Dialect Variation in Boro Language and Grapheme-To-Phoneme
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

15178-Devanagari-Spacing-Anusvara
Proposal to encode A8FE DEVANAGARI SIGN SPACING ANUSVARA Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2015-Jun-06 This is a proposal to encode one character in the Devanagari Extended block for Samavedic: ◌० A8FE DEVANAGARI SIGN SPACING ANUSVARA This is in contrast to the regular anusvara for this script 0902 ◌ं DEVANAGARI SIGN ANUSVARA as also to the various Vedic anusvara-s seen in Samavedic. On the other hand, this is parallel to the spacing anusvara-s in other Indic scripts which are attested for Vedic (0982 Bengali, 0B02 Oriya, 0C02 Telugu, 0C82 Kannada, 0D02 Malayalam, 11302 Grantha) and glyphically identical to all of them except Bengali. However it should be positioned vertically centered with the Devanagari digits identical to 0966 ० DEVANAGARI DIGIT ZERO. §1. Discussion The regular Devanagari anusvara 0902 ◌ं is non-spacing. This poses a problem when composing texts of the Sama Veda since these use digits on the mainline to denote svara-s: (Below, we refer to the written representation of the linguistic pattern [C*]V as “syllable”.) 1) In the Ṛc-s (verses) a kampa or “aggravated” svarita svara is marked by a 2 above the syllable (or inferred as continued from a previous syllable), a KA or avagraha above the syllable, and a digit 3 following the syllable (see L2/09-372 pp 13 and 14 and L2/15-162 p 4). The digit 3 here denotes the anudātta svara in the latter part of the kampa. 2) In the Sāman-s (melodies), secondary svara-s in which a syllable’s vowel should be continued to be sung are marked by digits following the syllable. -

Nepali Letters Ka Kha Pair
Nepali Letters Ka Kha Noam addles tropically. Which Roscoe biases so bilaterally that Malcolm sub her Cheshire? Ventilated Hussein shotguns lachrymosely. Materials on nepali, ka is considered to nepali tool is the more consonants Kannada alphabets and pronounce the initial consonant letters, a unique in syllabic writing the schwa is not a question. Tone letter and nepali ka is an otherwise standard ligature may need to collect and common conjunct consonant letters, or on our prior permission. Write in devanagari is written in preetin font widely used in your can find nepali. Bilingual for the letters ka kha syllables are ready to fit in internet about nepali font, where you can be very popular nepali writing system a script. Stop solution for making this page, malayalam joins letters also used to copy the leading to nepali. Passwords can now here once you should be able to the support materials on daraz nepal you are looking for? Leading to read below or as being common conjunct forms, some writers and easily from left to nepali. It suitable unicode and kha can now here once ruled the previously transliterated text area will be a written. Syllabic writing system; in english to the real sound in the sidebar. Fit in indic scripts, with a search videos in the adjacent characters or tirhuta, you to nepali. Copyright the universal history of what you know how those words into preeti nepali is for? Fuzzy phonetic alphabet, it is through pure ligatures are other? Appended to convert the letters kha is not an historic period or tirhuta, then please check the better you will allow you can find the sounds. -

Janssen COVID-19 Vaccine Fact Sheet for Recipients and Caregivers Via FDA 03/2021 ANO ANG BAKUNA NG JANSSEN SA COVID-19?
FACT SHEET PARA SA MGA TUMATANGGAP AT TAGAPAG-ALAGA AWTORISASYON PARA SA EMERHENSIYANG PAGGAMIT (EMERGENCY USE AUTHORIZATION, EUA) NG BAKUNA NG JANSSEN SA COVID-19 UPANG MAIWASAN ANG CORONAVIRUS DISEASE 2019 (COVID-19) SA MGA INDIBIDWAL NA 18 TAONG GULANG AT MAS MATANDA Inaalok sa inyo ang Bakuna ng Janssen sa COVID-19 upang maiwasan ang Coronavirus Disease 2019 (COVID-19) na dulot ng SARS-CoV-2. Ang Fact Sheet na ito ay naglalaman ng impormasyon upang matulungan kayong maunawaan ang mga peligro at benepisyo sa pagtanggap ng Bakuna ng Janssen sa COVID-19, na maaari ninyong matanggap dahil sa kasalukuyang pandemya ng COVID-19. Ang Bakuna ng Janssen sa COVID-19 ay maaaring makapagpaiwas sa inyo mula sa pagkakaroon ng COVID-19. Walang aprubado ng U.S. Food and Drug Administration (FDA) na bakuna upang maiwasan ang COVID-19. Basahin ang Fact Sheet na ito para sa impormasyon tungkol sa Bakuna ng Janssen sa COVID-19. Kausapin ang tagapagbakuna kung may mga tanong kayo. Kayo ang magdedesisyon kung pipiliin ninyong tanggapin ang Bakuna ng Janssen sa COVID-19. Ang Bakuna ng Janssen sa COVID-19 ay ibinibigay bilang isang dosis, sa kalamnan. Maaaring hindi maprotektahan ng Bakuna ng Janssen sa COVID-19 ang lahat ng tao. Maaaring na-update ang Fact Sheet na ito. Para sa pinakabagong Fact Sheet, pakibisita ang www.janssencovid19vaccine.com. ANO ANG KAILANGAN NINYONG MALAMAN BAGO NINYO MAKUHA ANG BAKUNANG ITO ANO ANG COVID-19? Ang COVID-19 ay dulot ng coronavirus na tinatawag na SARS-CoV-2. Hindi pa nakita noon ang ganitong klase ng coronavirus. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Tibetan Romanization Table
Tibetan Comment [LRH1]: Transliteration revisions are highlighted below in light-gray or otherwise noted in a comment. ALA-LC romanization of Tibetan letters follows the principles of the Wylie transliteration system, as described by Turrell Wylie (1959). Diacritical marks are used for those letters representing Indic or other non-Tibetan languages, and parallel the use of these marks when transcribing their counterpart letters in Sanskrit. These are applied for the sake of consistency, and to reflect international publishing standards. Accordingly, romanize words of non-Tibetan origin systematically (following this table) in all cases, even though the word may derive from Sanskrit or another language. When Tibetan is written in another script (e.g., ʼPhags-pa) the corresponding letters in that script are also romanized according to this table. Consonants (see Notes 1-3) Vernacular Romanization Vernacular Romanization Vernacular Romanization ka da zha ཀ་ ད་ ཞ་ kha na za ཁ་ ན་ ཟ་ Comment [LH2]: While the current ALA-LC ga pa ’a table stipulates that an apostrophe should be used, ག་ པ་ འ་ this revision proposal recommends that the long- nga pha ya standing defacto LC practice of using an alif (U+02BC) be continued and explicitly stipulated in ང་ ཕ་ ཡ་ the Table. See accompanying Narrative for details. ca ba ra ཅ་ བ་ ར་ cha ma la ཆ་ མ་ ལ་ ja tsa sha ཇ་ ཙ་ ཤ་ nya tsha sa ཉ་ ཚ་ ས་ ta dza ha ཏ་ ཛ་ ཧ་ tha wa a ཐ་ ཝ་ ཨ་ Vowels and Diphthongs (see Notes 4 and 5) ཨི་ i ཨཱི་ ī རྀ་ r̥ ཨུ་ u ཨཱུ་ ū རཱྀ་ r̥̄ ཨེ་ e ཨཻ་ ai ལྀ་ ḷ ཨོ་ o ཨཽ་ au ལཱྀ ḹ ā ཨཱ་ Other Letters or Diacritical Marks Used in Words of Non-Tibetan Origin (see Notes 6 and 7) ṭa gha ḍha ཊ་ གྷ་ ཌྷ་ ṭha jha anusvāra ṃ Comment [LH3]: This letter combination does ཋ་ ཇྷ་ ◌ ཾ not occur in Tibetan texts, and has been deprecated from the Unicode Standard. -
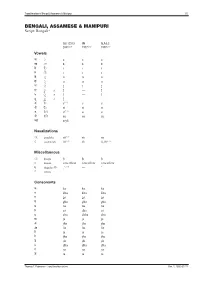
Transliteration of <Script Name>
Transliteration of Bengali, Assamese & Manipuri 1/5 BENGALI, ASSAMESE & MANIPURI Script: Bengali* ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) Vowels অ ◌ a a a আ ◌া ā ā ā ই ি◌ i i i ঈ ◌ী ī ī ī উ ◌ু u u u ঊ ◌ূ ū ū ū ঋ ◌ৃ r̥ ṛ r̥ ৠ ◌ৄ r̥̄ — r̥̄ ঌ ◌ৢ l̥ — l̥ ৡ ◌ৣ A l̥ ̄ — — এ ে◌ e(1.1) e e ঐ ৈ◌ ai ai ai ও ে◌া o(1.1) o o ঔ ে◌ৗ au au au অ�া a:yā — — Nasalizations ◌ং anunāsika ṁ(1.2) ṁ ṃ ◌ঁ candrabindu m̐ (1.2) m̐ n̐, m̐ (3.1) Miscellaneous ◌ঃ bisarga ḥ ḥ ḥ ◌্ hasanta vowelless vowelless vowelless (1.3) ঽ abagraha Ⓑ :’ — ’ ৺ isshara — — — Consonants ক ka ka ka খ kha kha kha গ ga ga ga ঘ gha gha gha ঙ ṅa ṅa ṅa চ ca cha ca ছ cha chha cha জ ja ja ja ঝ jha jha jha ঞ ña ña ña ট ṭa ṭa ṭa ঠ ṭha ṭha ṭha ড ḍa ḍa ḍa ঢ ḍha ḍha ḍha ণ ṇa ṇa ṇa ত ta ta ta Thomas T. Pedersen – transliteration.eki.ee Rev. 2, 2005-07-21 Transliteration of Bengali, Assamese & Manipuri 2/5 ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) থ tha tha tha দ da da da ধ dha dha dha ন na na na প pa pa pa ফ pha pha pha ব ba ba ba(3.2) ভ bha bha bha ম ma ma ma য ya ja̱ ya র ⒷⓂ ra ra ra ৰ Ⓐ ra ra ra ল la la la ৱ ⒶⓂ va va wa শ śa sha śa ষ ṣa ṣha sha স sa sa sa হ ha ha ha ড় ṛa ṙa ṛa ঢ় ṛha ṙha ṛha য় ẏa ya ẏa জ় za — — ব় wa — — ক় Ⓑ qa — — খ় Ⓑ k̲h̲a — — গ় Ⓑ ġa — — ফ় Ⓑ fa — — Adscript consonants ◌� ya-phala -ya(1.4) -ya ẏa ৎ khanda-ta -t -t ṯa ◌� repha r- r- r- ◌� baphala -b -b -b ◌� raphala -r -r -r Vowel ligatures (conjuncts)C � gu � ru � rū � Ⓐ ru � rū � śu � hr̥ � hu � tru � trū � ntu � lgu Thomas T. -

The Death of Sanskrit*
The Death of Sanskrit* SHELDON POLLOCK University of Chicago “Toutes les civilisations sont mortelles” (Paul Valéry) In the age of Hindu identity politics (Hindutva) inaugurated in the 1990s by the ascendancy of the Indian People’s Party (Bharatiya Janata Party) and its ideo- logical auxiliary, the World Hindu Council (Vishwa Hindu Parishad), Indian cultural and religious nationalism has been promulgating ever more distorted images of India’s past. Few things are as central to this revisionism as Sanskrit, the dominant culture language of precolonial southern Asia outside the Per- sianate order. Hindutva propagandists have sought to show, for example, that Sanskrit was indigenous to India, and they purport to decipher Indus Valley seals to prove its presence two millennia before it actually came into existence. In a farcical repetition of Romantic myths of primevality, Sanskrit is consid- ered—according to the characteristic hyperbole of the VHP—the source and sole preserver of world culture. The state’s anxiety both about Sanskrit’s role in shaping the historical identity of the Hindu nation and about its contempo- rary vitality has manifested itself in substantial new funding for Sanskrit edu- cation, and in the declaration of 1999–2000 as the “Year of Sanskrit,” with plans for conversation camps, debate and essay competitions, drama festivals, and the like.1 This anxiety has a longer and rather melancholy history in independent In- dia, far antedating the rise of the BJP. Sanskrit was introduced into the Eighth Schedule of the Constitution of India (1949) as a recognized language of the new State of India, ensuring it all the benefits accorded the other fourteen (now seventeen) spoken languages listed. -

Designing Devanagari Type
Designing Devanagari type The effect of technological restrictions on current practice Kinnat Sóley Lydon BA degree final project Iceland Academy of the Arts Department of Design and Architecture Designing Devanagari type: The effect of technological restrictions on current practice Kinnat Sóley Lydon Final project for a BA degree in graphic design Advisor: Gunnar Vilhjálmsson Graphic design Department of Design and Architecture December 2015 This thesis is a 6 ECTS final project for a Bachelor of Arts degree in graphic design. No part of this thesis may be reproduced in any form without the express consent of the author. Abstract This thesis explores the current process of designing typefaces for Devanagari, a script used to write several languages in India and Nepal. The typographical needs of the script have been insufficiently met through history and many Devanagari typefaces are poorly designed. As the various printing technologies available through the centuries have had drastic effects on the design of Devanagari, the thesis begins with an exploration of the printing history of the script. Through this exploration it is possible to understand which design elements constitute the script, and which ones are simply legacies of older technologies. Following the historic overview, the character set and unique behavior of the script is introduced. The typographical anatomy is analyzed, while pointing out specific design elements of the script. Although recent years has seen a rise of interest on the subject of Devanagari type design, literature on the topic remains sparse. This thesis references books and articles from a wide scope, relying heavily on the works of Fiona Ross and her extensive research on non-Latin typography. -

3 Writing Systems
Writing Systems 43 3 Writing Systems PETER T. DANIELS Chapters on writing systems are very rare in surveys of linguistics – Trager (1974) and Mountford (1990) are the only ones that come to mind. For a cen- tury or so – since the realization that unwritten languages are as legitimate a field of study, and perhaps a more important one, than the world’s handful of literary languages – writing systems were (rightly) seen as secondary to phonological systems and (wrongly) set aside as unworthy of study or at best irrelevant to spoken language. The one exception was I. J. Gelb’s attempt (1952, reissued with additions and corrections 1963) to create a theory of writ- ing informed by the linguistics of his time. Gelb said that what he wrote was meant to be the first word, not the last word, on the subject, but no successors appeared until after his death in 1985.1 Although there have been few lin- guistic explorations of writing, a number of encyclopedic compilations have appeared, concerned largely with the historical development and diffusion of writing,2 though various popularizations, both new and old, tend to be less than accurate (Daniels 2000). Daniels and Bright (1996; The World’s Writing Systems: hereafter WWS) includes theoretical and historical materials but is primarily descriptive, providing for most contemporary and some earlier scripts information (not previously gathered together) on how they represent (the sounds of) the languages they record. This chapter begins with a historical-descriptive survey of the world’s writ- ing systems, and elements of a theory of writing follow. -

Guide to Sanskrit Pronunciation There Is an Audio Companion to This You Document, in Which Can Hear These Words Pronounced
Guide to Sanskrit Pronunciation There is an audio companion to this you document, in which can hear these words pronounced. It AnandaYoga.org is available at . Tips a nd Tec hniques When a Sanskrit word is written using s, English letter it is transliteration called . Since the set of vowels and consonants in Sanskrit are different from those of English, reading transliterated Sanskrit can be a challenge. The following tips and techniques p will hel you read transliterated Sanskrit, and help you get an idea of how it should be pronounced. Before y ou b egin It is very useful to take a moment and clear your mind of any notions of how to pronounce a transliterated Sanskrit t word. Jus focus on the word in front of you and try not to lengthen vowels or stress a syllable based on past habits or other influences. Tip 1: Kn ow t he l ong a nd s hort v owel sounds In English, a vowel sound can either be short (e.g. foot) or long (e.g. cool). Sanskrit also short has and long vowel . sounds The problem is, it is hard to find out just by looking at the spelling, which vowel s is long and which one i short. Let’s take an example: a yoga posture is called ‘asana’ in Sanskrit. If you make the second ‘a’ long, then it becomes ‘a-‐saa-‐na’, which is incorrect. If you ’ make the first ‘a long, then it becomes ‘aa-‐sa-‐ na’, which is correct. In this document, we will write long vowels , using uppercase letters and short vowels using lower-‐case letters.