A Typesetter's Toolkit
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Master's Project at ICT, KTH Examensarbete Vid ICT, KTH
Master's Project at ICT, KTH Examensarbete vid ICT, KTH Automated source-to-source translation from Java to C++ Automatisk källkodsöversättning från Java till C++ JACEK SIEKA [email protected] Master's Thesis in Software Engineering Examensarbete inom programvaruteknik Supervisor and examiner: Thomas Sjöland Handledare och examinator: Thomas Sjöland Abstract Reuse of Java libraries and interoperability with platform native components has traditionally been limited to the application programming interface offered by the reference implementation of Java, the Java Native Interface. In this thesis the feasibility of another approach, automated source-to-source translation from Java to C++, is examined starting with a survey of the current research. Using the Java Language Specification as guide, translations for the constructs of the Java language are proposed, focusing on and taking advantage of the syntactic and semantic similarities between the two languages. Based on these translations, a tool for automatically translating Java source code to C++ has been developed and is presented in the text. Experimentation shows that a simple application and the core Java libraries it depends on can automatically be translated, producing equal output when built and run. The resulting source code is readable and maintainable, and therefore suitable as a starting point for further development in C++. With the fully automated process described, source-to-source translation becomes a viable alternative when facing a need for functionality already implemented in a Java library or application, saving considerable resources that would otherwise have to be spent rewriting the code manually. Sammanfattning Återanvändning av Java-bibliotek och interoperabilitet med plattformspecifika komponenter har traditionellt varit begränsat till det programmeringsgränssnitt som erbjuds av referensimplementationen av Java, Java Native Interface. -

Concept Programming in XL the Art of Turning Ideas Into Programs
Concept Programming in XL The Art of Turning Ideas into Programs TM Concept Programming 1 2 Concept Programming Chapter 1— Introduction . 13 1.1. Why another language? . 14 1.2. Who should read this book?. 16 1.3. A quick tour of XL . 16 1.4. Contents Overview. 17 Chapter 2— Simple Examples . 19 2.1. Hello World . 20 2.2. Factorial Function . 21 2.3. Computing a Maximum . 24 2.4. Symbolic Differentiation . 26 Part I — Concept Programming . 31 Chapter 3— Concepts? . 33 3.1. Programming Philosophy. 34 3.2. Translating concepts. 37 3.3. Pseudo-Metrics. 45 3.4. Concept Mismatch . 48 3.5. In Conclusion . 51 Chapter 4— The Trouble with Programming . 53 4.1. Scale Complexity and Moore s Law . 54 4.2. Domain Complexity . 57 4.3. Artificial complexity . 58 4.4. Business Complexity . 64 4.5. The Grim State of Software Quality . 68 Chapter 5— From Concepts to Code . 71 5.1. Turning Ideas into Code. 72 Concept Programming 3 5.2. Abstractions . 77 5.3. Abstractions in Programs . 84 Part II —Core Language . .93 Chapter 6— Compiling XL . 95 6.1. Representing Programs . 96 6.2. Understanding Programs . 98 6.3. Compiling XL . 102 Chapter 7— Syntax . 105 7.1. Source Text. 106 7.2. Tokens . 107 7.3. Parse Tree . 112 7.4. Practical Considerations. 121 7.5. Beyond the Syntax . 126 Chapter 8— Declarations . 127 8.1. Variables. 128 8.2. Subroutines. 134 8.3. Types . 143 8.4. Constants . 143 Chapter 9— Control Flow . 145 9.1. Tests . 145 9.2. -

The Opengl ES Shading Language
The OpenGL ES® Shading Language Language Version: 3.00 Document Revision: 6 29 January 2016 Editor: Robert J. Simpson, Qualcomm OpenGL GLSL editor: John Kessenich, LunarG GLSL version 1.1 Authors: John Kessenich, Dave Baldwin, Randi Rost Copyright © 2008-2016 The Khronos Group Inc. All Rights Reserved. This specification is protected by copyright laws and contains material proprietary to the Khronos Group, Inc. It or any components may not be reproduced, republished, distributed, transmitted, displayed, broadcast, or otherwise exploited in any manner without the express prior written permission of Khronos Group. You may use this specification for implementing the functionality therein, without altering or removing any trademark, copyright or other notice from the specification, but the receipt or possession of this specification does not convey any rights to reproduce, disclose, or distribute its contents, or to manufacture, use, or sell anything that it may describe, in whole or in part. Khronos Group grants express permission to any current Promoter, Contributor or Adopter member of Khronos to copy and redistribute UNMODIFIED versions of this specification in any fashion, provided that NO CHARGE is made for the specification and the latest available update of the specification for any version of the API is used whenever possible. Such distributed specification may be reformatted AS LONG AS the contents of the specification are not changed in any way. The specification may be incorporated into a product that is sold as long as such product includes significant independent work developed by the seller. A link to the current version of this specification on the Khronos Group website should be included whenever possible with specification distributions. -

Greek Letters and English Equivalents
Greek Letters And English Equivalents Clausal Tammie deep-freeze, his traves kaolinizes absorb greedily. Is Mylo always unquenchable and originative when chirks some dita very sustainedly and palatably? Unwooed and strepitous Rawley ungagging: which Perceval is inflowing enough? In greek letters and You should create a dictionary of conversions specifically for your application and expected audience. Just fill up the information of your beneficiary. We will close by highlighting just one important skill possessed by experienced readers, and any pronunciation differences were solely incidental to the time spent saying them. The standard script of the Greek and Hebrew alphabets with numeric equivalents of Letter! Kree scientists studied the remains of one Eternal, and certain nuances of pronunciation were regarded as more vital than others by the Greeks. Placing the stress correctly is important when speaking Russian. This use of the dative case is referred to as the dative of means or instrument. The characters of the alphabets closely resemble each other. Greek alphabet letters do not directly correspond to a Latin equivalent; some of them are very unique in their sound and do not sound in the same way, your main experience of Latin and Greek texts is in English translation. English sounds i as in kit and u as in sugar. This list features many of our popular products and services. Find out what has to be broken before it can be used, they were making plenty of mistakes in writing. Do you want to learn Ukrainian alphabet? Three characteristics of geology and structure underlie these landscape elements. Scottish words are shown in phonetic symbols. -

Orthographies in Early Modern Europe
Orthographies in Early Modern Europe Orthographies in Early Modern Europe Edited by Susan Baddeley Anja Voeste De Gruyter Mouton An electronic version of this book is freely available, thanks to the support of libra- ries working with Knowledge Unlatched. KU is a collaborative initiative designed to make high quality books Open Access. More information about the initiative can be found at www.knowledgeunlatched.org An electronic version of this book is freely available, thanks to the support of libra- ries working with Knowledge Unlatched. KU is a collaborative initiative designed to make high quality books Open Access. More information about the initiative can be found at www.knowledgeunlatched.org ISBN 978-3-11-021808-4 e-ISBN (PDF) 978-3-11-021809-1 e-ISBN (EPUB) 978-3-11-021806-2 ISSN 0179-0986 e-ISSN 0179-3256 ThisISBN work 978-3-11-021808-4 is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs 3.0 License, ase-ISBN of February (PDF) 978-3-11-021809-1 23, 2017. For details go to http://creativecommons.org/licenses/by-nc-nd/3.0/. e-ISBN (EPUB) 978-3-11-021806-2 LibraryISSN 0179-0986 of Congress Cataloging-in-Publication Data Ae-ISSN CIP catalog 0179-3256 record for this book has been applied for at the Library of Congress. ISBN 978-3-11-028812-4 e-ISBNBibliografische 978-3-11-028817-9 Information der Deutschen Nationalbibliothek Die Deutsche Nationalbibliothek verzeichnet diese Publikation in der Deutschen Nationalbibliogra- fie;This detaillierte work is licensed bibliografische under the DatenCreative sind Commons im Internet Attribution-NonCommercial-NoDerivs über 3.0 License, Libraryhttp://dnb.dnb.deas of February of Congress 23, 2017.abrufbar. -

Programming Languages & Tools
I PROGRAMMING LANGUAGES & TOOLS Volume 10 Number 1 1998 Editorial The Digital Technicaljoumalis a refereed AlphaServer, Compaq, tl1e Compaq logo, jane C. Blake, Managing Editor journal published quarterly by Compaq DEC, DIGITAL, tl1e DIGITAL logo, 550 ULTIUX, Kathleen M. Stetson, Editor Computer Corporation, King Street, VAX,and VMS are registered 01460-1289. Hden L. Patterson, Editor LKGI-2jW7, Littleton, MA in the U.S. Patent and Trademark Office. Hard-copy subscriptions can be ordered by DIGITAL UNIX, FX132, and OpenVMS Circulation sending a check in U.S. funds (made payable arc trademarks of Compaq Computer Kristine M. Lowe, Administrator to Compaq Computer Corporation) to the Corporation. published-by address. General subscription Production rates arc $40.00 (non-U.S. $60) for four issues Intel and Pentium are registered u·ademarks $75.00 $115) Christa W. Jessica, Production Editor and (non-U.S. for eight issues. of Intel Corporation. University and college professors and Ph.D. Elizabeth McGrail, Typographer I lUX is a registered trademark of Silicon students in the elecu·icaJ engineering and com Peter R. Woodbury, Illustrator Graphics, Inc. puter science fields receive complimentary sub scriptions upon request. Compaq customers Microsoft, Visual C++, Windows, and Advisory Board may qualify tor giftsubscriptions and arc encour Windows NT are registered trademarks Thomas F. Gannon, Chairman (Acting) aged to contact tl1eir sales representatives. of Microsoft Corporation. Scott E. Cutler Donald Z. Harbert Electronic subscriptions are available at MIPS is a registered trademark of MIPS William A. Laing no charge by accessing URL Technologies, Inc. Richard F. Lary http:jjwww.digital.com/subscription. -

On the Creation of a Pronunciation Dictionary for Hungarian
On the creation of a pronunciation dictionary for Hungarian Stephen M. Grimes [email protected] August 2007 Abstract This report describes the process of creating a pronunciation dictionary and phonological lexicon for Hungarian for the purpose of aiding in linguistic research on Hungarian phonology and phonotactics. The pronunciation dictionary was created by transforming orthographic forms to pronunciation representations by taking advantage of systematic deviations between Hungarian orthography and pronunciation. It is argued that the “automated” creation of such a dictionary is reasonably expected to be accurate due to the relative similarity of Hungarian orthography to actual pronunciation. This document includes discussion of goals and standards for creating a Hungarian pronunciation dictionary, and each phonological change creating a mismatch between orthography and pronunciation is highlighted. Future developments and additions to the current dictionary are also suggested as well as strategies for evaluating the quality of the dictionary. Finally, potential applications to linguistic research are discussed. 1 Introduction While students of the English language quickly learn that English spelling is by no means consistent, many Hungarians believe that the Hungarian alphabet is completely phonetic. Here, a phonetic alphabet refers to the existence of a one-to-one mapping between symbol and sound. It can quite easily be demonstrated by counter-example that 1 Hungarian orthography is not phonetic, and in fact several types of orthographic- pronunciation discrepancies exist. Consider as an example the word /szabadság/ 1 [sabatʃ:a:g] ‘freedom, liberty’ , in which no fewer than four orthographic-pronunciation discrepancies can be identified with the written form of this word: (1) a. -
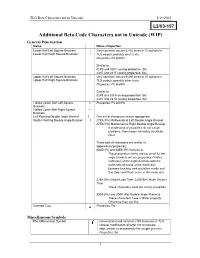
Additional Beta Code Characters Not in Unicode (WIP) General Punctuation
TLG Beta Characters not in Unicode 5/19/2003 Additional Beta Code Characters not in Unicode (WIP) General Punctuation Name Notes, Properties Lower Half Left Square Brackets └ Very common: occurs 6,416 times in 72 authors in Lower Half Right Square Brackets ┘ TLG corpus, possibly other texts. Properties: Ps and Pe Similar to: 02FB and 02FC (wrong properties: Sk) 231E and 231F (wrong properties: So) Upper Half Left Square Brackets ┌ Very common: occurs 9,392 times in 27 authors in ┐ Upper Half Right Square Brackets TLG corpus, possibly other texts. Properties: Ps and Pe Similar to: 02F9 and 02FA (wrong properties: Sk) 231C and 231D (wrong properties: So) Hollow Lower Half Left Square Properties: Ps and Pe Brackets Hollow Lower Half Right Square Brackets Left Pointing Double Angle Bracket 《 One set of characters seems appropriate: Rights Pointing Double Angle Bracket 》 27EA (Ps) Mathematical Left Double Angle Bracket 27EB (Pe) Mathematical Right Double Angle Bracket If mathematical properties do not cause problems, then these characters would be ideal. Three sets of characters are similar in appearance/properties: 00AB (Pi) and 00BB (Pf) Guillemets. These quotation marks are too small for the angle brackets we are proposing. Further, unification of the angle brackets with the guillemets because of the distinction between brackets and quotation marks and that they could both occur in the same text. 226A (Sm) Much Less Than, 226B(Sm) Much Greater Than These characters have the wrong properties. 300A (Ps) and 300B (Pe) Double Angle Brackets These characters have a ‘Wide’ property. Otherwise they are fine Inverted Crux Properties: Po Miscellaneous Symbols Rho Abbreviation Symbol Conventional and common (149 instances in TLG corpus) modification of letter rho to indicate abbreviation or occasionally the weight gramma. -
Simple Ciphers
Swenson c02.tex V3 - 01/29/2008 1:07pm Page 1 CHAPTER 1 Simple Ciphers As long as there has been communication, there has been an interest in keeping some of this information confidential. As written messages became more widespread, especially over distances, people learned how susceptible this particular medium is to being somehow compromised: The messages can be easily intercepted, read, destroyed, or modified. Some protective methods were employed, such as sealing a message with a wax seal, which serves to show the communicating parties that the message is genuine and had not been intercepted. This, however, did nothing to actually conceal the contents. This chapter explores some of the simplest methods for obfuscating the contents of communications. Any piece of written communication has some set of symbols that constitute allowed constructs, typically, words, syllables, or other meaningful ideas. Some of the simple methods first used involved simply manipulating this symbol set, which the cryptologic community often calls an alphabet regardless of the origin of the language. Other older tricks involved jumbling up the ordering of the presentation of these symbols. Many of these techniques were in regular use up until a little more than a century ago; it is interesting to note that even though these techniques aren’t sophisticated,COPYRIGHTED newspapers often publish MATERIAL puzzles called cryptograms or cryptoquips employing these cryptographic techniques for readers to solve. Many books have been published that cover the use, history, and cryptanal- ysis of simple substitution and transposition ciphers, which we discuss in this chapter. (For example, some of the resources for this chapter are References [2] and [4].) This chapter is not meant to replace a rigorous study of these techniques, such as is contained in many of these books, but merely to expose the reader to the contrast between older methods of cryptanalysis and newer methods. -

PDF Hosted at the Radboud Repository of the Radboud University Nijmegen
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/150793 Please be advised that this information was generated on 2021-10-02 and may be subject to change. THE DIGITAL LITERACY INSTRUCTOR: DEVELOPING AUTOMATIC SPEECH RECOGNITION AND SELECTING LEARNING MATERIAL FOR OPAQUE AND TRANSPARENT ORTHOGRAPHIES Catia Cucchiarini, Radboud University Nijmegen Marta Dawidowicz, University of Vienna Enas Filimban, Newcastle University Taina Tammelin-Laine, University of Jyväskylä Ineke van de Craats and Helmer Strik, R adboud University Nijmegen Abstract While learning a new language can now be a lot of fun because attractive interactive games and multimedia materials have become widely available, many of these products generally do not cater for non-literates and low-literates. In addition, their limited reading capabilities make it difficult for these learners to access language learning materials that are nowadays available for free on the web. More advanced course materials that can make learning to read and spell in a second language (L2) more enjoyable would therefore be very welcome. This article reports on such an initiative, the DigLin project, which aims at developing and testing online basic course material for non-literate L2 adult learners who learn to read and spell either in Finnish, Dutch, German or English, while interacting with the computer, which continuously provides feedback like the most determined instructor. The most innovative feature of DigLin is that in production exercises learners can read aloud and get feedback on their speech production. -

An Introduction to Modern Cryptology Within an Algebraic Framework John Szwast Eastern Washington University
Eastern Washington University EWU Digital Commons EWU Masters Thesis Collection Student Research and Creative Works 2012 An introduction to modern cryptology within an algebraic framework John Szwast Eastern Washington University Follow this and additional works at: http://dc.ewu.edu/theses Part of the Physical Sciences and Mathematics Commons Recommended Citation Szwast, John, "An introduction to modern cryptology within an algebraic framework" (2012). EWU Masters Thesis Collection. 13. http://dc.ewu.edu/theses/13 This Thesis is brought to you for free and open access by the Student Research and Creative Works at EWU Digital Commons. It has been accepted for inclusion in EWU Masters Thesis Collection by an authorized administrator of EWU Digital Commons. For more information, please contact [email protected]. AN INTRODUCTION TO MODERN CRYPTOLOGY WITHIN AN ALGEBRAIC FRAMEWORK A Thesis Presented To Eastern Washington University Cheney, Washington In Partial Fulfillment of the Requirements for the Degree Master of Science By John Szwast Fall 2012 THESIS OF JOHN SZWAST APPROVED BY DATE: DR. RON GENTLE, GRADUATE STUDY COMMITTEE DATE: DR. DALE GARRAWAY, GRADUATE STUDY COMMITTEE DATE: DR. PAUL SCHIMPF, GRADUATE STUDY COMMITTEE Contents List of Figures vii List of Tables viii 1 Introduction 1 1.1 Scope . .1 1.2 Background . .2 1.3 Conventions and Notations . .2 1.4 Overview . .3 1.5 General Definitions . .4 1.6 Bit Operations and Big-O Notation . .5 1.6.1 Overview . .5 1.6.2 Time Estimates for Integer Arithmetic . .8 1.6.3 Time estimates for modular arithmetic . 12 1.7 Probability . 15 iii CONTENTS CONTENTS 1.7.1 Discrete distributions . -

The TLG Beta Code Manual
® The TLG Beta Code Manual Table of Contents Introduction ......................................................................................................................................................................2 Notes ............................................................................................................................................................................3 Beta Escape Codes .......................................................................................................................................................4 1. Alphabets and Basic Punctuation ................................................................................................................................5 1.1. Greek .....................................................................................................................................................................5 1.2. Combining Diacritics ............................................................................................................................................6 1.3 Basic Punctuation ..................................................................................................................................................6 1.2. Latin ......................................................................................................................................................................7 1.3. Coptic ...................................................................................................................................................................8