Computational Analysis of Audio Recordings and Music Scores for the Description and Discovery of Ottoman-Turkish Makam Music
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Terminology of Art Music in Ottoman Turkish and Modern Turkish Lexicography (19Th-21St Century)
TERMINOLOGY OF ART MUSIC IN OTTOMAN TURKISH AND MODERN TURKISH LEXICOGRAPHY (19TH-21ST CENTURY). Agata Pawlina Jagiellonian University Abstract In this paper the author presents preliminary conclusions concerning changes in forms (in respect of orthography and morphology) and semantics of musical terms in Ottoman Turkish and modern Turkish lexicography. Selected dictionaries (including mono- and bilingual, general and specialized ones) from the period between the 19th and 21st century had been analyzed. This period of time is particularly interesting for establishing how a) Turkish lexicographic works reflect the Westernization of high- culture music of the late Ottoman Empire and the young Republic of Turkey and b) differences between art music of the Ottoman and European traditions are perceived nowadays. By presenting a terminological analysis of words considered to be not only basic musicological terms but also a part of natural language (‘singer’, ‘piano’, ‘kanun’) the author unveils some of the issues associated with the translation of Turkish musical terms into European languages and vice-versa. Those problems arise from the duality and hybridity which exist in contemporary Turkish musical culture. Its older part, the so-called classical/traditional art music (tur. Türk sanat müziği or Osmanlı/Türk klasik müziği) emerged at the turn of the 17th century, as a part of a Middle Eastern art musical tradition. Later on, during modernizing efforts conducted in the declining Ottoman Empire in the 19th century, European art music had been incorporated along with its international, translingual terminology. As a result of such duality, interesting phenomena are being observed in modern Turkish vocabulary concerning art music. -

Music: the Case of Afghanistan by JOHN BAILY
from Popular Music 1, CambridgeUniversity Press 1981 Cross -cultural perspectives in popular music: the case of Afghanistan by JOHN BAILY The problem of definition It is inevitable that the first issue of this yearbook will raise questions about the use of the term 'popular music'. I do not believe that this question is going to be easy to answer and, as a precaution, I think we should regard quick and seemingly clearcut solutions with suspicion. In fact, we may eventually have to operate with intuitive, poorly defined and rather elastic definitions of popular music. Before we resort to that expedient, however, the problem of definition must be considered and discussed from various points of view. The editors have offered the following two definitions (the number- ing is mine): (1)From one point of view 'popular music' exists in any stratified society. It is seen as the music of the mass of the people ... as against that of an élite. (2) From another point of view there is at the very least a significant qualita- tive change, both in the meaning which is felt to attach to the term and in the processes to which the music owes its life, when a society undergoes indus- trialisation. From this point of view popular music is typical of societies with a relatively highly developed division of labour and a clear distinction between producers and consumers, in which cultural products are created largely by professionals, sold in a mass market and reproduced through mass media. (P. i above) The first of these definitions is very general, the second very specific. -

ASSIGNMENT and DISSERTATION TIPS (Tagg's Tips)
ASSIGNMENT and DISSERTATION TIPS (Tagg’s Tips) Online version 5 (November 2003) The Table of Contents and Index have been excluded from this online version for three reasons: [1] no index is necessary when text can be searched by clicking the Adobe bin- oculars icon and typing in what you want to find; [2] this document is supplied with direct links to the start of every section and subsection (see Bookmarks tab, screen left); [3] you only need to access one file instead of three. This version does not differ substantially from version 4 (2001): only minor alterations, corrections and updates have been effectuated. Pages are renumbered and cross-refer- ences updated. This version is produced only for US ‘Letter’ size paper. To obtain a decent print-out on A4 paper, please follow the suggestions at http://tagg.org/infoformats.html#PDFPrinting 6 Philip Tagg— Dissertation and Assignment Tips (version 5, November 2003) Introduction (Online version 5, November 2003) Why this booklet? This text was originally written for students at the Institute of Popular Music at the Uni- versity of Liverpool. It has, however, been used by many outside that institution. The aim of this document is to address recurrent problems that many students seem to experience when writing essays and dissertations. Some parts of this text may initially seem quite formal, perhaps even trivial or pedantic. If you get that impression, please remember that communicative writing is not the same as writing down commu- nicative speech. When speaking, you use gesture, posture, facial expression, changes of volume and emphasis, as well as variations in speed of delivery, vocal timbre and inflexion, to com- municate meaning. -

Automatic Dastgah Recognition Using Markov Models
Automatic Dastgah Recognition Using Markov Models Luciano Ciamarone1, Baris Bozkurt2, and Xavier Serra2 1 Independent researcher 2 Universitat Pompeu Fabra, Barcelona, Spain [email protected], [email protected], [email protected] Abstract. This work focuses on automatic Dastgah recognition of mono- phonic audio recordings of Iranian music using Markov Models. We present an automatic recognition system that models the sequence of intervals computed from quantized pitch data (estimated from audio) with Markov processes. Classification of an audio file is performed by finding the closest match between the Markov matrix of the file and the (template) matrices computed from the database for each Dastgah. Ap- plying a leave-one-out evaluation strategy on a dataset comprised of 73 files, an accuracy of 0.986 has been observed for one of the four tested distance calculation methods. Keywords: mode recognition, dastgah recognition, iranian music 1 Introduction The presented study represents the first attempt in applying Markov Model to a non-western musical mode recognition task. The proposed approach focuses on Persian musical modes which are called Dastgah. Several different approaches to the same task have already been documented. In 2011 Abdoli [3] achieved an overall accuracy of 0.85 on a 5 Dastgahs classification task by computing similarity measures between Interval Type 2 Fuzzy Sets. In 2016 Heydarian [5] compared the performances of different methods including chroma features, spectral average, pitch histograms and the use of symbolic data. He reported an accuracy of 0.9 using spectral average and Manhattan metric as a distance cal- culation method between a signal and a set of templates. -

Sibelius Artwork Guidelines Contents
Sibelius Artwork Guidelines Contents Conditions of use ...........................................................................................................................3 Important information ..................................................................................................................4 Product names and logos.............................................................................................................5 Example copy..................................................................................................................................6 Endorsees ........................................................................................................................................7 Reviews............................................................................................................................................8 Awards...........................................................................................................................................11 House Style ...................................................................................................................................12 Conditions of use Who may use this material Authorized Sibelius distributors and dealers are permitted to reproduce text and graphics on this CD in order to market Sibelius products or PhotoScore, but only if these guidelines are adhered to, and all artwork is used unmodified and cleared by Sibelius Software before production of final proofs. Acknowledge trademarks Please -

How Was the Traditional Makam Theory Westernized for the Sake of Modernization?
Rast Müzikoloji Dergisi, 2018, 6 (1): 1769-1787 Original research https://doi.org/10.12975/pp1769-1787 Özgün araştırma How was the traditional makam theory westernized for the sake of modernization? Okan Murat Öztürk Ankara Music and Fine Arts University, Department of Musicology, Ankara, Turkey [email protected] Abstract In this article, the transformative interventions of those who want to modernize the tradition- al makam theory in Westernization process experienced in Turkey are discussed in historical and critical context. The makam is among the most basic concepts of Turkish music as well as the Eastern music. In order to analyze the issue correctly in conceptual framework, here, two basic ‘music theory approaches' have been distinguished in terms of the musical elements they are based on: (i.) ‘scale-oriented’ and, (ii.) ‘melody-oriented’. The first typically represents the conception of Western harmonic tonality, while the second also represents the traditional Turkish makam conception before the Westernization period. This period is dealt with in three phases: (i.) the traditional makam concept before the ‘modernization’, (ii.) transformative interventions in the modernization phase, (iii.) recent new and critical approaches. As makam theory was used once in the history of Turkey, to convey a traditional heritage, it had a peculi- ar way of practice and education in its own cultural frame. It is determined that three different theoretical models based on mathematics, philosophy or composition had been used to explain the makams. In the 19th century, Turkish modernization was resulted in a stage in which a desire to ‘resemble to the West’ began to emerge. -

MOLA Guidelines for Music Preparation
3 MOLA Guidelines for Music Preparation Foreword These guidelines for the preparation of music scores and parts are the result of many hours of discussion regarding the creation and layout of performance material that has come through our libraries. We realize that each music publisher has its own set of guidelines for music engraving. For new or self-published composers or arrangers, we would like to express our thoughts regarding the preparation of performance materials. Using notation so!ware music publishers and professional composers and arrangers are creating scores and parts that are as functional and beautiful as traditionally engraved music. " .pdf (portable document format) is the suggested final file format as it is independent of application so!ware, hardware, and operating system. "ll ma%or notation so!ware has the option to save a file in this format. "s digital storage and distribution of music data files becomes more common, there is the danger that the librarian will be obliged to assume the role of music publisher, expected to print, duplicate, and bind all of the sheet music. &ot all libraries have the facilities, sta', or time to accommodate these pro%ects, and while librarians can advise on the format and layout of printed music, they should not be expected to act as a surrogate publisher. The ma%ority of printed music is now produced using one of the established music notation so!ware programs. (ome of the guidelines that follow may well be implemented in such programs but the so!ware user, as well as anyone producing material by hand, will still find them beneficial. -

An App to Find Useful Glissandos on a Pedal Harp by Bill Ooms
HarpPedals An app to find useful glissandos on a pedal harp by Bill Ooms Introduction: For many years, harpists have relied on the excellent book “A Harpist’s Survival Guide to Glisses” by Kathy Bundock Moore. But if you are like me, you don’t always carry all of your books with you. Many of us now keep our music on an iPad®, so it would be convenient to have this information readily available on our tablet. For those of us who don’t use a tablet for our music, we may at least have an iPhone®1 with us. The goal of this app is to provide a quick and easy way to find the various pedal settings for commonly used glissandos in any key. Additionally, it would be nice to find pedal positions that produce a gliss for common chords (when possible). Device requirements: The application requires an iPhone or iPad running iOS 11.0 or higher. Devices with smaller screens will not provide enough space. The following devices are recommended: iPhone 7, 7Plus, 8, 8Plus, X iPad 9.7-inch, 10.5-inch, 12.9-inch Set the pedals with your finger: In the upper window, you can set the pedal positions by tapping the upper, middle, or lower position for flat, natural, and sharp pedal position. The scale or chord represented by the pedal position is shown in the list below the pedals (to the right side). Many pedal positions do not form a chord or scale, so this window may be blank. Often, there are several alternate combinations that can give the same notes. -
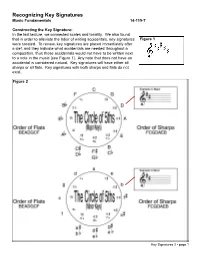
Recognizing Key Signatures Music Fundamentals 14-119-T
Recognizing Key Signatures Music Fundamentals 14-119-T Constructing the Key Signature: In the last lecture, we connected scales and tonality. We also found that in order to alleviate the labor of writing accidentals, key signatures Figure 1 were created. To review, key signatures are placed immediately after a clef, and they indicate what accidentals are needed throughout a composition, thus those accidentals would not have to be written next to a note in the music [see Figure 1]. Any note that does not have an accidental is considered natural. Key signatures will have either all sharps or all flats. Key signatures with both sharps and flats do not exist. Figure 2 Key Signatures 2 - page 1 The Circle of 5ths: One of the easiest ways of recognizing key signatures is by using the circle of 5ths [see Figure 2]. To begin, we must simply memorize the key signature without any flats or sharps. For a major key, this is C-major and for a minor key, A-minor. After that, we can figure out the key signature by following the diagram in Figure 2. By adding one sharp, the key signature moves up a perfect 5th from what preceded it. Therefore, since C-major has not sharps or flats, by adding one sharp to the key signa- ture, we find G-major (G is a perfect 5th above C). You can see this by moving clockwise around the circle of 5ths. For key signatures with flats, we move counter-clockwise around the circle. Since we are moving “backwards,” it makes sense that by adding one flat, the key signature is a perfect 5th below from what preceded it. -

Scanscore 2 Manual
ScanScore 2 Manual Copyright © 2020 by Lugert Verlag. All Rights Reserved. ScanScore 2 Manual Inhaltsverzeichnis Welcome to ScanScore 2 ..................................................................................... 3 Overview ...................................................................................................... 4 Quickstart ..................................................................................................... 4 What ScanScore is not .................................................................................... 6 Scanning and importing scores ............................................................................ 6 Importing files ............................................................................................... 7 Using a scanner ............................................................................................. 7 Using a smartphone ....................................................................................... 7 Open ScanScore project .................................................................................. 8 Multipage import ............................................................................................ 8 Working with ScanScore ..................................................................................... 8 The menu bar ................................................................................................ 8 The File Menu ............................................................................................ 9 The -

Music in Theory and Practice
CHAPTER 4 Chords Harmony Primary Triads Roman Numerals TOPICS Chord Triad Position Simple Position Triad Root Position Third Inversion Tertian First Inversion Realization Root Second Inversion Macro Analysis Major Triad Seventh Chords Circle Progression Minor Triad Organum Leading-Tone Progression Diminished Triad Figured Bass Lead Sheet or Fake Sheet Augmented Triad IMPORTANT In the previous chapter, pairs of pitches were assigned specifi c names for identifi cation CONCEPTS purposes. The phenomenon of tones sounding simultaneously frequently includes group- ings of three, four, or more pitches. As with intervals, identifi cation names are assigned to larger tone groupings with specifi c symbols. Harmony is the musical result of tones sounding together. Whereas melody implies the Harmony linear or horizontal aspect of music, harmony refers to the vertical dimension of music. A chord is a harmonic unit with at least three different tones sounding simultaneously. Chord The term includes all possible such sonorities. Figure 4.1 #w w w w w bw & w w w bww w ww w w w w w w w‹ Strictly speaking, a triad is any three-tone chord. However, since western European music Triad of the seventeenth through the nineteenth centuries is tertian (chords containing a super- position of harmonic thirds), the term has come to be limited to a three-note chord built in superposed thirds. The term root refers to the note on which a triad is built. “C major triad” refers to a major Triad Root triad whose root is C. The root is the pitch from which a triad is generated. 73 3711_ben01877_Ch04pp73-94.indd 73 4/10/08 3:58:19 PM Four types of triads are in common use. -

10 Steps to Producing Better Materials
10 STEPS TO PRODUCING BETTER MATERIALS If you are a composer who prepares your own parts, it’s pretty likely you are using computer software to typeset your music. The two most commonly used programs are Sibelius and Finale. I would like to offer some tips on how to prepare materials that are elegant and readable for your performers, so you won’t receive the dreaded call from the orchestra librarian “there are some serious problems with your parts.” 1. Proofread Your Score It may seem self evident, but I seldom receive a score from a composer that has been professionally proofread. Don’t trust the playback features of your software; they are helpful tools, but they can’t substitute for careful visual examination of the music. Be sure to print out the final score and carefully go through it. Proofreading onscreen is like scuba diving for treasure without a light; it’s pretty hit or miss what you will find. Pay particular attention to the extremes of the page and/or system (the end of one system, the start of the next). Be organized, and don’t try to read the music and imagine it in your head. Instead, try to look at the musical details and check everything for accuracy. Check items for continuity. If it says pizz., did you remember to put in arco? If the trumpet is playing with a harmon mute on page 10 and you never say senza sord., it will be that way for the rest of your piece, or the player will raise their hand in rehearsal and waste valuable time asking “do I ever remove this mute”? 2.