Social Media Types: Introducing a Data Driven Taxonomy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Diaspora Engagement Possibilities for Latvian Business Development
DIASPORA ENGAGEMENT POSSIBILITIES FOR LATVIAN BUSINESS DEVELOPMENT BY DALIA PETKEVIČIENĖ CONTENTS CHAPTER I. Diaspora Engagement Possibilities for Business Development .................. 3 1. Foreword .................................................................................................................... 3 2. Introduction to Diaspora ............................................................................................ 5 2.1. What is Diaspora? ............................................................................................ 6 2.2. Types of Diaspora ............................................................................................. 8 3. Growing Trend of Governments Engaging Diaspora ............................................... 16 4. Research and Analysis of the Diaspora Potential .................................................... 18 4.1. Trade Promotion ............................................................................................ 19 4.2. Investment Promotion ................................................................................... 22 4.3. Entrepreneurship and Innovation .................................................................. 28 4.4. Knowledge and Skills Transfer ....................................................................... 35 4.5. Country Marketing & Tourism ....................................................................... 36 5. Case Study Analysis of Key Development Areas ...................................................... 44 CHAPTER II. -

Brand Messages on Twitter: Predicting Diffusion with Textual
CORE Metadata, citation and similar papers at core.ac.uk Provided by Carolina Digital Repository BRAND MESSAGES ON TWITTER: PREDICTING DIFFUSION WITH TEXTUAL CHARACTERISTICS Chris J. Vargo A dissertation submitted to the faculty at the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the School of Journalism and Mass Communication. Chapel Hill 2014 Approved by: Joe Bob Hester Donald Lewis Shaw Francesca Carpentier Justin H. Gross Jaime Arguello © 2014 Chris J. Vargo ALL RIGHTS RESERVED ii ABSTRACT Chris J. Vargo: Brand Messages On Twitter: Predicting Diffusion With Textual Characteristics (Under the direction of Joe Bob Hester) This dissertation assesses brand messages (i.e. tweets by a brand) on Twitter and the characteristics that predict the amount of engagement (a.k.a. interaction) a tweet receives. Attention is given to theories that speak to characteristics observable in text and how those characteristics affect retweet and favorite counts. Three key concepts include sentiment, arousal and concreteness. For positive sentiment, messages appeared overly positive, but still a small amount of the variance in favorites was explained. Very few tweets had strong levels of arousal, but positive arousal still explained a small amount of the variance in retweet counts. Despite research suggesting that concreteness would boost sharing and interest, concrete tweets were retweeted and shared less than vague tweets. Vagueness explained a small amount of the variance in retweet and favorite counts. The presence of hashtags and images boosted retweet and favorite counts, and also explained variance. Finally, characteristics of the brand itself (e.g. -

Social Media Compliance for Investment Advisers by Peter I
THOMSON REUTERS Social media compliance for investment advisers By Peter I. Altman, Esq., Sandra Lewitz, Esq., and Kelly Handschumacher, Esq., Akin Gump MARCH 21, 2019 Social media pervades all aspects of society, from personal This spate of activity reflects the SEC’s focus on social media as and social communications to entertainment, business and an area replete with risk for registered investment advisers and politics. Presidents and CEOs communicate through Twitter; reinforces their obligations under the advertising, books and political activists organize through Facebook; and businesses records, and compliance rules of the Investment Advisers Act of blur the distinction between content and advertisement through 1940. Instagram. It is no surprise then that government agencies and Without careful attention to the changing communications law enforcement now routinely look at social media activity, both landscape and regulatory requirements, advisers could in real time and after the fact, for evidence of illegal activity. inadvertently violate these rules. For example, an adviser inviting For its part, the Securities and Exchange Commission has shown the public to “like” an investment adviser representative’s an increasing focus on social media activity in its examinations and biography that it posted on Facebook and then receiving “likes” investigations, such as using LinkedIn profiles during enforcement could violate the Testimonial Rule.2 And an adviser failing to investigation testimony to establish a witness’s experience and maintain records of tweets that it issues to provide news about citing public tweets as the basis for enforcement actions. One the firm or of private Facebook, WhatsApp or LinkedIn messages should assume that the SEC, whether in an examination or with clients about their investments could violate the Books and enforcement investigation, will review anything publicly available Records Rule. -

Real-Time News Certification System on Sina Weibo
Real-Time News Certification System on Sina Weibo Xing Zhou1;2, Juan Cao1, Zhiwei Jin1;2,Fei Xie3,Yu Su3,Junqiang Zhang1;2,Dafeng Chu3, ,Xuehui Cao3 1Key Laboratory of Intelligent Information Processing of Chinese Academy of Sciences (CAS) Institute of Computing Technology, Beijing, China 2University of Chinese Academy of Sciences, Beijing, China 3Xinhua News Agency, Beijing, China {zhouxing,caojuan,jinzhiwei,zhangjunqiang}@ict.ac.cn {xiefei,suyu,chudafeng,caoxuehui}@xinhua.org ABSTRACT There are many works has been done on rumor detec- In this paper, we propose a novel framework for real-time tion. Storyful[2] is the world's first social media news agency, news certification. Traditional methods detect rumors on which aims to discover breaking news and verify them at the message-level and analyze the credibility of one tweet. How- first time. Sina Weibo has an official service platform1 that ever, in most occasions, we only remember the keywords encourage users to report fake news and these news will be of an event and it's hard for us to completely describe an judged by official committee members. Undoubtedly, with- event in a tweet. Based on the keywords of an event, we out proper domain knowledge, people can hardly distinguish gather related microblogs through a distributed data acqui- between fake news and other messages. The huge amount sition system which solves the real-time processing need- of microblogs also make it impossible to identify rumors by s. Then, we build an ensemble model that combine user- humans. based, propagation-based and content-based model. The Recently, many researches has been devoted to automatic experiments show that our system can give a response at rumor detection on social media. -

Exploring the Relationship Between Online Discourse and Commitment in Twitter Professional Learning Communities
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Bowling Green State University: ScholarWorks@BGSU Bowling Green State University ScholarWorks@BGSU Visual Communication and Technology Education Faculty Publications Visual Communication Technology 8-2018 Exploring the Relationship Between Online Discourse and Commitment in Twitter Professional Learning Communities Wanli Xing Fei Gao Bowling Green State University, [email protected] Follow this and additional works at: https://scholarworks.bgsu.edu/vcte_pub Part of the Communication Technology and New Media Commons, Educational Technology Commons, and the Engineering Commons Repository Citation Xing, Wanli and Gao, Fei, "Exploring the Relationship Between Online Discourse and Commitment in Twitter Professional Learning Communities" (2018). Visual Communication and Technology Education Faculty Publications. 47. https://scholarworks.bgsu.edu/vcte_pub/47 This Article is brought to you for free and open access by the Visual Communication Technology at ScholarWorks@BGSU. It has been accepted for inclusion in Visual Communication and Technology Education Faculty Publications by an authorized administrator of ScholarWorks@BGSU. Exploring the relationship between online discourse and commitment in Twitter professional learning communities Abstract Educators show great interest in participating in social-media communities, such as Twitter, to support their professional development and learning. The majority of the research into Twitter- based professional learning communities has investigated why educators choose to use Twitter for professional development and learning and what they actually do in these communities. However, few studies have examined why certain community members remain committed and others gradually drop out. To fill this gap in the research, this study investigated how some key features of online discourse influenced the continued participation of the members of a Twitter-based professional learning community. -

Guide-Twitter
Guide pour les préfectures décembre 2014 GUIDE TWITTER POUR LES PRÉFECTURES TABLE DES MATIÈRES Introduction ............................................................................................................3 I. Twitter : les grands principes ...........................................................................4 1. Qu’est-ce que c’est ? . ............................................................................................4 2. Faut-il y être présent ? . ...........................................................................................5 2.1. En matière de veille . .........................................................................................5 2.2. En matière de communication . ............................................................................6 2.3. Combien ça coûte ? .........................................................................................6 3. Comment y être présent ?. .......................................................................................7 4. Quels sont les risques ? ..........................................................................................8 4.1. Usurpation d’identité ........................................................................................8 4.2. Le manque de modestie ....................................................................................9 4.3. La transmission d’une information erronée ou contenant une faute................................10 4.4. La modération sur Twitter .................................................................................11 -

La Conciencia De Marca En Redes Sociales: Impacto En La Comunicación Boca a Boca
Estudios Gerenciales ISSN: 0123-5923 Universidad Icesi La conciencia de marca en redes sociales: impacto en la comunicación boca a boca Rubalcava de León, Cristian-Alejandro; Sánchez-Tovar, Yesenia; Sánchez-Limón, Mónica-Lorena La conciencia de marca en redes sociales: impacto en la comunicación boca a boca Estudios Gerenciales, vol. 35, núm. 152, 2019 Universidad Icesi Disponible en: http://www.redalyc.org/articulo.oa?id=21262296009 DOI: 10.18046/j.estger.2019.152.3108 PDF generado a partir de XML-JATS4R por Redalyc Proyecto académico sin fines de lucro, desarrollado bajo la iniciativa de acceso abierto Artículo de investigación La conciencia de marca en redes sociales: impacto en la comunicación boca a boca Brand awareness in social networks: impact on the word of mouth Reconhecimento de marca nas redes sociais: impacto na comunicação boca a boca Cristian-Alejandro Rubalcava de León * [email protected] Universidad Autónoma de Tamaulipas, Mexico Yesenia Sánchez-Tovar ** Universidad Autónoma de Tamaulipas, Mexico Mónica-Lorena Sánchez-Limón *** Universidad Autónoma de Tamaulipas, Mexico Estudios Gerenciales, vol. 35, núm. 152, 2019 Resumen: El objetivo del presente artículo fue identificar los determinantes de la Universidad Icesi conciencia de marca y el impacto que esta tiene en la comunicación boca a boca. Recepción: 10 Agosto 2018 El estudio se realizó usando la técnica de ecuaciones estructurales y los datos fueron Aprobación: 16 Septiembre 2019 recolectados a partir de una encuesta que se aplicó a la muestra validada, conformada por DOI: 10.18046/j.estger.2019.152.3108 208 usuarios de redes sociales en México. Los resultados confirmaron un efecto positivo y significativo de la calidad de la información en la conciencia de marca y, a su vez, se CC BY demostró el efecto directo de la conciencia de marca en la comunicación boca a boca. -
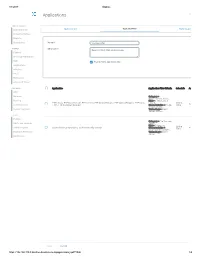
Applications Log Viewer
4/1/2017 Sophos Applications Log Viewer MONITOR & ANALYZE Control Center Application List Application Filter Traffic Shaping Default Current Activities Reports Diagnostics Name * Mike App Filter PROTECT Description Based on Block filter avoidance apps Firewall Intrusion Prevention Web Enable Micro App Discovery Applications Wireless Email Web Server Advanced Threat CONFIGURE Application Application Filter Criteria Schedule Action VPN Network Category = Infrastructure, Netw... Routing Risk = 1-Very Low, 2- FTPS-Data, FTP-DataTransfer, FTP-Control, FTP Delete Request, FTP Upload Request, FTP Base, Low, 4... All the Allow Authentication FTPS, FTP Download Request Characteristics = Prone Time to misuse, Tra... System Services Technology = Client Server, Netwo... SYSTEM Profiles Category = File Transfer, Hosts and Services Confe... Risk = 3-Medium Administration All the TeamViewer Conferencing, TeamViewer FileTransfer Characteristics = Time Allow Excessive Bandwidth,... Backup & Firmware Technology = Client Server Certificates Save Cancel https://192.168.110.3:4444/webconsole/webpages/index.jsp#71826 1/4 4/1/2017 Sophos Application Application Filter Criteria Schedule Action Applications Log Viewer Facebook Applications, Docstoc Website, Facebook Plugin, MySpace Website, MySpace.cn Website, Twitter Website, Facebook Website, Bebo Website, Classmates Website, LinkedIN Compose Webmail, Digg Web Login, Flickr Website, Flickr Web Upload, Friendfeed Web Login, MONITOR & ANALYZE Hootsuite Web Login, Friendster Web Login, Hi5 Website, Facebook Video -

Match Group Stock Pitch
Match Group Stock Pitch Analyst: James Campion First Things First Who in this room has used Tinder, Hinge, or another dating app? 2 Disclaimer I made these slides in 48 hours and took a lot of screenshots. You are allowed to take screenshots and make non-aesthetically pleasing slides for Investment Club (content matters more), but for SIBC and your full-time job do not do this! Thesis: 1. The Match Group currently holds a monopoly on the online- dating market, which is benefitting from changing social standards and increased connectivity 2. The Match Group has developed a diverse portfolio of brands, both through organic and inorganic methods, which enables them to serve customers of different ages and demographics 3. The Company’s combination of operating leverage and scale have led to expanding margins, driving a cash flow machine that should return cash to shareholders after the IAC spin-off 4. Valuation has gotten “frothy” but I still there is value as a long- term shareholder 4 Industry Focus Why online dating? More Couples Are Swiping Right ▸ In 2018, seven of the 53 couples profiled in the Vows column met on dating apps. ▸ And in the Times’ more populous Wedding Announcements section, 93 out of some 1,000 couples profiled this year met on dating apps ▸ The year before, 71 couples whose weddings were announced by the Times met on dating apps. Thanks to former NDIC President & VP, Dan McMurtie & Alex Draime for their report on the 6 dating market! Why Would Anyone Date Online?! ▸ Just a crazy thought, but what if in 10 years we think it is crazy that anyone met in person ▸ There are almost 8 billion people in the world, and we each get to meet about ~10,000 – And you’re telling me that you found your soulmate?! ▸ In the future, it might make more sense for machine learning trained algorithms to pair couples based on a number of different factors – There are just so many things it takes so long to tell someone about yourself (i.e. -

Social Media and Customer Engagement in Tourism: Evidence from Facebook Corporate Pages of Leading Cruise Companies
Social Media and Customer Engagement in Tourism: Evidence from Facebook Corporate Pages of Leading Cruise Companies Giovanni Satta, Francesco Parola, Nicoletta Buratti, Luca Persico Department of Economics and Business Studies and CIELI, University of Genoa, Italy, email: [email protected] (Corresponding author), [email protected], [email protected], [email protected] Roberto Viviani email: [email protected] Department of Economics and Business Studies, University of Genoa, Italy Abstract In the last decade, an increasing number of scholars has challenged the role of Social Media Marketing (SMM) in tourism. Indeed, Social Media (SM) provide undoubted opportunities for fostering firms’ relationships with their customers, and online customer engagement (CE) has become a common objective when developing communication strategies. Although extant literature appear very rich and heterogeneous, only a limited number of scholars have explored which kind of contents, media and posting day would engage tourists on social media. Hence, a relevant literature gap still persists, as tourism companies would greatly benefit from understanding how posting strategies on major social media may foster online CE. The paper investigates the antecedents of online CE in the tourism industry by addressing the posting activities of cruise companies on their Facebook pages. For this purpose, we scrutinize the impact of post content, format and timing on online CE, modelled as liking, commenting and sharing. In particular, we test the proposed model grounding on an empirical investigation performed on 982 Facebook posts uploaded by MSC Crociere (446), Costa Crociere (331) and Royal Caribbean Cruises (205) in a period of 12 month. -

Facebook Dating Application
Facebook Dating Application A Business Plan by Koen Heine, Alex Paninder & Fai Nopsuwanwong Idea: A Facebook dating application that will revolutionize the way people meet and date on the Internet. By choosing a superior business model, our company will outperform our competitors and change the faith of single people forever. This business plan is confidential. Business idea in itself or information from this description may not be used, reproduced or made available to third parties without the prior written permission of Koen Heine. 5/4/2011 Final Hand in –Entrepreneurship Program Facebook Dating Application Executive Summary The Internet is becoming an increasingly big part of our lives. We read the news, discover new music, watch video clips and communicate with social contacts. Meeting a romantic partner is a logical extension of the technology. This is where dating websites come in. However, research has shown that while people spend a lot of time on these websites, they are dissatisfied with the payoff. Despite the problems with current online dating solutions, the industry is estimated to be worth about $3-4 billion a year. The business model of choice for existing websites can be separated in monthly subscriptions and free dating sites that make money through advertising. According to competitive research by OkCupid, men are usually the contact initiator. On the paid dating website eHarmony, a man can expect a reply only 30% of the time, mainly because the receiving woman is not a paying member and is unable to reply. Scholarly research on a major American dating websites finds that women reply only 15.9% of the time. -

NAS 232 Using Aifoto on Your Mobile Devices
NAS 232 Using AiFoto on Your Mobile Devices Manage photos on your NAS using your mobile device ASUSTOR COLLEGE NAS 232: Using AiFoto on Your Mobile Devices Devices COURSE OBJECTIVES Upon completion of this course you should be able to: 1. Use AiFoto to manage photos and albums on your NAS and mobile device. PREREQUISITES Course Prerequisites: NAS 137: Introduction to Photo Gallery Students are expected to have a working knowledge of: N/A OUTLINE 1. Introduction to AiFoto 1.1 Introduction to AiFoto 2. Basic Functions 2.1 Settings and instructions 2.2 Connecting to your NAS with AiFoto 2.3 Browsing photos with AiFoto 3. Managing albums and photos 3.1 Album management 3.1.1 Creating albums 3.1.2 Editing album information 3.1.3 Deleting albums 3.1.4 Uploading and downloading albums 3.2 Photo management ASUSTOR COLLEGE / 2 NAS 232: Using AiFoto on Your Mobile Devices Devices 3.3 Using Camera Mode 3.4 Uploading your local camera roll to your NAS 3.5 Privacy settings 4. Notes ASUSTOR COLLEGE / 3 NAS 232: Using AiFoto on Your Mobile Devices Devices 1. Introduction to AiFoto 1.1 Introduction to AiFoto AiFoto lets you access Photo Gallery from your ASUSTOR NAS on your mobile device! With AiFoto you can user your mobile device to browse and manage your NAS web photo albums and instantly upload photos from your mobile device camera roll to your NAS. AiFoto also provides you with a Camera Mode allowing you to specify an album and then have any photos you take automatically uploaded to the album.