Pioneer: Verifying Code Integrity and Enforcing Untampered Code Execution on Legacy Systems∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

8Th Generation Intel® Core™ Processor Datasheet, Vol. 1
8th and 9th Generation Intel® Core™ Processor Families and Intel® Xeon® E Processor Family Datasheet, Volume 1 of 2 Supporting 8th Generation Intel® Core™ Processor Families, Intel® Pentium® Processors, Intel® Celeron® Processors for U/H/S Platforms, formerly known as Coffee Lake. Supporting 9th Generation Intel® Core™ Processor Families, Processors for S Platforms, formerly known as Coffee Lake Refresh For Datasheet Volume 2, Refer to Doc ID: 337345 October 2018 Revision 002 Document Number: 337344-002 Legal Lines and Disclaimers You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel technologies' features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com. Intel technologies may require enabled hardware, specific software, or services activation. Check with your system manufacturer or retailer. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. -

Intel® Architecture Instruction Set Extensions and Future Features
Intel® Architecture Instruction Set Extensions and Future Features Programming Reference May 2021 319433-044 Intel technologies may require enabled hardware, software or service activation. No product or component can be absolutely secure. Your costs and results may vary. You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. All product plans and roadmaps are subject to change without notice. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not “commercial” names and not intended to function as trademarks. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be ob- tained by calling 1-800-548-4725, or by visiting http://www.intel.com/design/literature.htm. Copyright © 2021, Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. -
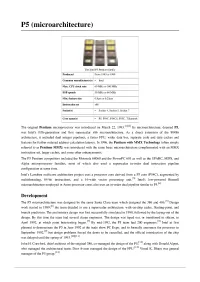
P5 (Microarchitecture)
P5 (microarchitecture) The Intel P5 Pentium family Produced From 1993 to 1999 Common manufacturer(s) • Intel Max. CPU clock rate 60 MHz to 300 MHz FSB speeds 50 MHz to 66 MHz Min. feature size 0.8pm to 0.25pm Instruction set x86 Socket(s) • Socket 4, Socket 5, Socket 7 Core name(s) P5. P54C, P54CS, P55C, Tillamook The original Pentium microprocessor was introduced on March 22, 1993.^^ Its microarchitecture, deemed P5, was Intel's fifth-generation and first superscalar x86 microarchitecture. As a direct extension of the 80486 architecture, it included dual integer pipelines, a faster FPU, wider data bus, separate code and data caches and features for further reduced address calculation latency. In 1996, the Pentium with MMX Technology (often simply referred to as Pentium MMX) was introduced with the same basic microarchitecture complemented with an MMX instruction set, larger caches, and some other enhancements. The P5 Pentium competitors included the Motorola 68060 and the PowerPC 601 as well as the SPARC, MIPS, and Alpha microprocessor families, most of which also used a superscalar in-order dual instruction pipeline configuration at some time. Intel's Larrabee multicore architecture project uses a processor core derived from a P5 core (P54C), augmented by multithreading, 64-bit instructions, and a 16-wide vector processing unit. T31 Intel's low-powered Bonnell [4i microarchitecture employed in Atom processor cores also uses an in-order dual pipeline similar to P5. Development The P5 microarchitecture was designed by the same Santa Clara team which designed the 386 and 486.^ Design work started in 1989;^ the team decided to use a superscalar architecture, with on-chip cache, floating-point, and branch prediction. -

The Intel X86 Microarchitectures Map Version 1.1
The Intel x86 Microarchitectures Map Version 1.1 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Alternative Names: iAPX 86 Alternative Names: 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) Series: 8086, 8088 (cheaper) Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) • Launch: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • Cheaper: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) • Lower-power: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 (Celeron), Northwood-128 (Celeron) • Desktop lower-performance: -

Intel Pentium Processor Users Manual Volume 1 1993
~ • INTEL. ~~ " Founded in 1968 to pursue the integration of large numbers of transistors onto tiny silicon chips, Intel's history has been marked by a remarkable number of scientific breakthroughs and innovations. In 1971, Intel introduced the 4004, the first microprocessor. Containing 2300 transistors, this first commercially available computer-on-a-chip is primitive compared with today's million-plus transistor products. Innovations such as the microprocessor, the erasable programmable read-only memory (EPROM) and the dynamic random access memory (DRAM) revolutionized electronics by making integrated circuits the mainstay of both consumer and business computing products. Over the last two-and-a-half decades, Intel's business has evolved and today the company's focus is on delivering an extensive line of component, module and system-level building block products to the computer industry. The company's product line covers a broad spectrum, and includes microprocessors, flash memory, microcontrollers, a broad line of PC enhancement and local area network products, multimedia technology products, and massively parallel supercomputers. Intel's 32-bit X86 architecture, represented by the Inte1386™ and Inte1486™ microprocessor families, is the de facto standard of modem business computing in millions of PCs worldwide. Intel has over 26,000 employees located in offices and manufacturing facilities around the world. Today, Intel is the largest semiconductor company in the world. LITERATURE To order Intel literature or obtain literature pricing information in the U.S. and Canada call or write Intel Literature Sales. In Europe and other international locations, please contact your local sales office or distributor. INTEL LITERATURE SALES In the U.S. -

The Intel X86 Microarchitectures Map Version 3.2
The Intel x86 Microarchitectures Map Version 3.2 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P6 (1995, 0.50 to 0.35 μm) Skylake (2015, 14 nm) NetBurst (2000 , 180 to 130 nm) Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: i686 Alternative Names: SKL (Desktop and Mobile), SKX (Server) (Note : all U and Y processors are MCPs) P5 (1993, 0.80 to 0.35 μm) Alternative Names: Pentium 4, Pentium IV, P4 • 16-bit data bus: Series: Series: Pentium Pro (used in desktops and servers) Series: Alternative Names: Pentium, Series: 8086 (iAPX 86) • Desktop/Server: i386DX Variant: Klamath (1997, 0.35 μm) • Desktop: Desktop 6th Generation Core i5 (i5-6xxx, S-H) 80586, 586, i586 • Desktop: Pentium 4 1.x (except those with a suffix, Willamette, 180 nm), Pentium 4 2.0 (Willamette, 180 • 8-bit data bus: • Desktop lower-performance: i386SX Alternative Names: Pentium II, PII • Desktop higher-performance: Desktop 6th Generation Core i7 (i7-6xxx, S-H), Desktop 7th Generation Core i7 X (i7-7xxxX, X), Desktop 7th Series: nm) 8088 (iAPX 88) • Mobile: i386SL, 80376, i386EX, Series: Pentium II 233/266/300 steppings C0 and C1 (Klamath, used in desktops) Generation Core i9 X (i7-7xxxXE, i7-7xxxX, X), Desktop 9th Generation Core i7 X (i7-9xxxX, X, 14 nm++?), Desktop 9th Generation Core i9 X • Desktop/Server: P5, P54C • Desktop higher-performance: Pentium 4 1.xA (Northwood, 130 nm), Pentium 4 2.x (except 2.0, 2.40A, i386CXSA, i386SXSA, i386CXSB New instructions: Deschutes (1998, 0.25 to 0.18 μm) (i7-9xxxXE, i7-9xxxX, X, 14 nm++?), Xeon W-3175X (W, 14 nm++?) -

OVERVIEW Intel Corporation Is an American Multinational Corporation
OVERVIEW ⌂ Introduced April 1, 1974. ⌂ Intel Corporation is an American multinational corporation headquartered in ⌂ 10 times faster than 8008. Santa Clara, California. ⌂ Used in the Altair 8800, Traffic light controller, cruise missile. ⌂ It is the inventor of the x86 series of microprocessors, the processors found in ⌂ Characteristics most personal computers. • 6 mm process ⌂ Intel Corporation, founded on July 18, 1968, is a portmanteau of • 4500 transistors Integrated Electronics (the fact that "intel" is the term for intelligence • 2 MHz information also made the name appropriate). • 8-bit word size ⌂ Intel sells its products and solutions to original equipment manufacturers • 40-pin DIP package (OEMs) and original design manufacturers (ODMs). Intel 8086/8088 ⌂ The 80486 architecture, for example, supports clock rates of from 33 to 66 ⌂ A 16 bit processors Introduced June 8, 1978(8086) and Introduced June 1, MHz. 1979(8088). ⌂ Because Intel discovered that it couldn't trademark its CPU numbers, it shifted ⌂ First used in the Compaq Deskpro IBM PC-compatible computers. Later used to a naming scheme, starting with the Pentium processors. Intel's sixth- in portable computing, and in the IBM PS/2 Model 25 and Model 30. Also generation chip is called the Pentium Pro. used in the AT&T PC6300 / Olivetti M24, a popular IBM PC-compatible HISTORY (predating the IBM PS/2 line). ⌂ Intel was originally founded in Mountain View, California in 1968 by Gordon E. ⌂ NASA used original 8086 CPUs on equipment for ground-based maintenance Moore, Robert Noyce, Arthur Rock and Max Palevsky. of the Space Shuttle Discovery until the end of the space shuttle program in ⌂ Intel's third employee was Andy Grove, a chemical engineer, who later ran the 2011. -

Pentium® Processor Specification Update
intet Pentium® Processor Specification Update Release Date: March, 1995 Order Number: 242480-002 Information is this document is provided in connection with Intel products. Intel assumes no liability whatsoever, including infringement of any patent or copyright, for sale and use of Intel products except as provided in Intel's Terms and Conditions of Sale for such products. Intel retains the right to make changes to these specifications at any time, without notice. Contact your local Intel sales office or your distributor to obtain the latest specifications before placing your product order. MDS is an ordering code only and is not used as a product name or trademark of Intel Corporation. 'Other brands and names are the property of their respective owners. tSince publication of documents referenced in this document, registration of the Pentium, OverDrive, and iCOMP trademarks has been issued to Intel Corporation. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature, may be obtained from: Intel Corporation P.O. Box 7641 Mt. Prospect, IL 60056-7641 or call 1-800-879-4683 ®INTEL CORPORATION 1995 intaL PENTIUM@ PROCESSOR SPECIFICATION UPDATE CONTENTS REVISION HISTORY ............................................................................................................................................... v PREFACE ................................................................................................................................................................ vii Part -

Számítógépes Architektúrák II
Számítógépes architektúrák II. Komló Csaba MÉDIAINFORMATIKAI KIADVÁNYOK Számítógépes architektúrák II. Komló Csaba Eger, 2013 Korszerű információtechnológiai szakok magyaror- szági adaptációja TÁMOP-4.1.2-A/1-11/1-2011-0021 Lektorálta: Nyugat-magyarországi Egyetem Regionális Pedagógiai Szolgáltató és Kutató Központ Felelős kiadó: dr. Kis-Tóth Lajos Készült: az Eszterházy Károly Főiskola nyomdájában, Egerben Vezető: Kérészy László Műszaki szerkesztő: Nagy Sándorné Tartalom 1. Bevezetés .......................................................................... 13 1.1. Célkitűzések, kompetenciák a tantárgy teljesítésének feltételei . 13 1.1.1. Célkitűzés .............................................................................. 13 1.1.2. Kompetenciák ....................................................................... 13 1.1.3. A tantárgy teljesítésének feltételei ...................................... 13 1.2. A kurzus tartalma ..................................................................... 14 2. Informatikai alapfogalmak ................................................ 17 2.1. Célkitűzések és kompetenciák .................................................. 17 2.2. Tananyag ................................................................................. 17 2.2.1. Számítások gépesítése .......................................................... 17 2.2.2. A számítógép megszületése ................................................. 19 2.2.3. Neumann-elvek .................................................................... 19 2.2.4. -

A Brief History of Intel CPU Microarchitectures
All the contents in this presentation come from the public Internet, belong to their respective owners. This work is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License. A Brief History of Intel CPU Microarchitectures Xiao-Feng Li [email protected] 2013-02-10 Notes • The materials are only for my personal use. – Not representing Intel opinions – Not a complete list of Intel microprocessors – Not specifications of Intel microprocessors Brief history of Intel CPU uArch - 2013/02/10 2 [email protected] Intel Pre-Processor Devices • Intel founded in 1968 • Intel 3101, 1969 – Intel first product – World first solid state memory device – 16 x 4-bit SRAM • Intel 1103, 1970 – World first DRAM product, 1K-bit PMOS – Used in HP 9800 series computers – By 1972, world bestselling memory chip, defeating magnetic memory Brief history of Intel CPU uArch - 2013/02/10 3 [email protected] Moore’s Law • Moore, Gordon E. (1965). "Cramming more components onto integrated circuits" (PDF). Electronics Magazine. pp. 4. – “The complexity for minimum component costs has increased at a rate of roughly a factor of two per year.” – Moore refined it to “every two years” in 1975 – Also quoted as “every 18 months” by David House, (referring to performance) – Most popular formulation: #transistors/IC • Carver Mead coined it as Moore's law around 1970 – “Tall & Thin engineers” • Ultimate limit of Moore’s Law – No one knows – How to use the capability? Resource limit? Brief history of Intel CPU uArch - 2013/02/10 4 [email protected] -

7I Laptop (15")
7i Laptop (15") PREMIUM PERFORMANCE. A precision-crafted chassis jacketed in high-grade aluminum, Lenovo™ Legion 7i has been meticulously machined to unload maximum damage. Don’t compromise on lightning-fast high-refresh panels, the tactile click-feel of Lenovo’s revolutionary TrueStrike keyboard, ultra-long battery life or the cool-to-the-touch sense of Legion Coldfront 2.0 with Vapor Chamber Technology and dual burn support which pushes the CPU and GPU together for maximum performance. Beneath the refined surface hides a battle-ready beast, with up to 10th Generation Intel® Core™ i9 HK Series processors, up to NVIDIA® GeForce RTX™ graphics, up to 16 GB 3466 MHz Overclocked DDR4 memory and M.2 NVMe PCIe SSD storage. WHY YOU SHOULD BUY THE LENOVO LEGION 7i LAPTOP (15") Game ready RTX. It’s On. Experience gaming With up to the latest immersion like NVIDIA GeForce RTX™ never-before with graphics behind you, up to 10th Generation you can enjoy the depth Intel® Core™ i9HK and visual fidelity of processors, 16 GB real-time ray-tracing. 3466 MHz DDR4 RTX Gaming, It’s On. memory, and 1 TB M.2 NVMe PCIe SSD storage all thermally optimized via Legion Coldfront 2.0. Set your Strike hard, sights higher strike true Cinema-like gaming Enjoy hair-trigger comes standard with accuracy via the up to a 15.6" FHD Legion 7i’s TrueStrike WVA, 240 Hz refresh Keyboard which sports rate, <1 ms response soft-landing switches, time*, NVIDIA® G-Sync 1.3 mm key travel, technology, Dolby 100% anti-ghosting, Vision™ and VESA <1 ms response times DisplayHDR 400 and over 16 million supported display.