A Reconfigurable Architecture Via Grain Perception Operator
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

University Name Agency Number China Embassy in Tehran 3641
University Name Agency Number China Embassy in Tehran 3641 Aba Teachers College Agency Number 10646 Agricultural University of Hebei Agency Number 10086 Akzo vocational and technical College Agency Number 13093 Anglo-Chinese College Agency Number 12708 Anhui Agricultural University Agency Number 10364 Anhui Audit Vocational College Agency Number 13849 Anhui Broadcasting Movie And Television College Agency Number 13062 Anhui Business College of Vocational Technology Agency Number 12072 Anhui Business Vocational College Agency Number 13340 Anhui China-Australia Technology and Vocational College Agency Number 13341 Anhui College of Traditional Chinese Medicine Agency Number 10369 Anhui College of Traditional Chinese Medicine Agency Number 12924 Anhui Communications Vocational & Technical College Agency Number 12816 Anhui Eletrical Engineering Professional Technique College Agency Number 13336 Anhui Finance & Trade Vocational College Agency Number 13845 Anhui Foreign Language College Agency Number 13065 Anhui Industry Polytechnic Agency Number 13852 Anhui Institute of International Business Agency Number 13846 Anhui International Business and Economics College(AIBEC) Agency Number 12326 Anhui International Economy College Agency Number 14132 Anhui Lvhai Vocational College of Business Agency Number 14133 Anhui Medical College Agency Number 12925 Anhui Medical University Agency Number 10366 Anhui Normal University Agency Number 10370 Anhui Occupatinoal College of City Management Agency Number 13338 Anhui Police College Agency Number 13847 Anhui -

A Complete Collection of Chinese Institutes and Universities For
Study in China——All China Universities All China Universities 2019.12 Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities Anhui 安徽 【www.studyinanhui.com】 1. Anhui University 安徽大学 http://ahu.admissions.cn 2. University of Science and Technology of China 中国科学技术大学 http://ustc.admissions.cn 3. Hefei University of Technology 合肥工业大学 http://hfut.admissions.cn 4. Anhui University of Technology 安徽工业大学 http://ahut.admissions.cn 5. Anhui University of Science and Technology 安徽理工大学 http://aust.admissions.cn 6. Anhui Engineering University 安徽工程大学 http://ahpu.admissions.cn 7. Anhui Agricultural University 安徽农业大学 http://ahau.admissions.cn 8. Anhui Medical University 安徽医科大学 http://ahmu.admissions.cn 9. Bengbu Medical College 蚌埠医学院 http://bbmc.admissions.cn 10. Wannan Medical College 皖南医学院 http://wnmc.admissions.cn 11. Anhui University of Chinese Medicine 安徽中医药大学 http://ahtcm.admissions.cn 12. Anhui Normal University 安徽师范大学 http://ahnu.admissions.cn 13. Fuyang Normal University 阜阳师范大学 http://fynu.admissions.cn 14. Anqing Teachers College 安庆师范大学 http://aqtc.admissions.cn 15. Huaibei Normal University 淮北师范大学 http://chnu.admissions.cn Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities 16. Huangshan University 黄山学院 http://hsu.admissions.cn 17. Western Anhui University 皖西学院 http://wxc.admissions.cn 18. Chuzhou University 滁州学院 http://chzu.admissions.cn 19. Anhui University of Finance & Economics 安徽财经大学 http://aufe.admissions.cn 20. Suzhou University 宿州学院 http://ahszu.admissions.cn 21. -

The Culture and Inheritance of Huizhou Architecture: Taking the Design Practice of INK Weiping Tourism Cultural Street As an Example
E3S Web of Conferences 237, 04028 (2021) https://doi.org/10.1051/e3sconf/202123704028 ARFEE 2020 The culture and inheritance of Huizhou architecture: taking the design practice of INK Weiping tourism cultural street as an example Peng Zhiming1, Yang Yang2, Xiao Hanyue3,Li Yunzhang3, and Bi Zhongsong1,3* 1*College of Architectural and Engineering & Research Center of Huizhou Architecture, Huangshan University,245041 Huangshan, China3 2School of Architecture, University of Sheffield, Sheffield S10 2TN, UK 3College of Architecture and Environment, Sichuan University,610065 Chengdu, China Abstract. This article uses the design analysis and insights of the Weiping Tourism Cultural Street, which the author participated in and practice to discuss how Huizhou culture can be protected and inherited in tourism cultural projects. Through the planning of the buildings of the project and the site planning of the surrounding environment, the formation of public spaces such as traditional streets, traditional theaters, as well as the influence of Huizhou culture on the space and architectural style and details of the building, the article interprets in detail the application of Huizhou architectural design and its traditional cultural connotations in cultural tourism development projects. At the same time, the article also discusses and summarizes the problems encountered in the protection and inheritance of Huizhou culture in the design and development process of the project, which has an enlightening effect on the better integration of the current practice of new Huizhou architecture with the current social and economic environment. 1 Research Background amount of agricultural productivity, promoting drastic urbanization, modernization of life, and a relatively Huizhou culture, Dunhuang culture, and Tibetan culture comfortable income level. -
Dear Ms. Jingping, XU It Is My Pleasure to Invite Your Delegation To
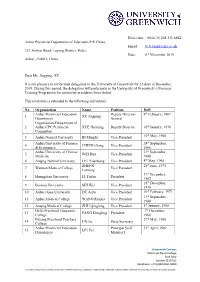
Direct line: 0044 (0) 208 331 8882 Anhui Provincial Department of Education P.R China, Email: [email protected] 321 Jinzhai Road, Luyang District, Hefei, Date: 6th November 2019 Anhui, 230061, China Dear Ms. Jingping, XU It is my pleasure to invite your delegation to the University of Greenwich for 21 days in December, 2019. During this period, the delegation will participate in the University of Greenwich’s Overseas Training Programme for university presidents from Anhui. This invitation is extended to the following individuals: No. Organisation Name Position DoB Anhui Provincial Education Deputy Director- 9th February, 1967 1 XU Jingping Department General Organisation Department of 2 Anhui CPC Provincial XUE Huiming Deputy Director 10th January, 1976 Committee th 3 Anhui Normal University BI Mingfu Vice President 10 May, 1968 Anhui University of Finance 24th September, 4 CHENG Gang Vice President & Economics 1966 Anhui University of Chinese 21st September, 5 WEI Hua Vice President Medicine 1966 6 Anqing Normal University LIU Youzhong Vice President 4th May, 1965 ZHENG 28th June, 1975 7 Wannan Medical College Vice President Lanrong 31st December, 8 Huangshan University LI Tiefan President 1967 18th December, 9 Bozhou University SHI Wei Vice President 1970 10 Anhui Open University DU Aiyu Vice President 16th February, 1971 11th September, 11 Anhui Medical College WANG Runxia Vice President 1968 12 Anqing Medical College ZHU Qingfeng Vice President 5th January, 1968 Hefei Preschool Education 7th December, 13 FANG Dongling President College 1968 Fuyang Preschool Teachers 27th May, 1968 14 JIN Jie Party Secretary College Anhui Provincial Education Principal Staff 21st April, 1981 15 LIU Fei Department Member I Greenwich Campus Old Royal Naval College Park Row London SE10 9LS Telephone: +44 (0)20 8331 8000 University of Greenwich, a charity and company limited by guarantee, registered in England (reg no.986729). -

University of Leeds Chinese Accepted Institution List 2021
University of Leeds Chinese accepted Institution List 2021 This list applies to courses in: All Engineering and Computing courses School of Mathematics School of Education School of Politics and International Studies School of Sociology and Social Policy GPA Requirements 2:1 = 75-85% 2:2 = 70-80% Please visit https://courses.leeds.ac.uk to find out which courses require a 2:1 and a 2:2. Please note: This document is to be used as a guide only. Final decisions will be made by the University of Leeds admissions teams. -

CGS) Merupakan Beasiswa Full Untuk Meneruskan Jenjang Pendidikan Magister Di Shanghai Normal University Dari Tahun 2016 Sampai Dengan Saat Ini
Departemen Pendidikan dan Pengembangan Organisasi Perhimpunan Pelajar Indonesia (PPI) Tiongkok Beasiswa pertama yang ia peroleh dari Chinese Government Scholarships (CGS) merupakan beasiswa full untuk meneruskan jenjang pendidikan magister di Shanghai Normal University dari tahun 2016 sampai dengan saat ini. Belajar dan tinggal di negeri China merupakan cita-cita kecilnya semenjak usia 6 tahun. Karena ia terinspirasi dari hadits Nabi Muhammad SAW yang berbunyi, “Uthlubul ilma walau bisshin” yang artinya, “Carilah ilmu sampai ke negeri China”. 0 | H a l a m a n Departemen Pendidikan dan Pengembangan Organisasi Perhimpunan Pelajar Indonesia (PPI) Tiongkok 1 | H a l a m a n Departemen Pendidikan dan Pengembangan Organisasi Perhimpunan Pelajar Indonesia (PPI) Tiongkok PPI Tiongkok mempersembahkan PANDUAN KULIAH DI CHINA Edisi 2017 Penulis: Nurul Juliati Putra Wanda Ahmad Fahmi Putri Aris Safitri Tirta anhari Editor: Fadlan Muzakki, Sitti Marwah, Marilyn Janice 2 | H a l a m a n Departemen Pendidikan dan Pengembangan Organisasi Perhimpunan Pelajar Indonesia (PPI) Tiongkok Sambutan Ketua PPI Tiongkok Salam sejahtera untuk kita semua. Ada pepatah yang mengatakan hidup itu harus menjadi garam dan terang bagi dunia. atas dasar itulah PPI Tiongkok ada, yaitu memberikan kontribusi positif bagi Indonesia. PPI Tiongkok sebagai wadah pengembangan minat dan bakat mahasiswa Indonesia memegang peranan penting dalam mempersatukan para pelajar Indonesia di Tiongkok. salah satu misi kami adalah agar para pelajar Indonesia tidak lupa dengan bangsanya sendiri dan suatu saat nanti bisa pulang untuk membangun Indonesia. Oleh karena itu visi Kabinet KB (keluarga berencana) PPI Tiongkok tahun ini adalah memperkuat hubungan internal antar pengurus dan juga meningkatkan kesinergian antara PPIT Cabang. kami yakin dengan hubungan internal yang solid, bahkan hingga mampu menjadi seperti keluarga, ditambah dengan perencanaan yang matang, PPI Tiongkok dapat menghasilkan inisiatif-inisiatif yang dapat berdampak positif bagi mahasiswa-mahasiswa Indonesia yang ada di Tiongkok. -

Founding Spirit
Hanseo University Founding Spirit Founding Spirit Hanseo University's priority is to create a learning environment that encourages creativity, confidence and contribution. Creativity is vitally important now in creating the new paradigm essential to meet the complexities of the rapidly changing global village. Confidence goes hand-in-hand with creativity to insure that a first- class academic experience and tireless efforts lead to the attainment of aspirations. Contribution is the ultimate goal of higher education, To be truly relevant, the academic experience must be used to contribute to society. Educational Purpose Hanseo University is committed to the educational philosophy of the nation. In this light, the University teaches and researches state-of-the art theories and their applications for the development of the nation and human society, thus producing a leadership to contribute to various fields of the society. Educational Goals 1. To develop individuals with the expertise required to meet society developments. 2. To provide specialized practical education needed to meet the requirements of an increasingly specialized, information-oriented global environment. 3. To play a constructive role in national and community development through academic-industrial cooperation. 4. To contribute to academic advancement through open and extended educational efforts. 5. To play an important role in cultural developments of the society by offering a top quality academic environment. HANSEO UNIVERSITY | 3 P resident’s Message President’s Message 4 | HANSEO UNIVERSITY Hanseo University Hanseo University accomplished amazing developments in a short period of time based on confidence of becoming a leader of the age of the west coast and specialized education. -
1 Please Read These Instructions Carefully
PLEASE READ THESE INSTRUCTIONS CAREFULLY. MISTAKES IN YOUR CSC APPLICATION COULD LEAD TO YOUR APPLICATION BEING REJECTED. Visit http://studyinchina.csc.edu.cn/#/login to CREATE AN ACCOUNT. • The online application works best with Firefox or Internet Explorer (11.0). Menu selection functions may not work with other browsers. • The online application is only available in Chinese and English. 1 • Please read this page carefully before clicking on the “Application online” tab to start your application. 2 • The Program Category is Type B. • The Agency No. matches the university you will be attending. See Appendix A for a list of the Chinese university agency numbers. • Use the + by each section to expand on that section of the form. 3 • Fill out your personal information accurately. o Make sure to have a valid passport at the time of your application. o Use the name and date of birth that are on your passport. Use the name on your passport for all correspondences with the CLIC office or Chinese institutions. o List Canadian as your Nationality, even if you have dual citizenship. Only Canadian citizens are eligible for CLIC support. o Enter the mailing address for where you want your admission documents to be sent under Permanent Address. Leave Current Address blank. Contact your home or host university coordinator to find out when you will receive your admission documents. Contact information for you home university CLIC liaison can be found here: http://clicstudyinchina.com/contact-us/ 4 • Fill out your Education and Employment History accurately. o For Highest Education enter your current degree studies. -

Download Article (PDF)
Advances in Social Science, Education and Humanities Research, volume 205 The 2nd International Conference on Culture, Education and Economic Development of Modern Society (ICCESE 2018) Study on Phonetics Acquisition of English Learners from Regions of Prominent Dialects in Anhui Province from the Perspective of Optimality Theory* Huazhen Wang School of Foreign Languages Anhui Sanlian University Hefei, China 230601 Abstract—Based on Optimality theory and the existing Sound Pattern of English (SPE in short, Chomsky & Halle, research result at home and abroad, this paper discover the 1968). Once born, it has far-reaching influence on the entire influence of Anhui dialect on undergraduates’ English linguistic field and has been widely used in children's phonetic learning through the long-term phonetics teaching language acquisition, second language acquisition, syntax and experimental teaching, probes into the problems in and semantics as a linguistic theory. The first scholar in phonetic transfer of graduates in typical dialectal areas of China to introduce Optimality theory is Wang Jialing (1995). Anhui province and its reasons, and formulate new corrective His article entitled "Optimality Theory" published in teaching strategy. Through long-term teaching experiment and "Foreign Linguistics" first introduced the basic content of practical investigation, the author explores and analyzes the this theory and opened the prelude to the study of Optimality phonetic phenomenon of negative transfer from Anhui dialects theory in China. Later, some scholars (Zhong Rongfu, 1995; and the distribution area. Then feasible phonetic correction approach is given according to the phonetic feature of Li Bing, 1998; Zuo Yan, 1999; Gong Qi, 2000; Ma Qiuwu, undergraduates. -

Of the Students, by the Students, and for the Students
Of the Students, By the Students, and For the Students Of the Students, By the Students, and For the Students: Time for Another Revolution Edited by Martin Wolff Of the Students, By the Students, and For the Students: Time for Another Revolution, Edited by Martin Wolff This book first published 2010 Cambridge Scholars Publishing 12 Back Chapman Street, Newcastle upon Tyne, NE6 2XX, UK British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library Copyright © 2010 by Martin Wolff and contributors All rights for this book reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owner. ISBN (10): 1-4438-2565-4, ISBN (13): 978-1-4438-2565-8 English has become the gatekeeper to higher education and employment in China. This book is dedicated to all of those who are unable to unlock the gate and pass through. CET 4 and CET 6 National English examinations have become the symbol of English proficiency in reading and writing. Employers have required them as prerequisite to employment consideration. All comments of students quoted in this book were written by post-graduate students who have passed CET 4 and some have passed CET 6; and the comments were created on computers equipped with Microsoft WORD. The students’ comments are unedited to reflect their true lack of English competency and to debunk the claim that CET 4 and CET 6 reflect any appreciable English writing proficiency, particularly with the availability of the “spell function” of WORD. -

Chinese Institutions Admitting International Students Under Chinese
CHINESE INSTITUTIONS ADMITTING INTERNATIONAL STUDENTS UNDER CHINESE GOVERNMENT SCHOLARSHIP PROGRAMS NO. Province Name of the School 1 ANHUI HEFEI UNIVERSITY 2 PROVINCE ANHUI UNIVERSITY 3 HEFEI UNIVERSITY OF TECHNOLOGY 4 UNIVERSITY OF SCIENCE & TECHNOLOGY OF CHINA 5 HUANGSHAN UNIVERSITY 6 ANHUI NORMAL UNIVERSITY 7 ANHUI AGRICULTRRAL UNIVERSITY 8 ANHUI MEDICAL UNIVERSITY 9 BEIJING BEIJING TECHNOLOGY AND BUSINESS UNIVERSITY 10 MUNICIPALITY BEIJING UNIVERSITY OF CHEMICAL TECHNOLOGY 11 BEIJING SPORT UNIVERSITY 12 CENTRAL UNIVERSITY OF FINANCE AND ECNOMICS 13 BEIJING NORMAL UNIVERSITY 14 BEIJING FORESTRY UNIVERSITY 15 COMMUNICATION UNIVERSITY OF CHINA 16 BEIJING INTERNATIONAL STUDIES UNIVERSITY 17 UNIVERSITY OF CHINESE ACADEMY OF SCIENCES 18 THE GRADUATE SCHOOL OF THE CHINESE ACADEMY OF AGRICULTURAL SCIENCES 19 BEIJING JIAOTONG UNIVERSITY 20 UNIVERSITY OF INTERNATIONAL BUSINESS AND ECONOMICS 21 CHINA AGRICULTURE UNIVERSITY 22 CHINA UNIVERSITY OF PETROLEUM 23 CAPITAL NORMAL UNIVERSITY 24 BEIJING INSTITUTE OF TECHNOLOGY 25 THE CENTRAL ACADEMY OF DRAMA 26 UNIVERSITY OF SCIENCE AND TECHNOLOGY BEIJING 27 BEIJING UNIVERSITY OF TECHNOLOGY 28 CHINA UNIVERSITY OF GEOSCIENCES (BEIJING) 29 RENMIN UNIVERISTY OF CHINA 30 CAPITAL UNIVERSITY OF ECONOMICS & BUSINESS 31 PEKING UNIVERSITY 32 BEIJING UNIVERSITY OF POSTS AND TELECOMMUNICATIONS 33 BEIHANG UNIVERSITY 34 CAPITAL INSTITUTE OF PHYSICAL EDUCATION 35 BEIJING FILM ACADEMY 36 NORTH CHINA ELECTRIC POWER UNIVERSITY 37 BEIJING FOREIGN STUDIES UNIVERSITY 38 MINZU UNIVERSITY OF CHINA 39 CHINA UNIVERISTY OF -

TU Dublin PG Entry Requirements
TU Dublin PG entry requirements ‐ China Note: These requirements represent the minimum entry classification for our programmes This information is for general guidance only; entry requirements vary for different programmes. We will require the Degree certificate plus full set of transcripts and cannot assess on the basis of a Graduation Cert. alone. Chinese Name/Institution English Name 2.1 2.2 阿坝师范学院 Aba Teachers University 88 (3.7) 83 (3.5) 河北农业大学 Agricultural University of Hebei 80 (3.25) 75 (2.8) 安徽农业大学 Anhui Agricultural University 80 (3.25) 75 (2.8) 安徽医科大学 Anhui Medical University 80 (3.25) 75 (2.8) 安徽师范大学 Anhui Normal University 80 (3.25) 75 (2.8) 安徽工程大学 Anhui Polytechnic University 83 (3.5) 78 (3.1) 安徽科技学院 Anhui Science and Technology University (AKA University of Science And 83 (3.5) 78 (3.1) Technology of Anhui) 安徽大学 Anhui University 78 (3.1) 73 (2.6) 安徽建筑大学 Anhui University of Architecture 80 (3.25) 75 (2.8) 安徽中医药大学 Anhui University of Chinese Medicine 83 (3.5) 78 (3.1) 安徽财经大学 Anhui University of Finance & Economics 80 (3.25) 75 (2.8) 安徽理工大学 Anhui University of Science and Technology 80 (3.25) 75 (2.8) 安徽工业大学 Anhui University of Technology 80 (3.25) 75 (2.8) 安康学院 Ankang University 88 (3.7) 83 (3.5) 安庆师范大学 Anqing Normal University 83 (3.5) 78 (3.1) 鞍山师范学院 Anshan Normal University Liaoning China 88 (3.7) 83 (3.5) 安顺学院 Anshun University 88 (3.7) 83 (3.5) 安阳工学院 Anyang Institute of Technology 88 (3.7) 83 (3.5) 安阳师范学院 Anyang Normal University 83 (3.5) 78 (3.1) 白城师范学院 Baicheng Normal University 88 (3.7) 83 (3.5) 百色学院 Baise University