cross-links, to poten- sensitization of cancer cells to cisplatin by repair shielding can be tiate the sensitivity of TGCTs to cisplatin therapy. We used CRISPR/ compromised and will depend on cell type (25). Cas9-mediated gene editing to knockout the HMGB4 gene in a HMGB4 has two tandem HMG domains, A and B, homologous testicular human embryonic carcinoma and examined cellular re- to those in HMGB1, and a shortened C-terminal tail that lacks the sponses. -

Adiponectin Hepatitis B Surface Antigen Growth Regulated
MOUSE EM001 m.ADP/Acrp30 EM006 m.CXCL4/PF4 Adiponectin Platelet Factor 4 Nazwy równoważne: Adiponectin / AdipoQ / ADP / Acrp30 / Nazwy równoważne: CXCL4 / PF4 / chemokine(C-X-C motif) GBP28 / ACDC / ADPN ligand 4 / C-X-C motif chemokine 4 / Oncostatin-A / PF-4 / platelet factor 4 czułość: — liniowość: — czułość: — liniowość: — EM002 m.HBsAg Hepatitis B Surface Antigen EM007 m.EGF Nazwy równoważne: Epidermal growth factor Nazwy równoważne: EGF(Epidermal growth factor) / URG / czułość: — liniowość: — HOMG4 / Beta-Urogastrone czułość: — liniowość: — EM003 m.CXCL1/GROα Growth Regulated Oncogene EM008 m.FK/CX3CL1 Alpha Fractalkine Nazwy równoważne: CXCL1 / GROα(Growth Regulated Nazwy równoważne: Fractalkine / CX3CL1 / FKN / ABCD- Oncogene Alpha) / NAP3 / GRO1 / GRO-A / MGSA / 3 / C3Xkine / CXC3 / CXC3C / NTN / NTT / SCYD1 / MGSA-A / SCYB1 / FSP / CINC-1 FKN / Fractalkine / Neurotactin / ABCD-3 / C3Xkine / chemokine(C-X3-C motif) ligand 1 / CX3C membrane-anchored czułość: — liniowość: — chemokine / CXC3 / CXC3C / FKN / fractalkine / Neurotactin / neurotactin / neurotactin) / NTNsmall inducible cytokine EM004 m.CXCL10/IP-10 subfamily D(Cys-X3-Cys), member 1(fractalkine / NTTSmall- inducible cytokine D1 / SCYD1C-X3-C motif chemokine 1 / Interferon Gamma Induced Protein small inducible cytokine subfamily D(Cys-X3-Cys), member-1 10kDa czułość: — liniowość: — Nazwy równoważne: CXCL10 / IP-10(Interferon Gamma Induced Protein 10kDa) / C7 / IFI10 / INP10 / SCYB10 / crg-2 / gIP-10 / mob-1 EM010 m.MPO czułość: — liniowość: — Myeloperoxidase Nazwy równoważne: -
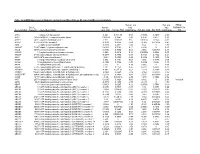
Mrna Expression in Human Leiomyoma and Eker Rats As Measured by Microarray Analysis
Table 3S: mRNA Expression in Human Leiomyoma and Eker Rats as Measured by Microarray Analysis Human_avg Rat_avg_ PENG_ Entrez. Human_ log2_ log2_ RAPAMYCIN Gene.Symbol Gene.ID Gene Description avg_tstat Human_FDR foldChange Rat_avg_tstat Rat_FDR foldChange _DN A1BG 1 alpha-1-B glycoprotein 4.982 9.52E-05 0.68 -0.8346 0.4639 -0.38 A1CF 29974 APOBEC1 complementation factor -0.08024 0.9541 -0.02 0.9141 0.421 0.10 A2BP1 54715 ataxin 2-binding protein 1 2.811 0.01093 0.65 0.07114 0.954 -0.01 A2LD1 87769 AIG2-like domain 1 -0.3033 0.8056 -0.09 -3.365 0.005704 -0.42 A2M 2 alpha-2-macroglobulin -0.8113 0.4691 -0.03 6.02 0 1.75 A4GALT 53947 alpha 1,4-galactosyltransferase 0.4383 0.7128 0.11 6.304 0 2.30 AACS 65985 acetoacetyl-CoA synthetase 0.3595 0.7664 0.03 3.534 0.00388 0.38 AADAC 13 arylacetamide deacetylase (esterase) 0.569 0.6216 0.16 0.005588 0.9968 0.00 AADAT 51166 aminoadipate aminotransferase -0.9577 0.3876 -0.11 0.8123 0.4752 0.24 AAK1 22848 AP2 associated kinase 1 -1.261 0.2505 -0.25 0.8232 0.4689 0.12 AAMP 14 angio-associated, migratory cell protein 0.873 0.4351 0.07 1.656 0.1476 0.06 AANAT 15 arylalkylamine N-acetyltransferase -0.3998 0.7394 -0.08 0.8486 0.456 0.18 AARS 16 alanyl-tRNA synthetase 5.517 0 0.34 8.616 0 0.69 AARS2 57505 alanyl-tRNA synthetase 2, mitochondrial (putative) 1.701 0.1158 0.35 0.5011 0.6622 0.07 AARSD1 80755 alanyl-tRNA synthetase domain containing 1 4.403 9.52E-05 0.52 1.279 0.2609 0.13 AASDH 132949 aminoadipate-semialdehyde dehydrogenase -0.8921 0.4247 -0.12 -2.564 0.02993 -0.32 AASDHPPT 60496 aminoadipate-semialdehyde -

Deciphering the Genetic Basis of Spanish Familial Testicular Cancer
Departamento de Bioquímica Deciphering the genetic basis of Spanish familial testicular cancer Tesis doctoral Beatriz Paumard Hernández Madrid, 2017 Departamento de Bioquímica Facultad de Medicina Universidad Autónoma de Madrid Deciphering the genetic basis of Spanish familial testicular cancer Tesis doctoral presentada por: Beatriz Paumard Hernández Licenciada en Biología por la Universidad Autónoma de Madrid (UAM) Director de la Tesis: Dr. Javier Benítez Director del Programa de Genética del Cáncer Humano (CNIO) Jefe del Grupo de Genética Humana (CNIO) Grupo de Genética Humana Programa de Genética del Cáncer Humano Centro Nacional de Investigaciones Oncológicas (CNIO) Dr. Javier Benítez Ortiz, Director del grupo de Genética del Cáncer Humano del Centro Nacional de Investigaciones Oncológicas (CNIO) CERTIFICA: Que Doña Beatriz Paumard Hernández, Licenciada en Biología por la Universidad Autónoma de Madrid, ha realizado la presente Tesis Doctoral “Deciphering the genec basis of Spanish familial testicular cáncer” y que a su juicio reúne plenamente todos los requisitos necesarios para optar al Grado de Doctor en Bioquímica, Biología Molecular, Biomedicina y Biotecnología, a cuyos efectos será presentada en la Universidad Autónoma de Madrid. El trabajo ha sido realizado bajo mi dirección, autorizando su presentación ante el Tribunal calificador. Y para que así conste, se extiende el presente certificado, Madrid, Junio 2017 Fdo: Director de la Tesis Fdo: Tutor de la Tesis VoBo del Director Dr.Javier Benítez Ortiz La presente Tesis Doctoral se realizó en el Grupo de Genética Humana en el Centro Nacional de Investigaciones Oncológicas (CNIO) de Madrid durante los años 2013 y 2017 bajo la supervisión del Dr. Javier Benítez Las siguientes becas, ayudas y proyectos han permitido la realización de esta Tesis Doctoral: “La Caixa”- Severo Ochoa International Phd Programmme at CNIO Proyecto FIS PI12/0070 BRIDGES Project (H2020) Summary / Resumen SUMMARY Testicular cancer is a frequently occurring disease among adult males, and it accounts for 1-2% of all male tumors.