PDF Hosted at the Radboud Repository of the Radboud University Nijmegen
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
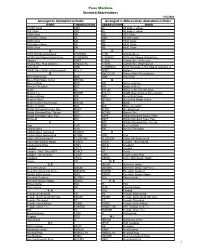
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W
Knowl. Org. 46(2019)No.3 209 W. Korwin and H. Lund. Alphabetization Alphabetization† †† Wendy Korwin*, Haakon Lund** *119 W. Dunedin Rd., Columbus, OH 43214, USA, <[email protected]> **University of Copenhagen, Department of Information Studies, DK-2300 Copenhagen S Denmark, <[email protected]> Wendy Korwin received her PhD in American studies from the College of William and Mary in 2017 with a dissertation entitled Material Literacy: Alphabets, Bodies, and Consumer Culture. She has worked as both a librarian and an archivist, and is currently based in Columbus, Ohio, United States. Haakon Lund is Associate Professor at the University of Copenhagen, Department of Information Studies in Denmark. He is educated as a librarian (MLSc) from the Royal School of Library and Information Science, and his research includes research data management, system usability and users, and gaze interaction. He has pre- sented his research at international conferences and published several journal articles. Korwin, Wendy and Haakon Lund. 2019. “Alphabetization.” Knowledge Organization 46(3): 209-222. 62 references. DOI:10.5771/0943-7444-2019-3-209. Abstract: The article provides definitions of alphabetization and related concepts and traces its historical devel- opment and challenges, covering analog as well as digital media. It introduces basic principles as well as standards, norms, and guidelines. The function of alphabetization is considered and related to alternatives such as system- atic arrangement or classification. Received: 18 February 2019; Revised: 15 March 2019; Accepted: 21 March 2019 Keywords: order, orders, lettering, alphabetization, arrangement † Derived from the article of similar title in the ISKO Encyclopedia of Knowledge Organization Version 1.0; published 2019-01-10. -

Conversion Table a = 1 B = 2 C = 3 D = 4 E = 5 F = 6 G = 7 H = 8 I = 9 J = 10 K =11 L = 12 M = 13 N =14 O =15 P = 16 Q =17 R
Classroom Activity 2 Math 113 The Dating Game Introduction: Disclaimer: Although this is called the “Dating Game”, it is merely intended to help the student gain understanding of the concept of Standard Deviation. It is not intended to help students find dates. The day after Thanksgiving, 1996, I was driving my sister, Conversion Table brother-in-law, and sister-in-law over to meet my brother in A=1 K=11 U=21 Springfield at the Mission where he and his wife helped out. B=2 L=12 V=22 During this drive, I ask my sister, “How do you know which C=3 M=13 W=23 woman is the right one for you?”. Now, my sister was born D=4 N=14 X=24 a Jones, and like the rest of the family, she can make E=5 O=15 Y=25 anything sound believable. Without missing a beat, she F=6 P=16 Z=26 said, “You take the letters in her name, convert them to G=7 Q=17 numbers, find the standard deviation, and whoever’s H=8 R=18 standard deviation is closest to yours is the woman for you.” I=9S=19 I was so proud of my sister, that was a really good answer. J=10 T=20 Then, she followed it up with “Actually, if you can find a woman who knows what a standard deviation is, that’s the woman for you.” The first part was easy, take each letter in your name and convert it to a number. Use the system where an A=1, B=2, .. -

Master's Project at ICT, KTH Examensarbete Vid ICT, KTH
Master's Project at ICT, KTH Examensarbete vid ICT, KTH Automated source-to-source translation from Java to C++ Automatisk källkodsöversättning från Java till C++ JACEK SIEKA [email protected] Master's Thesis in Software Engineering Examensarbete inom programvaruteknik Supervisor and examiner: Thomas Sjöland Handledare och examinator: Thomas Sjöland Abstract Reuse of Java libraries and interoperability with platform native components has traditionally been limited to the application programming interface offered by the reference implementation of Java, the Java Native Interface. In this thesis the feasibility of another approach, automated source-to-source translation from Java to C++, is examined starting with a survey of the current research. Using the Java Language Specification as guide, translations for the constructs of the Java language are proposed, focusing on and taking advantage of the syntactic and semantic similarities between the two languages. Based on these translations, a tool for automatically translating Java source code to C++ has been developed and is presented in the text. Experimentation shows that a simple application and the core Java libraries it depends on can automatically be translated, producing equal output when built and run. The resulting source code is readable and maintainable, and therefore suitable as a starting point for further development in C++. With the fully automated process described, source-to-source translation becomes a viable alternative when facing a need for functionality already implemented in a Java library or application, saving considerable resources that would otherwise have to be spent rewriting the code manually. Sammanfattning Återanvändning av Java-bibliotek och interoperabilitet med plattformspecifika komponenter har traditionellt varit begränsat till det programmeringsgränssnitt som erbjuds av referensimplementationen av Java, Java Native Interface. -

11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. Review Words Challenge Words
Spelling: Digraphs Name Fold back the paper 1. 1. thirty along the dotted line. 2. 2. width Use the blanks to write each word as it is read 3. 3. northern aloud. When you fi nish 4. 4. fi fth the test, unfold the paper. Use the list at 5. 5. choose the right to correct any 6. 6. touch spelling mistakes. 7. 7. chef 8. 8. chance 9. 9. pitcher 10. 10. kitchen 11. 11. sketched 12. 12. ketchup 13. 13. snatch 14. 14. stretching 15. 15. rush 16. 16. whine 17. 17. whirl 18. 18. bring 19. 19. graph 20. 20. photo Review Words 21. 21. unload Copyright © The McGraw-Hill Companies, Inc. 22. 22. relearn 23. 23. subway Challenge Words 24. 24. expression 25. 25. theater Phonics/Spelling • Grade 4 • Unit 2 • Week 2 37 Spelling: Digraphs Name thirty choose pitcher snatch whirl width touch kitchen stretching bring northern chef sketched rush graph fi fth chance ketchup whine photo A. Underline the spelling word in each row that rhymes with the word in bold type. Write the spelling word on the line. 1. much match touch luck 2. sting bring brag stint 3. fetching resting guessing stretching 4. pants stand lamp chance 5. dirty thirty forty wiry 6. shine mind whine lane 7. news loose stew choose 8. catch clutch snatch snake 9. laugh graph rough roof 10. fl ush crash rush puts Copyright © The McGraw-Hill Companies, Inc. 11. clef chef step leaf 12. etched skipped punched sketched 13. hurl hurt whirl while 14. richer pitcher sister listener B. -

Digraphs Th, Sh, Ch, Ph
At the Beach Digraphs th, sh, ch, ph • Generalization Words can have two consonants together that are pronounced as one sound: southern, shovel, chapter, hyRJlen. Word Sort Sort the list words by digraphs th, sh, ch, and ph. th ch 1. shovel 2. southern 1. 11. 3. northern 4. chapter 2. 12. 5. hyphen 6. chosen 7. establish 3. 13. 8. although 9. challenge 10. approach 4. 14. 11. astonish 12. python 5. 15. 13. shatter 0 14. ethnic 15. shiver sh 16. Ul 16. pharmacy .,; 6. ..~ ~ 17. charity a: !l 17. .c 18. china CJ) a: 19. attach 7. ~.. 20. ostrich i 18. ~.. 8. "'5 .; £ c ph 0 ~ C) 9. 19. ;ii" c: <G~ ,f 0 E 10. 20. CJ) ·c i;: 0 0 ~ + Home Home Activity Your child is learning about four sounds made with two consonants together, called ~ digraphs. Ask your child to tell you what those four sounds are and give one list word for each sound. DVD•62 Digraphs th, sh, ch, ph Name Unit 2Weel1 1Interactive Review Digraphs th, sh, ch, ph shovel hyphen challenge shatter charity southern chosen approach ethnic china northern establish astonish shiver attach chapter although python pharmacy ostrich Alphabetize Write the ten list words below in alphabetical order. ethnic python ostrich charity hyphen although chapter establish northern southern 1. 6. 2. 7. c, 3. 8. 4. 9. 5. 10. Synonyms Write the list word that has the same or nearly the same meaning. 11. surprise 16. drugstore 12. dare 17. break 13. shake 18. fasten "'u £ c 14. 19. dig 0 pottery ·;; " 15. -

MUFI Character Recommendation V. 3.0: Alphabetical Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 1: Alphabetical order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-402-2 ※ Characters on shaded background belong to the Private Use Area. Please read the introduction p. 11 carefully before using any of these characters. MUFI character recommendation ※ Part 1: alphabetical order version 3.0 p. 2 / 165 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). -

Concept Programming in XL the Art of Turning Ideas Into Programs
Concept Programming in XL The Art of Turning Ideas into Programs TM Concept Programming 1 2 Concept Programming Chapter 1— Introduction . 13 1.1. Why another language? . 14 1.2. Who should read this book?. 16 1.3. A quick tour of XL . 16 1.4. Contents Overview. 17 Chapter 2— Simple Examples . 19 2.1. Hello World . 20 2.2. Factorial Function . 21 2.3. Computing a Maximum . 24 2.4. Symbolic Differentiation . 26 Part I — Concept Programming . 31 Chapter 3— Concepts? . 33 3.1. Programming Philosophy. 34 3.2. Translating concepts. 37 3.3. Pseudo-Metrics. 45 3.4. Concept Mismatch . 48 3.5. In Conclusion . 51 Chapter 4— The Trouble with Programming . 53 4.1. Scale Complexity and Moore s Law . 54 4.2. Domain Complexity . 57 4.3. Artificial complexity . 58 4.4. Business Complexity . 64 4.5. The Grim State of Software Quality . 68 Chapter 5— From Concepts to Code . 71 5.1. Turning Ideas into Code. 72 Concept Programming 3 5.2. Abstractions . 77 5.3. Abstractions in Programs . 84 Part II —Core Language . .93 Chapter 6— Compiling XL . 95 6.1. Representing Programs . 96 6.2. Understanding Programs . 98 6.3. Compiling XL . 102 Chapter 7— Syntax . 105 7.1. Source Text. 106 7.2. Tokens . 107 7.3. Parse Tree . 112 7.4. Practical Considerations. 121 7.5. Beyond the Syntax . 126 Chapter 8— Declarations . 127 8.1. Variables. 128 8.2. Subroutines. 134 8.3. Types . 143 8.4. Constants . 143 Chapter 9— Control Flow . 145 9.1. Tests . 145 9.2. -

The Opengl ES Shading Language
The OpenGL ES® Shading Language Language Version: 3.00 Document Revision: 6 29 January 2016 Editor: Robert J. Simpson, Qualcomm OpenGL GLSL editor: John Kessenich, LunarG GLSL version 1.1 Authors: John Kessenich, Dave Baldwin, Randi Rost Copyright © 2008-2016 The Khronos Group Inc. All Rights Reserved. This specification is protected by copyright laws and contains material proprietary to the Khronos Group, Inc. It or any components may not be reproduced, republished, distributed, transmitted, displayed, broadcast, or otherwise exploited in any manner without the express prior written permission of Khronos Group. You may use this specification for implementing the functionality therein, without altering or removing any trademark, copyright or other notice from the specification, but the receipt or possession of this specification does not convey any rights to reproduce, disclose, or distribute its contents, or to manufacture, use, or sell anything that it may describe, in whole or in part. Khronos Group grants express permission to any current Promoter, Contributor or Adopter member of Khronos to copy and redistribute UNMODIFIED versions of this specification in any fashion, provided that NO CHARGE is made for the specification and the latest available update of the specification for any version of the API is used whenever possible. Such distributed specification may be reformatted AS LONG AS the contents of the specification are not changed in any way. The specification may be incorporated into a product that is sold as long as such product includes significant independent work developed by the seller. A link to the current version of this specification on the Khronos Group website should be included whenever possible with specification distributions. -

Iso/Iec Jtc 1/Sc 2/Wg 2 N ___Iso/Iec Jtc 1/Sc 2/Wg 2/Irg N 1180
SC2/WG2 N3063 ISO/IEC JTC 1/SC 2/WG 2 N _____ ISO/IEC JTC 1/SC 2/WG 2/IRG N 1180 ISO/IEC JTC1/SC2/WG2/IRG Ideographic Rapporteur Group (IRG) TITLE: Proposed additions to the CJK Strokes block of the UCS SOURCE: IRG Rapporteur STATUS: Submission from the IRG to WG2 DISTRIBUTION: Members of ISO/IEC JTC1/SC2/WG2 DATE: 2006-4-3 REFERENCE: WG2 N2807R, N2808R, IRG N1174 ATTACHMENTS: IRG N1181 (“Summary for Stroke submission”) Summary This document proposes the addition of twenty new CJK Strokes to the CJK Strokes block of the UCS. WG2 resolution M45.34 (N2754R) expanded the scope of IRG work to include CJK Strokes. The CJK Strokes block (U+31CO..U+31EF) now contains a total of sixteen CJK Strokes (U+31C0..U+31CF), derived from HKSCS (ISO/IEC 10646:2003/Amd.1). The IRG formed ad-hoc groups to complete the repertoire of common CJK Strokes, and finalized the repertoire in the IRG#25 meeting held in Berkeley, California, U.S.A. The twenty new CJK Strokes are proposed for code points in the range (U+31D0..U+31E3). Information on naming conventions and collation is also provided. List of the proposed characters, character names and code positions 31C 31D 31E 31C0 CJK STROKE T 31E0 CJK STROKE HXWG 0 ㇀ ㇐ ㇠ 31C1 CJK STROKE WG 31E1 CJK STROKE HZZZG 31C2 CJK STROKE XG 31E2 CJK STROKE PG 1 ㇁ ㇑ ㇡ 31C3 CJK STROKE BXG 31E3 CJK STROKE Q 31C4 CJK STROKE SW 2 ㇂ ㇒ ㇢ 31C5 CJK STROKE HZZ 31C6 CJK STROKE HZG 31C7 CJK STROKE HP 3 ㇃ ㇓ ㇣ 31C8 CJK STROKE HZWG 31C9 CJK STROKE SZWG 4 ㇄ ㇔ 31CA CJK STROKE HZT 31CB CJK STROKE HZZP 5 ㇅ ㇕ 31CC CJK STROKE HPWG 31CD CJK STROKE -

A Typesetter's Toolkit
A Typesetter's Toolht Pierre A. MacKay Department of Classics DH-10, Department of Near Eastern Languages and Civilization (DH-20) University of Washington, Seattle, WA 98195 U.S.A. Internet: mackayecs .washi ngton .edu Abstract Over the past ten years, a variety of publications in the humanities has required the development of special capabilities, particularly in fonts for non-English text. A number of these are of general interest, since they involve strategies for remapping fonts and for generating composite glyphs from an existing repertory of simple characters. Techniques for selective compilation and remapping of METAFONTs are described here, together with a program for generating Postscript-style Adobe Font Metrics from Computer Modern Fonts. Introduction usually start out in a technology that was out of date in the first place. In the past year we have History. For the past ten years I have served as had to work with one text made up of extensive the technical department of a typesetting effort quotations from Greek inscriptions, composed in which produces scholarly publications for the fields a version of RUNOFF dating from about 1965 and of Classics and Near Eastern Languages, with occa- modified by an unknown hand to produce Greek sional forays into the related social sciences. Right on an unknown printer. The final version of the from the beginning these texts have presented the manuscript was submitted to the editorial board in challenge of special characters, both simplex and 1991. I have no idea when the unique adaptation for composite. We have used several different roman- epigraphical Greek was first written. -

Orthographies in Early Modern Europe
Orthographies in Early Modern Europe Orthographies in Early Modern Europe Edited by Susan Baddeley Anja Voeste De Gruyter Mouton An electronic version of this book is freely available, thanks to the support of libra- ries working with Knowledge Unlatched. KU is a collaborative initiative designed to make high quality books Open Access. More information about the initiative can be found at www.knowledgeunlatched.org An electronic version of this book is freely available, thanks to the support of libra- ries working with Knowledge Unlatched. KU is a collaborative initiative designed to make high quality books Open Access. More information about the initiative can be found at www.knowledgeunlatched.org ISBN 978-3-11-021808-4 e-ISBN (PDF) 978-3-11-021809-1 e-ISBN (EPUB) 978-3-11-021806-2 ISSN 0179-0986 e-ISSN 0179-3256 ThisISBN work 978-3-11-021808-4 is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs 3.0 License, ase-ISBN of February (PDF) 978-3-11-021809-1 23, 2017. For details go to http://creativecommons.org/licenses/by-nc-nd/3.0/. e-ISBN (EPUB) 978-3-11-021806-2 LibraryISSN 0179-0986 of Congress Cataloging-in-Publication Data Ae-ISSN CIP catalog 0179-3256 record for this book has been applied for at the Library of Congress. ISBN 978-3-11-028812-4 e-ISBNBibliografische 978-3-11-028817-9 Information der Deutschen Nationalbibliothek Die Deutsche Nationalbibliothek verzeichnet diese Publikation in der Deutschen Nationalbibliogra- fie;This detaillierte work is licensed bibliografische under the DatenCreative sind Commons im Internet Attribution-NonCommercial-NoDerivs über 3.0 License, Libraryhttp://dnb.dnb.deas of February of Congress 23, 2017.abrufbar.