Conference Program Includes a Wide Range of Stimulating Papers, Posters and Works-In-Progress, and Other Presentations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Manual for Language Test Development and Examining
Manual for Language Test Development and Examining For use with the CEFR Produced by ALTE on behalf of the Language Policy Division, Council of Europe © Council of Europe, April 2011 The opinions expressed in this work are those of the authors and do not necessarily reflect the official policy of the Council of Europe. All correspondence concerning this publication or the reproduction or translation of all or part of the document should be addressed to the Director of Education and Languages of the Council of Europe (Language Policy Division) (F-67075 Strasbourg Cedex or [email protected]). The reproduction of extracts is authorised, except for commercial purposes, on condition that the source is quoted. Manual for Language Test Development and Examining For use with the CEFR Produced by ALTE on behalf of the Language Policy Division, Council of Europe Language Policy Division Council of Europe (Strasbourg) www.coe.int/lang Contents Foreword 5 3.4.2 Piloting, pretesting and trialling 30 Introduction 6 3.4.3 Review of items 31 1 Fundamental considerations 10 3.5 Constructing tests 32 1.1 How to define language proficiency 10 3.6 Key questions 32 1.1.1 Models of language use and competence 10 3.7 Further reading 33 1.1.2 The CEFR model of language use 10 4 Delivering tests 34 1.1.3 Operationalising the model 12 4.1 Aims of delivering tests 34 1.1.4 The Common Reference Levels of the CEFR 12 4.2 The process of delivering tests 34 1.2 Validity 14 4.2.1 Arranging venues 34 1.2.1 What is validity? 14 4.2.2 Registering test takers 35 1.2.2 Validity -

Exploring the Dynamics of Second Language Writing
CY147/Kroll-FM CY147/Kroll 0 521 82292 0 January 15, 2003 12:46 Char Count= 0 Exploring the Dynamics of Second Language Writing Edited by Barbara Kroll California State University, Northridge v CY147/Kroll-FM CY147/Kroll 0 521 82292 0 January 15, 2003 12:46 Char Count= 0 published by the press syndicate of the university of cambridge The Pitt Building, Trumpington Street, Cambridge, United Kingdom cambridge university press The Edinburgh Building, Cambridge CB2 2RU, UK 40 West 20th Street, New York, NY 10011-4211, USA 477 Williamstown Road, Port Melbourne, VIC 3207, Australia Ruiz de Alarcon´ 13, 28014 Madrid, Spain Dock House, The Waterfront, Cape Town 8001, South Africa http://www.cambridge.org C Cambridge University Press 2003 This book is in copyright. Subject to statutory exception and to the provisions of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. First published 2003 Printed in the United States of America Typefaces Sabon 10.5/12 pt. and Arial System LATEX2ε [TB] A catalog record for this book is available from the British Library. Library of Congress Cataloging in Publication data Exploring the dynamics of second language writing / edited by Barbara Kroll. p. cm. – (The Cambridge applied linguistics series) Includes bibliographical references and index. ISBN 0-521-82292-0 (hardback) – ISBN 0-521-52983-2 (pbk.) 1. Language and languages – Study and teaching. 2. Composition (Language arts) 3. Rhetoric – Study and teaching. I. Kroll, -

Language Requirements
Language Policy NB: This Language Policy applies to applicants of the 20J and 20D MBA Classes. For all other MBA Classes, please use this document as a reference only and be sure to contact the MBA Admissions Office for confirmation. Last revised in October 2018. Please note that this Language Policy document is subject to change regularly and without prior notice. 1 Contents Page 3 INSEAD Language Proficiency Measurement Scale Page 4 Summary of INSEAD Language Requirements Page 5 English Proficiency Certification Page 6 Entry Language Requirement Page 7 Exit Language Requirement Page 8 FL&C contact details Page 9 FL&C Language courses available Page 12 FL&C Language tests available Page 13 Language Tuition Prior to starting the MBA Programme Page 15 List of Official Language Tests recognised by INSEAD Page 22 Frequently Asked Questions 2 INSEAD Language Proficiency Measurement Scale INSEAD uses a four-level scale which measures language competency. This is in line with the Common European Framework of Reference for language levels (CEFR). Below is a table which indicates the proficiency needed to fulfil INSEAD language requirement. To be admitted to the MBA Programme, a candidate must be fluent level in English and have at least a practical level of knowledge of a second language. These two languages are referred to as your “Entry languages”. A candidate must also have at least a basic level of understanding of a third language. This will be referred to as “Exit language”. LEVEL DESCRIPTION INSEAD REQUIREMENTS Ability to communicate spontaneously, very fluently and precisely in more complex situations. -
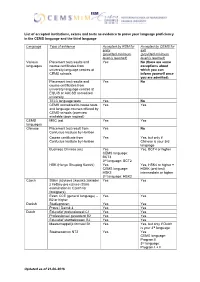
List of Accepted Institutions, Exams and Tests As Evidence to Prove Your Language Proficiency in the CEMS Language and the Third Language
List of accepted institutions, exams and tests as evidence to prove your language proficiency in the CEMS language and the third language Language Type of evidence Accepted by RSM for Accepted by CEMS for entry exit (provided minimum (provided minimum level is reached) level is reached) Various Placement test results and Yes No (there are some languages course certificates from exceptions about university language centres at which you can CEMS schools inform yourself once you are admitted) Placement test results and Yes No course certificates from university language centres at EQUIS or AACSB accredited university TELC language tests Yes No CEMS accredited in-house tests Yes Yes and language courses offered by CEMS-schools (overview available upon request) CEMS MBC test Yes Yes languages Chinese Placement test result from Yes No Confucius Institute by Hanban Course certificate from Yes Yes, but only if Confucius Institute by Hanban Chinese is your 3rd language Business Chinese test Yes Yes, BCT4 or higher CEMS language: BCT3 3rd language: BCT2 HSK (Hanyu Shuiping Kaoshi) Yes Yes, HSK4 or higher + CEMS language: HSKK (oral test) HSK3 intermediate or higher 3rd language: HSK2 Czech Státní jazyková zkouška základní Yes Yes z češtiny pro cizince (State examination in Czech for foreigners) Exam CCE (general language) – Yes Yes B2 or higher Danish Studieprøven Yes Yes Prøve i Dansk 3 Yes Yes Dutch Educatief professioneel C1 Yes Yes Professioneel gevorderd B2 Yes Yes Educatief startbekwaam B2 Yes Yes Maatschappelijk formeel B1 Yes Yes, but only -

Studies and Essays on Learning, Teaching and Assessing L2 Writing in Honour of Alister Cumming
Studies and Essays on Learning, Teaching and Assessing L2 Writing in Honour of Alister Cumming Studies and Essays on Learning, Teaching and Assessing L2 Writing in Honour of Alister Cumming Edited by A. Mehdi Riazi, Ling Shi and Khaled Barkaoui Studies and Essays on Learning, Teaching and Assessing L2 Writing in Honour of Alister Cumming Edited by A. Mehdi Riazi, Ling Shi and Khaled Barkaoui This book first published 2020 Cambridge Scholars Publishing Lady Stephenson Library, Newcastle upon Tyne, NE6 2PA, UK British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library Copyright © 2020 by A. Mehdi Riazi, Ling Shi and Khaled Barkaoui and contributors All rights for this book reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owner. ISBN (10): 1-5275-4814-7 ISBN (13): 978-1-5275-4814-5 TABLE OF CONTENTS Preface ..................................................................................................... viii Section 1: Learning to Write in a Second Language Introduction ................................................................................................ 2 On the Interface between Second Language Writing and Learning A. Mehdi Riazi, Macquarie University Chapter 1 .................................................................................................... 8 L2 Writing and L2 Learning: -

ALTE Framework 2019
ALTE Framework 2019 A1 A2 B1 B2 C1 C2 Language Organisation Pre-A1 ALTE Breakthrough ALTE Level 1 ALTE Level 2 ALTE Level 3 ALTE Level 4 ALTE Level 5 Euskararen Gaitasun Agiria (EGA) • Re-audit Nov 2021 Basque Government Eusko Jaurlaritza Basque Euskara Euskararen Gaitasun Agiria (EGA) • Re-audit pending Government of Navarre Gobierno de Navarra Standardised Test in Bulgarian as a Foreign Sofia University St. Language B2 Kliment Ohridski – • Re-audit March 2019 Department for Language Teaching - Bulgarian DLTIS Български език Софийски университет "Св. Климент Охридски" – Департамент за езиково обучение – ДЕО Version date: 05/02/2019 ALTE Framework 2019 A1 A2 B1 B2 C1 C2 Language Organisation Pre-A1 ALTE Breakthrough ALTE Level 1 ALTE Level 2 ALTE Level 3 ALTE Level 4 ALTE Level 5 Nivell superior de català Catalan Generalitat of Catalonia • Audit pending Català Generalitat de Catalunya Charles University in The Czech Language The Czech Language The Czech Language The Czech Language The Czech Language Prague, Institute for Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Language and A1 A2 B1 B2 C1 Czech Preparatory Studies • Re-audit Jan 2021 • Re-audit Jan 2021 • Re-audit Jan 2021 • Re-audit Jan 2021 • Re-audit Jan 2021 (ILPS) Čeština Univerzita Karlova v Praze, Ústav jazykové a odborné přípravy, (ÚJOP UK) Prøve i Dansk 1 (PD1) Prøve i Dansk 2 (PD2) Prøve i Dansk 3 (PD3) • • • The Ministry for Re-audit Oct 2022 Re-audit Oct 2022 Re-audit Oct 2022 Danish Foreigners and Integration -

Types of Documents Confirming the Knowledge of a Foreign Language by Foreigners
TYPES OF DOCUMENTS CONFIRMING THE KNOWLEDGE OF A FOREIGN LANGUAGE BY FOREIGNERS 1. Diplomas of completion of: 1) studies in the field of foreign languages or applied linguistics; 2) a foreign language teacher training college 3) the National School of Public Administration (KSAP). 2. A document issued abroad confirming a degree or a scientific title – certifies the knowledge of the language of instruction 3. A document confirming the completion of higher or postgraduate studies conducted abroad or in Poland - certifies the knowledge of the language only if the language of instruction was exclusively a foreign language. 4. A document issued abroad that is considered equivalent to the secondary school-leaving examination certificate - certifies the knowledge of the language of instruction 5. International Baccalaureate Diploma. 6. European Baccalaureate Diploma. 7. A certificate of passing a language exam organized by the following Ministries: 1) the Ministry of Foreign Affairs; 2) the ministry serving the minister competent for economic affairs, the Ministry of Cooperation with Foreign Countries, the Ministry of Foreign Trade and the Ministry of Foreign Trade and Marine Economy; 3) the Ministry of National Defense - level 3333, level 4444 according to the STANAG 6001. 8. A certificate confirming the knowledge of a foreign language, issued by the KSAP as a result of linguistic verification proceedings. 9. A certificate issued by the KSAP confirming qualifications to work on high-rank state administration positions. 10. A document confirming -

New Directions for L2 Research
NEW DIRECTIONS FOR L2 RESEARCH Edited by SARAH RANSDELL Florida Atlantic University, USA & MARIE-LAURE BARBIER University of Lyon, France II TABLE OF CONTENTS PREFACE v Gert Rijlaarsdam AN INTRODUCTION TO NEW DIRECTIONS 1 FOR RESEARCH IN L2 WRITING Sarah Ransdell & Marie-Laure Barbier CRITICAL EXAMINATION OF L2 WRITING 11 PROCESS RESEARCH Julio Roca De Larios, Liz Murphy, & Javier Marin BUILDING AN EMPIRICALLY-BASED MODEL 49 OF EFL LEARNERS’ WRITING PROCESSES Miyuki Sasaki THE RELATIONSHIPS BETWEEN BILINGUAL 81 CHILDREN’S READING AND WRITING IN THEIR TWO LANGUAGES Aydin Durgunoğlu, Montserrat Mir, & Sofia Ariño-Martin LINGUISTIC KNOWLEDGE, METACOGNITIVE KNOWLEDGE 101 AND RETRIEVAL SPEED IN L1, L2, AND EFL WRITING: A structural equation modelling approach Rob Schoonen, Amos van Gelderen, Kees de Glopper, Jan Hulstijn, Patrick Snellings, Annegien Simis, & Marie Stevenson EARLY EXPOSURE TO AN L2 PREDICTS GOOD L1 123 AS WELL AS GOOD L2 WRITING Rosario Arecco & Sarah Ransdell THE EFFECTS OF TRAINING A GOOD WORKING 133 MEMORY STRATEGY ON L1 and L2 WRITING Sarah Ransdell, Beverly Lavelle, & Michael Levy A COMPARISON BETWEEN NOTETAKING IN L1 145 AND L2 BY UNDERGRADUATE STUDENTS Martine Faraco, Marie-Laure Barbier & Annie Piolat AN INTRODUCTION TO NEW DIRECTIONS FOR RESEARCH IN L2 WRITING iii COLLABORATIVE WRITING IN L2: 169 THE EFFECT OF GROUP INTERACTION ON TEXT QUALITY Folkert Kuiken & Ineke Vedder INVESTIGATING LEARNERS’ GOALS 179 IN THE CONTEXT OF ADULT SECOND-LANGUAGE WRITING Alister Cumming, Michael Busch, & Ally Zhou WHEN AND WHY TALKING CAN MAKE WRITING HARDER 179 Margaret Franken & Stephen Haslett A PROBLEM-POSING APPROACH TO USING 179 NATIVE LANGUAGE WRITING IN ENGLISH LITERACY INSTRUCTION Elizabeth Quintero REFERENCES 179 AUTHOR INDEX 179 SUBJECT INDEX 179 LIST OF CONTRIBUTORS 179 PREFACE GERT RIJLAARSDAM University of Amsterdam & Utrecht University, the Netherlands Multilingualism is becoming the default in our global world. -

Relating Language Examinations to the CEFR: a Manual
January 2009 Relating Language Examinations to the Common European Framework of Reference for Languages: Learning, Teaching, Assessment (CEFR) A Manual Language Policy Division, Strasbourg www.coe.int/lang Contents List of Figures Page iii List of Tables Page v List of Forms Page vii Preface Page ix Chapter 1: The CEFR and the Manual Page 1 Chapter 2: The Linking Process Page 7 Chapter 3: Familiarisation Page 17 Chapter 4: Specification Page 25 Chapter 5: Standardisation Training and Benchmarking Page 35 Chapter 6: Standard Setting Procedures Page 57 Chapter 7: Validation Page 89 References Page 119 Appendix A Forms and Scales for Description and Specification (Ch. 1 & 4) Page 122 A1: Salient Characteristics of CEFR Levels (Ch. 1) Page 123 A2: Forms for Describing the Examination (Ch. 4) Page 126 A3: Specification: Communicative Language Activities (Ch. 4) Page 132 A4: Specification: Communicative Language Competence (Ch. 4) Page 142 A5: Specification: Outcome of the Analysis (Ch. 4) Page 152 Appendix B Content Analysis Grids (Ch.4) B1: CEFR Content Analysis Grid for Listening & Reading Page 153 B2: CEFR Content Analysis Grids for Writing and Speaking Tasks Page 159 Appendix C Forms and Scales for Standardisation & Benchmarking (Ch. 5) Page 181 Reference Supplement: Section A: Summary of the Linking Process Section B: Standard Setting Section C: Classical Test Theory Section D: Qualitative Analysis Methods Section E: Generalisability Theory Section F: Factor Analysis Section G: Item Response Theory Section H: Test Equating i ii List of -

The Hallmarks of L2 Writing Viewed Through the Prism of Translation Universals
Linguistic Research 35(Special Edition), 171-205 DOI: 10.17250/khisli.35..201809.007 The hallmarks of L2 writing viewed through the prism of translation universals*1 Younghee Cheri Lee (Yonsei University) Lee, Younghee Cheri. 2018. The hallmarks of L2 writing viewed through the prism of translation universals. Linguistic Research 35(Special Edition), 171-205. Rooted in a perception that second language (L2) writing bears neither resemblance with nontranslated counterparts nor relation to translation, this article explores the untested terrain of revealing lexical and textual attributes unique to L2 writers' texts, thus identifying their linguistic qualities from the angle of translation universals. Setting plausible parameters to discern translational instances related to lexical and syntactical choices, this article argues that idiosyncratic properties shared by translated English may typify the hallmarks of L2 writing produced by non-anglophone scholars in English disciplines. By compiling the comparable corpora of English journal abstracts consisting of 638,764 tokens, it is shown how salient translational features arise in expert L2 writers' texts in compliance with corpus linguistics. Kruskal-Wallis tests are applied to evaluate linguistic indices that make Korean scholars' L2 writing distinct from native scholars’ original writing. On a substantial level, a general presumption on the interrelatedness between expert L2 writers' English and translational English has turned out to be warranted, meaning that Korean scholars' L2 writing can be marked by universals of simplification, normalization, explicitation, and convergence in their broad outlines. It can be deducible from the findings that regardless of L2 proficiency levels, second language writers may be destined to go through a ‘mental translation' as an inescapable cognitive mechanism during the L2 writing process, which in turn renders translational manifestations pervasive in the ‘product’ of L2 writing. -

Introduction
Dana Ferris, who was not even born when some of the veteran contributors to this collection began their teaching careers, is nonetheless considerably older than Paul Kei Matsuda, the other “junior” contributor, who wrote the epilogue. Starstruck while attending the 1996 TESOL colloquium, which initiated the work leading to this collection, Dana has since moved on to the more mature stage of simple respect and admiration. Introduction Dana Ferris California State University, Sacramento Beware of “complacency that puts our critical faculties to sleep.”—Ilona Leki Ask students what they want, think, and need.—Joy Reid A “questionable practice”: Error correction and identi‹cation. —Alister Cumming “The ‹ve-paragraph essay: Tool, or torpedo?”—Ann M. Johns I had “a tendency to overload students.”—Melinda Erickson We need to “value qualitative research.” —Linda Lonon Blanton “I can’t believe I did that!”—Barbara Kroll How a “New Kid on the Block” Ended Up in This Book These wonderful “sound bites,” and other provocative quotations and ideas, were swirling through my head as I left the 1996 TESOL colloquium on writing that gave rise to this collection. Like any veteran conference-goer, I have experi- enced papers and panels that have been good, bad, and indif- ferent. Over the years, I have arrived at the view that if at a professional conference I hear just one really memorable 2 ESL Composition Tales paper or colloquium panel, a presentation that stimulates or challenges my thinking or teaching, the trip is a success. I left that Chicago colloquium, orchestrated by Barbara Kroll, with a sigh of satisfaction, knowing that my modest hopes had once again been ful‹lled and that the money spent, the time away (I missed my younger daughter’s second birthday), and the frozen toes and ‹ngertips (a lifelong Californian, I have limited tolerance for a Chicago winter) had been justi‹ed. -

Lourdes Ortega Curriculum Vitae
Lourdes Ortega Curriculum Vitae Updated: August 2019 Department of Linguistics 1437 37th Street NW Box 571051 Poulton Hall 250 Georgetown University Washington, DC 20057-1051 Department of Linguistics Fax (202) 687-6174 E-mail: [email protected] Webpage: https://sites.google.com/a/georgetown.edu/lourdes-ortega/ EDUCATION 2000 Ph.D. in Second Language Acquisition. University of Hawai‘i at Mānoa, Department of Second Language Studies, USA. 1995 M.A. in English as a Second Language. University of Hawai‘i at Mānoa, Department of Second Language Studies, USA. 1993 R.S.A. Dip., Diploma for Overseas Teachers of English. Cambridge University/UCLES, UK. 1987 Licenciatura in Spanish Philology. University of Cádiz, Spain. EMPLOYMENT since 2012 Professor, Georgetown University, Department of Linguistics. 2004-2012 Professor (2010-2012), Associate Professor (2006-2010), Assistant Professor (2004-2006), University of Hawai‘i at Mānoa, Department of Second Language Studies. 2002-2004 Assistant Professor (tenure-track), Northern Arizona University, Department of English. 2000-2002 Assistant Professor (tenure-track). Georgia State University, Department of Applied Linguistics and ESL. 1999-2000 Visiting Instructor of Applied Linguistics, Georgetown University, Department of Linguistics. 1994-1998 Research and Teaching Graduate Assistant, University of Hawai‘i at Mānoa, College of Languages, Linguistics, and Literature. 1987-1993 Instructor of Spanish, Instituto Cervantes of Athens, Greece. FELLOWSHIPS 2018: Distinguished Visiting Fellow at the Graduate Center, City University of New York, Advanced Research Collaborative (ARC). August through December, 2018. 2010: External Senior Research Fellow at the Freiburg Institute of Advanced Studies (FRIAS), University of Freiburg. One-semester residential fellowship at FRIAS to carry out project titled Pathways to multicompetence: Applying usage-based and constructionist theories to the study of interlanguage development.