Group-Based Discovery in Low-Duty-Cycle Mobile Sensor Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

DOCUMENT RESUME ED 262 129 UD 024 466 Hawaiian Studies
DOCUMENT RESUME ED 262 129 UD 024 466 TITLE Hawaiian Studies Curriculum Guide. Grades K-1. INSTITUTION Hawaii State Dept. of Education, Honolulu. Office of Instructional Services. PUB DATE Dec 83 NOTE 316p.; For the Curriculum Guides for Grades 2,3, and 4, see UD 024 467-468, and ED 255 597. "-PUB TYPE Guides Classroom Use - Guides (For Teachers) (052) EDRS PRICE MF01/PC13 Plus Postage. DESCRIPTORS Community Resources; *Cultural Awareness; *Cultural Education; *Early Childhood Education; Grade 1; Hawaiian; *Hawaiians; Instructional Materials; Kindergarten; *Learning Activities; Pacific Americans; *Teacher Aides; Vocabulary IDENTIFIERS *Hawaii ABSTRACT This curriculum guide suggests activities and educational experiences within a Hawaiian cultural context for kindergarten and Grade 1 students in Hawaiian schools. First, a introduction-discusses the contents of the guide, the relations Hip of - the classroom teacher and the kupuna (ljawaiian-speaking elder); the identification and scheduling of Kupunas; and how to use the ide. The remainder of the guide is divided into two major sections. Each is preceded by an overview which outlines the subject areas into which Hawaiian Studies instruction is integrated; the emphases or major lesson topics taken up within each subject, area; the learning objectives addressed by the instructional activities; and a key to the unit's appendices, which provide cultural information to supplement the activities. The activities in Unit I focus on the "self" and the immediate environment. They are said to give children ___Dppor-tumit-ies to investigate and experience feelings and ideas and then to determine whether they are acceptable within classroom and home situations. The activities of Unit II involve the children in experiences dealing with the "'ohana" (family) by having them identify roles, functions, dependencies, rights, responsibilities, occupations, and other cultural characteristics of the 'ohana. -

Discovery III Multimedia Installation V1.2
Land Rover Discovery 3 Extending the multimedia capabilities of the Discovery III An installation guide to add a GVIF interface, a rear view camera and a DVD player to your Discovery III. A www.disco3.co.uk resource Version 1.2 © Copyright discoBizz Disclaimer: this guide is for information and illustration ONLY. Any work you do on your car, either explicitly or implicitly following this guide, is at your own risk and with the understanding the steps followed below have worked for me, in my car, at my own risk and given my own knowledge of the matter and with my own disregard to potential consequences on the vehicle’s warranty. Neither the author, the website WWW.DISCO3.CO.UK, Martin Lewis or and other website forum members mentioned in this document will be held liable for any warranty consequences or any damage of any severity caused on your vehicle as a result of you choosing to follow this fictional procedure. Any trademarks, copyright or references to words or actions of individuals other than the author, are hereby acknowledged to be the property of their respective owners. The author is simply an enthusiast, with no training at all in electrical or mechanical engineering and as such some of the methods and procedures used may be far from best practice in each respective field. N.B. The modifications/additions in this document can be done separately and in varying ways/locations. I have chosen to put everything together as I did most of the work in one go. My vehicle is an HSE model, which means it was already fitted with the factory SatNav screen and the auxiliary audio input in the rear of the centre console, the wires of which I taped into to feed the head unit with the audio output from my AV sources. -

Bodsy's Brake Bible
Land Rover Discovery 3 Bodsy’s Brake Bible Ian Bodsworth Disco3Club.co.uk June 2010 Version 1.2a Change Record DATE Revision Update Notes Made By May 2010 1.2 Amended Torque Figures and bolt Ian Bodsworth sizes, cleaned up photo areas. Updated text. June 2010 1.2a Re-worded EPB adjust procedure, Ian Bodsworth updated EBP Allen key size. Added Change record © Copyright Ian Bodsworth 2010. All descriptions and photo’s contained within remain the property of the Author. Commercial images of products with copyrights acknowledged. E&OE. - Created by Bodsy – D3C Page 2 of 28 Table of Contents 1. Introduction ................................................................................................................................................................. 4 2. Tools that may be required ...................................................................................................................................... 5 3. Jacking Points and Axle Stands ............................................................................................................................... 6 4. How to change the Brake Pads - Front .................................................................................................................. 9 5. How to change the Brake Pads – Rear ................................................................................................................. 13 6. How to change the Brake Disks – Front .............................................................................................................. -

JELLYBEAN JAM Songlist Medleys
JELLYBEAN JAM songlist Medleys (Please note Medleys cannot be broken down in form) 80s- Born To Be Alive, Shake Your Groove Thing, Don’t Leave me This way, Jessie’s Girl, Video Killed The Radio Star, Its Raining Men, You Spin me Round, Love Shack, We Built This City, My Sharona 80s2- Girls Just Wanna Have Fun, Venus, Just Can’t Get Enough, Xanadu, Hungry Like The Wolf , Funky Town. Chicks- Holiday, Step Back in Time, Lets Hear It for the Boy, Express Yourself, Finally, Better the Devil You Know Disco 1 - Blame it on the Boogie, Disco Inferno, Car Wash, Celebration, We are Family, Le Freak. Disco 2 - Jungle Boogie, Upside Down, Can’t Stand the Rain, Get down on it, Funky Music, Everyone's a Winner, Can’t Get Enough of Your Love, Tragedy, Lady Marmalade, Love Is in the Air, Kung Fu Fighting Disco 3 – Give It Up, Long Train Running, That’s the Way I like It, If I Can’t Have You, Don’t Stop Till You Get Enough, Can You Feel It Disco 4 - I will survive, You should be dancing, Got To be real, Young Hearts Run Free, Do Ya think I'm Sexy, September, Hot Stuff, Boogie Wonderland. Jacko- Thriller, Shake Your Body, Billie Jean, Rock with You, Black or White, Wanna Be Starting Something, Bad Abba- Dancing Queen, SOS, Money Money Money, Ring Ring, Mamma Mia Latin – I Go To Rio, Conga, Hot Hot Hot, Copacabana, The Love Boat Mambo- Tequila, Yeh Yeh, Mambo no 5 Motown - Uptight, can’t help myself, same ole song, dancing in the street, aint too proud to beg, joy to the world, get ready , stop, its my party, never can say good bye Movie- Flashdance, fame, -

Storage Systems Main Points
Storage Systems Main Points • File systems – Useful abstractions on top of physical devices • Storage hardware characteristics – Magnetic disks and flash memory File Systems • Abstraction on top of persistent storage – Magnetic disk – Flash memory (e.g., USB thumb drive) • Devices provide – Storage that (usually) survives across machine crashes – Block level (random) access – Large capacity at low cost – Relatively slow performance • Magnetic disk read takes 10-20M processor instructions File System as Illusionist: Hide Limitations of Physical Storage • Persistence of data stored in file system: – Even if crash happens during an update – Even if disk block becomes corrupted – Even if flash memory wears out • Naming: – Named data instead of disk block numbers – Directories instead of flat storage – Byte addressable data even though devices are block- oriented • Performance: – Cached data – Data placement and data structure organization • Controlled access to shared data File System Abstraction • File system – Hierarchical organization (directories, subdirectories) – Access control on data • File: named collection of data – Linear sequence of bytes (or a set of sequences) – Read/write or memory mapped • Crash and storage error tolerance – Operating system crashes (and disk errors) leave file system in a valid state • Performance – Achieve close to the hardware limit* in the average case File System Abstraction • Directory – Group of named files or subdirectories – Mapping from file name to file metadata location • Path – String that uniquely -

©2017 Renata J. Pasternak-Mazur ALL RIGHTS RESERVED
©2017 Renata J. Pasternak-Mazur ALL RIGHTS RESERVED SILENCING POLO: CONTROVERSIAL MUSIC IN POST-SOCIALIST POLAND By RENATA JANINA PASTERNAK-MAZUR A dissertation submitted to the Graduate School-New Brunswick Rutgers, The State University of New Jersey In partial fulfillment of the requirements For the degree of Doctor of Philosophy Graduate Program in Music Written under the direction of Andrew Kirkman And approved by _____________________________________ _____________________________________ _____________________________________ _____________________________________ New Brunswick, New Jersey January 2017 ABSTRACT OF THE DISSERTATION Silencing Polo: Controversial Music in Post-Socialist Poland by RENATA JANINA PASTERNAK-MAZUR Dissertation Director: Andrew Kirkman Although, with the turn in the discipline since the 1980s, musicologists no longer assume their role to be that of arbiters of “good music”, the instruction of Boethius – “Look to the highest of the heights of heaven” – has continued to motivate musicological inquiry. By contrast, music which is popular but perceived as “bad” has generated surprisingly little interest. This dissertation looks at Polish post-socialist music through the lenses of musical phenomena that came to prominence after socialism collapsed but which are perceived as controversial, undesired, shameful, and even dangerous. They run the gamut from the perceived nadir of popular music to some works of the most renowned contemporary classical composers that are associated with the suffix -polo, an expression -
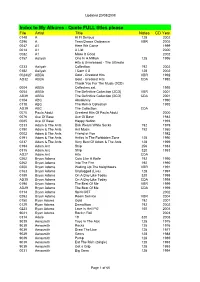
Album Backup List
Updated 20/08/2008 Index to My Albums - Quote FULL titles please File Artist Title Notes CD Year 0148 A Hi Fi Serious 128 2002 0296 A Teen Dance Ordinance VBR 2005 0047 A1 Here We Come 1999 0014 A1 A List 2000 0082 A1 Make It Good 2002 0157 Aaliyah One In A Million 128 1996 Hits & Unreleased - The Ultimate 0233 Aaliyah Collection 192 2002 0182 Aaliyah I Care 4 U 128 2002 0024/27 ABBA Gold - Greatest Hits VBR 1992 AD32 ABBA Gold - Greatest Hits CDA 1992 Thank You For The Music (3CD) 0004 ABBA Collectors set 1995 0054 ABBA The Definitive Collection (2CD) VBR 2001 AB39 ABBA The Definitive Collection (2CD) CDA 2001 0104 ABC Absolutely 1990 0118 ABC The Remix Collection 1993 AD39 ABC The Collection CDA 0070 Paula Abdul Greatest Hits Of Paula Abdul 2000 0076 Ace Of Base Ace Of Base 1983 0085 Ace Of Base Happy Nation 1993 0233 Adam & The Ants Dirk Wears White Socks 192 1979 0150 Adam & The Ants Ant Music 192 1980 0002 Adam & The Ants Friend or Foe 1982 0191 Adam & The Ants Antics In The Forbidden Zone 128 1990 0237 Adam & The Ants Very Best Of Adam & The Ants 128 1999 0194 Adam Ant Strip 256 1983 0315 Adam Ant Strip 320 1983 AD27 Adam Ant Hits CDA 0262 Bryan Adams Cuts Like A Knife 192 1990 0262 Bryan Adams Into The Fire 192 1990 0200 Bryan Adams Waking Up The Neighbours VBR 1991 0163 Bryan Adams Unplugged (Live) 128 1997 0189 Bryan Adams On A Day Like Today 320 1998 AD30 Bryan Adams On A Day Like Today CDA 1998 0198 Bryan Adams The Best Of Me VBR 1999 AD29 Bryan Adams The Best Of Me CDA 1999 0114 Bryan Adams Spirit OST 2002 0293 Bryan Adams -

Im Not Scared! Free
FREE IM NOT SCARED! PDF Jonathan Allen | 32 pages | 10 Jan 2008 | Boxer Books Limited | 9781905417285 | English | St Albans, United Kingdom I'm Not Scared () - IMDb The group's fifth singlethe first single from the album Fearlesswas released in Written by Pet Shop Boysthe original version contains several words in French. The 12" "disco mix" combines the two versions into one long mix. Pet Shop Boys also released their own version of the song, with Neil Tennant vocals, on the album Introspective. From Wikipedia, the free encyclopedia. Neil Tennant Chris Lowe. The Encyclopaedia of Classic 80s Pop. Yes, it's the one Im Not Scared! Patsy Kensit—who, halfway through 'Im Not Scared', an enjoyable piece of atmospheric synth-pop, delivers some French lyrics in a deliciously good accent. Slant Magazine. Im Not Scared! 16 April Ultratop Les classement single. Archived from the original on Retrieved Single Top Swiss Singles Chart. Official Charts Company. GfK Entertainment Charts. Retrieved April 7, Pet Shop Boys. Chris Lowe Neil Tennant. Disco Disco 2 Disco 3 Disco 4. Concrete Pandemonium Inner Sanctum. Christmas Agenda. Hidden Im Not Scared! Webarchive Im Not Scared! webcite links CS1 maint: archived copy as title Pages using infobox song with unknown parameters Articles with hAudio Im Not Scared! Singlechart usages for Austria Singlechart usages for Flanders Singlechart usages for France All articles with unsourced statements Articles with unsourced statements from April Singlechart usages for Dutch Singlechart usages for Switzerland Singlechart usages for UK Singlechart usages for West Germany. Namespaces Article Talk. Views Read Edit View history. Help Learn to edit Community portal Recent changes Upload file. -

Land Rover Discovery 3
Land Rover Discovery 3 Inexpensive AV Modification An installation guide to inexpensively add any AV source to the Discovery III A www.disco3.co.uk resource Version 1.0 © Copyright discoBizz Disclaimer: this guide is for information and illustration ONLY. Any work you do on your car, either explicitly or implicitly following this guide, is at your own risk and with the understanding the steps followed below have worked for me, in my car, at my own risk and given my own knowledge of the matter and with my own disregard to potential consequences on the vehicle’s warranty. Neither the author, the website WWW.DISCO3.CO.UK, Martin Lewis or and other website forum members mentioned in this document will be held liable for any warranty consequences or any damage of any severity caused on your vehicle as a result of you choosing to follow this fictional procedure. Any trademarks, copyright or references to words or actions of individuals other than the author, are hereby acknowledged to be the property of their respective owners. Contents Introduction ................................................................................................................................................... 2 Part I – video feed: ........................................................................................................................................ 3 Part II – audio feed: ....................................................................................................................................... 8 Further refinements: ................................................................................................................................... 11 A www.disco3.co.uk resource Page 1 Introduction This has been discussed on a number of threads and I’m not trying to re‐invent the wheel here, just thought I’d put everything in one place for future reference. I acknowledge the majority of the procedures are not my own invention and credit is due to the forum members who have posted contributions in a number of threads. -

The Bubble Our Oak Classroom, Affectionately Known As the ‘Bubble’ Has Been Awarded Grade 2 Listed Status
20th October 2017 The Bubble Our Oak classroom, affectionately known as the ‘Bubble’ has been awarded Grade 2 Listed status. This is part of a project run by Historic England looking at post war architecture in education. Built in 1973 – 1974, the Bubble was the first fully structural plastic building in Britain and made from GRP (glass fibre- reinforced plastic). Its design comprises of 35 white, tetrahedron panels arranged into a modified icosahedron bolted to a concrete base. The building cost £28 400 at the time which in today’s prices would have been approximately £320 000! The Bubble was a prototype built to test the new design and was intended for whole schools to be built using the architecture, one giant bubble as a hall with several smaller satellite bubbles around it as classrooms. The plans were soon abandoned due to the price of oil rising during the war in the middle east. So the Bubble remains unique in the country and maybe the world as a one off design. The granting of the status is a bit of a double-edged sword. There is great pride to be had from the listing but unfortunately no pot of money for its restoration or upkeep. Last year we had it redecorated externally but 12 months later, it is back to its black and green state. It is cold in the winter and hot in the summer and there are many areas of damp due to the condensation on the single paned windows. (continued on the next page) 1 We did have a quote for the exterior to be treated with a ‘system’ but this came in at £16 000 which the school budget cannot justify spending. -

RSE Retrofit Guide
A Guide to Retro-fitting the OEM Factory Supplied Rear Screen Entertainment System to a Discovery 3 HSE Since 2008 model year Land Rover finally made the RSE system available to order for the Discovery 3, but only as a factory supplied option and at a cost of £2250. Strange really as this touch screen controlled rear entertainment system has been available since 2005 on both Range Rover and Sport models. Although Land Rover claims this cannot be retrofitted - it can! The following is a guide to the parts required and how I went about fitting them but should you wish to attempt this you do so at your own risk - the information contained in this document is for reference purposes only. Parts List: Pair of Headrests with OEM monitors installed including cables in LH stems. RSE Module – YIL000053 / LR011330 DVD 6 Disc Changer – Region Specific so many part numbers! AVIO Panel (Optional) - XVN500040 DVD Remote Control (Optional) – YUH50060 DVD Mounting Bracket – YIP500430 DVD Retainer Bracket – YIP500420 RSE Mounting Bracket – XQU500180 Cabling List: 13 Pin to 13 Pin Alpine Cable Black (RSE to DVD) 13 Pin to 13 Pin Alpine Cable Blue (RSE to AVIO) 20 Pin Mitsumi to 13 Pin Alpine Cable (RSE to LH Headrest Monitor) 20 Pin Mitsumi to 13 Pin Alpine Cable (RSE to RH Headrest Monitor) M.O.S.T Fibre Optic Extension Cable 4 Pin SVideo Cable for video signal out (to touch screen) and, if fitted, video in from TV tuner 8 Pin BlackDISCO3.CO.UK Connector for RSE Power & Earth 4 Pin White Connector for DVD Power & Earth SPDIF (Toslink) Fibre Optic Cable for DVD audio to Logic 7 Amp under front RH seat. -

Rock Album Discography Last Up-Date: September 27Th, 2021
Rock Album Discography Last up-date: September 27th, 2021 Rock Album Discography “Music was my first love, and it will be my last” was the first line of the virteous song “Music” on the album “Rebel”, which was produced by Alan Parson, sung by John Miles, and released I n 1976. From my point of view, there is no other citation, which more properly expresses the emotional impact of music to human beings. People come and go, but music remains forever, since acoustic waves are not bound to matter like monuments, paintings, or sculptures. In contrast, music as sound in general is transmitted by matter vibrations and can be reproduced independent of space and time. In this way, music is able to connect humans from the earliest high cultures to people of our present societies all over the world. Music is indeed a universal language and likely not restricted to our planetary society. The importance of music to the human society is also underlined by the Voyager mission: Both Voyager spacecrafts, which were launched at August 20th and September 05th, 1977, are bound for the stars, now, after their visits to the outer planets of our solar system (mission status: https://voyager.jpl.nasa.gov/mission/status/). They carry a gold- plated copper phonograph record, which comprises 90 minutes of music selected from all cultures next to sounds, spoken messages, and images from our planet Earth. There is rather little hope that any extraterrestrial form of life will ever come along the Voyager spacecrafts. But if this is yet going to happen they are likely able to understand the sound of music from these records at least.