Predicting Web Searcher Satisfaction with Existing Community-Based Answers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Recommending Best Answer in a Collaborative Question Answering System
RECOMMENDING BEST ANSWER IN A COLLABORATIVE QUESTION ANSWERING SYSTEM Mrs Lin Chen Submitted in fulfilment of the requirements for the degree of Master of Information Technology (Research) School of Information Technology Faculty of Science & Technology Queensland University of Technology 2009 Recommending Best Answer in a Collaborative Question Answering System Page i Keywords Authority, Collaborative Social Network, Content Analysis, Link Analysis, Natural Language Processing, Non-Content Analysis, Online Question Answering Portal, Prestige, Question Answering System, Recommending Best Answer, Social Network Analysis, Yahoo! Answers. © 2009 Lin Chen Page i Recommending Best Answer in a Collaborative Question Answering System Page ii © 2009 Lin Chen Page ii Recommending Best Answer in a Collaborative Question Answering System Page iii Abstract The World Wide Web has become a medium for people to share information. People use Web- based collaborative tools such as question answering (QA) portals, blogs/forums, email and instant messaging to acquire information and to form online-based communities. In an online QA portal, a user asks a question and other users can provide answers based on their knowledge, with the question usually being answered by many users. It can become overwhelming and/or time/resource consuming for a user to read all of the answers provided for a given question. Thus, there exists a need for a mechanism to rank the provided answers so users can focus on only reading good quality answers. The majority of online QA systems use user feedback to rank users’ answers and the user who asked the question can decide on the best answer. Other users who didn’t participate in answering the question can also vote to determine the best answer. -
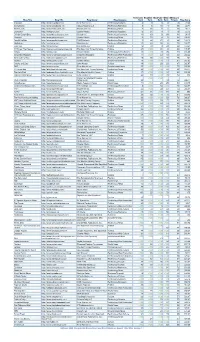
Blog Title Blog URL Blog Owner Blog Category Technorati Rank
Technorati Bloglines BlogPulse Wikio SEOmoz’s Blog Title Blog URL Blog Owner Blog Category Rank Rank Rank Rank Trifecta Blog Score Engadget http://www.engadget.com Time Warner Inc. Technology/Gadgets 4 3 6 2 78 19.23 Boing Boing http://www.boingboing.net Happy Mutants LLC Technology/Marketing 5 6 15 4 89 33.71 TechCrunch http://www.techcrunch.com TechCrunch Inc. Technology/News 2 27 2 1 76 42.11 Lifehacker http://lifehacker.com Gawker Media Technology/Gadgets 6 21 9 7 78 55.13 Official Google Blog http://googleblog.blogspot.com Google Inc. Technology/Corporate 14 10 3 38 94 69.15 Gizmodo http://www.gizmodo.com/ Gawker Media Technology/News 3 79 4 3 65 136.92 ReadWriteWeb http://www.readwriteweb.com RWW Network Technology/Marketing 9 56 21 5 64 142.19 Mashable http://mashable.com Mashable Inc. Technology/Marketing 10 65 36 6 73 160.27 Daily Kos http://dailykos.com/ Kos Media, LLC Politics 12 59 8 24 63 163.49 NYTimes: The Caucus http://thecaucus.blogs.nytimes.com The New York Times Company Politics 27 >100 31 8 93 179.57 Kotaku http://kotaku.com Gawker Media Technology/Video Games 19 >100 19 28 77 216.88 Smashing Magazine http://www.smashingmagazine.com Smashing Magazine Technology/Web Production 11 >100 40 18 60 283.33 Seth Godin's Blog http://sethgodin.typepad.com Seth Godin Technology/Marketing 15 68 >100 29 75 284 Gawker http://www.gawker.com/ Gawker Media Entertainment News 16 >100 >100 15 81 287.65 Crooks and Liars http://www.crooksandliars.com John Amato Politics 49 >100 33 22 67 305.97 TMZ http://www.tmz.com Time Warner Inc. -

Location-Based Services: Industrial and Business Analysis Group 6 Table of Contents
Location-based Services Industrial and Business Analysis Group 6 Huanhuan WANG Bo WANG Xinwei YANG Han LIU Location-based Services: Industrial and Business Analysis Group 6 Table of Contents I. Executive Summary ................................................................................................................................................. 2 II. Introduction ............................................................................................................................................................ 3 III. Analysis ................................................................................................................................................................ 3 IV. Evaluation Model .................................................................................................................................................. 4 V. Model Implementation ........................................................................................................................................... 6 VI. Evaluation & Impact ........................................................................................................................................... 12 VII. Conclusion ........................................................................................................................................................ 16 1 Location-based Services: Industrial and Business Analysis Group 6 I. Executive Summary The objective of the report is to analyze location-based services (LBS) from the industrial -

Sustaining Software Innovation from the Client to the Web Working Paper
Principles that Matter: Sustaining Software Innovation from the Client to the Web Marco Iansiti Working Paper 09-142 Copyright © 2009 by Marco Iansiti Working papers are in draft form. This working paper is distributed for purposes of comment and discussion only. It may not be reproduced without permission of the copyright holder. Copies of working papers are available from the author. Principles that Matter: Sustaining Software Innovation 1 from the Client to the Web Marco Iansiti David Sarnoff Professor of Business Administration Director of Research Harvard Business School Boston, MA 02163 June 15, 2009 1 The early work for this paper was based on a project funded by Microsoft Corporation. The author has consulted for a variety of companies in the information technology sector. The author would like to acknowledge Greg Richards and Robert Bock from Keystone Strategy LLC for invaluable suggestions. 1. Overview The information technology industry forms an ecosystem that consists of thousands of companies producing a vast array of interconnected products and services for consumers and businesses. This ecosystem was valued at more than $3 Trillion in 2008.2 More so than in any other industry, unique opportunities for new technology products and services stem from the ability of IT businesses to build new offerings in combination with existing technologies. This creates an unusual degree of interdependence among information technology products and services and, as a result, unique opportunities exist to encourage competition and innovation. In the growing ecosystem of companies that provide software services delivered via the internet - or “cloud computing” - the opportunities and risks are compounded by a significant increase in interdependence between products and services. -

The Topic of Terrorism on Yahoo! Answers : Questions, Answers and Users’ Anonymity
This is a repository copy of The Topic of Terrorism on Yahoo! Answers : Questions, Answers and Users’ Anonymity. White Rose Research Online URL for this paper: https://eprints.whiterose.ac.uk/154122/ Version: Accepted Version Article: Chua, Alton Y.K. and Banerjee, Snehasish orcid.org/0000-0001-6355-0470 (2020) The Topic of Terrorism on Yahoo! Answers : Questions, Answers and Users’ Anonymity. Aslib Journal of Information Management. pp. 1-16. ISSN 2050-3806 https://doi.org/10.1108/AJIM-08-2019-0204 Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Aslib Journal of Information Management Aslib Journal of Information Management The Topic of Terrorism on Yahoo! Answers: Questions, Answers and Users’ Anonymity Journal: Aslib Journal of Information Management Manuscript ID AJIM-08-2019-0204.R1 Manuscript Type: Research Paper Community question answering, online anonymity, online hate speech, Keywords: Terrorism, Question themes, Answer characteristics Page 1 of 34 Aslib Journal of Information Management 1 2 3 The Topic of Terrorism on Yahoo! Answers: Questions, Answers and Users’ Anonymity 4 Aslib Journal of Information Management 5 6 7 8 Abstract 9 10 Purpose: This paper explores the use of community question answering sites (CQAs) on the 11 12 13 topic of terrorism. -

2019-09-23-UNGA-Release 0.Pdf
News Release FOR IMMEDIATE RELEASE Media contact: September 23, 2019 Bernadette Brijlall [email protected] Alex Martinetti [email protected] Ground-Breaking Immersive Installation Brings to Life Urgency of Climate Action What you need to know: 2019 Climate Action Summit kicked off with an immersive look at devasting impacts of climate change, produced by RYOT a Verizon Media company. Verizon to focus its support of the Sustainable Development Goals (SDGs), emphasizing SDG 4: Quality Education and SDG 13: Climate Action, through social responsibility programs such as Verizon Innovative Learning and the company's sustainability efforts. New York, New York (September 23, 2019) – As world leaders and diplomats convene for the 74th United Nations General Assembly (UNGA), Verizon continues to focus on responsible business and the power of cutting-edge technology to deliver compelling story-telling that reinforces the need for urgent climate action. During UNGA, Verizon will focus on its support of the Sustainable Development Goals (SDGs), emphasizing SDG 4: Quality Education and SDG 13: Climate Action, through social responsibility programs such as Verizon Innovative Learning and the company's sustainability efforts. Verizon has also joined the UN Global Compact, as part of a long-term pledge to a principles-based approach to corporate sustainability that upholds a commitment to people and the planet. As part of UNGA, the 2019 Climate Action Summit kicked off with an immersive look at the devastating impacts climate change is having right now, as well as the vast opportunities ahead as the world moves from the grey to the green economy, with technological innovation playing a key role. -

Why Google Dominates Advertising Markets Competition Policy Should Lean on the Principles of Financial Market Regulation
Why Google Dominates Advertising Markets Competition Policy Should Lean on the Principles of Financial Market Regulation Dina Srinivasan* * Since leaving the industry, and authoring The Antitrust Case Against Face- book, I continue to research and write about the high-tech industry and competition, now as a fellow with Yale University’s antitrust initiative, the Thurman Arnold Pro- ject. Separately, I have advised and consulted on antitrust matters, including for news publishers whose interests are in conflict with Google’s. This Article is not squarely about antitrust, though it is about Google’s conduct in advertising markets, and the idea for writing a piece like this first germinated in 2014. At that time, Wall Street was up in arms about a book called FLASH BOYS by Wall Street chronicler Michael Lewis about speed, data, and alleged manipulation in financial markets. The controversy put high speed trading in the news, giving many of us in advertising pause to appre- ciate the parallels between our market and trading in financial markets. Since then, I have noted how problems related to speed and data can distort competition in other electronic trading markets, how lawmakers have monitored these markets for con- duct they frown upon in equities trading, but how advertising has largely remained off the same radar. This Article elaborates on these observations and curiosities. I am indebted to and thank the many journalists that painstakingly reported on industry conduct, the researchers and scholars whose work I cite, Fiona Scott Morton and Aus- tin Frerick at the Thurman Arnold Project for academic support, as well as Tom Fer- guson and the Institute for New Economic Thinking for helping to fund the research this project entailed. -

Ad Tech Inquiry: Issues Paper Response from Verizon Media
ACCC - Ad tech Inquiry: Issues Paper Response from Verizon Media Australia April 2020 1. Introduction 1.1. Verizon Media is pleased to provide these initial comments in response to the issues paper. We support competition authorities deepening their understanding of the digital advertising market, to fully understand the competitive dynamics and broader context - regulatory, contractual, and otherwise - within which competition takes place. 1.2. The inquiry impacts our business at all levels. Verizon Media is active in the advertising market as an advertiser, media owner and advertising intermediary. 2. About Verizon Media 2.1. Verizon Media is a global house of digital media and technology brands. Verizon Media’s brands include Yahoo, AOL, Ryot, HuffPost, TechCrunch and BUILD. Through our own operations, and in partnership with others, Verizon Media helps drive diversity and choice in consumer services and brand advertising. 2.2. Verizon Media is a business division of Verizon Communications Inc. Verizon Media operates in Australia as Verizon Media Australia Pty Ltd. 3. General comments 3.1. The digital advertising market provides benefits to both businesses and consumers. Revenue generated by digital advertising funds content creation and is critical for fueling investment in platforms, content creation and journalism. Competition in the ad intermediation market provides publishers the ability to partner with multiple platforms and to maximise the value of their inventory. In turn, this promotes plurality by providing a sustainable revenue stream for digital media. Consumers, in turn, reap the benefits of more diverse media. 3.2. We welcome the ACCC’s commitment to detailed evidence-gathering and analysis. -

Networking Best Practices for Large Deployments Google, Inc
Networking Best Practices for Large Deployments Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com Part number: NETBP_GAPPS_3.8 November 16, 2016 © Copyright 2016 Google, Inc. All rights reserved. Google, the Google logo, G Suite, Gmail, Google Docs, Google Calendar, Google Sites, Google+, Google Talk, Google Hangouts, Google Drive, Gmail are trademarks, registered trademarks, or service marks of Google Inc. All other trademarks are the property of their respective owners. Use of any Google solution is governed by the license agreement included in your original contract. Any intellectual property rights relating to the Google services are and shall remain the exclusive property of Google, Inc. and/or its subsidiaries (“Google”). You may not attempt to decipher, decompile, or develop source code for any Google product or service offering, or knowingly allow others to do so. Google documentation may not be sold, resold, licensed or sublicensed and may not be transferred without the prior written consent of Google. Your right to copy this manual is limited by copyright law. Making copies, adaptations, or compilation works, without prior written authorization of Google. is prohibited by law and constitutes a punishable violation of the law. No part of this manual may be reproduced in whole or in part without the express written consent of Google. Copyright © by Google Inc. Google provides this publication “as is” without warranty of any either express or implied, including but not limited to the implied warranties of merchantability or fitness for a particular purpose. Google Inc. may revise this publication from time to time without notice. -

Ronto Colostate 0053N 10925.Pdf (291.1Kb)
THESIS WHAT IS GOING ON IN THE BLOGOSPHERE: AN EXPLORATORY STUDY OF HOW CONSUMERS AND COMPANIES USE WEBLOGS IN THE MARKETING AND COMMUNICATION PROCESS Submitted by Paul Ronto Department of Journalism and Technical Communication In partial fulfillment of the requirements For the Degree of Master of Science Colorado State University Fort Collins, Colorado Spring 2012 Master’s Committee : Advisor: Jamie Switzer Joseph Champ Joseph Cannon ABSTRACT WHAT IS GOING ON IN THE BLOGOSPHERE: AN EXPLORATORY STUDY OF HOW CONSUMERS AND COMPANIES USE WEBLOGS IN THE MARKETING AND COMMUNICATION PROCESS In the past few years weblogs have become a major channel for publishing content over the Internet. With the popularity of social media as a medium to communicate with consumers, companies around the world have started using weblogs as part of their communication strategy. However there remains a void of literature on company blogging, and users still do not have a solid understanding of how and why both consumers and companies are using this tool. This is an exploratory study into the world of company blogging, and it aims to add some insight as to what is going on in the blogosphere. Qualitative interviews were conducted with participants representing both the company and consumer perspective. The results indicate that although some companies believe having a blog is important, this belief is based more on blind faith in the medium than actual measurable data. The companies studied showed that their blogging strategy was very casual and the actual benefits to the company or consumer needs were not taken into account. From the consumer perspective, blogs were viewed as a tool to gather information and a place where a consumer would hopefully receive some sort of value for their time. -

Google Ngram Viewer by Andrew Weiss
Google Ngram Viewer By Andrew Weiss Digital Services Librarian California State University, Northridge Introduction: Google, mass digitization and the emerging science of culturonomics Google Books famously launched in 2004 with great fanfare and controversy. Two stated original goals for this ambitious digitization project were to replace the generic library card catalog with their new “virtual” one and to scan all the books that have ever been published, which by a Google employee’s reckoning is approximately 129 million books. (Google 2014) (Jackson 2010) Now ten years in, the Google Books mass-digitization project as of May 2014 has claimed to have scanned over 30 million books, a little less than 24% of their overt goal. Considering the enormity of their vision for creating this new type of massive digital library their progress has been astounding. However, controversies have also dominated the headlines. At the time of the Google announcement in 2004 Jean Noel Jeanneney, head of Bibliothèque nationale de France at the time, famously called out Google’s strategy as excessively Anglo-American and dangerously corporate-centric. (Jeanneney 2007) Entrusting a corporation to the digitization and preservation of a diverse world-wide corpus of books, Jeanneney argues, is a dangerous game, especially when ascribing a bottom-line economic equivalent figure to cultural works of inestimable personal, national and international value. Over the ten years since his objections were raised, many of his comments remain prescient and relevant to the problems and issues the project currently faces. Google Books still faces controversies related to copyright, as seen in the current appeal of the Author’s Guild v. -

The Power of Google: Serving Consumers Or Threatening Competition? Hearing Committee on the Judiciary United States Senate
S. HRG. 112–168 THE POWER OF GOOGLE: SERVING CONSUMERS OR THREATENING COMPETITION? HEARING BEFORE THE SUBCOMMITTEE ON ANTITRUST, COMPETITION POLICY AND CONSUMER RIGHTS OF THE COMMITTEE ON THE JUDICIARY UNITED STATES SENATE ONE HUNDRED TWELFTH CONGRESS FIRST SESSION SEPTEMBER 21, 2011 Serial No. J–112–43 Printed for the use of the Committee on the Judiciary ( U.S. GOVERNMENT PRINTING OFFICE 71–471 PDF WASHINGTON : 2011 For sale by the Superintendent of Documents, U.S. Government Printing Office Internet: bookstore.gpo.gov Phone: toll free (866) 512–1800; DC area (202) 512–1800 Fax: (202) 512–2104 Mail: Stop IDCC, Washington, DC 20402–0001 VerDate Nov 24 2008 11:11 Dec 21, 2011 Jkt 071471 PO 00000 Frm 00001 Fmt 5011 Sfmt 5011 S:\GPO\HEARINGS\71471.TXT SJUD1 PsN: CMORC COMMITTEE ON THE JUDICIARY PATRICK J. LEAHY, Vermont, Chairman HERB KOHL, Wisconsin CHUCK GRASSLEY, Iowa DIANNE FEINSTEIN, California ORRIN G. HATCH, Utah CHUCK SCHUMER, New York JON KYL, Arizona DICK DURBIN, Illinois JEFF SESSIONS, Alabama SHELDON WHITEHOUSE, Rhode Island LINDSEY GRAHAM, South Carolina AMY KLOBUCHAR, Minnesota JOHN CORNYN, Texas AL FRANKEN, Minnesota MICHAEL S. LEE, Utah CHRISTOPHER A. COONS, Delaware TOM COBURN, Oklahoma RICHARD BLUMENTHAL, Connecticut BRUCE A. COHEN, Chief Counsel and Staff Director KOLAN DAVIS, Republican Chief Counsel and Staff Director SUBCOMMITTEE ON ANTITRUST, COMPETITION POLICY AND CONSUMER RIGHTS HERB KOHL, Wisconsin, Chairman CHUCK SCHUMER, New York MICHAEL S. LEE, Utah AMY KLOBUCHAR, Minnesota CHUCK GRASSLEY, Iowa AL FRANKEN, Minnesota JOHN CORNYN, Texas RICHARD BLUMENTHAL, Connecticut CAROLINE HOLLAND, Democratic Chief Counsel/Staff Director DAVID BARLOW, Republican General Counsel (II) VerDate Nov 24 2008 11:11 Dec 21, 2011 Jkt 071471 PO 00000 Frm 00002 Fmt 5904 Sfmt 5904 S:\GPO\HEARINGS\71471.TXT SJUD1 PsN: CMORC C O N T E N T S STATEMENTS OF COMMITTEE MEMBERS Page Feinstein, Hon.