1 Writing Sanskrit
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
Pos. KE QA GE GA Initial ᠬ ᠭ Medial Final
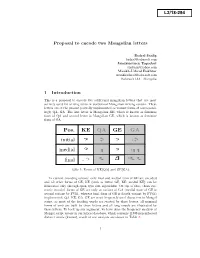
Proposal to encode two Mongolian letters Badral Sanlig [email protected] Jamiyansuren Togoobat [email protected] Munkh-Uchral Enkhtur [email protected] Bolorsoft LLC, Mongolia 1 Introduction This is a proposal to encode two additional mongolian letters that are most actively used for writing texts in traditional Mongolian writing system. These letters are at the present partially implemented as variant forms of correspond- ingly QA, GA. The first letter is Mongolian KE, which is known as feminine form of QA and second letter is Mongolian GE, which is known as feminine form of GA. Pos. KE QA GE GA ᠬ ᠭ initial medial final - Table 1: Forms of KE(QA) and GE(GA). In current encoding scheme, only final and medial form of GE are encoded and all other forms of GE, KE (such as initial GE, KE, medial KE) can be illustrated only through open type font algorithms. On top of that, those cur- rently encoded forms of GE are only as variant of GA (medial form of GE is second variant by FVS1, whereas final form of GE is fourth variant by FVS3) implemented. QA, KE, GA, GE are most frequently used characters in Mongol script, as most of the heading words are started by these letters, all nominal forms of verb are built by these letters and all long vowels are illustrated by these letters. To back up our argument, we have done the frequency analysis of Mongol script letters in our lexical database, which contains 41808 non-inflected distinct words (lemma), result of our analysis are shown in Table 2. -

Kannada Versus Sanskrit: Hegemony, Power and Subjugation Dr
================================================================== Language in India www.languageinindia.com ISSN 1930-2940 Vol. 17:8 August 2017 UGC Approved List of Journals Serial Number 49042 ================================================================ Kannada versus Sanskrit: Hegemony, Power and Subjugation Dr. Meti Mallikarjun =================================================================== Abstract This paper explores the sociolinguistic struggles and conflicts that have taken place in the context of confrontation between Kannada and Sanskrit. As a result, the dichotomy of the “enlightened” Sanskrit and “unenlightened” Kannada has emerged among Sanskrit-oriented scholars and philologists. This process of creating an asymmetrical relationship between Sanskrit and Kannada can be observed throughout the formation of the Kannada intellectual world. This constructed dichotomy impacted the Kannada world in such a way that without the intellectual resource of Sanskrit, the development of the Kannada intellectual world is considered quite impossible. This affirms that Sanskrit is inevitable for Kannada in every respect of its sociocultural and philosophical formations. This is a very simple contention, and consequently, Kannada has been suffering from “inferiority” both in the cultural and philosophical development contexts. In spite of the contributions of Prakrit and Pali languages towards Indian cultural history, the Indian cultural past is directly connected to and by and large limited to the aspects of Sanskrit culture and philosophy alone. The Sanskrit language per se could not have dominated or subjugated any of the Indian languages. But its power relations with religion and caste systems are mainly responsible for its domination over other Indian languages and cultures. Due to this sociolinguistic hegemonic structure, Sanskrit has become a language of domination, subjugation, ideology and power. This Sanskrit-centric tradition has created its own notion of poetics, grammar, language studies and cultural understandings. -

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Social Transformation of Pakistan Under Urdu Language
Social Transformations in Contemporary Society, 2021 (9) ISSN 2345-0126 (online) SOCIAL TRANSFORMATION OF PAKISTAN UNDER URDU LANGUAGE Dr. Sohaib Mukhtar Bahria University, Pakistan [email protected] Abstract Urdu is the national language of Pakistan under article 251 of the Constitution of Pakistan 1973. Urdu language is the first brick upon which whole building of Pakistan is built. In pronunciation both Hindi in India and Urdu in Pakistan are same but in script Indian choose their religious writing style Sanskrit also called Devanagari as Muslims of Pakistan choose Arabic script for writing Urdu language. Urdu language is based on two nation theory which is the basis of the creation of Pakistan. There are two nations in Indian Sub-continent (i) Hindu, and (ii) Muslims therefore Muslims of Indian sub- continent chanted for separate Muslim Land Pakistan in Indian sub-continent thus struggled for achieving separate homeland Pakistan where Muslims can freely practice their religious duties which is not possible in a country where non-Muslims are in majority thus Urdu which is derived from Arabic, Persian, and Turkish declared the national language of Pakistan as official language is still English thus steps are required to be taken at Government level to make Urdu as official language of Pakistan. There are various local languages of Pakistan mainly: Punjabi, Sindhi, Pashto, Balochi, Kashmiri, Balti and it is fundamental right of all citizens of Pakistan under article 28 of the Constitution of Pakistan 1973 to protect, preserve, and promote their local languages and local culture but the national language of Pakistan is Urdu according to article 251 of the Constitution of Pakistan 1973. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Indic Loanwords In Tocharian B, Local Markedness, And The Animacy
Indic Loanwords in Tocharian B, Local Markedness, and the Animacy Hierarchy Francesco Burroni and Michael Weiss (Department of Linguistics, Cornell University) A question that is rarely addressed in the literature devoted to Language Contact is: how are nominal forms borrowed when the donor and the recipient language both possess rich inflectional morphology? Can nominal forms be borrowed from and in different cases? What are the decisive factors shaping the borrowing scenario? In this paper, we frame this question from the angle of a case study involving two ancient Indo-European languages: Tocharian and Indic (Sanskrit, Prakrit(s)). Most studies dedicated to the topic of loanwords in Tocharian B (henceforth TB) have focused on borrowings from Iranian (e.g. Tremblay 2005), but little attention has been so far devoted to forms borrowed from Indic, perhaps because they are considered uninteresting. We argue that such forms, however, are of interest for the study of Language Contact. A remarkable feature of Indic borrowings into TB is that a-stems are borrowed in TB as e-stems when denoting animate referents, but as consonant (C-)stems when denoting inanimate referents, a distribution that was noticed long ago by Mironov (1928, following Staёl-Holstein 1910:117 on Uyghur). In the literature, however, one finds no reaction to Mironov’s idea. By means of a systematic study of all the a-stems borrowed from Indic into TB, we argue that the trait [+/- animate] of the referent is, in fact, a very good predictor of the TB shape of the borrowing, e.g. male personal names from Skt.