Storage Systems Main Points
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

DOCUMENT RESUME ED 262 129 UD 024 466 Hawaiian Studies
DOCUMENT RESUME ED 262 129 UD 024 466 TITLE Hawaiian Studies Curriculum Guide. Grades K-1. INSTITUTION Hawaii State Dept. of Education, Honolulu. Office of Instructional Services. PUB DATE Dec 83 NOTE 316p.; For the Curriculum Guides for Grades 2,3, and 4, see UD 024 467-468, and ED 255 597. "-PUB TYPE Guides Classroom Use - Guides (For Teachers) (052) EDRS PRICE MF01/PC13 Plus Postage. DESCRIPTORS Community Resources; *Cultural Awareness; *Cultural Education; *Early Childhood Education; Grade 1; Hawaiian; *Hawaiians; Instructional Materials; Kindergarten; *Learning Activities; Pacific Americans; *Teacher Aides; Vocabulary IDENTIFIERS *Hawaii ABSTRACT This curriculum guide suggests activities and educational experiences within a Hawaiian cultural context for kindergarten and Grade 1 students in Hawaiian schools. First, a introduction-discusses the contents of the guide, the relations Hip of - the classroom teacher and the kupuna (ljawaiian-speaking elder); the identification and scheduling of Kupunas; and how to use the ide. The remainder of the guide is divided into two major sections. Each is preceded by an overview which outlines the subject areas into which Hawaiian Studies instruction is integrated; the emphases or major lesson topics taken up within each subject, area; the learning objectives addressed by the instructional activities; and a key to the unit's appendices, which provide cultural information to supplement the activities. The activities in Unit I focus on the "self" and the immediate environment. They are said to give children ___Dppor-tumit-ies to investigate and experience feelings and ideas and then to determine whether they are acceptable within classroom and home situations. The activities of Unit II involve the children in experiences dealing with the "'ohana" (family) by having them identify roles, functions, dependencies, rights, responsibilities, occupations, and other cultural characteristics of the 'ohana. -

Spanish Language Broadcasting Collection
Spanish Language Broadcasting Collection NMAH.AC.1404 IrMarie Fraticelli, Edwin A. Rodriguez, and Justine Thomas This collection received Federal support from the Latino Initiatives Pool, administered by the Smithsonian Latino Center. Archives Center, National Museum of American History P.O. Box 37012 Suite 1100, MRC 601 Washington, D.C. 20013-7012 [email protected] http://americanhistory.si.edu/archives Table of Contents Collection Overview ........................................................................................................ 1 Administrative Information .............................................................................................. 1 Arrangement..................................................................................................................... 2 Biographical / Historical.................................................................................................... 2 Scope and Contents........................................................................................................ 2 Names and Subjects ...................................................................................................... 2 Container Listing ............................................................................................................. 4 Series 1: Gilda Mirós, (bulk 1950 - 2016, undated) (bulk 1950 - 2016, undated).................................................................................................................... 4 Series 2: Hector Aguilar, 1940 - 2002, undated.................................................... -

KD-ADV49/KD-AVX44 RÉCEPTEUR DVD/CD RECEPTOR CONDVD/CD DVD/CD RECEIVER Pour L’Installationetlesraccordements,Seréféreraumanuelséparé
ENGLISH DVD/CD RECEIVER RECEPTOR CON DVD/CD RÉCEPTEUR DVD/CD ESPAÑOL KD-ADV49/KD-AVX44 FRANÇAIS For canceling the display demonstration, see page 7. Para cancelar la demonstración en pantalla, consulte la página 7. Pour annuler la démonstration des affichages, référez-vous à la page 7. For installation and connections, refer to the separate manual. For customer Use: Para la instalación y las conexiones, refiérase al manual separado. Enter below the Model No. Pour l’installation et les raccordements, se référer au manuel séparé. and Serial No. which are located on the top or bottom of the cabinet. Retain this information for future INSTRUCTIONS reference. MANUAL DE INSTRUCCIONES MANUEL D’INSTRUCTIONS Model No. Serial No. LVT1797-001B [J/C] CCover_KDADV49AVX44[JC].inddover_KDADV49AVX44[JC].indd 2 008.2.188.2.18 110:45:380:45:38 AAMM Thank you for purchasing a JVC product. Please read all instructions carefully before operation, to ensure your complete understanding and to obtain the best possible performance from the unit. IMPORTANT FOR LASER PRODUCTS 1. CLASS 1 LASER PRODUCT ENGLISH 2. CAUTION: Do not open the top cover. There are no user serviceable parts inside the unit; leave all servicing to qualified service personnel. 3. CAUTION: (For U.S.A.) Visible and/or invisible class II laser radiation when open. Do not stare into beam. (For Canada) Visible and/or invisible class 1M laser radiation when open. Do not view directly with optical instruments. 4. REPRODUCTION OF LABEL: CAUTION LABEL, PLACED OUTSIDE THE UNIT. INFORMATION (For U.S.A.) WARNINGS: This equipment has been tested and found to To prevent accidents and damage comply with the limits for a Class B digital device, pursuant to Part 15 of the FCC Rules. -

Bearmach Accessories
LAND ROVER Parts and Accessories suitable for All Land Rovers from BEARMACH Ltd SERIES 2a & 3 FRONT END PROTECTION All of our black, nylon coated steel Nudge Bars, Bull Bars and ‘A’ frames give an aggressive and purposeful look and offer improved front end protection due to their strength. Spot light mounting points are also included on accessories most. The units bolt to the existing holes on the chassis/bumper although some cutting of the front spoiler may be required. BA 119 BA 009 nudge bars INTEGRAL BUMPER & NUDGE BAR Replaces the existing bumper & uses existing fixings. Flame cut profiles with wraparounds mounted to a 14 gauge steel box bumper with a lower protector bar. 11/2” (37mm) diameter tube. Box section 21/2” x 4" (63 x 100mm). Shot blasted, etched and then black nylon coated for superior finish and TUBULAR “A” FRAME NUDGE BAR durability. This is the ultimate coating finish which endures all conditions. Weight: – 26kgs. Robust “A” Frame bar suitable for Series 3. Manufactured in 2" diameter 14 Fits all models (including 90/110). gauge steel. To fit to Series vehicles 8 holes need to be drilled. Also features Spotlight mounting facility. Will also fit air conditioned vehicles. NOTE: For vehicles fitted with side lift jacks use extension BA 2140 (optional) NOTE: For vehicles fitted with side lift jacks use extension BA 2140 (optional) BA 009 – Integral Bumper and Nudge Bar BA 119 Tubular ‘A’ Frame Nudge Bar, Black Nylon Coated. PROTECTION BAR ALSO AVAILABLE BA 119S Tubular ‘A’ Frame Nudge Bar, Polished Stainless Steel. IN STAINLESS STEEL Spotlight mounting brackets to the rear PROTECTION BAR A simple tubular bar, made from heavy gauge steel tubing. -

Discovery III Multimedia Installation V1.2
Land Rover Discovery 3 Extending the multimedia capabilities of the Discovery III An installation guide to add a GVIF interface, a rear view camera and a DVD player to your Discovery III. A www.disco3.co.uk resource Version 1.2 © Copyright discoBizz Disclaimer: this guide is for information and illustration ONLY. Any work you do on your car, either explicitly or implicitly following this guide, is at your own risk and with the understanding the steps followed below have worked for me, in my car, at my own risk and given my own knowledge of the matter and with my own disregard to potential consequences on the vehicle’s warranty. Neither the author, the website WWW.DISCO3.CO.UK, Martin Lewis or and other website forum members mentioned in this document will be held liable for any warranty consequences or any damage of any severity caused on your vehicle as a result of you choosing to follow this fictional procedure. Any trademarks, copyright or references to words or actions of individuals other than the author, are hereby acknowledged to be the property of their respective owners. The author is simply an enthusiast, with no training at all in electrical or mechanical engineering and as such some of the methods and procedures used may be far from best practice in each respective field. N.B. The modifications/additions in this document can be done separately and in varying ways/locations. I have chosen to put everything together as I did most of the work in one go. My vehicle is an HSE model, which means it was already fitted with the factory SatNav screen and the auxiliary audio input in the rear of the centre console, the wires of which I taped into to feed the head unit with the audio output from my AV sources. -

Bodsy's Brake Bible
Land Rover Discovery 3 Bodsy’s Brake Bible Ian Bodsworth Disco3Club.co.uk June 2010 Version 1.2a Change Record DATE Revision Update Notes Made By May 2010 1.2 Amended Torque Figures and bolt Ian Bodsworth sizes, cleaned up photo areas. Updated text. June 2010 1.2a Re-worded EPB adjust procedure, Ian Bodsworth updated EBP Allen key size. Added Change record © Copyright Ian Bodsworth 2010. All descriptions and photo’s contained within remain the property of the Author. Commercial images of products with copyrights acknowledged. E&OE. - Created by Bodsy – D3C Page 2 of 28 Table of Contents 1. Introduction ................................................................................................................................................................. 4 2. Tools that may be required ...................................................................................................................................... 5 3. Jacking Points and Axle Stands ............................................................................................................................... 6 4. How to change the Brake Pads - Front .................................................................................................................. 9 5. How to change the Brake Pads – Rear ................................................................................................................. 13 6. How to change the Brake Disks – Front .............................................................................................................. -

Korg TRITON Extreme Список Тембров
Korg TRITON Extreme Ñïèñîê òåìáðîâ Ìóçûêàëüíàÿ ðàáî÷àÿ ñòàíöèÿ/ñýìïëåð Îôèöèàëüíûé è ýêñêëþçèâíûé äèñòðèáüþòîð êîìïàíèè Korg íà òåððèòîðèè Ðîññèè, ñòðàí Áàëòèè è ÑÍà — êîìïàíèÿ A&T Trade. Äàííîå ðóêîâîäñòâî ïðåäîñòàâëÿåòñÿ áåñïëàòíî. Åñëè âû ïðèîáðåëè äàííûé ïðèáîð íå ó îôèöèàëüíîãî äèñòðèáüþòîðà ôèðìû Korg èëè àâòîðèçîâàííîãî äèëåðà êîìïàíèè A&T Trade, êîìïàíèÿ A&T Trade íå íåñåò îòâåòñòâåííîñòè çà ïðåäîñòàâëåíèå áåñïëàòíîãî ïåðåâîäà íà ðóññêèé ÿçûê ðóêîâîäñòâà ïîëüçîâàòåëÿ, à òàêæå çà îñóùåñòâëåíèå ãàðàíòèéíîãî ñåðâèñíîãî îáñëóæèâàíèÿ. © ® A&T Trade, Inc. Гарантийное обслуживание Ïî âñåì âîïðîñàì, ñâÿçàííûì ñ ðåìîíòîì èëè ñåðâèñíûì îáñëóæèâàíèåì ìóçûêàëüíîé ðàáî÷åé ñòàíöèè/ñýìïëåðà TRITON Extreme, îáðàùàéòåñü ê ïðåäñòàâèòåëÿì ôèðìû Korg — êîìïàíèè A&T Trade. Òåëåôîí äëÿ ñïðàâîê (095) 796-9262; e-mail: [email protected] ССооддеерржжааннииее Комбинации . 2 Программы . 6 Мультисэмплы . 11 Сэмплы ударных . 14 Наборы ударных . 18 Наборы ударных GM . 35 Пресетные / Пользовательские арпеджиаторные паттерны . 37 Шаблоны песен . 39 Пресетные паттерны . 39 Демо.песни. 39 Korg TRITON Extreme. Ñïèñîê òåìáðîâ 1 Комбинации Bank A Bank B Bank C # Name Category # Name Category # Name Category # Name Category # Name Category A000 The Piano 00 A064 Mellow Piano Pad 00 B000 Stereo Piano 00 B064 Soft Piano Pad 00 C000 The Ballade 00 A001 Film Sound Track 05 A065 Strings & Reeds 05 B001 Velo Orch. SW1 05 B065 From pp To ff 05 C001 EXP Power Orch. 05 A002 Wave Sequencer 3 09 A066 Millennium Pad 2 09 B002 RHYTHMWAVE 09 B066 Arp Factory 2 09 C002 Analog Theme -

JELLYBEAN JAM Songlist Medleys
JELLYBEAN JAM songlist Medleys (Please note Medleys cannot be broken down in form) 80s- Born To Be Alive, Shake Your Groove Thing, Don’t Leave me This way, Jessie’s Girl, Video Killed The Radio Star, Its Raining Men, You Spin me Round, Love Shack, We Built This City, My Sharona 80s2- Girls Just Wanna Have Fun, Venus, Just Can’t Get Enough, Xanadu, Hungry Like The Wolf , Funky Town. Chicks- Holiday, Step Back in Time, Lets Hear It for the Boy, Express Yourself, Finally, Better the Devil You Know Disco 1 - Blame it on the Boogie, Disco Inferno, Car Wash, Celebration, We are Family, Le Freak. Disco 2 - Jungle Boogie, Upside Down, Can’t Stand the Rain, Get down on it, Funky Music, Everyone's a Winner, Can’t Get Enough of Your Love, Tragedy, Lady Marmalade, Love Is in the Air, Kung Fu Fighting Disco 3 – Give It Up, Long Train Running, That’s the Way I like It, If I Can’t Have You, Don’t Stop Till You Get Enough, Can You Feel It Disco 4 - I will survive, You should be dancing, Got To be real, Young Hearts Run Free, Do Ya think I'm Sexy, September, Hot Stuff, Boogie Wonderland. Jacko- Thriller, Shake Your Body, Billie Jean, Rock with You, Black or White, Wanna Be Starting Something, Bad Abba- Dancing Queen, SOS, Money Money Money, Ring Ring, Mamma Mia Latin – I Go To Rio, Conga, Hot Hot Hot, Copacabana, The Love Boat Mambo- Tequila, Yeh Yeh, Mambo no 5 Motown - Uptight, can’t help myself, same ole song, dancing in the street, aint too proud to beg, joy to the world, get ready , stop, its my party, never can say good bye Movie- Flashdance, fame, -

How Do I Switch on My Supertooth Disco 2 ?
What does Bluetooth A2DP profile mean? A2DP (Advanced Audio Distribution Profile) is a technology allowing stereo sound to be streamed via Bluetooth from any audio source (mobile phone, PC or laptop) to a stereo speaker or headset. To do so both the source and the speaker need to support this profile. What does Bluetooth AVRCP profile mean? AVRCP (Audio Video Remote Control Profile) is a remote control. This profile enables the control functions ‘Play / Pause / Stop / Previous Track / Next Track’ directly from the SuperTooth Disco 2 or audio source connected to it. To enable this function both the speaker and the connected audio source need to support this profile. How do I switch on my SuperTooth Disco 2 ? Press and hold the On / Off Button for 2 seconds. A power on beep is heard in the speaker, all the buttons switch on and off automatically. How do I switch off my SuperTooth Disco 2 ? Press and hold the On / Off Button for 3 seconds. A power on beep is heard in the speaker, all the buttons switch on and off automatically. How do I pair my SuperTooth Disco 2 with my Bluetooth phone / device ? Important: Make sure that your phone / device supports Bluetooth A2DP (Advanced Audio Distribution Profile) before proceeding. Note : Any other device previously paired with the SuperTooth Disco 2 must be turned off, or its Bluetooth must be disabled before proceeding. 1. The SuperTooth Disco 2 must be turned OFF. Press and hold the On / Off Button (6) for 6 seconds until the Play / Pause Button (3) blinks red fast. -

©2017 Renata J. Pasternak-Mazur ALL RIGHTS RESERVED
©2017 Renata J. Pasternak-Mazur ALL RIGHTS RESERVED SILENCING POLO: CONTROVERSIAL MUSIC IN POST-SOCIALIST POLAND By RENATA JANINA PASTERNAK-MAZUR A dissertation submitted to the Graduate School-New Brunswick Rutgers, The State University of New Jersey In partial fulfillment of the requirements For the degree of Doctor of Philosophy Graduate Program in Music Written under the direction of Andrew Kirkman And approved by _____________________________________ _____________________________________ _____________________________________ _____________________________________ New Brunswick, New Jersey January 2017 ABSTRACT OF THE DISSERTATION Silencing Polo: Controversial Music in Post-Socialist Poland by RENATA JANINA PASTERNAK-MAZUR Dissertation Director: Andrew Kirkman Although, with the turn in the discipline since the 1980s, musicologists no longer assume their role to be that of arbiters of “good music”, the instruction of Boethius – “Look to the highest of the heights of heaven” – has continued to motivate musicological inquiry. By contrast, music which is popular but perceived as “bad” has generated surprisingly little interest. This dissertation looks at Polish post-socialist music through the lenses of musical phenomena that came to prominence after socialism collapsed but which are perceived as controversial, undesired, shameful, and even dangerous. They run the gamut from the perceived nadir of popular music to some works of the most renowned contemporary classical composers that are associated with the suffix -polo, an expression -
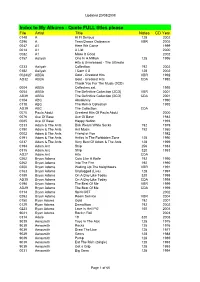
Album Backup List
Updated 20/08/2008 Index to My Albums - Quote FULL titles please File Artist Title Notes CD Year 0148 A Hi Fi Serious 128 2002 0296 A Teen Dance Ordinance VBR 2005 0047 A1 Here We Come 1999 0014 A1 A List 2000 0082 A1 Make It Good 2002 0157 Aaliyah One In A Million 128 1996 Hits & Unreleased - The Ultimate 0233 Aaliyah Collection 192 2002 0182 Aaliyah I Care 4 U 128 2002 0024/27 ABBA Gold - Greatest Hits VBR 1992 AD32 ABBA Gold - Greatest Hits CDA 1992 Thank You For The Music (3CD) 0004 ABBA Collectors set 1995 0054 ABBA The Definitive Collection (2CD) VBR 2001 AB39 ABBA The Definitive Collection (2CD) CDA 2001 0104 ABC Absolutely 1990 0118 ABC The Remix Collection 1993 AD39 ABC The Collection CDA 0070 Paula Abdul Greatest Hits Of Paula Abdul 2000 0076 Ace Of Base Ace Of Base 1983 0085 Ace Of Base Happy Nation 1993 0233 Adam & The Ants Dirk Wears White Socks 192 1979 0150 Adam & The Ants Ant Music 192 1980 0002 Adam & The Ants Friend or Foe 1982 0191 Adam & The Ants Antics In The Forbidden Zone 128 1990 0237 Adam & The Ants Very Best Of Adam & The Ants 128 1999 0194 Adam Ant Strip 256 1983 0315 Adam Ant Strip 320 1983 AD27 Adam Ant Hits CDA 0262 Bryan Adams Cuts Like A Knife 192 1990 0262 Bryan Adams Into The Fire 192 1990 0200 Bryan Adams Waking Up The Neighbours VBR 1991 0163 Bryan Adams Unplugged (Live) 128 1997 0189 Bryan Adams On A Day Like Today 320 1998 AD30 Bryan Adams On A Day Like Today CDA 1998 0198 Bryan Adams The Best Of Me VBR 1999 AD29 Bryan Adams The Best Of Me CDA 1999 0114 Bryan Adams Spirit OST 2002 0293 Bryan Adams -

Group-Based Discovery in Low-Duty-Cycle Mobile Sensor Networks
2012 9th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks (SECON) Group-based Discovery in Low-duty-cycle Mobile Sensor Networks Liangyin Chen∗,YuGu†, Shuo Guo§,TianHe§, Yuanchao Shu‡†, Fan Zhang‡ and Jiming Chen‡ ∗College of Computer Science, Sichuan University † Singapore University of Technology and Design §Department of Computer Science and Engineering, University of Minnesota ‡ Department of Control, Zhejiang University Abstract—Wireless Sensor Networks have been used in many is to reduce duty-cycle by listening briefly and shutting down mobile applications such as wildlife tracking and participatory radios most of the time (e.g., 99% or more). Such a simple urban sensing. Because of the combination of high mobility and low-duty-cycle operation, however, leads to a challenging low-duty-cycle operations, it is a challenging issue to reduce discovery delay among mobile nodes, so that mobile nodes can issue: how nodes within physical vicinity can discovery each establish connection quickly once they are within each other’s other if they listen to the channel in an asynchronous manner. vicinity. Existing discovery designs are essentially pair-wise based, This issue becomes even more challenging when low-duty- in which discovery is passively achieved when two nodes are cycle operation is combined with the mobility of sensor nodes pre-scheduled to wake-up at the same time. In contrast, for in many applications such as in ZerbraNet [7], opportunistic the first time, this work reduces discovery delay significantly by proactively referring wake-up schedules among a group of data collection (SNIP) [19] and urban sensing [5].