Jingwei Zhuo*, Chang Liu, Jiaxin Shi, Jun Zhu, Ning Chen and Bo Zhang Motivations & Preliminaries Particle Degeneracy Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chieftains Into Ancestors: Imperial Expansion and Indigenous Society in Southwest China
1 Chieftains into Ancestors: Imperial Expansion and Indigenous Society in Southwest China. David Faure and Ho Ts’ui-p’ing, editors. Vancouver and Toronto: University of British Columbia Press, 2013. ISBN: 9780774823692 The scholars whose essays appear in this volume all attempt, in one way or another, to provide a history of southern and southwestern China from the perspective of the people who lived and still live there. One of the driving forces behind the impressive span of research across several cultural and geographical areas is to produce or recover the history(ies) of indigenous conquered people as they saw and experienced it, rather than from the perspective of the Chinese imperial state. It is a bold and fresh look at a part of China that has had a long-contested relationship with the imperial center. The essays in this volume are all based on extensive fieldwork in places ranging from western Yunnan to western Hunan to Hainan Island. Adding to the level of interest in these pieces is the fact that these scholars also engage with imperial-era written texts, as they interrogate the different narratives found in oral (described as “ephemeral”) rituals and texts written in Chinese. In fact, it is precisely the nexus or difference between these two modes of communicating the past and the relationship between the local and the central state that energizes all of the scholarship presented in this collection of essays. They bring a very different understanding of how the Chinese state expanded its reach over this wide swath of territory, sometimes with the cooperation of indigenous groups, sometimes in stark opposition, and how indigenous local traditions were, and continue to be, reified and constructed in ways that make sense of the process of state building from local perspectives. -

Narrative Inquiry Into Chinese International Doctoral Students
Volume 16, 2021 NARRATIVE INQUIRY INTO CHINESE INTERNATIONAL DOCTORAL STUDENTS’ JOURNEY: A STRENGTH-BASED PERSPECTIVE Shihua Brazill Montana State University, Bozeman, [email protected] MT, USA ABSTRACT Aim/Purpose This narrative inquiry study uses a strength-based approach to study the cross- cultural socialization journey of Chinese international doctoral students at a U.S. Land Grant university. Historically, we thought of socialization as an institu- tional or group-defined process, but “journey” taps into a rich narrative tradi- tion about individuals, how they relate to others, and the identities that they carry and develop. Background To date, research has employed a deficit perspective to study how Chinese stu- dents must adapt to their new environment. Instead, my original contribution is using narrative inquiry study to explore cross-cultural socialization and mentor- ing practices that are consonant with the cultural capital that Chinese interna- tional doctoral students bring with them. Methodology This qualitative research uses narrative inquiry to capture and understand the experiences of three Chinese international doctoral students at a Land Grant in- stitute in the U.S. Contribution This study will be especially important for administrators and faculty striving to create more diverse, supportive, and inclusive academic environments to en- hance Chinese international doctoral students’ experiences in the U.S. Moreo- ver, this study fills a gap in existing research by using a strength-based lens to provide valuable practical insights for researchers, practitioners, and policymak- ers to support the unique cross-cultural socialization of Chinese international doctoral students. Findings Using multiple conversational interviews, artifacts, and vignettes, the study sought to understand the doctoral experience of Chinese international students’ experience at an American Land Grant University. -

THE UNIVERSITY of BRITISH COLUMBIA Curriculum Vitae for Faculty Members
THE UNIVERSITY OF BRITISH COLUMBIA Curriculum Vitae for Faculty Members Date: April 20, 2019 Initials:NN 1. SURNAME:Nan FIRST NAME:Ning MIDDLE NAME(S): 2. DEPARTMENT/SCHOOL:Accounting and Information Systems 3. FACULTY:Sauder School of Business 4. PRESENT RANK:Assistant Professor SINCE:June 2012 5. POST-SECONDARY EDUCATION University or Institution Degree Subject Area Dates University of Michigan PhD1 Business Administration August, 2006 University of Minnesota MA Mass Communication July, 2002 Peking University BA Advertising July, 1999 Special Professional Qualifications 6. EMPLOYMENT RECORD (a) Prior to coming to UBC University, Company or Organization Rank or Title Dates University of Oklahoma Assistant Professor 2006-2012 (b) At UBC Rank or Title Dates Assistant Professor 2012-present (c) Date of granting of tenure at U.B.C.: 1 Title of Dissertation: Unintended Consequences in Central-Remote Office Arrangement: A Study Coupling Laboratory Experiments with Multi-Agent Modeling. Supervisor: Prof. Judith Olson Updated April 20, 2019 - Page 2/15 7. LEAVES OF ABSENCE University, Company or Organization Type of Leave Dates at which Leave was taken 8. TEACHING (a) Areas of special interest and accomplishments My teaching experience includes undergraduate, MBA, and PhD level courses. I seek to deliver both handson technology skills and critical thinking abilities to students. To date, I have taught the following topics: • E-business (digital business) • Database management • Introduction to Management Information Systems • Complexity theory -

Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation
Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation A/L Krishnan Thiinash Bachelor of Information Technology March 2015 A/L Selvaraju Theeban Raju Bachelor of Commerce January 2015 A/P Balan Durgarani Bachelor of Commerce with Distinction March 2015 A/P Rajaram Koushalya Priya Bachelor of Commerce March 2015 Hiba Mohsin Mohammed Master of Health Leadership and Aal-Yaseen Hussein Management July 2015 Aamer Muhammad Master of Quality Management September 2015 Abbas Hanaa Safy Seyam Master of Business Administration with Distinction March 2015 Abbasi Muhammad Hamza Master of International Business March 2015 Abdallah AlMustafa Hussein Saad Elsayed Bachelor of Commerce March 2015 Abdallah Asma Samir Lutfi Master of Strategic Marketing September 2015 Abdallah Moh'd Jawdat Abdel Rahman Master of International Business July 2015 AbdelAaty Mosa Amany Abdelkader Saad Master of Media and Communications with Distinction March 2015 Abdel-Karim Mervat Graduate Diploma in TESOL July 2015 Abdelmalik Mark Maher Abdelmesseh Bachelor of Commerce March 2015 Master of Strategic Human Resource Abdelrahman Abdo Mohammed Talat Abdelziz Management September 2015 Graduate Certificate in Health and Abdel-Sayed Mario Physical Education July 2015 Sherif Ahmed Fathy AbdRabou Abdelmohsen Master of Strategic Marketing September 2015 Abdul Hakeem Siti Fatimah Binte Bachelor of Science January 2015 Abdul Haq Shaddad Yousef Ibrahim Master of Strategic Marketing March 2015 Abdul Rahman Al Jabier Bachelor of Engineering Honours Class II, Division 1 -

Self-Study Syllabus on Chinese Foreign Policy
Self-Study Syllabus on Chinese Foreign Policy www.mandarinsociety.org PrefaceAbout this syllabus with China’s rapid economic policymakers in Washington, Tokyo, Canberra as the scale and scope of China’s current growth, increasing military and other capitals think about responding to involvement in Africa, China’s first overseas power,Along and expanding influence, Chinese the challenge of China’s rising power. military facility in Djibouti, or Beijing’s foreign policy is becoming a more salient establishment of the Asian Infrastructure concern for the United States, its allies This syllabus is organized to build Investment Bank (AIIB). One of the challenges and partners, and other countries in Asia understanding of Chinese foreign policy in that this has created for observers of China’s and around the world. As China’s interests a step-by-step fashion based on one hour foreign policy is that so much is going on become increasingly global, China is of reading five nights a week for four weeks. every day it is no longer possible to find transitioning from a foreign policy that was In total, the key readings add up to roughly one book on Chinese foreign policy that once concerned principally with dealing 800 pages, rarely more than 40–50 pages will provide a clear-eyed assessment of with the superpowers, protecting China’s for a night. We assume no prior knowledge everything that a China analyst should know. regional interests, and positioning China of Chinese foreign policy, only an interest in as a champion of developing countries, to developing a clearer sense of how China is To understanding China’s diplomatic history one with a more varied and global agenda. -
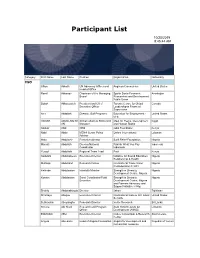
Participant List
Participant List 10/20/2019 8:45:44 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Ramil Abbasov Chariman of the Managing Spektr Socio-Economic Azerbaijan Board Researches and Development Public Union Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Amr Abdallah Director, Gulf Programs Educaiton for Employment - United States EFE HAGAR ABDELRAHM African affairs & SDGs Unit Maat for Peace, Development Egypt AN Manager and Human Rights Abukar Abdi CEO Juba Foundation Kenya Nabil Abdo MENA Senior Policy Oxfam International Lebanon Advisor Mala Abdulaziz Executive director Swift Relief Foundation Nigeria Maryati Abdullah Director/National Publish What You Pay Indonesia Coordinator Indonesia Yussuf Abdullahi Regional Team Lead Pact Kenya Abdulahi Abdulraheem Executive Director Initiative for Sound Education Nigeria Relationship & Health Muttaqa Abdulra'uf Research Fellow International Trade Union Nigeria Confederation (ITUC) Kehinde Abdulsalam Interfaith Minister Strength in Diversity Nigeria Development Centre, Nigeria Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Shahlo Abdunabizoda Director Jahon Tajikistan Shontaye Abegaz Executive Director International Insitute for Human United States Security Subhashini Abeysinghe Research Director Verite -

Representing Talented Women in Eighteenth-Century Chinese Painting: Thirteen Female Disciples Seeking Instruction at the Lake Pavilion
REPRESENTING TALENTED WOMEN IN EIGHTEENTH-CENTURY CHINESE PAINTING: THIRTEEN FEMALE DISCIPLES SEEKING INSTRUCTION AT THE LAKE PAVILION By Copyright 2016 Janet C. Chen Submitted to the graduate degree program in Art History and the Graduate Faculty of the University of Kansas in partial fulfillment of the requirements for the degree of Doctor of Philosophy. ________________________________ Chairperson Marsha Haufler ________________________________ Amy McNair ________________________________ Sherry Fowler ________________________________ Jungsil Jenny Lee ________________________________ Keith McMahon Date Defended: May 13, 2016 The Dissertation Committee for Janet C. Chen certifies that this is the approved version of the following dissertation: REPRESENTING TALENTED WOMEN IN EIGHTEENTH-CENTURY CHINESE PAINTING: THIRTEEN FEMALE DISCIPLES SEEKING INSTRUCTION AT THE LAKE PAVILION ________________________________ Chairperson Marsha Haufler Date approved: May 13, 2016 ii Abstract As the first comprehensive art-historical study of the Qing poet Yuan Mei (1716–97) and the female intellectuals in his circle, this dissertation examines the depictions of these women in an eighteenth-century handscroll, Thirteen Female Disciples Seeking Instructions at the Lake Pavilion, related paintings, and the accompanying inscriptions. Created when an increasing number of women turned to the scholarly arts, in particular painting and poetry, these paintings documented the more receptive attitude of literati toward talented women and their support in the social and artistic lives of female intellectuals. These pictures show the women cultivating themselves through literati activities and poetic meditation in nature or gardens, common tropes in portraits of male scholars. The predominantly male patrons, painters, and colophon authors all took part in the formation of the women’s public identities as poets and artists; the first two determined the visual representations, and the third, through writings, confirmed and elaborated on the designated identities. -

Howard on Qiang, 'Art, Religion and Politics in Medieval China: the Dunhuang Cave of the Zhai Family'
H-Asia Howard on Qiang, 'Art, Religion and Politics in Medieval China: The Dunhuang Cave of the Zhai Family' Review published on Sunday, January 1, 2006 Ning Qiang. Art, Religion and Politics in Medieval China: The Dunhuang Cave of the Zhai Family. Honolulu: University of Hawaii Press, 2004. xv + 178 pp. $39.00 (cloth), ISBN 978-0-8248-2703-8. Reviewed by Angela Howard (Rutgers,) Published on H-Asia (January, 2006) The Making of a Seventh-Century Buddhist Cave in Dunhuang, China: Politics or Piety This book is a case study of Dunhuang Cave 220, completed in 642 through the sponsorship of the prominent Zhai family, which continued to supervise the cave's upkeep until the tenth century. Ning Qiang has chosen the cave for several reasons; it is dated, we know the identity of its patrons, and its décor manifests stylistic and doctrinal innovations. Breaking away from sixth-century stylistic and doctrinal conventions, Cave 220 was decorated with large murals of Pure Lands or Paradises on the lateral walls, a composition of the Vimalakirti and Manjushri (the Bodhisattva of Wisdom) debate above the entrance, and a large niche in the rear wall where a group of sculpture was complemented by painted images on the niche's surrounding walls. The lay-out and décor established a model for subsequent Tang caves. Although the author emphatically states that his study gives equal weight to the textual sources of the décor, related pictorial examples, and their socio-political foundations, he emphasizes the political and social influence of patronage and tends to overlook the religious sources of the art. -

Optimal Operating Strategy for a Storage Facility
Optimal Operating Strategy for a Storage Facility by E Ning Zhai SEP 0 5 2008 B.Eng., Electrical Engineering LIBRARIES National University of Singapore, 2007 Submitted to the School of Engineering in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computation for Design and Optimization at the Massachusetts Institute of Technology SEPTEMBER 2008 0 2008 Massachusetts Institute of Technology All rights reserved I A Signature of Author ................................... ....................... School of Engineering August 14, 2008 Certified by ............ 7 .. Jo.. ......... John E. Parso ns Senior Lecturer, Sloan School of Management, Executive Director, MIT Center for Energy and Environmental Policy Research Thesis Supervisor A ccepted by ................ r ................... f ......... ................................................................. Robert M. Freund Professor in Management Science, Sloan School of Management, Codirector, Computation for Design and Optimization Program BARKER 2 Optimal Operating Strategy for a Storage Facility by Ning Zhai B.Eng., Electrical Engineering National University of Singapore, 2007 Submitted to the School of Engineering in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computation for Design and Optimization ABSTRACT In the thesis, I derive the optimal operating strategy to maximize the value of a storage facility by exploiting the properties in the underlying natural gas spot price. To achieve the objective, I investigate the optimal operating strategy under three different spot price processes: the one-factor mean reversion price process with and without seasonal factors, the one-factor geometric Brownian motion price process with and without seasonal factors, and the two-factor short-term/long-term price process with and without seasonal factors. I prove the existence of the unique optimal trigger prices, and calculate the trigger prices under certain conditions. -

Ultrasonic Vibration Assisted Manufacturing of High-Performance Materials
Ultrasonic vibration assisted manufacturing of high-performance materials by Fuda Ning, B.S., M.S. A Dissertation In Industrial, Manufacturing, and Systems Engineering Submitted to the Graduate Faculty of Texas Tech University in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY Approved Dr. Weilong Cong Chair of Committee Dr. Hong-Chao Zhang Dr. Golden Kumar Dr. George Zhuo Tan Dr. Wei Li (Dean’s Representative) Mark Sheridan Dean of the Graduate School May, 2018 Copyright 2018, Fuda Ning Texas Tech University, Fuda Ning, May 2018 To My Family and Fleeting Time. ii Texas Tech University, Fuda Ning, May 2018 ACKNOWLEDGMENTS First and foremost, I would like to express the deepest appreciation to my advisor, Dr. Weilong Cong, for his supervision and tremendous help throughout the past few years. He continually conveyed a rigorous attitude toward research and scholarship, which inspired me all the time. This dissertation would not have been completed without his professional guidance. I would like to thank my committee members, Dr. Hong-Chao Zhang, Dr. Golden Kumar, and Dr. George Zhuo Tan, for their valuable advice on my dissertation. I also want to thank Dr. Wei Li to serve as the Dean’s Representative for my defense. My sincere appreciation goes to the U.S. National Science Foundation for the financial support through award CMMI-1538381. I would like to extend my thanks to the Gradual School at Texas Tech University for the Doctoral Dissertation Completion Fellowship to enable me to devote full-time effort to finalizing this dissertation in the very last year of my Ph.D. -

Inhabiting Literary Beijing on the Eve of the Manchu Conquest
THE UNIVERSITY OF CHICAGO CITY ON EDGE: INHABITING LITERARY BEIJING ON THE EVE OF THE MANCHU CONQUEST A DISSERTATION SUBMITTED TO THE FACULTY OF THE DIVISION OF THE HUMANITIES IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY DEPARTMENT OF EAST ASIAN LANGUAGES AND CIVILIZATIONS BY NAIXI FENG CHICAGO, ILLINOIS DECEMBER 2019 TABLE OF CONTENTS LIST OF FIGURES ....................................................................................................................... iv ACKNOWLEDGEMENTS .............................................................................................................v ABSTRACT ................................................................................................................................. viii 1 A SKETCH OF THE NORTHERN CAPITAL...................................................................1 1.1 The Book ........................................................................................................................4 1.2 The Methodology .........................................................................................................25 1.3 The Structure ................................................................................................................36 2 THE HAUNTED FRONTIER: COMMEMORATING DEATH IN THE ACCOUNTS OF THE STRANGE .................39 2.1 The Nunnery in Honor of the ImperiaL Sister ..............................................................41 2.2 Ant Mounds, a Speaking SkulL, and the Southern ImperiaL Park ................................50 -

Rethinking Chinese Kinship in the Han and the Six Dynasties: a Preliminary Observation
part 1 volume xxiii • academia sinica • taiwan • 2010 INSTITUTE OF HISTORY AND PHILOLOGY third series asia major • third series • volume xxiii • part 1 • 2010 rethinking chinese kinship hou xudong 侯旭東 translated and edited by howard l. goodman Rethinking Chinese Kinship in the Han and the Six Dynasties: A Preliminary Observation n the eyes of most sinologists and Chinese scholars generally, even I most everyday Chinese, the dominant social organization during imperial China was patrilineal descent groups (often called PDG; and in Chinese usually “zongzu 宗族”),1 whatever the regional differences between south and north China. Particularly after the systematization of Maurice Freedman in the 1950s and 1960s, this view, as a stereo- type concerning China, has greatly affected the West’s understanding of the Chinese past. Meanwhile, most Chinese also wear the same PDG- focused glasses, even if the background from which they arrive at this view differs from the West’s. Recently like Patricia B. Ebrey, P. Steven Sangren, and James L. Watson have tried to challenge the prevailing idea from diverse perspectives.2 Some have proven that PDG proper did not appear until the Song era (in other words, about the eleventh century). Although they have confirmed that PDG was a somewhat later institution, the actual underlying view remains the same as before. Ebrey and Watson, for example, indicate: “Many basic kinship prin- ciples and practices continued with only minor changes from the Han through the Ch’ing dynasties.”3 In other words, they assume a certain continuity of paternally linked descent before and after the Song, and insist that the Chinese possessed such a tradition at least from the Han 1 This article will use both “PDG” and “zongzu” rather than try to formalize one term or one English translation.