Keyword Extraction and Topic Finding Approaches in Microblogging Systems: a Survey Prachi Jain* Shanthi K
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
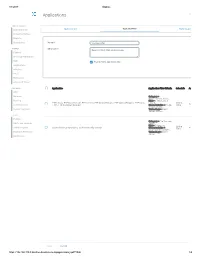
Applications Log Viewer
4/1/2017 Sophos Applications Log Viewer MONITOR & ANALYZE Control Center Application List Application Filter Traffic Shaping Default Current Activities Reports Diagnostics Name * Mike App Filter PROTECT Description Based on Block filter avoidance apps Firewall Intrusion Prevention Web Enable Micro App Discovery Applications Wireless Email Web Server Advanced Threat CONFIGURE Application Application Filter Criteria Schedule Action VPN Network Category = Infrastructure, Netw... Routing Risk = 1-Very Low, 2- FTPS-Data, FTP-DataTransfer, FTP-Control, FTP Delete Request, FTP Upload Request, FTP Base, Low, 4... All the Allow Authentication FTPS, FTP Download Request Characteristics = Prone Time to misuse, Tra... System Services Technology = Client Server, Netwo... SYSTEM Profiles Category = File Transfer, Hosts and Services Confe... Risk = 3-Medium Administration All the TeamViewer Conferencing, TeamViewer FileTransfer Characteristics = Time Allow Excessive Bandwidth,... Backup & Firmware Technology = Client Server Certificates Save Cancel https://192.168.110.3:4444/webconsole/webpages/index.jsp#71826 1/4 4/1/2017 Sophos Application Application Filter Criteria Schedule Action Applications Log Viewer Facebook Applications, Docstoc Website, Facebook Plugin, MySpace Website, MySpace.cn Website, Twitter Website, Facebook Website, Bebo Website, Classmates Website, LinkedIN Compose Webmail, Digg Web Login, Flickr Website, Flickr Web Upload, Friendfeed Web Login, MONITOR & ANALYZE Hootsuite Web Login, Friendster Web Login, Hi5 Website, Facebook Video -

NAS 232 Using Aifoto on Your Mobile Devices
NAS 232 Using AiFoto on Your Mobile Devices Manage photos on your NAS using your mobile device ASUSTOR COLLEGE NAS 232: Using AiFoto on Your Mobile Devices Devices COURSE OBJECTIVES Upon completion of this course you should be able to: 1. Use AiFoto to manage photos and albums on your NAS and mobile device. PREREQUISITES Course Prerequisites: NAS 137: Introduction to Photo Gallery Students are expected to have a working knowledge of: N/A OUTLINE 1. Introduction to AiFoto 1.1 Introduction to AiFoto 2. Basic Functions 2.1 Settings and instructions 2.2 Connecting to your NAS with AiFoto 2.3 Browsing photos with AiFoto 3. Managing albums and photos 3.1 Album management 3.1.1 Creating albums 3.1.2 Editing album information 3.1.3 Deleting albums 3.1.4 Uploading and downloading albums 3.2 Photo management ASUSTOR COLLEGE / 2 NAS 232: Using AiFoto on Your Mobile Devices Devices 3.3 Using Camera Mode 3.4 Uploading your local camera roll to your NAS 3.5 Privacy settings 4. Notes ASUSTOR COLLEGE / 3 NAS 232: Using AiFoto on Your Mobile Devices Devices 1. Introduction to AiFoto 1.1 Introduction to AiFoto AiFoto lets you access Photo Gallery from your ASUSTOR NAS on your mobile device! With AiFoto you can user your mobile device to browse and manage your NAS web photo albums and instantly upload photos from your mobile device camera roll to your NAS. AiFoto also provides you with a Camera Mode allowing you to specify an album and then have any photos you take automatically uploaded to the album. -

Systematic Scoping Review on Social Media Monitoring Methods and Interventions Relating to Vaccine Hesitancy
TECHNICAL REPORT Systematic scoping review on social media monitoring methods and interventions relating to vaccine hesitancy www.ecdc.europa.eu ECDC TECHNICAL REPORT Systematic scoping review on social media monitoring methods and interventions relating to vaccine hesitancy This report was commissioned by the European Centre for Disease Prevention and Control (ECDC) and coordinated by Kate Olsson with the support of Judit Takács. The scoping review was performed by researchers from the Vaccine Confidence Project, at the London School of Hygiene & Tropical Medicine (contract number ECD8894). Authors: Emilie Karafillakis, Clarissa Simas, Sam Martin, Sara Dada, Heidi Larson. Acknowledgements ECDC would like to acknowledge contributions to the project from the expert reviewers: Dan Arthus, University College London; Maged N Kamel Boulos, University of the Highlands and Islands, Sandra Alexiu, GP Association Bucharest and Franklin Apfel and Sabrina Cecconi, World Health Communication Associates. ECDC would also like to acknowledge ECDC colleagues who reviewed and contributed to the document: John Kinsman, Andrea Würz and Marybelle Stryk. Suggested citation: European Centre for Disease Prevention and Control. Systematic scoping review on social media monitoring methods and interventions relating to vaccine hesitancy. Stockholm: ECDC; 2020. Stockholm, February 2020 ISBN 978-92-9498-452-4 doi: 10.2900/260624 Catalogue number TQ-04-20-076-EN-N © European Centre for Disease Prevention and Control, 2020 Reproduction is authorised, provided the -

Probabilistic Forecasting in Decision-Making: New Methods and Applications
Probabilistic Forecasting in Decision-Making: New Methods and Applications Xiaojia Guo A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy of University College London. UCL School of Management University College London November 10, 2020 2 I, Xiaojia Guo, confirm that the work presented in this thesis is my own. Where information has been derived from other sources, I confirm that this has been indi- cated in the work. 3 To my family for their invaluable support throughout the years. Abstract This thesis develops new methods to generate probabilistic forecasts and applies these methods to solve operations problems in practice. The first chapter introduces a new product life cycle model, the tilted-Gompertz model, which can predict the distribution of period sales and cumulative sales over a product’s life cycle. The tilted-Gompertz model is developed by exponential tilting the Gompertz model, which has been widely applied in modelling human mortality. Due to the tilting parameter, this new model is flexible and capable of describing a wider range of shapes compared to existing life cycle models. In two empirical studies, one on the adoption of new products and the other on search interest in social networking websites, I find that the tilted-Gompertz model performs well on quantile forecast- ing and point forecasting, when compared to other leading life-cycle models. In the second chapter, I develop a new exponential smoothing model that can cap- ture life-cycle trends. This new exponential smoothing model can also be viewed as a tilted-Gompertz model with time-varying parameters. -

NAS 137 Introduction to Photo Gallery
NAS 137 Introduction to Photo Gallery Manage and share the photos on your ASUSTOR NAS ASUSTOR COLLEGE NAS 137: Introduction to Photo Gallery COURSE OBJECTIVES Upon completion of this course you should be able to: 1. Use Photo Gallery to manage and share the photos on your ASUSTOR NAS. PREREQUISITES Course Prerequisites: None Students are expected to have a working knowledge of: N/A OUTLINE 1. Introduction to Photo Gallery 1.1 Introduction to Photo Gallery 1.2 Where to get Photo Gallery 2. Using Photo Gallery 2.1 Installing Photo Gallery 2.2 Creating a new album 2.3 Album and Photo Management 2.3.1 Album management 2.3.2 Photo management 2.3.3 Search 2.3.4 Viewing photos individually and via slideshow 2.4 Co-managing albums 2.5 Social media sharing 3. Notes ASUSTOR COLLEGE / 2 NAS 137: Introduction to Photo Gallery 1. Introduction to Photo Gallery 1.1 Introduction to Photo Gallery Photo Gallery is a dedicated web photo album application for ASUSTOR NAS. After downloading and installing Photo Gallery from App Central, NAS administrators will be able to browse their photo collection on the NAS from any PC along with co-managing and sharing albums with NAS users. Photo Gallery utilizes a modern cover design for albums which is comprised of a large photo with 4 smaller thumbnails of recently uploaded photos. This allows users to easily organize their photos and keep track of the latest changes by simply viewing the album cover. Photo Gallery features a clear and crisp interface with an easy to browse photo wall along with a built-in thumbnail accelerator that allows users to quickly browse all photos. -

Twittering* for Work and Health
Twitter Twittering* for Work & Health • http://twitter.com/ * (and Plurking) PF Anderson, Emerging Technologies Librarian, Health Sciences Libraries, University of Michigan, [email protected] July 15, 2008 Twitter lifecycle Twitter is … • Twitter is a type of tool • Twitter = Microblogging (sort of) • Microblogging ≠ Twitter • Microblogging = (Twitter OR Jaiku OR Pownce OR Plurk OR Tumblr) • http://cogdoghouse.wikispaces.com/TwitterCycle Twitter is … • for friends • for news • for current events • for crisis response • for silliness • for intelligent discussion Twitter for • like fishing • like sex productivity • like a chatroom • a microblogging tool • an RSS feed generator • • the social search engine • and what else? we’ve all been waiting for 1 Twitter + time management Twitter + task management Twitter + calendar Twitter + weather Twitter + traffic More 2 Twitter + health news Twitter for discovery Twitter + health Twitter + health news news Today’s buzz – Google Health Twitter + health legislation • HR 2790 – Physician Assistants 3 Today’s buzz – Google Health Today’s buzz - Google Health • attillacsordas Today’s buzz - Google Health Today’s buzz - Google Health • dporter • laktek Today’s buzz - Google Health Today’s buzz - Google Health • Google • Google API 4 Twitter + science Using Twitter in health & healthcare Twitter + doctors Twitter + nurses Twitter + Telemedicine + Twitter + dentists Second Opinion 5 Twitter + activism Twitter + make a difference Twitter + exercise Twitter + health tracking • “Tweet your pain” Twitter + food -

Using Social Media What Is Social Media?
What is social media? Using Social Forms of electronic communication Media Users connect and share information using various tools Ideas By: Mike Collins, Liz Johnson and Emilie Meissner Information Videos Pictures Term first used in 2004 Importance of Social Media Importance of Social Media “Between 1995 and 2010, the percentage of American adults with access to the Internet “E-patient” health consumers who use grew from 10% to 75%.” (Yamout 2011) the Internet to obtain information about medical issues of interest to them Most social media tools are free Address patient concerns or respond to negative experiences Importance of Social Media Guidelines and Privacy “Medical professionals need to have an online presence to monitor what AMA (American Medical Association) information is put up and to maintain Policy: Professionalism in the Use of their online reputation.” (Glick Interview 2011) Social Media Center Specific Data ACS Center Volumes Report MCW guidelines Individual hospital/HR guidelines 1 “Facebook helps you connect and share with the people in your life.” Founded February 4, 2004 Initially used as a way for college students to connect to each other Currently has 800 million users Ways to Use Facebook Solicit patient feedback Post educational materials for patients and family members Give general information about your center Main Page/Wall Info Page Example of a post 2 First video uploaded in April 2005 YouTube allows users to view and post videos on a variety of topics Advertise your center Educate patients and patients’ families Post specific disease information More than 13 million hours of video were uploaded during 2010 and 40 hours of video are uploaded every minute. -

Tweeted out Management Tools to Prevent Social Media from Monopolizing Your Time
AALLMarch2014:1 2/14/14 8:57 AM Page 14 Tweeted Out Management tools to prevent social media from monopolizing your time By Ashley Ames Ahlbrand nyone in charge of monitoring management tools include the social media accounts for their ability to schedule posts in A workplace can attest to what a advance; the ability to auto- time-consuming task this can be. schedule posts, allowing the Although managing social media seems social media management tool quick and easy—a simple browse of a to choose the best time to post newsfeed, a quick 140-character message in order to reach the broadest now and then—monitoring more than audience; and the ability to one type of social media, or even using monitor and post to multiple platforms and/or multiple one platform diligently, can easily Image courtesy of Crystal Gibson. consume a large chunk of one’s day. This accounts within the same is due in large part to the rapidly platform all at once. Here are changing format that social media boasts; some of the more prevalent social media having to go to multiple websites. rather than dealing with a static webpage, management tools. Further, if you have multiple accounts the content in any social media platform within one platform—for instance, is constantly changing, and, if you are not Hootsuite several Twitter accounts for your watching it 24/7, you are bound to miss organization—you can create tabs for Hootsuite (www.hootsuite.com) is each of those accounts so that you can something. This article will highlight arguably one of the most popular social several prominent social media avoid having to continually log in and media management tools, allowing you out of Twitter to update each account. -

90 Lovehome (90Lovehome.Com) Is an E-Commerce Site Specializing in Home and Family Products
90 LoveHome (90lovehome.com) is an e-commerce site specializing in home and family products. Contact with us: • https://90lovehome.com/ • https://90lovehome.com/sitemap/ • https://www.facebook.com/90lovehome.official • https://twitter.com/90Lovehome • https://www.instagram.com/90lovehome.official • https://www.youtube.com/channel/UC6E87BY2QnzFToJw4sqbnCw • https://www.linkedin.com/in/90lovehomeofficial/ • https://www.pinterest.com/90lovehomeofficial/ • https://vimeo.com/90lovehome • https://github.com/90lovehome • https://docs.microsoft.com/en-us/users/90lovehome/ • https://www.reddit.com/user/90lovehome • https://90lovehome.tumblr.com/ • https://www.tumblr.com/blog/90lovehome • https://medium.com/@90lovehome.official • https://soundcloud.com/90lovehome • https://90lovehome.weebly.com/ • https://chrome.google.com/webstore/detail/90- lovehome/oldgbmpkopojenlahljecmmljibfgboi • https://dribbble.com/90lovehome • https://90lovehome.wordpress.com/ • https://www.ebay.com/usr/love8463 • https://www.tripadvisor.com/Profile/90lovehome • https://stackoverflow.com/users/14497162/90-lovehome • https://meta.stackexchange.com/users/872635/90-lovehome?tab=profile • https://www.twitch.tv/90lovehome/ • https://getpocket.com/@3eDpfT4bA3d9edb350gu942g55dSAo9e653nd5v39 fH904Hy6drHbQO7m19YRb39 • https://www.patreon.com/90lovehome • https://foursquare.com/user/590099962 • https://www.meetup.com/members/319043768/ • https://community.atlassian.com/t5/user/viewprofilepage/user-id/4135285 • https://www.trustpilot.com/users/5f911516e20bf1001903c9a4 • https://www.goodreads.com/user/show/123342616-90-lovehome -

Cover, Toc, Full Paper (2.108Mb)
USING SOCIAL MEDIA AS A MEANS TO PROMOTE NOVEL Shienny Megawati Sutanto, Marina Wardaya Universitas Ciputra, Universitas Ciputra Indonesia [email protected], [email protected] ABSTRACT The era of globalization is characterized by the development of very fast internet, nowadays many things have turned into digital form, including businesses. Promotional activity has also been faced with many changes, now promotional activities are not just limited to advertisements in print, audio and television are an expensive proposition, marketing these days can be done in various media and ways with a relatively low cost, one of them by using social media. This study aimed to identify the use of social media as a means of promotion on Facebook. Any promotional content that could lead to novel consumer awareness. The theoretical basis of this research is to use the model AIDA, namely their attention (Attention) Ketertatikan (Interest) Desire (Desire) and Action (Action) by media consumers and social theory. The research method used is a qualitative description of the research that describes the phenomenon of social media as a media campaign. With the interview method on a resource of experienced experts in the promotion of social media. The results of this study would be useful to the creative industries, especially the publishing industry when formulating promotional content on social media Facebook. Keyword : promotion, publisher, novel, consument, AIDA, social media, Facebook. INTRODUCTION The last few decades, technology and communication experienced a rapid development. The Internet has become a necessity for modern society in Indonesia. Of course we still remember that previously internet technology is only used for sending electronic messages through email and chatting, to search for information through browsing and googling. -

Social Media Is Bullshit
SOCIAL MEDIA IS BULLSHIT 053-50475_ch00_4P.indd i 7/14/12 6:37 AM 053-50475_ch00_4P.indd ii 7/14/12 6:37 AM 053-50475_ch00_4P.indd iii 7/14/12 6:37 AM social media is bullshit. Copyright © 2012 by Earth’s Temporary Solu- tion, LLC. For information, address St. Martin’s Press, 175 Fifth Avenue, New York, N.Y. 10011. www .stmartins .com Design by Steven Seighman ISBN 978- 1- 250- 00295- 2 (hardcover) ISBN 978-1-250-01750-5 (e-book) First Edition: September 2012 10 9 8 7 6 5 4 3 2 1 053-50475_ch00_4P.indd iv 7/14/12 6:37 AM To Amanda: I think you said it best, “If only we had known sooner, we would have done nothing diff erent.” 053-50475_ch00_4P.indd v 7/14/12 6:37 AM 053-50475_ch00_4P.indd vi 7/14/12 6:37 AM CONTENTS AN INTRODUCTION: BULLSHIT 101 One: Our Terrible, Horrible, No Good, Very Bad Web site 3 Two: Astonishing Tales of Mediocrity 6 Three: “I Wrote This Book for Pepsi” 10 Four: Social Media Is Bullshit 15 PART I: SOCIAL MEDIA IS BULLSHIT Five: There Is Nothing New Under the Sun . or on the Web 21 Six: Shovels and Sharecroppers 28 Seven: Yeah, That’s the Ticket! 33 Eight: And Now You Know . the Rest of the Story 43 Nine: The Asshole- Based Economy 54 053-50475_ch00_4P.indd vii 7/14/12 6:37 AM Ten: There’s No Such Thing as an Infl uencer 63 Eleven: Analyze This 74 PART II: MEET THE PEOPLE BEHIND THE BULLSHIT Twelve: Maybe “Social Media” Doesn’t Work So Well for Corporations, Either? 83 Thirteen: Kia and Facebook Sitting in a Tree . -

A Tecnocultura Atual E Suas Tendências Futuras Current Affairs
A tecnocultura atual Current Affairs and Future Trends e suas tendências futuras in Technoculture Tem sido freqüentemente lembrado que o último quarto We often remember the last quarter of the 20th cen- do século 20 não teve precedentes na escala, finalidade e tury as a period of unprecedented changes in terms of velocidade de sua transformação histórica, de modo que the extent, purpose and pace of historical transforma- a única certeza para o futuro é que ele será bem dife- tion. Thus, the only certainty we have about the future rente do que é hoje, e que assim será de maneira muito is that it will be very different from our present and mais rápida do que nunca. A razão disso tudo está na that it will run faster than ever. The reason behind revolução tecnológica, uma idéia que se tornou rotineira all of this is technological revolution, an idea that has e lugar comum, nestes tempos de tecnocultura. É, de become commonplace in the so-called technoculture fato, impressionante a aceleração das transformações era. In fact, the transformation speed experienced by dos meios tecnológicos de produção de linguagens e de technological means of language and communication comunicação. Desde a invenção da fotografia, já alcan- production is impressive. Since the invention of pho- çamos a quinta geração de tecnologias comunicacionais. tography, we have already achieved the 5th generation Este trabalho tem por objetivo apresentar brevemente of communication technologies. This paper aims at essas cinco gerações tecnológicas, a saber, as Tecno- introducing