Designing Future Search Interfaces for the Web Full Text Available At
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Google Toolbar for Enterprise Admin Guide
Google Toolbar for Enterprise Admin Guide ● Introduction ● Technical Overview ● Downloading the Software ● Configuring the Group Policies ❍ Preferences ❍ Enterprise Integration ❍ Custom Buttons ❍ Popup Whitelist ● Defining Custom Buttons ● Pushing Out the Policy to User Registries ● Installing Google Toolbar on User Machines Introduction back to top This document contains information about setting up Google Toolbar for Enterprise. Google Toolbar is an end-user application that adds a search bar and other useful web tools to the Internet Explorer browser window. Google Toolbar for Enterprise makes it easy to provide enterprise users with the Google Toolbar and to create standards for its use. The document was written for Windows domain administrators. As an administrator, you can install and configure Google Toolbar for all users. By defining enterprise-wide policies for Google Toolbar, you can decide which buttons and features users can access. For example, you could remove the feature that saves search history, whitelist certain pages to exempt them from the popup blocker, or prevent users from sending votes to Google about their favorite web pages . You can configure policies before installing Google Toolbar for the users, or at any subsequent time. Google Toolbar also provides the ability to create custom buttons that display specified pages, direct searches to predefined systems, or display information from an RSS feed. Using Google Toolbar for Enterprise, you can define buttons for all users, using data from your own network or from the Internet. For example, you could create a custom button that directs a user's search to your Google Search Appliance or Google Mini to display a corporate web page or show important phone numbers from your intranet. -

Computers for Beginners 3 Use the Web Handout
Computers for Beginners 3: Use the Web JAN 2020 CF Learning Objectives: In this class you will: 1. Understand web site addresses 2. Practice using web site addresses to visit web sites 3. Learn about different areas of a web site 4. Practice using a web site home page to explore the site 5. Learn how search engines work and when to use them 6. Conduct a simple search with the search engine Google 2 Review Quiz Let’s take a short quiz to remind ourselves of what we’ve already learned. 1. What can you use to move up and down on a web page? a. The Tab key. b. The Scroll Wheel on your mouse. c. The Arrow Keys on your keyboard. d. B and C, but not A. 2. What does it mean when your cursor looks like a pointing hand? a. You can click on a link. b. You should stretch your hands. c. You can start typing on the page. 3. What should you do if your mouse gets close to the edge of your desk, and your cursor still isn’t in the right place? a. Panic. b. “Hop” your mouse away from the edge by lifting it up and setting it back down close to your keyboard. c. Slide your mouse back to where you started and try again. 3 Quiz Answers: 1d. You can move up and down a web page using either the scroll wheel on your mouse, or the arrow keys on your keyboard. You can also use your mouse to drag the Scroll Bar on the right side of your screen up and down. -

Public Access Search Instructions
PUBLIC SEARCH SITE How to perform a search Address Search Use this search option to locate properties using a street number, name or direction. Address example with partial street name: 1. For best results leave off the street suffix. 2. Use the * as a wild card to match any string of characters (when unsure of spelling or to return all results on a particular street). A wild card is assumed at the end on any string of characters. Type Results Woodland All addresses on a street with the name Woodland in it: # Woodland Dr # Woodland Hills Way Ba* All addresses on a street beginning # Bay Ct # Babbitz Ave # Baldwin *wood All addresses on a street ending with # Birchwood # Southwood # Underwood PUBLIC SEARCH SITE How to perform a search Owner Search Use this search option to locate properties with a known Ownership example with partial name: owner name. 1. Type in the full name or part of the full name into the search box (LastName FirstName without commas). 2. Use the * as a wild card to match any string of characters. A wild card is assumed at the end on any string of characters. Type Results Smith John Smith John B*ow Brown, Barlow, Below, etc. B*o*ski Bojarski, Bronowski, Bukowski, etc. Grant Grant, Grantham, Grants, etc. PUBLIC SEARCH SITE How to perform a search Parcel Number Search identification number. Parcel ID example: 1. Type the parcel id into the search box. Enter all or part of the number. 2. Use the * as a wild card to find a group of parcels. -

Navigate Windows and Folders
Windows® 7 Step by Step by Joan Preppernau and Joyce Cox To learn more about this book, visit Microsoft Learning at http://www.microsoft.com/MSPress/books/ 9780735626676 ©2009 Joan Preppernau and Joyce Cox Early Content—Subject to Change Windows 7 Step by Step Advance Content–Subject to Change Windows 7 Step by Step Draft Table of Contents Overview Front Matter ............................................................................................................................................. 3 Contents ................................................................................................................................................ 3 About the Authors ................................................................................................................................ 3 Features and Conventions of This Book ................................................................................................ 3 Using the Companion CD ...................................................................................................................... 3 Getting Help .......................................................................................................................................... 3 Introducing Windows 7 ......................................................................................................................... 3 Part I: Getting Started with Windows 7 .................................................................................................... 4 1 Explore Windows 7 ........................................................................................................................... -
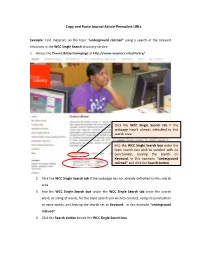
Copy and Paste Journal Article Permalink Urls
Copy and Paste Journal Article Permalink URLs Example: Find materials on the topic “underground railroad” using a search of the relevant resources in the WCC Single Search discovery service: 1. Access the Erwin Library homepage at http://www.waynecc.edu/library/ Click the WCC Single Search tab if the webpage hasn’t already defaulted to this search area Into the WCC Single Search box enter the topic search you wish to conduct with no punctuation, leaving the search on Keyword: in this example, “underground railroad” and click the Search button 2. Click the WCC Single Search tab if the webpage has not already defaulted to this search area 3. Into the WCC Single Search box under the WCC Single Search tab enter the search word, or string of words, for the topic search you wish to conduct, using no punctuation or extra words, and leaving the search set to Keyword: in this example “underground railroad” 4. Click the Search button beside the WCC Single Search box Copy and Paste Journal Article Permalink URLs Enter all the numbers on an Erwin Library patron barcode sticker with no spaces 5. After clicking on the WCC Single Search button, if you are using the Erwin Library databases outside of the Erwin Library, login using all fourteen digits on your Erwin Library barcode sticker and click the Login button In the Limit To option list click inside the Full Text checkbox to eliminate all abstract‐only entries from your Results list, and then click inside the Scholarly/Peer Reviewed checkbox if required for your research Rev. -

Spot-Tracking Lens: a Zoomable User Interface for Animated Bubble Charts
Spot-Tracking Lens: A Zoomable User Interface for Animated Bubble Charts Yueqi Hu, Tom Polk, Jing Yang ∗ Ye Zhao y Shixia Liu z University of North Carolina at Charlotte Kent State University Tshinghua University Figure 1: A screenshot of the spot-tracking lens. The lens is following Belarus in the year 1995. Egypt, Syria, and Tunisia are automatically labeled since they move faster than Belarus. Ukraine and Russia are tracked. They are visible even when they go out of the spotlight. The color coding of countries is the same as in Gapminder[1], in which countries from the same geographic region share the same color. The world map on the top right corner provides a legend of the colors. ABSTRACT thus see more details. Zooming brings many benefits to visualiza- Zoomable user interfaces are widely used in static visualizations tion: it allows users to examine the context of an interesting object and have many benefits. However, they are not well supported in by zooming in the area where the object resides; labels overcrowded animated visualizations due to problems such as change blindness in the original view can be displayed without overlaps after zoom- and information overload. We propose the spot-tracking lens, a new ing in; it allows users to focus on a local area and thus reduce their zoomable user interface for animated bubble charts, to tackle these cognitive load. problems. It couples zooming with automatic panning and provides In spite of these benefits, zooming is not as well supported in an- a rich set of auxiliary techniques to enhance its effectiveness. -

Quick Start for New Users
Act! Quick Start for New Users Act! helps organize all your prospect and customer details in one place so you can prioritize your day and market your products and services more effectively. This Quick Start for New Users Guide explains some of the basics of getting started with Act!. If you are viewing the Quick Start guide online, click the link to go to the page. Get to Know the Workspace 1 All About Databases 2 Import Contacts 3 Add Contacts to the Database 4 Set Preferences for Email 5 Track Your Schedule and Manage Appointments 6 Communicate with Your Contacts 7 Organize Your Contacts into Groups 8 Keep More Details about Your Contacts 9 Search for Contacts 10 Share Information with Others 11 TIP: The Quick Reference Card also provides shortcuts and quick tips. Go to Help>Online Manuals. Get to Know the Workspace Most of the tasks that you want to do in Act! require you to: l Open a View. l Click commands on the Menu bar. l Click buttons (tools) on the Global toolbar. l Click items on the Navigation bar (Navbar). l Click tools on a view toolbar. The following section describes these items. View. Appears in the main window of the application. The views are: Act! Insight, Act! Connect, Contacts, Groups, Companies, Calendar, Task List, History List, Opportunities, Emarketing, Reports, Dashboard, Search, and Welcome Page. The Contacts, Groups, Companies, and Opportunities views have a Detail view and List view that you can toggle between. Menu bar. Located at the top of all views. It contains the default menus and commands for the current view. -

Zoomtext Quick Reference Guide Version 10
ZoomText Quick Reference Guide version 10 Contents Welcome to ZoomText 10 ................ 3 Cursor Enhancements ............................24 System Requirements ............................... 4 Focus Enhancements ..............................25 Installing ZoomText ................................. 5 Font Enhancements .................................26 Activating ZoomText ............................... 6 Desktop Finder ........................................27 Starting ZoomText .................................... 8 Web Finder ...............................................28 ZoomText User Interface ......................... 9 Text Finder ...............................................31 Enabling and Disabling ZoomText ...... 11 Smooth Panning ......................................33 Magnifier Toolbar .......................... 12 Reader Toolbar .............................. 35 Setting the Magnification level ............. 13 Turning Speech On and Off ...................36 Selecting a Zoom Window .................... 14 Adjusting the Speech Rate .....................37 Adjusting a Zoom Window ................... 16 Synthesizer Settings ................................38 Using the Freeze Window ..................... 17 Typing Echo .............................................39 Using View Mode ................................... 18 Mouse Echo ..............................................40 Dual Monitor Support ............................ 19 Verbosity...................................................41 Color Enhancements ............................. -

CRGIS Tutorial 2, Map Tools
CRGIS Map Tools This tutorial will teach you about the tools available in CRGIS. In addition to basic map navigation, these tools include the Spatial Search, Measure, Feedback and more. Table of Contents Getting Started ............................................................................................................................................... 2 Understanding the Map ................................................................................................................................ 2 Tools ................................................................................................................................................................ 3 Map Window Tools ................................................................................................................................... 3 Legend Tools .............................................................................................................................................. 5 Search Box Tools ..................................................................................................................................... 10 Spatial Search ................................................................................................................................................ 14 New Tools for Registered Users ............................................................................................................... 17 CRGIS Tutorial #2 Page | 1 10/2017 CRGIS Map Tools Getting Started To access the CRGIS map tools, log -

Installation Instructions: SEARCH Investigative Toolbar
Installation Instructions: SEARCH Investigative Toolbar February 2014 The SEARCH Investigative Toolbar is an aid for investigators who conduct online, cellular telephone, and wireless investigations. Once installed, it becomes a readily available desktop resource that contains frequently used and up-to-date online investigative links. IMPORTANT NOTICE: The Toolbar is hosted by a third party, but offered through the SEARCH website. There are two issues that users should be aware of before installing the Toolbar: 1. The host has included revenue-generating applications that are triggered within the Toolbar installation process. These apps allow advertisements to appear on your device. SEARCH has no control over the inclusion of these apps, but we can show you how to avoid installing them so that you will not see the ads. 2. Certain elements within this installation process can trigger antivirus software alerts. Depending on the antivirus software, the software might view these applications as a nuisance. With the proper installation, the Toolbar will not cause any antivirus alerts. Users are encouraged to follow this installation guide carefully to avoid getting these alerts. This installation process is accurate for all browsers, including Firefox, Internet Explorer, Chrome, and Safari. 1 | P a g e Download the SEARCH Investigative Toolbar from www.searchinvestigative.ourtoolbar.com (Figure 1). Select the Free Download button to start the download process. NOTE: Disregard the Firefox installation Instructions displayed on the screen; they are controlled by the host and are not an accurate representation of the download process. Follow the instructions on the coming pages to ensure a successful installation. Figure 1 The SEARCH Investigative Toolbar is an executable (.exe) file. -

Using Search Engines
Using search engines Search engines let you easily find all manner of information. Benefits of using search engines Search engines help you find what you’re looking for on the internet. • There are many search engines, including those from Google, Yahoo and Bing. • To start a search, type what you want to know more about into the Search box and click on Google, Yahoo and Bing the magnifying glass. • If you want to search for a phrase, put it in “quotation marks” (use the marks with two strokes). Otherwise the search will be for the individual words. • The results of your search will be presented as a list. There might be some advertisements, or sponsored links at the top of the list, before the real search results appear. • If you make a spelling mistake, the search engine will still try to find what you’re after. Using website addresses and bookmarks If you already know the web address you want to visit, you won’t need a search engine. 1. Type the website address into the Address bar of a web browser. This is near the top of the browser window. Click in the Address bar to start. 2. You can skip the http:// at the start. The browser will add that for you. Make it easy to return to a site by using Bookmarks or Favourites. • Bookmarks and Favourites are names used by different web browsers for the same function. beconnected.esafety.gov.au Using search engines • Bookmarks and Favourites are shortcuts to a website. • On a Windows computer, you save a Bookmark by clicking the star on the browser Address bar, and confirming the name and location. -

In Search of Stupidity: Over 20 Years of High-Tech Marketing Disasters
CYAN YELLOW MAGENTA BLACK PANTONE 123 CV Chapman “A funny AND grim read that explains why so many of the high-tech sales departments I’ve trained and written about over the years frequently have Merrill R.Chapman homicidal impulses towards their marketing groups. A must read.” Foreword by Eric Sink —Mike Bosworth Author of Solution Selling, Creating Buyers in Difficult Selling Markets and coauthor of Customer Centric Selling In Search of Stupidity In Search OVER 20 YEARS OF HIGH-TECH MARKETING DISASTERS 20 YEARS OF HIGH-TECH OVER n 1982 Tom Peters and Robert Waterman Ikicked off the modern business book era with In Search of Excellence: Lessons from America’s Best-Run Companies. Unfortunately, as time went by it became painfully obvious that many of the companies Peters and Waterman had profiled, particularly the high-tech ones, were something less than excellent. Firms such as Atari, DEC, IBM, Lanier, Wang, Xerox and others either crashed and burned or underwent painful and wrenching traumas you would have expected excellent companies to avoid. What went wrong? Merrill R. (Rick) Chapman believes he has the answer (and the proof is in these pages). He’s observed that high-tech companies periodically meltdown because they fail to learn from the lessons of the past and thus continue to make the same completely avoidable mistakes again and again and again. To help teach you this, In Search of Stupidity takes you on a fascinating journey from yesterday to today as it salvages some of high-tech’s most famous car wrecks. You will be there as MicroPro, once the industry’s largest desktop software company, destroys itself by committing a fundamental positioning mistake.