Gene Regulation Gravitates Toward Either Addition Or Multiplication When Combining the Effects of Two Signals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

The CXCR4 Antagonist AMD3100 Impairs Survival of Human AML Cells and Induces Their Differentiation
Leukemia (2008) 22, 2151–2158 & 2008 Macmillan Publishers Limited All rights reserved 0887-6924/08 $32.00 www.nature.com/leu ORIGINAL ARTICLE The CXCR4 antagonist AMD3100 impairs survival of human AML cells and induces their differentiation S Tavor1, M Eisenbach1, J Jacob-Hirsch2, T Golan1, I Petit1, K BenZion1, S Kay1, S Baron1, N Amariglio2, V Deutsch1, E Naparstek1 and G Rechavi2 1Institute of Hematology and Bone Marrow Transplantation, Sourasky Medical Center, Tel Aviv, Israel and 2Cancer Research Center, Sheba Medical Center, Tel-Hashomer, and Sackler School of Medicine, Tel Aviv University, Tel Aviv, Israel The chemokine stromal cell-derived factor-1 (SDF-1) and its NOD/SCID mice, homing and subsequent engraftment of human receptor, CXCR4, participate in the retention of acute myelo- normal or AML stem cells are dependent on the expression of cell blastic leukemia (AML) cells within the bone marrow micro- 9–12 environment and their release into the circulation. AML cells surface CXCR4 and SDF-1 produced within the murine. In also constitutively express SDF-1-dependent elastase, which addition to controlling cell motility, SDF-1 regulates cell regulates their migration and proliferation. To study the proliferation, induces cell cycle progression and acts as a survival molecular events and genes regulated by the SDF-1/CXCR4 factor for normal human stem cells and AML cells.13–16 axis and elastase in AML cells, we examined gene expression CXCR4 blockage in AML cells, using the polypeptide profiles of the AML cell line, U937, under treatment with a RCP168, enhanced chemotherapy-induced apoptosis in vitro.17 neutralizing anti-CXCR4 antibody or elastase inhibitor, as compared with non-treated cells, using DNA microarray Most importantly, high CXCR4 expression level in leukemic technology. -

Genome-Wide DNA Methylation Analysis of KRAS Mutant Cell Lines Ben Yi Tew1,5, Joel K
www.nature.com/scientificreports OPEN Genome-wide DNA methylation analysis of KRAS mutant cell lines Ben Yi Tew1,5, Joel K. Durand2,5, Kirsten L. Bryant2, Tikvah K. Hayes2, Sen Peng3, Nhan L. Tran4, Gerald C. Gooden1, David N. Buckley1, Channing J. Der2, Albert S. Baldwin2 ✉ & Bodour Salhia1 ✉ Oncogenic RAS mutations are associated with DNA methylation changes that alter gene expression to drive cancer. Recent studies suggest that DNA methylation changes may be stochastic in nature, while other groups propose distinct signaling pathways responsible for aberrant methylation. Better understanding of DNA methylation events associated with oncogenic KRAS expression could enhance therapeutic approaches. Here we analyzed the basal CpG methylation of 11 KRAS-mutant and dependent pancreatic cancer cell lines and observed strikingly similar methylation patterns. KRAS knockdown resulted in unique methylation changes with limited overlap between each cell line. In KRAS-mutant Pa16C pancreatic cancer cells, while KRAS knockdown resulted in over 8,000 diferentially methylated (DM) CpGs, treatment with the ERK1/2-selective inhibitor SCH772984 showed less than 40 DM CpGs, suggesting that ERK is not a broadly active driver of KRAS-associated DNA methylation. KRAS G12V overexpression in an isogenic lung model reveals >50,600 DM CpGs compared to non-transformed controls. In lung and pancreatic cells, gene ontology analyses of DM promoters show an enrichment for genes involved in diferentiation and development. Taken all together, KRAS-mediated DNA methylation are stochastic and independent of canonical downstream efector signaling. These epigenetically altered genes associated with KRAS expression could represent potential therapeutic targets in KRAS-driven cancer. Activating KRAS mutations can be found in nearly 25 percent of all cancers1. -

SUPPLEMENTARY MATERIAL Bone Morphogenetic Protein 4 Promotes
www.intjdevbiol.com doi: 10.1387/ijdb.160040mk SUPPLEMENTARY MATERIAL corresponding to: Bone morphogenetic protein 4 promotes craniofacial neural crest induction from human pluripotent stem cells SUMIYO MIMURA, MIKA SUGA, KAORI OKADA, MASAKI KINEHARA, HIROKI NIKAWA and MIHO K. FURUE* *Address correspondence to: Miho Kusuda Furue. Laboratory of Stem Cell Cultures, National Institutes of Biomedical Innovation, Health and Nutrition, 7-6-8, Saito-Asagi, Ibaraki, Osaka 567-0085, Japan. Tel: 81-72-641-9819. Fax: 81-72-641-9812. E-mail: [email protected] Full text for this paper is available at: http://dx.doi.org/10.1387/ijdb.160040mk TABLE S1 PRIMER LIST FOR QRT-PCR Gene forward reverse AP2α AATTTCTCAACCGACAACATT ATCTGTTTTGTAGCCAGGAGC CDX2 CTGGAGCTGGAGAAGGAGTTTC ATTTTAACCTGCCTCTCAGAGAGC DLX1 AGTTTGCAGTTGCAGGCTTT CCCTGCTTCATCAGCTTCTT FOXD3 CAGCGGTTCGGCGGGAGG TGAGTGAGAGGTTGTGGCGGATG GAPDH CAAAGTTGTCATGGATGACC CCATGGAGAAGGCTGGGG MSX1 GGATCAGACTTCGGAGAGTGAACT GCCTTCCCTTTAACCCTCACA NANOG TGAACCTCAGCTACAAACAG TGGTGGTAGGAAGAGTAAAG OCT4 GACAGGGGGAGGGGAGGAGCTAGG CTTCCCTCCAACCAGTTGCCCCAAA PAX3 TTGCAATGGCCTCTCAC AGGGGAGAGCGCGTAATC PAX6 GTCCATCTTTGCTTGGGAAA TAGCCAGGTTGCGAAGAACT p75 TCATCCCTGTCTATTGCTCCA TGTTCTGCTTGCAGCTGTTC SOX9 AATGGAGCAGCGAAATCAAC CAGAGAGATTTAGCACACTGATC SOX10 GACCAGTACCCGCACCTG CGCTTGTCACTTTCGTTCAG Suppl. Fig. S1. Comparison of the gene expression profiles of the ES cells and the cells induced by NC and NC-B condition. Scatter plots compares the normalized expression of every gene on the array (refer to Table S3). The central line -

1714 Gene Comprehensive Cancer Panel Enriched for Clinically Actionable Genes with Additional Biologically Relevant Genes 400-500X Average Coverage on Tumor
xO GENE PANEL 1714 gene comprehensive cancer panel enriched for clinically actionable genes with additional biologically relevant genes 400-500x average coverage on tumor Genes A-C Genes D-F Genes G-I Genes J-L AATK ATAD2B BTG1 CDH7 CREM DACH1 EPHA1 FES G6PC3 HGF IL18RAP JADE1 LMO1 ABCA1 ATF1 BTG2 CDK1 CRHR1 DACH2 EPHA2 FEV G6PD HIF1A IL1R1 JAK1 LMO2 ABCB1 ATM BTG3 CDK10 CRK DAXX EPHA3 FGF1 GAB1 HIF1AN IL1R2 JAK2 LMO7 ABCB11 ATR BTK CDK11A CRKL DBH EPHA4 FGF10 GAB2 HIST1H1E IL1RAP JAK3 LMTK2 ABCB4 ATRX BTRC CDK11B CRLF2 DCC EPHA5 FGF11 GABPA HIST1H3B IL20RA JARID2 LMTK3 ABCC1 AURKA BUB1 CDK12 CRTC1 DCUN1D1 EPHA6 FGF12 GALNT12 HIST1H4E IL20RB JAZF1 LPHN2 ABCC2 AURKB BUB1B CDK13 CRTC2 DCUN1D2 EPHA7 FGF13 GATA1 HLA-A IL21R JMJD1C LPHN3 ABCG1 AURKC BUB3 CDK14 CRTC3 DDB2 EPHA8 FGF14 GATA2 HLA-B IL22RA1 JMJD4 LPP ABCG2 AXIN1 C11orf30 CDK15 CSF1 DDIT3 EPHB1 FGF16 GATA3 HLF IL22RA2 JMJD6 LRP1B ABI1 AXIN2 CACNA1C CDK16 CSF1R DDR1 EPHB2 FGF17 GATA5 HLTF IL23R JMJD7 LRP5 ABL1 AXL CACNA1S CDK17 CSF2RA DDR2 EPHB3 FGF18 GATA6 HMGA1 IL2RA JMJD8 LRP6 ABL2 B2M CACNB2 CDK18 CSF2RB DDX3X EPHB4 FGF19 GDNF HMGA2 IL2RB JUN LRRK2 ACE BABAM1 CADM2 CDK19 CSF3R DDX5 EPHB6 FGF2 GFI1 HMGCR IL2RG JUNB LSM1 ACSL6 BACH1 CALR CDK2 CSK DDX6 EPOR FGF20 GFI1B HNF1A IL3 JUND LTK ACTA2 BACH2 CAMTA1 CDK20 CSNK1D DEK ERBB2 FGF21 GFRA4 HNF1B IL3RA JUP LYL1 ACTC1 BAG4 CAPRIN2 CDK3 CSNK1E DHFR ERBB3 FGF22 GGCX HNRNPA3 IL4R KAT2A LYN ACVR1 BAI3 CARD10 CDK4 CTCF DHH ERBB4 FGF23 GHR HOXA10 IL5RA KAT2B LZTR1 ACVR1B BAP1 CARD11 CDK5 CTCFL DIAPH1 ERCC1 FGF3 GID4 HOXA11 IL6R KAT5 ACVR2A -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Transcription Factor Gene Expression Profiling and Analysis of SOX Gene Family Transcription Factors in Human Limbal Epithelial
Transcription factor gene expression profiling and analysis of SOX gene family transcription factors in human limbal epithelial progenitor cells Der Naturwissenschaftlichen Fakultät der Friedrich-Alexander-Universität Erlangen-Nürnberg zur Erlangung des Doktorgrades Dr. rer. nat. vorgelegt von Dr. med. Johannes Menzel-Severing aus Bonn Als Dissertation genehmigt von der Naturwissenschaftlichen Fakultät der Friedrich-Alexander-Universität Erlangen-Nürnberg Tag der mündlichen Prüfung: 7. Februar 2018 Vorsitzender des Promotionsorgans: Prof. Dr. Georg Kreimer Gutachter: Prof. Dr. Andreas Feigenspan Prof. Dr. Ursula Schlötzer-Schrehardt 1 INDEX 1. ABSTRACTS Page 1.1. Abstract in English 4 1.2. Zusammenfassung auf Deutsch 7 2. INTRODUCTION 2.1. Anatomy and histology of the cornea and the corneal surface 11 2.2. Homeostasis of corneal epithelium and the limbal stem cell paradigm 13 2.3. The limbal stem cell niche 15 2.4. Cell therapeutic strategies in ocular surface disease 17 2.5. Alternative cell sources for transplantation to the corneal surface 18 2.6. Transcription factors in cell differentiation and reprogramming 21 2.7. Transcription factors in limbal epithelial cells 22 2.8. Research question 25 3. MATERIALS AND METHODS 3.1. Human donor corneas 27 3.2. Laser Capture Microdissection (LCM) 28 3.3. RNA amplification and RT2 profiler PCR arrays 29 3.4. Real-time PCR analysis 33 3.5. Immunohistochemistry 34 3.6. Limbal epithelial cell culture 38 3.7. Transcription-factor knockdown/overexpression in vitro 39 3.8. Proliferation assay 40 3.9. Western blot 40 3.10. Statistical analysis 41 2 4. RESULTS 4.1. Quality control of LCM-isolated and amplified RNA 42 4.2. -
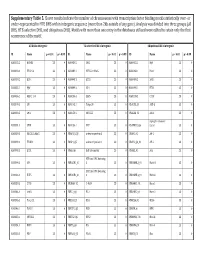
Supplementary Table 5. Clover Results Indicate the Number Of
Supplementary Table 5. Clover results indicate the number of chromosomes with transcription factor binding motifs statistically over‐ or under‐represented in HTE DHS within intergenic sequence (more than 2kb outside of any gene). Analysis was divided into three groups (all DHS, HTE‐selective DHS, and ubiquitous DHS). Motifs with more than one entry in the databases utilized were edited to retain only the first occurrence of the motif. All DHS x Intergenic TEselective DHS x Intergenic Ubiquitous DHS x Intergenic ID Name p < 0.01 p > 0.99 ID Name p < 0.01 p > 0.99 ID Name p < 0.01 p > 0.99 MA0002.2 RUNX1 23 0 MA0080.2 SPI1 23 0 MA0055.1 Myf 23 0 MA0003.1 TFAP2A 23 0 MA0089.1 NFE2L1::MafG 23 0 MA0068.1 Pax4 23 0 MA0039.2 Klf4 23 0 MA0098.1 ETS1 23 0 MA0080.2 SPI1 23 0 MA0055.1 Myf 23 0 MA0099.2 AP1 23 0 MA0098.1 ETS1 23 0 MA0056.1 MZF1_1‐4 23 0 MA0136.1 ELF5 23 0 MA0139.1 CTCF 23 0 MA0079.2 SP1 23 0 MA0145.1 Tcfcp2l1 23 0 V$ALX3_01 ALX‐3 23 0 MA0080.2 SPI1 23 0 MA0150.1 NFE2L2 23 0 V$ALX4_02 Alx‐4 23 0 myocyte enhancer MA0081.1 SPIB 23 0 MA0156.1 FEV 23 0 V$AMEF2_Q6 factor 23 0 MA0089.1 NFE2L1::MafG 23 0 V$AP1FJ_Q2 activator protein 1 23 0 V$AP1_01 AP‐1 23 0 MA0090.1 TEAD1 23 0 V$AP4_Q5 activator protein 4 23 0 V$AP2_Q6_01 AP‐2 23 0 MA0098.1 ETS1 23 0 V$AR_Q6 half‐site matrix 23 0 V$ARX_01 Arx 23 0 BTB and CNC homolog MA0099.2 AP1 23 0 V$BACH1_01 1 23 0 V$BARHL1_01 Barhl‐1 23 0 BTB and CNC homolog MA0136.1 ELF5 23 0 V$BACH2_01 2 23 0 V$BARHL2_01 Barhl2 23 0 MA0139.1 CTCF 23 0 V$CMAF_02 C‐MAF 23 0 V$BARX1_01 Barx1 23 0 MA0144.1 Stat3 23 0 -

Aberrant HOXC Expression Accompanies the Malignant Phenotype in Human Prostate1
[CANCER RESEARCH 63, 5879–5888, September 15, 2003] Aberrant HOXC Expression Accompanies the Malignant Phenotype in Human Prostate1 Gary J. Miller,2 Heidi L. Miller, Adrie van Bokhoven, James R. Lambert, Priya N. Werahera, Osvaldo Schirripa,3 M. Scott Lucia, and Steven K. Nordeen4 Department of Pathology, University of Colorado Health Sciences Center, Denver, Colorado 80262 ABSTRACT breast (13, 14), and renal (15) carcinomas; melanomas (16); and squamous carcinomas of the skin (17). Because the genes implicated Dysregulation of HOX gene expression has been implicated as a factor show little consensus, the dysregulation may be a tissue-specific in malignancies for a number of years. However, no consensus has perturbation of the existing HOX expression pattern rather than a emerged regarding specific causative genes. Using a degenerate reverse transcription-PCR technique, we show up-regulation of genes from the single causative gene. Tissue-specific expression patterns have been HOXC cluster in malignant prostate cell lines and lymph node metastases. reported in kidney and colon, by Northern blot analysis (12, 15). When relative expression levels of the four HOX clusters were examined, Primary tumors in both kidney and colon showed variations in spe- lymph node metastases and cell lines derived from lymph node metastases cific HOX gene expression from the corresponding normal tissue, but exhibited very similar patterns, patterns distinct from those in benign cells overall expression patterns for individual tumors were not reported. or malignant cell lines derived from other tumor sites. Specific reverse Only primary kidney tumors were examined (15), but liver metastases transcription-PCR for HOXC4, HOXC5, HOXC6, and HOXC8 confirmed from colon tumors reportedly displayed expression of specific HOX overexpression of these genes in malignant cell lines and lymph node genes similar to that seen in either primary colon tumors or normal metastases. -

Association Between HOTAIR Lncrna Polymorphisms and Coronary Artery Disease Susceptibility
Journal of Personalized Medicine Article Association between HOTAIR lncRNA Polymorphisms and Coronary Artery Disease Susceptibility In-Jai Kim 1,†, Jeong-Yong Lee 2,†, Hyeon-Woo Park 2, Han-Sung Park 2, Eun-Ju Ko 2, Jung-Hoon Sung 1 and Nam-Keun Kim 2,* 1 CHA Bundang Medical Center, Department of Cardiology, CHA University, Seongnam 13496, Korea; [email protected] (I.-J.K.); [email protected] (J.-H.S.) 2 Department of Biomedical Science, College of Life Science, CHA University, Seongnam 13488, Korea; [email protected] (J.-Y.L.); [email protected] (H.-W.P.); [email protected] (H.-S.P.); [email protected] (E.-J.K.) * Correspondence: [email protected]; Tel.: +82-31-881-7137; Fax: +82-31-881-7249 † Theses authors contributed equally to this work. Abstract: Coronary artery disease (CAD), one of the most frequent causes of mortality, is the most common type of cardiovascular disease. This condition is characterized by the accumulation of plaques in the coronary artery, leading to blockage of blood flow to the heart. The main symptom of CAD is chest pain caused by blockage of the coronary artery and shortness of breath. HOX transcript antisense RNA gene (HOTAIR) is a long non-coding RNA which is well-known as an oncogene involved in various cancers, such as lung, breast, colorectal, and gastric cancer. We selected six single nucleotide polymorphisms, rs4759314 A>G, rs1899663 G>T, rs920778 T>C, rs7958904 G>C, rs12826786 C>T, and rs874945 C>T, for genotype frequency analysis and assessed the frequency of HOTAIR Citation: Kim, I.-J.; Lee, J.-Y.; gene polymorphisms in 442 CAD patients and 418 randomly selected control subjects. -

Identification of Key Differentially Expressed Genes and Gene
Zhu et al. World Journal of Surgical Oncology (2020) 18:52 https://doi.org/10.1186/s12957-020-01820-z RESEARCH Open Access Identification of key differentially expressed genes and gene mutations in breast ductal carcinoma in situ using RNA-seq analysis Congyuan Zhu*, Hao Hu, Jianping Li*, Jingli Wang, Ke Wang and Jingqiu Sun Abstract Background: The aim of this study was to identify the key differentially expressed genes (DEGs) and high-risk gene mutations in breast ductal carcinoma in situ (DCIS). Methods: Raw data (GSE36863) were downloaded from the database of Gene Expression Omnibus (GEO), including three DCIS samples (DCIS cell lines MCF10.DCIS, Sum102, and Sum225) and one normal control sample (normal mammary epithelial cell line MCF10A). The DEGs were analyzed using NOIseq and annotated via DAVID. Motif scanning in the promoter region of DEGs was performed via SeqPos. Additionally, single nucleotide variations (SNVs) were identified via GenomeAnalysisTK and SNV risk was assessed via VarioWatch. Mutant genes with a high frequency and risk were validated by RT-PCR analyses. Results: Finally, 5391, 7073, and 7944 DEGs were identified in DCIS, Sum102, and Sum22 cell lines, respectively, when compared with MCF10A. VENN analysis of the three cell lines revealed 603 upregulated and 1043 downregulated DEGs, including 16 upregulated and 36 downregulated transcription factor (TF) genes. In addition, six TFs each (e.g., E2F1 and CREB1) were found to regulate the core up- and downregulated DEGs, respectively. Furthermore, SNV detection results revealed 1104 (MCF10.DCIS), 2833 (Sum102), and 1132 (Sum22) mutation sites. Four mutant genes (RWDD4, SDHC, SEPT7, and SFN) with high frequency and risk were identified. -

1 Novel Expression Signatures Identified by Transcriptional Analysis
ARD Online First, published on October 7, 2009 as 10.1136/ard.2009.108043 Ann Rheum Dis: first published as 10.1136/ard.2009.108043 on 7 October 2009. Downloaded from Novel expression signatures identified by transcriptional analysis of separated leukocyte subsets in SLE and vasculitis 1Paul A Lyons, 1Eoin F McKinney, 1Tim F Rayner, 1Alexander Hatton, 1Hayley B Woffendin, 1Maria Koukoulaki, 2Thomas C Freeman, 1David RW Jayne, 1Afzal N Chaudhry, and 1Kenneth GC Smith. 1Cambridge Institute for Medical Research and Department of Medicine, Addenbrooke’s Hospital, Hills Road, Cambridge, CB2 0XY, UK 2Roslin Institute, University of Edinburgh, Roslin, Midlothian, EH25 9PS, UK Correspondence should be addressed to Dr Paul Lyons or Prof Kenneth Smith, Department of Medicine, Cambridge Institute for Medical Research, Addenbrooke’s Hospital, Hills Road, Cambridge, CB2 0XY, UK. Telephone: +44 1223 762642, Fax: +44 1223 762640, E-mail: [email protected] or [email protected] Key words: Gene expression, autoimmune disease, SLE, vasculitis Word count: 2,906 The Corresponding Author has the right to grant on behalf of all authors and does grant on behalf of all authors, an exclusive licence (or non-exclusive for government employees) on a worldwide basis to the BMJ Publishing Group Ltd and its Licensees to permit this article (if accepted) to be published in Annals of the Rheumatic Diseases and any other BMJPGL products to exploit all subsidiary rights, as set out in their licence (http://ard.bmj.com/ifora/licence.pdf). http://ard.bmj.com/ on September 29, 2021 by guest. Protected copyright. 1 Copyright Article author (or their employer) 2009.