Rater Expertise in a Second Language Speaking Assessment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Manual for Language Test Development and Examining
Manual for Language Test Development and Examining For use with the CEFR Produced by ALTE on behalf of the Language Policy Division, Council of Europe © Council of Europe, April 2011 The opinions expressed in this work are those of the authors and do not necessarily reflect the official policy of the Council of Europe. All correspondence concerning this publication or the reproduction or translation of all or part of the document should be addressed to the Director of Education and Languages of the Council of Europe (Language Policy Division) (F-67075 Strasbourg Cedex or [email protected]). The reproduction of extracts is authorised, except for commercial purposes, on condition that the source is quoted. Manual for Language Test Development and Examining For use with the CEFR Produced by ALTE on behalf of the Language Policy Division, Council of Europe Language Policy Division Council of Europe (Strasbourg) www.coe.int/lang Contents Foreword 5 3.4.2 Piloting, pretesting and trialling 30 Introduction 6 3.4.3 Review of items 31 1 Fundamental considerations 10 3.5 Constructing tests 32 1.1 How to define language proficiency 10 3.6 Key questions 32 1.1.1 Models of language use and competence 10 3.7 Further reading 33 1.1.2 The CEFR model of language use 10 4 Delivering tests 34 1.1.3 Operationalising the model 12 4.1 Aims of delivering tests 34 1.1.4 The Common Reference Levels of the CEFR 12 4.2 The process of delivering tests 34 1.2 Validity 14 4.2.1 Arranging venues 34 1.2.1 What is validity? 14 4.2.2 Registering test takers 35 1.2.2 Validity -
Jetaudio Music Player Free Download for Android
Jetaudio music player free download for android Continue More Images Replace the Old Stock Media Player in Your Android with jetAudio HD Music Player.jetAudio HD Music Player is a free app for Android that is a powerful audio player and is touted to be one of the most rated and most downloaded audio player for your smartphone. The player maintains a good mix of audio files such as wav, .mp3, .ogg, .flac, .m4a, .mpc, .tta, .wv, .ape, .mod, .spx, .opus, .wma and more. It also offers you various effects and enhancements that include reverb and X-Bass, plus it gives you a 10 group equalizer with 32 presets for a different listening experience. Then there are also playback controls like, playback speed control and crossface. The paid version offers a lot more features and you're taking down ads. Download jetAudio HD Music Player and enjoy the fun and convenient features it offers. Please check out Tom's Guide for more interesting apps and the latest tips on Android.And you can go visit Tom's Guide Forums for any concerns about your Android. Download フォロ offers a high-quality sound experience combined with attractive equalizer options, this app has assets that can make your music session unique and enjoyable. jetAudio Basic plays almost all types of sound media and can modify them. The app has a well-organized and neat interface. jetAudio Basic offers all the settings and options that a good media player for Android devices should have with some extra extras such as sound effects, 32 equalizer presets, social media sharing, so you can post what you are currently listening to on Twitter and Facebook, and many other useful options that can enhance your music listening experience. -

31 out of 50 Tested Download.Com Applications Bundle Pups (Based on Research by the Emsisoft Lab, Feb 2015)
List of Shame: 31 out of 50 tested Download.com applications bundle PUPs (based on research by the Emsisoft Lab, Feb 2015) Application Potentially Unwanted Program 1. Avast Free Antivirus Dropbox 2. KMPlayer Spigot browser extensions - shopping aid, newtab Aid, slick savings, Ebay shopping assistant, search protect, offers to change homepage and search engine to Yahoo during installation, Pro PC Cleaner, and Wajam 3. AVG Free Antivirus AVG SafeGuard - changes homepage and search engine to AVG secure search, web tuneup 4. YAC (Yet Another Cleaner) Considered to be a PUP itself 5. CCleaner Chrome 6. Advanced System Care Driver Booster, iObit Uninstaller 7. Free Youtube Download Skype, PC Reviver 8. YTD Video Downloader Spigot browser extensions - slick savings, browser Error assistant, Ebay shopping assistant, search protect, offers to change home and startup pages to Yahoo during installation, and GeniusBox 9. iObit Uninstaller Advanced System Care 10. Download App Spigot browser extensions - shopping new tab aid, slick savings, Ebay shopping assistant, search protect, offers to change homepage and search engine to Yahoo during installation, and Pro PC Cleaner 11. 3DP Chip nProtect, SpeedUpMyPC 2015 12. GOM Media Player Skype, Clean Water 13. Virtual DJ 8 14. Malwarebytes Anti-Malware 15. PhotoScape Google Drive, PC Mechanic 16. Start Menu 8 17. Driver Booster iObit Malware Fighter 18. VLC Media Player 19. Ad Aware Free Antivirus Ad Aware Web Companion - changes home page and search engine to secure search 20. Minitool Partition Wizard 21. Irfan View 22. mHotspot Tuneup Utilities, PC Mechanic, Safer Browser, Clean Water, Driver Max 23. Panda Free Antivirus Panda Security Toolbar - changes default homepage and search engine to Yahoo 24. -

Language Requirements
Language Policy NB: This Language Policy applies to applicants of the 20J and 20D MBA Classes. For all other MBA Classes, please use this document as a reference only and be sure to contact the MBA Admissions Office for confirmation. Last revised in October 2018. Please note that this Language Policy document is subject to change regularly and without prior notice. 1 Contents Page 3 INSEAD Language Proficiency Measurement Scale Page 4 Summary of INSEAD Language Requirements Page 5 English Proficiency Certification Page 6 Entry Language Requirement Page 7 Exit Language Requirement Page 8 FL&C contact details Page 9 FL&C Language courses available Page 12 FL&C Language tests available Page 13 Language Tuition Prior to starting the MBA Programme Page 15 List of Official Language Tests recognised by INSEAD Page 22 Frequently Asked Questions 2 INSEAD Language Proficiency Measurement Scale INSEAD uses a four-level scale which measures language competency. This is in line with the Common European Framework of Reference for language levels (CEFR). Below is a table which indicates the proficiency needed to fulfil INSEAD language requirement. To be admitted to the MBA Programme, a candidate must be fluent level in English and have at least a practical level of knowledge of a second language. These two languages are referred to as your “Entry languages”. A candidate must also have at least a basic level of understanding of a third language. This will be referred to as “Exit language”. LEVEL DESCRIPTION INSEAD REQUIREMENTS Ability to communicate spontaneously, very fluently and precisely in more complex situations. -

Opções De Vagas
Anexo - Vagas Disponíveis UNIVERSIDADE PAÍS VAGAS IDIOMA 1 PROFICIENCIA IDIOMA 1 OU IDIOMA 2 PROFICIÊNCIA IDIOMA 2 Alemão: Atestado ou Exame de proficiência no Inglês: Atestado ou Exame de Eberhard Karls Universität Tübingen Alemanha 5 Alemão OU Inglês mínimo nível B2 proficiência no mínimo nível B2 DSH 2, DSH 3, TestDAF (com 4 ou 5 pontos em todas as áreas, no mínimo 16 pontos) ou equivalente; German Ernst-Abbe-Fachhochschule Jena Alemanha 5 Alemão language proficiency: upper intermediate (e.g. Goethe certificate B2, TestDaF 3-4) Inglês: Atestado ou Exame de Hochschule Neu-Ulm Alemanha 3 Alemão Atestado ou Exame de proficiência no mínimo nível B2 OU Inglês proficiência no mínimo nível B2 Alemão: Atestado ou Exame de proficiência no Inglês: Atestado ou Exame de Hochschule Ruhr West Alemanha 5 Alemão OU Inglês mínimo nível B1 proficiência no mínimo nível B1 Alemão: Atestado ou Exame de proficiência no Inglês: Atestado ou Exame de Hochschule Worms Alemanha 3 Alemão OU Inglês mínimo nível B1 proficiência no mínimo nível B2 DSH 2, DSH 3, TestDaF 4 em todas as habilidades, Inglês: Atestado ou Exame de Westfälische Wilhelms-Universität Münster Alemanha 2 Alemão Goethe-Zertifikat C2, UNIcert-certificate III and IV ou OU Inglês Atestado ou Exame de proficiência no mínimo nível B2 proficiência no mínimo nível B2 Alemão: Atestado ou Exame de proficiência no Inglês: Atestado ou Exame de FHWien der WKW Áustria 1 Alemão OU Inglês mínimo B2 proficiência no mínimo nível B2 Francês: Atestado ou Exame de proficiência no Inglês: Atestado ou Exame de Ecole Pratique des Hautes Etudes Commerciales Bélgica 2 Francês OU Inglês mínimo nível B2 proficiência no mínimo nível B2 Francês: Atestado ou Exame de proficiência no Inglês: Atestado ou Exame de Université Libre de Bruxelles Bélgica 2 Francês OU Inglês mínimo nível B2 proficiência no mínimo nível B2 TOEFL (Test of English as a Foreign Language) iBT (internet-based test) score of 80 or PBT (paper-based test) score of 550. -

English Language Testing in US Colleges and Universities
DOCUMENT RESUME ED 331 284 FL 019 122 AUTHOR Douglas, Dan, Ed. TITLE English Language Testing in U.S. Colleges and Universities. INSTITUTION National Association for Foreign Student Affairs, Washington, D.C. SPONS AGENCY United States information Agency, Washington, DC. Advisory, Teaching, and Specialized Programs Div. REPORT NO /SBN-0-912207-56-6 PUB DATE 90 NOTE 106p. PUB TYPE Collected Works - General (020) EDRS PRICE MF01/PC05 Plus Postage. DESCRIPTORS Admission Criteria; College Admission; *English (Second Language); Foreign Countries; *Foreign Students; Higher Education; *Language Tests; Questionnaires; Second Language Programs; Standardized Tests; Surveys; *Teaching Assistants; *Test Interpretation; Test Results; Writing (Composition); Writing Tests IDENTIFIERS United Kingdom ABSTRACT A collection of essays and research reports addresses issues in the testing of English as a Second Language (ESL) among foreign students in United States colleges and universities. They include the following: "Overview of ESL Testing" (Ralph Pat Barrett); "English Language Testing: The View from the Admissions Office" (G. James Haas); "English Language Testing: The View from the English Teaching Program" (Paul J. Angelis); "Standardized ESL Tests Used in U.S. Colleges and Universities" (Harold S. Madsen); "British Tests of English as a Foreign Language" (J. Charles Alderson); "ESL Composition Testing" (Jane Hughey); "The Testing and Evaluation of International Teaching Assistants" (Barbara S. Plakans, Roberta G. Abraham); and "Interpreting Test Scores" (Grant Henning). Appended materials include addresses for use in obtaining information about English language testing, and the questionnaire used in a survey of higher education institutions, reported in one of the articles. (ME) *********************************************************************** Reproductions supplied by EDRS are the best that can be made from the original document. -
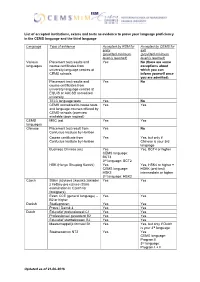
List of Accepted Institutions, Exams and Tests As Evidence to Prove Your Language Proficiency in the CEMS Language and the Third Language
List of accepted institutions, exams and tests as evidence to prove your language proficiency in the CEMS language and the third language Language Type of evidence Accepted by RSM for Accepted by CEMS for entry exit (provided minimum (provided minimum level is reached) level is reached) Various Placement test results and Yes No (there are some languages course certificates from exceptions about university language centres at which you can CEMS schools inform yourself once you are admitted) Placement test results and Yes No course certificates from university language centres at EQUIS or AACSB accredited university TELC language tests Yes No CEMS accredited in-house tests Yes Yes and language courses offered by CEMS-schools (overview available upon request) CEMS MBC test Yes Yes languages Chinese Placement test result from Yes No Confucius Institute by Hanban Course certificate from Yes Yes, but only if Confucius Institute by Hanban Chinese is your 3rd language Business Chinese test Yes Yes, BCT4 or higher CEMS language: BCT3 3rd language: BCT2 HSK (Hanyu Shuiping Kaoshi) Yes Yes, HSK4 or higher + CEMS language: HSKK (oral test) HSK3 intermediate or higher 3rd language: HSK2 Czech Státní jazyková zkouška základní Yes Yes z češtiny pro cizince (State examination in Czech for foreigners) Exam CCE (general language) – Yes Yes B2 or higher Danish Studieprøven Yes Yes Prøve i Dansk 3 Yes Yes Dutch Educatief professioneel C1 Yes Yes Professioneel gevorderd B2 Yes Yes Educatief startbekwaam B2 Yes Yes Maatschappelijk formeel B1 Yes Yes, but only -

ALTE Framework 2019
ALTE Framework 2019 A1 A2 B1 B2 C1 C2 Language Organisation Pre-A1 ALTE Breakthrough ALTE Level 1 ALTE Level 2 ALTE Level 3 ALTE Level 4 ALTE Level 5 Euskararen Gaitasun Agiria (EGA) • Re-audit Nov 2021 Basque Government Eusko Jaurlaritza Basque Euskara Euskararen Gaitasun Agiria (EGA) • Re-audit pending Government of Navarre Gobierno de Navarra Standardised Test in Bulgarian as a Foreign Sofia University St. Language B2 Kliment Ohridski – • Re-audit March 2019 Department for Language Teaching - Bulgarian DLTIS Български език Софийски университет "Св. Климент Охридски" – Департамент за езиково обучение – ДЕО Version date: 05/02/2019 ALTE Framework 2019 A1 A2 B1 B2 C1 C2 Language Organisation Pre-A1 ALTE Breakthrough ALTE Level 1 ALTE Level 2 ALTE Level 3 ALTE Level 4 ALTE Level 5 Nivell superior de català Catalan Generalitat of Catalonia • Audit pending Català Generalitat de Catalunya Charles University in The Czech Language The Czech Language The Czech Language The Czech Language The Czech Language Prague, Institute for Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Certificate Exam (CCE) Language and A1 A2 B1 B2 C1 Czech Preparatory Studies • Re-audit Jan 2021 • Re-audit Jan 2021 • Re-audit Jan 2021 • Re-audit Jan 2021 • Re-audit Jan 2021 (ILPS) Čeština Univerzita Karlova v Praze, Ústav jazykové a odborné přípravy, (ÚJOP UK) Prøve i Dansk 1 (PD1) Prøve i Dansk 2 (PD2) Prøve i Dansk 3 (PD3) • • • The Ministry for Re-audit Oct 2022 Re-audit Oct 2022 Re-audit Oct 2022 Danish Foreigners and Integration -

Types of Documents Confirming the Knowledge of a Foreign Language by Foreigners
TYPES OF DOCUMENTS CONFIRMING THE KNOWLEDGE OF A FOREIGN LANGUAGE BY FOREIGNERS 1. Diplomas of completion of: 1) studies in the field of foreign languages or applied linguistics; 2) a foreign language teacher training college 3) the National School of Public Administration (KSAP). 2. A document issued abroad confirming a degree or a scientific title – certifies the knowledge of the language of instruction 3. A document confirming the completion of higher or postgraduate studies conducted abroad or in Poland - certifies the knowledge of the language only if the language of instruction was exclusively a foreign language. 4. A document issued abroad that is considered equivalent to the secondary school-leaving examination certificate - certifies the knowledge of the language of instruction 5. International Baccalaureate Diploma. 6. European Baccalaureate Diploma. 7. A certificate of passing a language exam organized by the following Ministries: 1) the Ministry of Foreign Affairs; 2) the ministry serving the minister competent for economic affairs, the Ministry of Cooperation with Foreign Countries, the Ministry of Foreign Trade and the Ministry of Foreign Trade and Marine Economy; 3) the Ministry of National Defense - level 3333, level 4444 according to the STANAG 6001. 8. A certificate confirming the knowledge of a foreign language, issued by the KSAP as a result of linguistic verification proceedings. 9. A certificate issued by the KSAP confirming qualifications to work on high-rank state administration positions. 10. A document confirming -

Relating Language Examinations to the CEFR: a Manual
January 2009 Relating Language Examinations to the Common European Framework of Reference for Languages: Learning, Teaching, Assessment (CEFR) A Manual Language Policy Division, Strasbourg www.coe.int/lang Contents List of Figures Page iii List of Tables Page v List of Forms Page vii Preface Page ix Chapter 1: The CEFR and the Manual Page 1 Chapter 2: The Linking Process Page 7 Chapter 3: Familiarisation Page 17 Chapter 4: Specification Page 25 Chapter 5: Standardisation Training and Benchmarking Page 35 Chapter 6: Standard Setting Procedures Page 57 Chapter 7: Validation Page 89 References Page 119 Appendix A Forms and Scales for Description and Specification (Ch. 1 & 4) Page 122 A1: Salient Characteristics of CEFR Levels (Ch. 1) Page 123 A2: Forms for Describing the Examination (Ch. 4) Page 126 A3: Specification: Communicative Language Activities (Ch. 4) Page 132 A4: Specification: Communicative Language Competence (Ch. 4) Page 142 A5: Specification: Outcome of the Analysis (Ch. 4) Page 152 Appendix B Content Analysis Grids (Ch.4) B1: CEFR Content Analysis Grid for Listening & Reading Page 153 B2: CEFR Content Analysis Grids for Writing and Speaking Tasks Page 159 Appendix C Forms and Scales for Standardisation & Benchmarking (Ch. 5) Page 181 Reference Supplement: Section A: Summary of the Linking Process Section B: Standard Setting Section C: Classical Test Theory Section D: Qualitative Analysis Methods Section E: Generalisability Theory Section F: Factor Analysis Section G: Item Response Theory Section H: Test Equating i ii List of -

User's Manual CW200
PORTABLE DIGITAL AUDIO PLAYER iAUDIO CW200 User’s Manual CW200 Manufactured by Distributed by CW200 COPYRIGHT and TRADEMARKS Copyright ©2003 JetAudio, Inc. All rights reserved. No part of this manual may be used or reproduced in any manner whatsoever without the prior written consent of JetAudio, Inc. Distribution or commercial usage of JetShell, JetAudio, and JetVoiceMail, and all MP3 files created by using these software is strictly prohibited without the prior written consent of COWON Systems, Inc. iAUDIO is a registered trademark of COWON Systems, Inc. Microsoft, Windows and the Windows logo are registered trademarks of Microsoft Corporation. All other trademarks and brand names are the property of their respective proprietors. All rights reserved by JetAudio, Inc. 2003 2 CW200 CW200 WARRANTY LIMITED WARRANTY JetAudio, Inc., is commited to providing you the flawless products by using the best materials and the workmanship available. Our warranty period is one year from the date of purchase. If these products prove defective during this warranty period, call Customer Support in order to obtain a Return Authorization Number. BE SURE TO HAVE YOUR PROOF OF PURCHASE AND A BARCODE FROM THE PRODUCT'S PACKAGING ON HAND WHEN CALLING. RETURN REQUESTS CANNOT BE PROCESSED WITHOUT PROOF OF PURCHASE. When returning a product, mark the Return Authorization Number clearly on the outside of the package and include your original proof of purchase. All customers located outside of the United States of America shall be responsible for shipping and handling charges. IN NO EVENT SHALL COWON’S LIABILITY EXCEED THE PRICE PAID FOR THE PRODUCTS FROM DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES RESULTING FROM THE USE OF THE PRODUCT, ITS ACCOMPANYING SOFTWARE, OR ITS DOCUMENTATION. -

User's Guide Ver. 1.4 EN
User’s Guide ver. 1.4 EN COWON + Copyright Notice Thank you for purchasing a COWON product. We do our utmost to deliver DIGITAL PRIDE to our customers. This manual contains information on how to use the product and the precautions to take during use. If you familiarize yourself with this manual, you will have a more enjoyable digital experience. Introduction to website + The address of the product-related website is http://www.COWON.com. + You can download the latest information on our products and the most recent firmware updates from our website. + For first-time users, we provide an FAQ section and a user guide. + Become a member of the website by using the serial number on the back of the product to register the product. You will then be a registered member. + Once you become a registered member, you can use the one-to-one enquiry service to receive online customer advice. You can also receive information on new products and events by e-mail. + Copyright Notice General + COWON is a registered trademark of COWON SYSTEMS, INC. + COWON SYSTEMS, INC. owns the copyright to this manual, and any unauthorized distribution of its contents, whether in part or in its entirety, is strictly prohibited. + COWON SYSTEMS, INC. complies with laws and regulations related to records, disks, videos and games. Users are also encouraged to comply with the relevant laws and regulations. + As soon as you purchase the product, visit the website (http://www.COWON.com), and become a registered mem- ber. You will benefit from various member services. + This manual is based on product specifications, and various exemplary texts, illustrations, pictures, detailed functions and H/W and S/W specifications contained herein can be altered without any prior notice by the copyright owner.