Proposal to Encode Additional Dialectology Latin Characters
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Brand Book Cover 2021.Pub
RR PP Commissioner QQ BB BB Rਤਦਨਲਲ਼ਤਤਣ Bਠਭਣਲ ਠਲ ਮਥ MARCH 31, 2021 REMEMBER TO REGISTER YOUR BRAND 2021 BRAND RENEWAL YEAR Alabama Law requires any livestock owner who uses a brand to identify their livestock must register their brand with the Alabama Department of Agriculture and Industries. Brands are renewed every three years. Renewals Start September 2021. Pursuant to §2-15-21 & §2-15-23 Code of Alabama 1975 S B S 1445 Federal Drive · Montgomery, Alabama 36107-1123 Rick Pate 334-240-7304 · 800-642-7761 Ext. 7304 Commissioner APPLICATION FOR LIVESTOCK BRAND REGISTRATION FOR REGISTRATION PERIOD OCTOBER 1, 2028—SEPTEMBER 30, 2021 (Please Print or Type) Date: __________________ Name: _________________________________________________________________ Business Name: _________________________________________________________________ Address: _________________________________________________________________ (Street) (City) (State) (Zip) Phone: ___________________________ E-Mail: _____________________________ County: _______________________ Livestock Type: ___________________________ Signature: _____________________________________________________________________ I hereby make application for a recorded brand to be used on livestock. IMPORTANT NOTICE Do not have irons made or brand any stock until you have received your brand certificate. BRAND EXAMPLES WITH VERBAL DESCRIPTIONS RJ LJ LJ - Left Jaw RJ - Right Jaw THERE IS A RECORDING FEE OF $ 20.00 FOR THE FIRST LOCATION AND A $ 4.00 FEE FOR EACH ADDITIONAL LOCATION. CIRCLE LOCATION YOU WISH TO RESERVE RH LH RR LR RS LS RJ LJ 1st Choice 2nd Choice 3rd Choice Verbal Description: 1st Choice _______________________________________________ 2nd Choice _______________________________________________ 3rd Choice _______________________________________________ Duplicate brands cannot be registered. Give your second and third choices to save any delays in the event your first choice has been already registered. Draw your brand exactly as it will appear on the animal. -

The Unicode Standard, Version 6.1 This File Contains an Excerpt from the Character Code Tables and List of Character Names for the Unicode Standard, Version 6.1
Latin Extended-D Range: A720–A7FF The Unicode Standard, Version 6.1 This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 6.1. Characters in this chart that are new for The Unicode Standard, Version 6.1 are shown in conjunction with any existing characters. For ease of reference, the new characters have been highlighted in the chart grid and in the names list. This file will not be updated with errata, or when additional characters are assigned to the Unicode Standard. See http://www.unicode.org/errata/ for an up-to-date list of errata. See http://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See http://www.unicode.org/charts/PDF/Unicode-6.1/ for charts showing only the characters added in Unicode 6.1. See http://www.unicode.org/Public/6.1.0/charts/ for a complete archived file of character code charts for Unicode 6.1. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 6.1 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 6.1, online at http://www.unicode.org/versions/Unicode6.1.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, and #44, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

MUFI Character Recommendation V. 3.0: Alphabetical Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 1: Alphabetical order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-402-2 ※ Characters on shaded background belong to the Private Use Area. Please read the introduction p. 11 carefully before using any of these characters. MUFI character recommendation ※ Part 1: alphabetical order version 3.0 p. 2 / 165 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). -
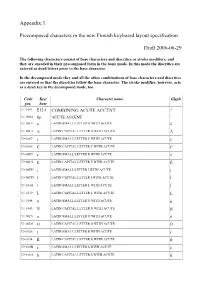
Appendix 3. Precomposed Characters in the New Finnish Keyboard Layout
Appendix 3. Precomposed characters in the new Finnish keyboard layout specification Draft 2006-06-29 The following characters consist of base characters and diacritics or stroke modifiers, and they are encoded in their precomposed form in the basic mode. In this mode the diacritics are entered as dead letters prior to the base character. In the decomposed mode they and all the other combinations of base characters and diacritics are entered so that the diacritics follow the base character. The stroke modifier, however, acts as a dead key in the decomposed mode, too. Code Key/ Character name Glyph pos. base U+0301 E12-1 COMBINING ACUTE ACCENT U+00B4 Sp. ACUTE ACCENT ´ U+00E1 a LATIN SMALL LETTER A WITH ACUTE á U+00C1 A LATIN CAPITAL LETTER A WITH ACUTE Á U+0107 c LATIN SMALL LETTER C WITH ACUTE U+0106 C LATIN CAPITAL LETTER C WITH ACUTE U+00E9 e LATIN SMALL LETTER E WITH ACUTE é U+00C9 E LATIN CAPITAL LETTER E WITH ACUTE É U+00ED i LATIN SMALL LETTER I WITH ACUTE í U+00CD I LATIN CAPITAL LETTER I WITH ACUTE Í U+013A l LATIN SMALL LETTER L WITH ACUTE U+0139 L LATIN CAPITAL LETTER L WITH ACUTE U+0144 n LATIN SMALL LETTER N WITH ACUTE U+0143 N LATIN CAPITAL LETTER N WITH ACUTE U+00F3 o LATIN SMALL LETTER O WITH ACUTE ó U+00D3 O LATIN CAPITAL LETTER O WITH ACUTE Ó U+0155 r LATIN SMALL LETTER R WITH ACUTE U+0154 R LATIN CAPITAL LETTER R WITH ACUTE U+015B s LATIN SMALL LETTER S WITH ACUTE U+015A S LATIN CAPITAL LETTER S WITH ACUTE U+00FA u LATIN SMALL LETTER U WITH ACUTE ú U+00DA U LATIN CAPITAL LETTER U WITH ACUTE Ú U+1E83 w LATIN SMALL LETTER W WITH ACUTE 3 U+1E82 W LATIN CAPITAL LETTER W WITH ACUTE 2 U+00FD y LATIN SMALL LETTER Y WITH ACUTE U+00DD Y LATIN CAPITAL LETTER Y WITH ACUTE U+017A z LATIN SMALL LETTER Z WITH ACUTE # U+0179 Z LATIN CAPITAL LETTER Z WITH ACUTE " U+01FD æ LATIN SMALL LETTER AE WITH ACUTE / U+01FC Æ LATIN CAPITAL LETTER AE WITH ACUTE . -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

Abbreviations and Conversions Page 1 of 2 Latin Abbreviations
Abbreviations and Conversions Latin Abbreviations Abbreviation Meaning Latin ad.lib. freely as wanted ad libitum aq. water aqua b.i.d. twice a day bis in die cap. capsule capula c with bar on top with cum div. divide divide eq.pts. equal parts equalis partis gtt. a drop gutta h. hour hora no. number numero O. pint octarius p.r.n. as occasion requires pro re nata q.s. a sufficient quantity quantum sufficiat q4h every 4 hours quaque 4 hora q6h every 6 hours quaque 6 hora q1d every day quaque 1 die q1w every week q.i.d. four times a day quater in die s.i.d. once a day semel in die Sig., S. write on the label signa stat. immediately statim tab. a tablet tabella t.i.d. three times a day ter in die The Apothecaries' System The Metric System Weight Weight 20 grains (gr) 1 scruple ( ) 1 picogram (pg) 10-12 gram 3 scruples 1 dram( ) = 60 grains 1000 picograms 1 nanogram (ng) or 10-9 gram 8 drams 1 ounce ( ) = 480 grains 1000 nanograms 1 microgram (ug) or 10-6 gram Volume 1000 micrograms 1 milligram (mg) or 10-3 gram 60 minims (m) 1 fluid dram ( ) 1000 milligrams 1 gram (g) 8 fluid drams 1 fluid ounce ( ) 1000 grams 1 kilogram (kg) 16 fluid ounces 1 pint (O.) Volume Know eqivalents in bold faced type 1000 milliliters (ml) 1 liter (L) Be able to interconvert all of these values Prefixes for volumes correspond to those for weight. Page 1 of 2 Abbreviations and Conversions Conversion Equivalents Approximate Exact 1 milligram 1/60 grain 1/65 grain 1 gram 15 grains 15.432 grains 1 kilogram 2.2 pounds* 2.2 pounds* 1 milliliter 15 minims 16.23 minims 1 liter 1 quart 1.06 quarts or 33.8 fluid ounces 1 grain 60 milligrams 65 milligrams 1 dram 4 grams 3.88 grams 1 ounce 30 grams 31.1 grams 1 pound* 450 grams 454 grams 1 minim 0.06 milliliter 0.062 milliliter 1 fluid dram 4 milliliters 3.7 milliliters 1 fluid ounce 30 milliliters 29.57 milliliters 1 pint 500 milliliters 473 milliliters 1 quart 1000 milliliters 946 milliliters 1 drop 1 minim 1 teaspoonful 5 milliliters 1 dessertspoonful 8 milliliters 1 tablespoonful 15 milliliters Know equivalents in bold face type. -

New Constraints on the Galactic Bar I
Draft version November 7, 2018 A Preprint typeset using LTEX style emulateapj v. 08/22/09 NEW CONSTRAINTS ON THE GALACTIC BAR I. Minchev1, J. Nordhaus1,2 and A. C. Quillen1 Draft version November 7, 2018 ABSTRACT Previous work has related the Galactic Bar to structure in the local stellar velocity distribution. Here we show that the Bar also influences the spatial gradients of the velocity vector via the Oort constants. By numerical integration of test-particles we simulate measurements of the Oort C value in a gravitational potential including the Galactic Bar. We account for the observed trend that C is increasingly negative for stars with higher velocity dispersion. By comparing measurements of C with our simulations we improve on previous models of the Bar, estimating that the Bar pattern speed is Ωb/Ω0 =1.87 ± 0.04, where Ω0 is the local circular frequency, and the Bar angle lies within ◦ ◦ 20 6 φ0 6 45 . We find that the Galactic Bar affects measurements of the Oort constants A and B less than ∼ 2 km/s/kpc for the hot stars. Subject headings: 1. INTRODUCTION Assuming the Galactic Bar affects the shape of the The Galaxy is often modeled as an axisymmetric disk. distribution function of the old stellar population in the With the ever increasing proper motion and radial ve- SN, an additional constraint on the Bar can be provided locity data, it is now apparent that nonaxisymmetric by considering the values derived for the Oort constant effects cannot be neglected (nonzero Oort constant C, C. In other words, in addition to relating the dynamical Olling & Dehnen 2003, hereafter O&D; nonzero vertex influence of the Bar to the local velocity field, C provides deviation, Famaey et al. -

Preliminary Proposal to Encode Additional Dialectology Latin Characters
Preliminary proposal to encode additional dialectology Latin characters Denis Moyogo Jacquerye <[email protected]> 2013-08-01 1. Background The recent addition of the German dialectology symbols to Unicode raises the question of other dialectology transcription systems being encoded. Romance dialectology transcription systems were created in the late 19th century or early 20th, in the same period as German dialectology systems or the International Phonetic Alphabet (IPA). Besides the Böhmer-Ascoli transcription from which the Teuthonista transcription is derived, another major transcription systems is the Rousselot-Gilliéron (French) system, and other systems have borrewed from these such as the Revista de Filología española (Spanish) system or the Romanian dialectology system. These transcription systems have been used, adapted or extended in a relatively large quantity of dialectology works (French, Spanish and Portuguese, Italian, and Romanian), some of these are being digitized and require standardized characters. More recent transcription systems were developped in the second half of the 20th century, on the basis of these transcription systems and the IPA, to accomodate larger second generation dialectology works (European: ALE, Mediteranean: ALM, Romance languages: ALiR, and others), some of these require additional characters to be encoded. The characters being proposed are used mostly in Romance languages dialectology works but not exclusively, they are also used in transcription of other linguistic families present in the areas covered by these works. The characters needed for several other dialectology transcription systems, such as the Swedish, Danish and Norwegian systems would require further work and is out of the scope of this proposal. This proposal aims to encode the missing characters needed for these transcription systems and questions the current encoding model for superscript diacritic letters with diacritics (nested letters) given their heavy use in some transcription systems. -

Revised Proposal to Encode Characters
ISO/IEC JTC1 SC2 WG2 N3981 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Revised Proposal to encode characters for the English Phonotypic Alphabet (EPA) in the UCS Source: German NB Author: Karl Pentzlin Status: National Body Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2011-01-18 Replaces: L2/10-229R, L2/10-403 Major changes compared with L2/10-229R (submitted to the UTC 2010-08-04): – The section 2.3 “Casing issues” is completely rewritten (based on the UTC feedback on Rev. 1). – The formal case pairing reflected in the character properties was rearranged considering the naming and the shape of the characters, rather than the special use in any EPA variant. – Variation sequences are no longer proposed. – In consequence of this, some characters were renamed, and the whole set was rearranged. – Three lower case forms from other sources were added, to accomplish the case pairing in the light of the valid stability policies (see the detailed explanations in the new section 2.3). – It is proposed to group capital letters without lowercase counterparts together, employing the otherwise unusable area in the “Alphabetic Presentation Forms” block. – One punctuation mark was added (an “inverted wiggly exclamation mark” was found in the sources). – In section 2.5 “Special issues on single characters”, paragraphs were added for characters where questions were raised in the UTC feedback. – The code positions of the punctuation marks were shifted to prevent overlapping with other proposals. -
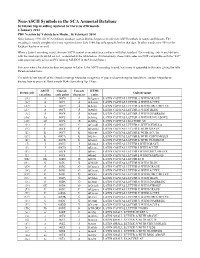
Non-ASCII Symbols in the SCA Armorial Database
Non-ASCII Symbols in the SCA Armorial Database by Iulstan Sigewealding, updated by Herveus d'Ormonde 4 January 2014 PDF Version by Yehuda ben Moshe, 16 February 2014 Since January 1996, the SCA Ordinary database (oanda.db) has begun to encode non-ASCII symbols in names and blazons. The encoding is mostly complete for items registered since July 1980, but only sporadic before that date. In other words, over 90% of the database has been revised. When a Latin-1 encoding exists, the non-ASCII symbol is encoded in accordance with that standard. The resulting code is an 8-bit byte with the most-significant bit set to 1, as detailed in the table below. (Unfortunately, these 8-bit codes are NOT compatible with the "437" code page normally active on PCs running MS-DOS in the United States.) For cases where the character does not appear in Latin-1, the ASCII encoding is used, but a note is appended to the entry giving the fully Da'ud encoded form. The table below lists all of the Da'ud encodings Morsulus recognizes. If you need something not listed there, contact Morsulus to discuss how to proceed. Don't simply Make Something Up. Please. ASCII Unicode Unicode HTML Da'ud code Unicode name encoding code point character entity {'A} A 00C0 À À LATIN CAPITAL LETTER A WITH GRAVE {A'} A 00C1 Á Á LATIN CAPITAL LETTER A WITH ACUTE {A^} A 00C2 Â Â LATIN CAPITAL LETTER A WITH CIRCUMFLEX {A~} A 00C3 Ã Ã LATIN CAPITAL LETTER A WITH TILDE {A:} A 00C4 Ä Ä LATIN CAPITAL LETTER A WITH DIAERESIS {Ao} Aa 00C5 Å Å LATIN CAPITAL LETTER -

A New Method for Determining the Milky Way Bar Pattern Speed
Mem. S.A.It. Vol. 00, 189 c SAIt 2008 Memorie della New method for determining the Milky Way bar pattern speed I. Minchev1, J. Nordhaus2 and A. C. Quillen3 1 Observatoire Astronomique, Universit´ede Strasbourg, Strasbourg, France 2 Department of Astrophysical Sciences, Princeton University, Princeton, NJ, USA 3 Department of Physics and Astronomy, University of Rochester, Rochester, NY, USA Abstract. Previous work has related the Galactic bar to structure in the local stellar ve- locity distribution. Here we show that the bar also influences the spatial gradients of the velocity vector via the Oort constants. By numerical integration of test-particles we sim- ulate measurements of the Oort C value in a gravitational potential including the Galactic bar. We account for the observed trend that C is increasingly negative for stars with higher velocity dispersion. By comparing measurements of C with our simulations we improve on previous models of the bar, estimating that the bar pattern speed is Ωb/Ω0 = 1.87 ± 0.04, ◦ ◦ where Ω0 is the local circular frequency, and the bar angle lies within 20 6 φ0 6 45 . We find that the Galactic bar affects measurements of the Oort constants A and B less than ∼ 2 km s−1 kpc−1 for the hot stars. 1. Introduction as orientation and pattern speed, have only been inferred indirectly from observations of The Galaxy is often modeled as an ax- the inner Galaxy (e.g., Blitz & Spergel 1991; isymmetric disk. With the ever increasing Weinberg 1992). proper motion and radial velocity data, it is now apparent that non-axisymmetric effects However, the bar has also been found to cannot be neglected (nonzero Oort constant affect the local velocity distribution of stars.