Evaluation of Mineral Resources Carrying Capacity Based on the Particle Swarm Optimization Clustering Algorithm S
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CLEAN DEVELOPMENT MECHANISM PROJECT DESIGN DOCUMENT FORM (CDM-PDD) Version 03 - in Effect As Of: 28 July 2006
PROJECT DESIGN DOCUMENT FORM (CDM PDD) - Version 03 CDM – Executive Board page 1 CLEAN DEVELOPMENT MECHANISM PROJECT DESIGN DOCUMENT FORM (CDM-PDD) Version 03 - in effect as of: 28 July 2006 CONTENTS A. General description of project activity B. Application of a baseline and monitoring methodology C. Duration of the project activity / crediting period D. Environmental impacts E. Stakeholders‟ comments Annexes Annex 1: Contact information on participants in the project activity Annex 2: Information regarding public funding Annex 3: Baseline information Annex 4: Monitoring plan PROJECT DESIGN DOCUMENT FORM (CDM PDD) - Version 03 CDM – Executive Board page 2 SECTION A. General description of project activity A.1. Title of the project activity: Project title: Sichuan Dechang Xinma 120 MW Hydropower project PDD Version: 1.0 Completion date PDD: 11/08/2009 A.2. Description of the project activity: The Sichuan Dechang Xinma 120 MW Hydropower project (hereafter referred to „ the project „ or „project‟) involves the construction of a run-of-river hydropower station at the main stream of the Anning River at Meizi Village, Dechang county of Sichuan Province, China, which is constructed and operated by Dechang Xinma Hydropower development Co., Ltd. The dam locates 40 km from Dechang County, The total installed capacity of the project will be 120MW and the total surface area of the reservoir at full capacity is 374,000m2 and the power density of the project is 320 W/m2. The expected annual effective operating hour is 4,086 hours and annual power generation is about 573,960MWh. The expected annual power supply is 544,000 MWh. -
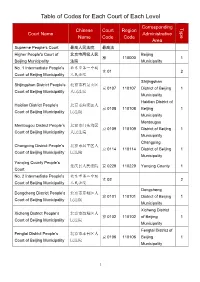
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

ECONOMIC GEOLOGY RESEARCH INSTITUTE HUGH ALLSOPP LABORATORY University of the Witwatersrand Johannesburg
2 ECONOMIC GEOLOGY RESEARCH INSTITUTE HUGH ALLSOPP LABORATORY University of the Witwatersrand Johannesburg ! GEOLOGICAL CHARACTERISTICS OF PGE-BEARING LAYERED INTRUSIONS IN SOUTHWEST SICHUAN PROVINCE, CHINA Y.YAO, M.J. VILJOEN, R.P. VILJOEN, A.H. WILSON, H. ZHONG, B.G. LIU, H.L. YING, G.Z. TU and N. LUO ! INFORMATION CIRCULAR No. 358 3 UNIVERSITY OF THE WITWATERSRAND JOHANNESBURG GEOLOGICAL CHARACTERISTICS OF PGE-BEARING LAYERED INTRUSIONS IN SOUTHWEST SICHUAN PROVINCE, CHINA by Y. YAO1, M. J. VILJOEN2, R. P. VILJOEN2, A. H. WILSON3, H. ZHONG1, B. G. LIU4, H. L. YING4, G. Z. TU4 AND Y. N. LUO5, ( 1 Economic Geology Research Institute, School of Geosciences, University of the Witwatersrand, P/Bag 3, WITS 2050, Johannesburg, South Africa; 2 Department of Geology and CAMEG, School of Geosciences, University of the Witwatersrand, P/Bag 3, WITS 2050, Johannesburg, South Africa; 3 Department of Geology and Applied Geology, University of Natal, King George V Avenue, Durban, 4001; 4 Institute of Geology and Geophysics, Chinese Academy of Sciences, P.O. Box 9825, Qijiahuozhi, Deshengmenwai, Beijing 100029, P.R. China; 5 Geological Exploration Bureau of Sichuan Province, Renminglu, Chengdu 610081, P.R. China) ECONOMIC GEOLOGY RESEARCH UNIT INFORMATION CIRCULAR No. 358 December 2001 4 GEOLOGICAL CHARACTERISTICS OF PGE-BEARING LAYERED INTRUSIONS IN SOUTHWEST SICHUAN PROVINCE, CHINA ABSTRACT A number of platinum-group-element (PGE-bearing), layered, ultramafic-mafic intrusions in the Pan-Xi and Danba areas of the southwest Sichuan Province of China have been investigated. The two study areas are located, respectively, in the central and northern parts of the Kangding Axis on the western margin of the Yangtze Platform, a region geologically distinguished by late- Archaean to late-Proterozoic basement and by stable sedimentary sequences. -

A Study from the Perspectives of Shared Innovation
SUBGROUPING OF NISOIC (YI) LANGUAGES: A STUDY FROM THE PERSPECTIVES OF SHARED INNOVATION AND PHYLOGENETIC ESTIMATION by ZIWO QIU-FUYUAN LAMA Presented to the Faculty of the Graduate School of The University of Texas at Arlington in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT ARLINGTON May 2012 Copyright © by Ziwo Qiu-Fuyuan Lama 2012 All Rights Reserved To my parents: Qiumo Rico and Omu Woniemo Who have always wanted me to stay nearby, but they have also wished me to go my own way! ACKNOWLEDGEMENTS The completion of this dissertation could not have happened without the help of many people; I own much gratitude to these people and I would take this moment to express my heartfelt thanks to them. First, I wish to express my deep thanks to my supervisor, Professor Jerold A Edmondson, whose guidance, encouragement, and support from the beginning to the final page of this dissertation. His direction showed me the pathway of the writing of this dissertation, especially, while working on chapter of phylogenetic study of this dissertation, he pointed out the way to me. Secondly, I would like to thank my other committee members: Dr. Laurel Stvan, Dr. Michael Cahill, and Dr. David Silva. I wish to thank you very much for your contribution to finishing this dissertation. Your comments and encouragement were a great help. Third, I would like to thank my language informants and other people who helped me during my field trip to China in summer 2003, particularly ZHANF Jinzhi, SU Wenliang, PU Caihong, LI Weibing, KE Fu, ZHAO Hongying, ZHOU Decai, SHI Zhengdong, ZI Wenqing, and ZUO Jun. -

Environmental Due Diligence Report People's Republic of China: Mountain Railway Safety Enhancement Project
Environmental Due Diligence Report March 2017 People’s Republic of China: Mountain Railway Safety Enhancement Project Prepared by the China Railway Corporation for the Asian Development Bank. CURRENCY EQUIVALENTS (as of 4 January 2017) Currency unit – yuan (CNY) CNY1.00 = $0.1439 $1.00 = CNY6.9516 ABBREVIATIONS ADB – Asian Development Bank CRC – China Railway Corporation CKRC – Chengdu-Kunming Railway Corporation CKRL – Chengdu-Kunming railway line CREEC – China Railway Eryuan Engineering Company EIA – environmental impact assessment EIR – environmental impact report EPL – Environmental Protection Law NDRC – National Development and Reform Commission PRC – People’s Republic of China WEIGHTS AND MEASURES km – kilometer NOTE In the report, “$” refers to US dollars. This environmental due diligence report is a document of the borrower. The views expressed herein do not necessarily represent those of ADB's Board of Directors, Management, or staff, and may be preliminary in nature. Your attention is directed to the “terms of use” section on ADB’s website. In preparing any country program or strategy, financing any project, or by making any designation of or reference to a particular territory or geographic area in this document, the Asian Development Bank does not intend to make any judgments as to the legal or other status of any territory or area. TABLE OF CONTENTS I. Introduction ............................................................................................................ 4 A. The Project .............................................................................................................. -

CHINA Sichuanpower TRANSMISSION PROJECT
;'lAssessment/AnRaly$sis cAS epolbs SW Public Disclosure Authorized 'ttit ,., w' i '' .... ,j ~~~~~~~ReportE0090 t¢if4 ,';' i ,., ..' : ., ,,,,,,* ,,,, ,(,,,1 , . .~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Public Disclosure Authorized :XrX~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~, Public Disclosure Authorized j$^/+t,,'~~~~~~~~~~~~~~~~~~~~~~~~~ii . ' 0 @ t ; i,~~~~~~~~... ... ..7 Public Disclosure Authorized THE ENVIRONMENTALIMPACT ASSESSM:ENTREPORT FOR CHINA SIcHuANPOWER TRANSMISSION PROJECT (Final Report) Document for The World Bank Appraisal BA-OOS-B Sichuan Electric Power Company Chengdu, China Sep., 1994 -. U * t *ilA*E~~~~~~~~~~~-a- $ {..*S;~~~~~~~~ 1-p * i,$-"a . @~~~~~~~ OR t1 1 Cs 1. _ 'fl, Ctv'W$; FIrfrmr:r_ M>,siN rnF.1 -S AoA . E. sH % h a h t O d .. F>,¢^sakt*.{ ,_ ;rcM t a I'-Alssi~~~~~c k{wt >4 I4i' RIUrua iWr 'HIP,) 1; - ;oup Bi ! .~1t>'Ix Y :%' v..P4^t Mt + vct... FRI ' ta }XE'B1tbyeXaReRSSWiBCv ° 4A,L W'40 Ww' s '-W Xi+ffiX e WWX a W7f y A-Vf *z-f 7gag jV7Y gg 7;Urtwg 'A .w- ta±.4 t. 'tk E kf V 4 - JW > 4-V ' Ir -Dalb' rt W 'SS#Rg'X'wt-~W 'FXt °X V >w--,Ir -ff4' Mt iWRt 3 k;W so.I tV WsCf't1'%4W 4flY M4flY 'q'f l4 * WS w + w ~ g ~ *N e v4 W ' - i~ Y rt I j u )-~Iae -rt-fl.. 49R Al ES'' 4 -i> \$; E S 9 g NK§414 N-1k',) fia > 'MBis Xw'Il fl9 _ od h9iX$7:Y C ,tg,§ t . b ,' . a r -i I 'ME' -h' 1 x, * 6'' .:i ffi .1 a- Ž-- rt o 4Wt~~~~~~~~~~~~~~~~~~~~46- ={1 40s;-. -
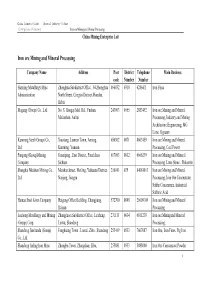
Iron Ore Mining and Mineral Processing China Mining Enterprise Lsit
China Commerce Guide -- Mineral Industry Volume Enterprises Directory Iron ore Mining and Mineral Processing China Mining Enterprise Lsit Iron ore Mining and Mineral Processing Company Name Address Post District Telephone Main Business code Number Number Hanxing Metallurgy Mine Zhonghua Subdistrict Office , 54 Zhonghua 056032 0310 6286411 Iron Fines Administration North Street, Congtai District, Handan, Hebei Magang (Group) Co., Ltd. No. 8, Hongqi Mid. Rd., Yushan, 243003 0555 2883492 Iron ore Mining and Mineral Ma'anshan, Anhui Processing, Industry and Mining Architecture Engineering, MG Lime, Gypsum Kunming Steel (Group) Co., Xiaotang, Lianran Town, Anning, 650302 0871 8603459 Iron ore Mining and Mineral Ltd. Kunming, Yunnan Processing, Coal Power Pangang (Group)Mining Guaziping , East District, Panzhihua, 617063 0812 6666239 Iron ore Mining and Mineral Company Sichuan Processing, Lime Stone,Dolomite Shanghai Meishan Mining Co., Meishan Street, Meiling, Yuhuatai District, 210041 025 84084013 Iron ore Mining and Mineral Ltd. Nanjing, Jiangsu Processing, Iron Ore Concentrate, Sulfur Concentrate, Industrial Sulfuric Acid Hainan Steel & iron Company Haigang Office Building, Changjiang, 572700 0898 26609109 Iron ore Mining and Mineral Hainan Processing Luzhong Metallurgy and Mining Zhangjiawa Subdistrict Office, Laicheng, 271113 0634 6811238 Iron ore Miningand Mineral (Group) Corp. Laiwu, Shandong Processing; Shandong Jinshunda (Group) Fenghuang Town , Lionzi, Zibo , Shandong 255419 0533 7607087 Iron Ore, Iron Fines, Pig Iron Co., Ltd. Shandong -

CHINA the Church of Almighty God: Prisoners Database (1663 Cases)
CHINA The Church of Almighty God: Prisoners Database (1663 cases) Prison term: 15 years HE Zhexun Date of birth: On 18th September 1963 Date and place of arrest: On 10th March 2009, in Xuchang City, Henan Province Charges: Disturbing social order and using a Xie Jiao organization to undermine law enforcement because of being an upper-level leader of The Church of Almighty God in mainland China, who was responsible for the overall work of the church Statement of the defendant: He disagreed with the decision and said what he believed in is not a Xie Jiao. Court decision: In February 2010, he was sentenced to 15 years in prison by the Zhongyuan District People’s Court of Zhengzhou City, Henan Province. Place of imprisonment: No. 1 Prison of Henan Province Other information: He was regarded by the Chinese authorities as a major criminal of the state and had long been on the wanted list. To arrest him, authorities offered 500,000 RMB as a reward to informers who gave tips leading to his arrest to police. He was arrested at the home of a Christian in Xuchang City, Henan Province. Based on the information from a Christian serving his sentence in the same prison, HE Zhexun was imprisoned in a separate area and not allowed to contact other prisoners. XIE Gao, ZOU Yuxiong, SONG Xinling and GAO Qinlin were arrested in succession alongside him and sentenced to prison terms ranging from 11 to 12 years. Source: https://goo.gl/aGkHBj Prison term: 14 years MENG Xiumei Age: Forty-one years old Date and place of arrest: On 14th August 2014, in Xinjiang Uyghur Autonomous Region Charges: Using a Xie Jiao organization to undermine law enforcement because of being a leader of The Church of Almighty God and organizing gatherings for Christians and the work of preaching the gospel in Ili prefecture Statement of the defendant: She claimed that her act did not constitute crimes. -

People's Republic of China Death Penalty Log: January to December
People’s Republic of China Death Penalty log: January to December 2000 The table overleaf lists the following (from left to right): the sources and dates of the reports (when known); the date of the reported death sentences (DS) or executions (EX) (when known); the province or city where the sentences were imposed or carried out (when known); the names (when known) or numbers of the alleged offenders and further details (when known); the alleged criminal offences for which the death sentences were imposed (when known); the number of death sentences imposed without stay of execution; the number of executions actually carried out; the number of death sentences imposed with a two-year stay of execution (2y); other information when available, including the number of death sentences, executions and two-year reprieve cases for each month. Abbreviations used in the table: DS number of death sentences pronounced without a stay of execution EX number of executions reported to have been carried out 2y number of death sentences with a 2-year reprieve (stay of execution) (F) Female Source of Report - abbreviations used (unless otherwise given) SWB BBC Summary of World Broadcasts (U.K. publication) SCMP South China Morning Post (Hong Kong daily newspaper) FBIS Foreign Broadcast Information Service (U.S. publication) AFP Agence France Presse AP Associated Press Xinhua New China News Agency (Chinese state news agency) VOA Voice of America CNA China News Analysis ETIC East Turkistan Information Centre PBS People's Broadcasting Station (Chinese -

Listing of Global Companies with Ongoing Government Activity
COMPANY LINE OF BUSINESS TICKER D & B MED PHARM PHARMACEUTICAL PREPARATIONS D & K PHARMACY PHARMACEUTICAL PREPARATIONS D & O PHARMA PHARMACEUTICAL PREPARATIONS D & O PHARMACHEM (INDIA) LIMITED PHARMACEUTICAL PREPARATIONS D BHARAT KUMAR & COMPANY MEDICINALS AND BOTANICALS, NSK D BHARAT KUMAR & COMPANY MEDICINALS AND BOTANICALS, NSK D C P S COMPANY PHARMACEUTICAL PREPARATIONS D C S PHARMACEUTICALS PRIVATE LIMITED PHARMACEUTICAL PREPARATIONS D D PHARMACEUTICALS PRIVATE LIMITED PHARMACEUTICAL PREPARATIONS D D S A PHARMUCEUTICALS PHARMACEUTICAL PREPARATIONS D D SHAH & COMPANY PHARMACEUTICAL PREPARATIONS D DA SILVA MESQUITA ME PHARMACEUTICAL PREPARATIONS D DILIP & COMPANY PHARMACEUTICAL PREPARATIONS D E B'S HOMOEO PHARMA PHARMACEUTICAL PREPARATIONS D G PHARMA PHARMACEUTICAL PREPARATIONS D I L LIMITED PHARMACEUTICAL PREPARATIONS D J LABORATORIES PRIVATE LIMITED MEDICINALS AND BOTANICALS, NSK D K AYURVEDIC PHARMACY PROP GN MEDICINALS AND BOTANICALS, NSK D K HERBAL UDYOG MEDICINALS AND BOTANICALS, NSK D K HERBALS MEDICINALS AND BOTANICALS, NSK D M ENGINEERING COMPANY (VATVA GIDC) PHARMACEUTICAL PREPARATIONS D M PHARMACEUTICAL PVT LTD . PHARMACEUTICAL PREPARATIONS D M PLASTOPACK PRIVATE LIMITED PHARMACEUTICAL PREPARATIONS D ORSI DOBILIO Y VIEYTES OSCAR JOSE PHARMACEUTICAL PREPARATIONS D P PHARMACEUTICALS PHARMACEUTICAL PREPARATIONS D S M ANTI INEFECTIVES INDIA LIMITED MEDICINALS AND BOTANICALS, NSK D V DEO BOTANICAL EXTRACTS LTD MEDICINALS AND BOTANICALS, NSK D V M PHARMACEUTICALS INC PHARMACEUTICAL PREPARATIONS D X N HERBAL MEDICINALS AND BOTANICALS, NSK D.C.F. - DERMO COSMETICA FARMACEUTICA, LDA PHARMACEUTICAL PREPARATIONS D.D.D. LABORATORIUM APOTHEKER GERHARD KRAUSS PHARMACEUTICAL PREPARATIONS D.I.F.C. CO., LTD. PHARMACEUTICAL PREPARATIONS D.M.S. FARMACEUTICI SPA PHARMACEUTICAL PREPARATIONS D.O.O. PROIZ. FARM. PROIZ. 'HEMOFARM' MEDICINALS AND BOTANICALS, NSK D.S.M. -

Multiscale Spatio-Temporal Dynamics of Economic
sustainability Article Multiscale Spatio-Temporal Dynamics of Economic Development in an Interprovincial Boundary Region: Junction Area of Tibetan Plateau, Hengduan Mountain, Yungui Plateau and Sichuan Basin, Southwestern China Case Jifei Zhang 1,2 and Wei Deng 1,* 1 Institute of Mountain Hazards and Environment, Chinese Academy of Sciences, Chengdu 610041, China; [email protected] 2 The International Centre for Integrated Mountain Development, Kathmandu 44700, Nepal * Correspondence: [email protected]; Tel./Fax: +86-028-8535-3897 Academic Editors: Giuseppe Ioppolo and Marc A. Rosen Received: 8 December 2015; Accepted: 25 February 2016; Published: 29 February 2016 Abstract: An interprovincial boundary region is a new subject of economic disparity study in China. This study explored the multi-scale spatio-temporal dynamics of economic development from 1995 to 2010 in the interprovincial boundary region of Sichuan-Yunnan-Guizhou, a mountain area and also the junction area of Tibetan Plateau, Hengduan Mountain, Yungui Plateau and Sichuan Basin in southwestern China. A quantitative study on county GDP per capita for different scales of administrative regions was conducted using the Theil index, Markov chains, a geographic information system and exploratory spatial data analysis. Results indicated that the economic disparity was closely related with geographical unit scale in the study area: the smaller the unit, the bigger the disparity, and the regional inequality gradually weakened over time. Moreover, significant positive spatial autocorrelation and clustering of economic development were also found. The spatial pattern of economic development presented approximate circle structure with two cores in the southwest and northeast. The Panxi region in the southwest core and a part of Hilly Sichuan Basin in the northeast core were considered to be hot spots of economic development. -

Multiple Mechanisms Underlie Rapid Expansion of an Invasive Alien Plant
New Phytologist Research Multiple mechanisms underlie rapid expansion of an invasive alien plant Rui Wang1,2, Jin-Feng Wang3, Zhi-Jing Qiu2, Bin Meng4, Fang-Hao Wan1 and Yin-Zheng Wang2 1State Key Laboratory for Biology of Plant Diseases and Insect Pests, Institute of Plant Protection, Chinese Academy of Agricultural Sciences, Beijing 100094, China; 2State Key Laboratory of Systematic and Evolutionary Botany, Institute of Botany, Chinese Academy of Sciences, Beijing 100093, China; 3State Key Laboratory of Resources and Environmental Information System, Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing 100101, China; 4College of Arts & Science of Beijing Union University, Beijing 100083, China Summary Authors for correspondence: • With growing concerns over serious ecological problems, a particular challenge Yin-Zheng Wang is to reveal the complex mechanisms underlying rapid expansion of invasive spe- Tel: +86 10 62836474 cies. Ageratina adenophora is of particular interest in addressing this question. Email: [email protected] • We used geographic information systems and logistic regression to identify the Fang-Hao Wan geographic and environmental factors contributing to the presence of A. Tel: +86 10 82105927 adenophora. Join-count spatial statistics with reproduction mode examination Email: [email protected] were employed to elucidate the spatiotemporal dispersal mechanisms. Received: 24 October 2010 • Multiple factors have significantly contributed to the rapid expansion of A. Accepted: 3 March 2011 adenophora. Its biological traits, favoring dispersal by water and wind coupled with local spatiotemporally heterogeneous geography and ecology, promote inva- New Phytologist (2011) sion downstream and upstream along river valleys, while other factors associated doi: 10.1111/j.1469-8137.2011.03720.x with human activities facilitate its invasion over high mountains and across river valleys, providing new scope for progressive invasions.