Graphical System Visualization and Flow Display a Visual Representation of an Authentication, Authorization, and Accounting Backend
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Integrating Wi-Fi and Femtocells a Feasibility Study Based on a Techno Economic Comparison of the Two Technologies
Integrating Wi-Fi and Femtocells A feasibility study based on a techno economic comparison of the two technologies RAZVAN POPESCU Master of Science Thesis Stockholm, Sweden 2013 Integrating Wi-Fi and Femtocells A feasibility study based on a techno economic comparison of the two technologies Student Razvan Popescu Supervisor Ashraf Awadelakrim Widaa Ahmed Examiner Jan I Markendahl Wireless@KTH School of Information and Communication Technology, KTH-Royal Institute of Technology, Stockholm, Sweden June 2013 Abstract At the end of 2009 mobile industry reached an inevitable milestone; the aggregated mobile data traffic exceeded voice traffic in the mobile networks. Starting with this point, data consumption has been continuously increasing and there are no signs that this behaviour will change in the future. For this reason mobile operators face nowadays a new paradox: they have to invest massively in their networks in order to sustain the increasing traffic while revenues are not expected to rise. This means that in order to survive, operators have to add extra capacity in a cost-efficient way. Using indoor solutions and mobile data offloading has been considered one right approach for solving this issue. While indoor solutions like Distributed Antenna Systems and repeaters have been used in the mobile networks for some time now, data offloading represents a relatively newcomer in the mobile industry. Using this concept, data traffic generated by mobile devices is moved towards alternative networks releasing the congestion in the operators’ macrocell layers. Among indoor solutions, two technologies stepped forward, Wi-Fi and Femtocells. This MSc thesis studies these two technologies, making a techno- economic comparison between them with respect on QoS level, interference, security and capacity-cost ratio. -

A Techno-Economic Comparison Between Outdoor Macro-Cellular and Indoor Offloading Solutions
A techno-economic comparison between outdoor macro-cellular and indoor offloading solutions FEIDIAS MOULIANITAKIS Master's Degree Project Stockholm, Sweden August 2015 TRITA-ICT-EX-2015:224 A techno-economic comparison between outdoor macro-cellular and indoor offloading solutions Feidias Moulianitakis 2015-08-31 Master’s Thesis Examiner Academic adviser Prof. Jan Markendahl Ashraf A. Widaa Ahmed School of Information and Communication Technology (ICT) KTH Royal Institute of Technology Stockholm, Sweden Abstract Mobile penetration rates have already exceeded 100% in many countries. Nowadays, mobile phones are part of our daily lives not only for voice or short text messages but for a plethora of multimedia services they provide via their internet connection. Thus, mobile broadband has become the main driver for the evolution of mobile networks and it is estimated that until 2018 the mobile broadband traffic will exceed the level of 15 exabytes. This estimation is a threat to the current mobile networks which have to significantly improve their capacity performance. Furthermore, another important aspect is the fact that 80% of the mobile broadband demand comes from indoor environments which add to the signal propagation the burden of building penetration loss. Keeping these facts in mind, there are many potential solutions that can solve the problem of the increasing indoor mobile broadband demand. In general, there are two approaches; improve the existing macro-cellular networks by for example enhancing them with carrier aggregation or enter the buildings and deploy small cell solutions such as femtocells or WiFi APs. Both the academia and the industry have already shown interest in these two approaches demonstrating the importance of the problem. -

Aptilo Carrier-Class Wi-Fi Solution Datasheet
No one knows carrier Wi-Fi better than we do! Aptilo Carrier-Class Wi-Fi Solution Datasheet Partner Network Roaming OSS / BSS Integration Wi-Fi User Experience Hotel BYOD Home Wi-Fi Flexible APIs ServiceGlue Captive Portal Guest Internet Existing portals B2B Adaptors Policy OCS / Prepaid Prepaid / & OFCS / Billing Charging Charging PCRF Smart Advanced Wi-Fi Sub Office Wi-Fi CRM Lookups Configurable Database Other databases Logic Quota Mgmt EAP TLS Wi-Fi Policy DNS EAP TTLS EAP-SIM/AKA Public Wi-Fi HLR / HSS 3GPP AAA Wi-Fi AAA DHCP Diameter SS7 Trusted / Diameter RADIUS Untrusted RADIUS Local SOAP Access Gateway Adaptors (VSA) Break-out Mobile Core Integration Wi-Fi Service Control Small Cell Wi-Fi Wi-Fi Backhaul to mobile core through tunnels Gateway EAP-SIM/AKA non-SIM Carrier-Class Wi-Fi. Your challenge, our speciality The Aptilo Service Management Platform™ (SMP) With more than 90 service provider Wi-Fi customers in 60 coun- Aptilo offers a fast-track for launching Wi-Fi services with our tries under our belt, we understand that building a carrier-class optional pre-integrated functions for subscriber management, Wi-Fi service is a challenging task with a lot of considerations, prepaid & charging, web portals, access control as well as statis- • How to integrate with my existing OSS/BSS? tics and reporting; all optimized to work together on a single scal- • How to efficiently roll-out new sites? able system – the Aptilo Service Management Platform™ (SMP). • How to make Wi-Fi attractive to venue owners? What this means for you as a service provider is faster time-to- • Which business models should I use? market and happy subscribers with the best user experience avail- • Which Wi-Fi radio vendor should I select? able today. -
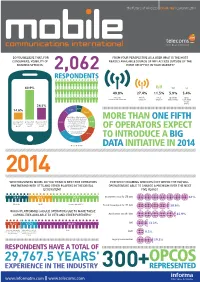
Telecoms.Com Intelligence Global Industry Survey
the future of wireless ISSUE 182 FEBRUARY 2014 DO YOU BELIEVE THAT, FOR FROM YOUR PERSPECTIVE AS A USER WHAT IS THE MOST CONSUMERS, VISIBILITY OF READILY AVAILABLE SOURCE OF WIFI ACCESS OUTSIDE OF THE ROAMING SPEND IS: HOME OR OFFICE IN YOUR MARKET? RESPONDENTS 60.9% 49.8% 27.4% 11.5% 5.9% 5.4% Amenity Mobile Fixed Specialist Open (café, shop, mall, stadium etc) operator operator wifi provider residential access points 24.5% 5.5% 14.6% 11.2% 12.2% How likely is it that operators in your market will use shared MORE THAN ONE FIFTH spectrum (licensed shared Less important As important More important 21.6% 10.8% access/authorised shared than amount as amount than amount access/white space, etc) spent? spent? spent? for some of their capacity in the next five years? OF OPERATORS EXPECT (1 – 7, where 1 is highly unlikely and 7 is highly likely) 16.9% 21.9% TO INTRODUCE A BIG 123456 7 DATA INITIATIVE IN 2014 TELECOMS.COM INTELLIGENCE 2014 GLOBAL INDUSTRY SURVEY WHICH BUSINESS MODEL DO YOU THINK IS BEST FOR OPERATORS FOR WHICH ROAMING SERVICES (NOT WITHIN THE EU) WILL PARTNERING WITH OTTS AND OTHER PLAYERS IN THE DIGITAL OPERATORS BE ABLE TO CHARGE A PREMIUM OVER THE NEXT ECOSYSTEM? FIVE YEARS? 24.6% 25.6% 50.1% Guaranteed QoS for LTE data 61% Wholesale Retail Revenue share with OTT Tiered throughput for LTE data 38.6% WHICH PLATFORM(S) SHOULD OPERATORS USE TO MAKE THESE CAPABILITIES AVAILABLE TO OTTS AND OTHER PARTNERS? Application-specific data 45.9% 16.2% 17.7% 66.1% SMS 13.3% Only through industry-wide Only through their own B2B Both initiatives such as the GSMA's collaboration platform, enabling MMS OneAPI Exchange? partners to create mash-up 9.3% services? Legacy voice services 19.3% RESPONDENTS HAVE A TOTAL OF EXPERIENCE IN THE INDUSTRY OFC_MCI182.indd 1 10/02/2014 08:18 FRONT Editorial 02 CONTENTS FEBRUARY14 Analysis 04 Heavyweight Vodafone Carrier Services makes a big investment in IPX capabilities and threatens the The leading provider existence of smaller IPX providers. -

Sweden-Nigeria Business Forum
SWEDEN-NIGERIA BUSINESS FORUM STOCKHOLM, SWEDEN 18-19 MAY 2020 Partnerships between Sweden and Nigeria on ICT, Energy and Transport towards building a Smarter and Innovation Driven Cities www.eqtpartners.com ABOUT DELEGATION HIGH-LEVEL NIGERIAN BUSINESS DELEGATION TO SWEDEN LED BY MINISTER FOR TRADE & INVESTMENT, NIGERIA, H.E. OTUNBA ADENIYI ADEBAYO, STOCKHOLM, SWEDEN, MAY 18TH -19TH 2020 Sweden is a global leader in innovation and ranked first in Europe according to the European innovation scoreboard. Sweden spends more on Research & Development than any European nation (3% of GDP) and excels in promoting training and transfer of knowledge with partner countries and businesses. Over the years, this has given Swedish enterprises a unique head-start on the global scene with innovations like Bluetooth, Spotify, Skype and global companies like Ericsson, Scania, Volvo and ABB. Sweden´s capital Stockholm is currently producing the highest number of so-called ‘unicorns’ (or billion-dollar tech companies) per capita after Silicon Valley. Sweden is also ranked as the world´s most digitized economy. Investments and advancement in ICT have played a crucial role in diversifying the economy, creating new companies and jobs and developed smart new solutions in various sectors, including energy and transport. Nigeria is the biggest country and economy in Africa, with a population of approximately 200 million, accounting for 47% of West Africa’s population and over 65% of West Africa’s GDP. With abundant natural resources and a young, dynamic population, the country has long played an important role on the continent and it has the potential to be a wider global player in the coming decades. -
Design Issues in All-IP Mobile Networks
ESPOO 2007 VTT RESEARCH NOTES 2376 VTT Tiedotteita – Research Notes 2376 Design Issues in All-IP Mobile Networks NOTES RESEARCH VTT 2368 Technology roadmap of security research. Rouhiainen, Veikko (ed.). 2007. 33 p. 2369 Googlen mainokset ja muita sosiaalisen median liiketoimintamalleja. Kangas, Petteri, Toivonen, Santtu & Bäck, Asta (toim.). 2007. 59 s. 2370 Huhta, Hanna-Kaisa, Rytkönen, Jorma & Sassi, Jukka. Estimated nutrient load from waste waters originating from ships in the Baltic Sea area. 2007. 58 p. + app. 13 p. 2371 TBT-BAT MANUAL – Organotinapitoisten sedimenttien ruoppaus ja käsittely. Design Issues in All-IP Menettelytapaohje. Vahanne, Pasi & Vestola, Elina (toim.). 2007. 76 s. + liitt. 3 s. 2372 Nylund, Nils-Olof, Erkkilä, Kimmo & Hartikka, Tuukka. Kaupunkibussien polttoaineen kulutus ja pakokaasupäästöt. Uusimman dieseltekniikan suorituskyky. Mobile Networks 2007. 47 s. + liitt. 1 s. 2373 Nylund, Nils-Olof, Erkkilä, Kimmo & Hartikka, Tuukka. Fuel consumption and exhaust emissions of urban buses. Performance of the new diesel technology. 2007. 48 p. + app. 1 p. 2374 Wessberg, Nina. Ympäristöturvallisuus. Ympäristöriskien arvioinnin osaaminen ja haasteet. 2007. 38 s. + liitt. 8 s. 2375 Oksman, Virpi, Noppari, Elina, Tammela, Antti, Mäkinen, Maarit & Ollikainen, Ville. News in mobiles. Comparing text, audio and video. 2007. 37 p. 2376 Design Issues in All-IP Mobile Networks. Raatikainen, Pertti (ed.). 2007. 136 p. 2377 Holopainen, Riikka, Hekkanen, Martti, Hemmilä, Kari & Norvasuo, Markku. Suomalaisten rakennusten energiakorjausmenetelmät ja säästöpotentiaalit. 2007. 104 s. + liitt. 2 s. 2378 Tallgren, Markus, Pihlajamaa, Olli & Törönen, Juha. Ubiquitous Customer Loyalty Services. Technology and Market Outlook. 2007. 77 p. + app. 52 p. 2379 Paiho, Satu, Ahlqvist, Toni, Lehtinen, Erkki, Laarni, Jari, Sipilä, Kari, Ala-Siuru, Pekka & Parkkila, Tommi. -

FIERCE INNOVATION AWARDS 2015 from the PUBLISHER of Fiercewireless, Fiercetelecom, & Fiercecable Telecom Edition
FIERCE INNOVATION AWARDS 2015 FROM THE PUBLISHER OF FierceWireless, FierceTelecom, & FierceCable Telecom Edition INNOVATION REPORT FIERCE INNOVATION AWARDS 2015 Telecom Edition 2 TABLE OF CONTENTS Introduction: The ‘Network’: Are You Behind It or Ahead of It? .................................3 Recognition of Best In Show Winners ...............................................................................4 Recognition of Category Winners ......................................................................................5 Recognition of Finalists ........................................................................................................11 Recognition of Judges ..........................................................................................................12 STATE OF THE INDUSTRY ARTICLES: Business Networks Are Cloudy, Insecure and Mobile .................................................15 The Slow Road to 4K TV ......................................................................................................18 Wi-Fi: Getting From Free To Wheeeeeeeee! ..................................................................21 Is The Need For 5G Valid? ..................................................................................................24 Harnessing the Fast-Growing IoT Opportunity ...............................................................27 Directory Listings ...................................................................................................................31 FIERCE INNOVATION AWARDS -

5G a “Special Generation” – but in Good Time
MWC15 Daily DAY4.qxp_DAY1 04/03/2015 18:07 Page 1 BROUGHT TO YOU BY: OFFICIAL NEWSPAPER OF MOBILE WORLD CONGRESS 2015 IN THIS ISSUE WI-FI ALLIANCE OUTLINES RISKS WITH LTE-U INDUSTRY BODY STRESSES NEED TO COOPERATE WITH MOBILE CAMP PAGE 4 ORANGE PUTS MEA PIECES INTO PLACE OPERATOR SAYS MOVE WILL MAKE IT EASIER TO ENTER INTO MERGERS IN THE REGION PAGE 6 XIAOMI: SUCCESS IS DOWN TO BRAND CHINESE FIRM SAYS ITS FRESH APPROACH IS PAYING OFF PAGE 6 D AY F O U R • THURSDAY 5TH MARCH 5G a “special generation” – but in good time By Paul Rasmussen and Joseph Waring unveil a new performance leap, the LTE engineers respond by he mobile industry should matching it.” consider 5G as a “special Underlining the need for a new Galaxy S6 Edge Tgeneration”, introducing generation, Mischa Dohler, “challenges in all layers of the professor of wireless scoops Best In technology”, Mike Short, VP of communications at King’s College public affairs Telefónica Europe London, insisted: “We really do Show Award (pictured right), said. need 5G in order to have a Speaking in one of yesterday’s paradigm shift. The order of services. We must look at “And we’re going to fit all that on amsung’s Galaxy S6 Edge - sessions covering the next- magnitude jump in traffic is what is performance and coverage, and not one network. The risk with 5G is unveiled Sunday on the eve generation mobile technology, he really driving this move.” just consider microcells.” we’re stretching it too wide to be Sof MWC15 - has been said: “It’s beyond what we’re doing He said the industry is nearing Ericsson group CTO Ulf able to build it. -

Proyecto Fin De Grado
ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA Y SISTEMAS DE TELECOMUNICACIÓN PROYECTO FIN DE GRADO TÍTULO: IP FLOW MOBILITY STRATEGY IN MOBILE DATA TRAFFIC OFFLOADING AUTOR: Jose Guillermo Aparicio Pulido TITULACIÓN : Grado en Ingeniería de Sistemas de Telecomunicación TUTOR: Dr. Piotr Korbel UNIVERSIDAD: Technical University of Lodz CENTRO: International Faculty of Engineering PAÍS: Polonia Fecha de lectura: 6 de Junio de 2016 Calificación: El Coordinador de Movilidad, Lodz University of Technology Institute of Electronics IP Flow Mobility Strategy for Mobile Data Traffic Offloading Final Project Author: Jose Guillermo Aparicio Pulido Tutor: Dr. Piotr Korbel Date: 26/06/2014 2 Index 1. Introduction 2. Mobile Data Offloading 2.1. WLAN Offloading 3.1 WLAN Offloading Techniques 3.1.1 Leak breakout 2.2 Mobile Data Offloading 2.2.1 ANDSF 3. Offloading Strategies 3.1 Modeling Network Traffic in Mobile Network 3.1.1 Preliminaries 3.1.2 Traffic Model for offloading 3.1.3 Applicability of the model 3.1.4 Results 3.1.5 Performance bounds in offloading scenarios 3.2 Local IP Access (LIPA) 3.2.1 LIPA Architecture 3.3 Selected IP Traffic Offloading (SIPTO) 3.3.1 Scenario 1 – Multiple PDN connections 3.3.2 Scenario 2 – Session continuity 3.4 Adoption of Mobility Solutions 3.4.1 PMIPv6 3.4.2 GTP 4. IP Flow Mobility 4.1 IP Flow Mobility trigger mechanism 4.2 IP Flow Mobility algorithm 4.2.1 Model description 4.2.2 Algorithm description 4.3 Implementation 4.3.1 First scenario 4.3.1.1 Video Streaming 4.3.1.2 VoIP 4.3.1.3 FTP 4.3.1.4 Selection of optimal Access -

Strategies for Effective Wi-Fi Offload
BONUS SUPPLIER Strategies for GUIDE 16 WIRELESS INFRASTRUCTURE COMPANIES effective Wi-Fi SERVICE, TRAINING, STAFFING, HARDWARE, COMPONENT AND offload ACCESSORY COMPANIES By Martha DeGrasse JUNE 2015 Report Sponsors: Featured Analyst: FEATURE REPORT Introduction Now those carriers are investigating cutthroat pricing environment, keeping As much as half of all mobile data is carrier-driven Wi-Fi offload by offering customers connected and happy is offloaded from cellular networks to Wi-Fi, subscribers more opportunities to use paramount. If the cellular network offers a and that amount is growing each day. By Wi-Fi when they are on the go. Carrier- subpar connection in a given area, moving next year, mobile operators will see more driven Wi-Fi offload can increase customer a customer to reliable Wi-Fi can keep the traffic offloaded to Wi-Fi than remains on satisfaction, network capacity and even network’s problem from becoming the cellular networks, according to Cisco’s most revenue. In order to achieve these goals, customer’s problem. Even in places where recent Visual Networking Index. carrier-driven Wi-Fi offload needs to coverage and capacity are sufficient for The vast majority of Wi-Fi offload is user leverage network intelligence to ensure most use cases, heavy user traffic can driven. Mobile subscribers purposely move efficient and effective offload. overload the network. Moving some users their devices to Wi-Fi networks when they to Wi-Fi can keep all users happy. are within range, or set their phones to con- Don’t, don’t you want me? “We’ll do everything we can to solve your nect automatically to home or office Wi-Fi Moving a customer off the network problems, and today, that’s about uniting access points. -

User Friendly Access Solutions for Mobile Wimax
User Friendly Access Solutions for Mobile WiMAX Brage Rønning Tukkensæter Master of Science in Communication Technology Submission date: June 2009 Supervisor: Yuming Jiang, ITEM Co-supervisor: Thomas Jelle, Trådløse Trondheim Lene Maria Myhre, Trådløse Trondheim Norwegian University of Science and Technology Department of Telematics Problem Description The objective of this project is to investigate possible user friendly access solutions for Mobile WiMAX. The study includes both a theoretical and a practical part. The theoretical part should investigate the IEEE 802.16e and WiMAX Forum standards for user access. Security should be discussed, and a brief comparison with Wi-Fi and GSM/UMTS access solutions should be given. The practical part should design and implement a proof-of concept access solution for Mobile WiMAX, including organizational RADIUS authentication and paying users. The access solution should give users secure and user friendly access to the Mobile WiMAX network. Assignment given: 21. January 2009 Supervisor: Yuming Jiang, ITEM Abstract Today, WiMAX networks are deployed several places worldwide. To get access to these networks, users have to buy equipment specialized for one operator with a subscription. User equipment has earlier been stationary or mounted, but with the Mobile WiMAX amendment, smaller receivers are made possible. Mobile WiMAX allows users to move between different operators, making user access and roaming a more challenging task. In this thesis, several Mobile WiMAX access solutions are discussed, emphasizing security and user friendliness. A captive portal solution is developed, and an EAP-TTLS (Extensible Authentication Protocol - Tunneled Transport Layer Security) solution utilizing FreeRADIUS is planned. Security in WiMAX is compared to Wi-Fi very good. -

Feature Brief
Aptilo Access Controller Data sheet In the sample Service Profile “Premium” to the right, the main At a Glance service is capped to 8 Mbit/s of total The Aptilo Access Controller™ (AC) gateway is bandwidth allowance for the purpose-built for access control, usage monitoring “premium” user. Listed below the and policy enforcement in Wi-Fi networks. It runs main service are services that can be on standard hardware and features true client plug- and-play functionality. The AC dynamically handles capped or defined as unlimited, these user sessions, QoS and routing from the local are prioritized within the main service. network to the Internet. Optionally an additional service can be Depending on the business model and integration defined outside the main service and level, the Access Controller can either be locally, prioritized on the same level. regionally or centrally placed in the network, catering to several separate sites. This ensures that there is additional capacity left for e.g. real-time critical applications even if the bandwidth of the main service is The AC software can assume 3 different roles; Load Balancer (front-end), Traffic node (back-end) and consumed. Specific firewall and route policies can be set for each Backup node. Service Profile. The automatic bandwidth balancer feature of the Aptilo AC distributes available bandwidth between all active sessions TM The Aptilo Access Controller (AC) forms according to the priorities set in the service profiles. A service can be part of a state-of-the-art platform from automatically throttled down to a certain capacity if the pre-paid Aptilo Networks that facilitates the creation quota has been depleted to a specified level.