Digital Image Basics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
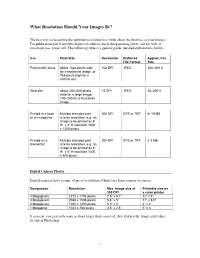
What Resolution Should Your Images Be?
What Resolution Should Your Images Be? The best way to determine the optimum resolution is to think about the final use of your images. For publication you’ll need the highest resolution, for desktop printing lower, and for web or classroom use, lower still. The following table is a general guide; detailed explanations follow. Use Pixel Size Resolution Preferred Approx. File File Format Size Projected in class About 1024 pixels wide 102 DPI JPEG 300–600 K for a horizontal image; or 768 pixels high for a vertical one Web site About 400–600 pixels 72 DPI JPEG 20–200 K wide for a large image; 100–200 for a thumbnail image Printed in a book Multiply intended print 300 DPI EPS or TIFF 6–10 MB or art magazine size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1800 x 1200 pixels. Printed on a Multiply intended print 200 DPI EPS or TIFF 2-3 MB laserwriter size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1200 x 800 pixels. Digital Camera Photos Digital cameras have a range of preset resolutions which vary from camera to camera. Designation Resolution Max. Image size at Printable size on 300 DPI a color printer 4 Megapixels 2272 x 1704 pixels 7.5” x 5.7” 12” x 9” 3 Megapixels 2048 x 1536 pixels 6.8” x 5” 11” x 8.5” 2 Megapixels 1600 x 1200 pixels 5.3” x 4” 6” x 4” 1 Megapixel 1024 x 768 pixels 3.5” x 2.5” 5” x 3 If you can, you generally want to shoot larger than you need, then sharpen the image and reduce its size in Photoshop. -

Invention of Digital Photograph
Invention of Digital photograph Digital photography uses cameras containing arrays of electronic photodetectors to capture images focused by a lens, as opposed to an exposure on photographic film. The captured images are digitized and stored as a computer file ready for further digital processing, viewing, electronic publishing, or digital printing. Until the advent of such technology, photographs were made by exposing light sensitive photographic film and paper, which was processed in liquid chemical solutions to develop and stabilize the image. Digital photographs are typically created solely by computer-based photoelectric and mechanical techniques, without wet bath chemical processing. The first consumer digital cameras were marketed in the late 1990s.[1] Professionals gravitated to digital slowly, and were won over when their professional work required using digital files to fulfill the demands of employers and/or clients, for faster turn- around than conventional methods would allow.[2] Starting around 2000, digital cameras were incorporated in cell phones and in the following years, cell phone cameras became widespread, particularly due to their connectivity to social media websites and email. Since 2010, the digital point-and-shoot and DSLR formats have also seen competition from the mirrorless digital camera format, which typically provides better image quality than the point-and-shoot or cell phone formats but comes in a smaller size and shape than the typical DSLR. Many mirrorless cameras accept interchangeable lenses and have advanced features through an electronic viewfinder, which replaces the through-the-lens finder image of the SLR format. While digital photography has only relatively recently become mainstream, the late 20th century saw many small developments leading to its creation. -

Foveon FO18-50-F19 4.5 MP X3 Direct Image Sensor
® Foveon FO18-50-F19 4.5 MP X3 Direct Image Sensor Features The Foveon FO18-50-F19 is a 1/1.8-inch CMOS direct image sensor that incorporates breakthrough Foveon X3 technology. Foveon X3 direct image sensors Foveon X3® Technology • A stack of three pixels captures superior color capture full-measured color images through a unique stacked pixel sensor design. fidelity by measuring full color at every point By capturing full-measured color images, the need for color interpolation and in the captured image. artifact-reducing blur filters is eliminated. The Foveon FO18-50-F19 features the • Images have improved sharpness and immunity to color artifacts (moiré). powerful VPS (Variable Pixel Size) capability. VPS provides the on-chip capabil- • Foveon X3 technology directly converts light ity of grouping neighboring pixels together to form larger pixels that are optimal of all colors into useful signal information at every point in the captured image—no light for high frame rate, reduced noise, or dual mode still/video applications. Other absorbing filters are used to block out light. advanced features include: low fixed pattern noise, ultra-low power consumption, Variable Pixel Size (VPS) Capability and integrated digital control. • Neighboring pixels can be grouped together on-chip to obtain the effect of a larger pixel. • Enables flexible video capture at a variety of resolutions. • Enables higher ISO mode at lower resolutions. Analog Biases Row Row Digital Supplies • Reduces noise by combining pixels. Pixel Array Analog Supplies Readout Reset 1440 columns x 1088 rows x 3 layers On-Chip A/D Conversion Control Control • Integrated 12-bit A/D converter running at up to 40 MHz. -

Single-Pixel Imaging Via Compressive Sampling
© DIGITAL VISION Single-Pixel Imaging via Compressive Sampling [Building simpler, smaller, and less-expensive digital cameras] Marco F. Duarte, umans are visual animals, and imaging sensors that extend our reach— [ cameras—have improved dramatically in recent times thanks to the intro- Mark A. Davenport, duction of CCD and CMOS digital technology. Consumer digital cameras in Dharmpal Takhar, the megapixel range are now ubiquitous thanks to the happy coincidence that the semiconductor material of choice for large-scale electronics inte- Jason N. Laska, Ting Sun, Hgration (silicon) also happens to readily convert photons at visual wavelengths into elec- Kevin F. Kelly, and trons. On the contrary, imaging at wavelengths where silicon is blind is considerably Richard G. Baraniuk more complicated, bulky, and expensive. Thus, for comparable resolution, a US$500 digi- ] tal camera for the visible becomes a US$50,000 camera for the infrared. In this article, we present a new approach to building simpler, smaller, and cheaper digital cameras that can operate efficiently across a much broader spectral range than conventional silicon-based cameras. Our approach fuses a new camera architecture Digital Object Identifier 10.1109/MSP.2007.914730 1053-5888/08/$25.00©2008IEEE IEEE SIGNAL PROCESSING MAGAZINE [83] MARCH 2008 based on a digital micromirror device (DMD—see “Spatial Light Our “single-pixel” CS camera architecture is basically an Modulators”) with the new mathematical theory and algorithms optical computer (comprising a DMD, two lenses, a single pho- of compressive sampling (CS—see “CS in a Nutshell”). ton detector, and an analog-to-digital (A/D) converter) that com- CS combines sampling and compression into a single non- putes random linear measurements of the scene under view. -

1/2-Inch Megapixel CMOS Digital Image Sensor
MT9M001: 1/2-Inch Megapixel Digital Image Sensor Features 1/2-Inch Megapixel CMOS Digital Image Sensor MT9M001C12STM (Monochrome) Datasheet, Rev. M For the latest datasheet, please visit www.onsemi.com Features Table 1: Key Performance Parameters Parameter Value • Array Format (5:4): 1,280H x 1,024V (1,310,720 active Optical format 1/2-inch (5:4) pixels). Total (incl. dark pixels): 1,312H x 1,048V Active imager size 6.66 mm (H) x 5.32 mm (V) (1,374,976 pixels) • Frame Rate: 30 fps progressive scan; programmable Active pixels 1,280 H x 1,024 V • Shutter: Electronic Rolling Shutter (ERS) Pixel size 5.2 m x 5.2 m • Window Size: SXGA; programmable to any smaller Shutter type Electronic rolling shutter (ERS) Maximum data rate/ format (VGA, QVGA, CIF, QCIF, etc.) 48 MPS/48 MHz • Programmable Controls: Gain, frame rate, frame size master clock Frame SXGA 30 fps progressive scan; rate (1280 x 1024) programmable Applications ADC resolution 10-bit, on-chip Responsivity 2.1 V/lux-sec • Digital still cameras Dynamic range 68.2 dB • Digital video cameras •PC cameras SNRMAX 45 dB Supply voltage 3.0 V3.6 V, 3.3 V nominal 363 mW at 3.3 V (operating); Power consumption General Description 294 W (standby) Operating temperature 0°C to +70°C The ON Semiconductor MT9M001 is an SXGA-format with a 1/2-inch CMOS active-pixel digital image sen- Packaging 48-pin CLCC sor. The active imaging pixel array of 1,280H x 1,024V. It The sensor can be operated in its default mode or pro- incorporates sophisticated camera functions on-chip grammed by the user for frame size, exposure, gain set- such as windowing, column and row skip mode, and ting, and other parameters. -

More About Digital Cameras Image Characteristics Several Important
More about Digital Cameras Image Characteristics Several important characteristics of digital images include: Physical Size How big is the image that has been captured, as measured in inches or pixels? File Size How large is the computer file that makes up the image, as measured in kilobytes or megabytes? Pixels All digital images taken with a digital camera are made up of pixels (short for picture elements). A pixel is the smallest part (sometimes called a point or a dot) of a digital image and the total number of pixels make up the image and help determine its size and its resolution, or how much information is included in the image when we view it. Generally speaking, the larger the number of pixels an image contains, the sharper it will appear, especially when it is enlarged, which is what happens when we want to print our photographs larger than will fit into small 3 1\2 X 5 inch or 5 X 7 inch frames. You will notice in the first picture below that the Grand Canyon is in sharp focus and there is a large amount of detail in the image. However, when the image is enlarged to an extreme level, the individual pixels that make up the image are visible--and the image is no longer clear and sharp. Megapixels The term megapixels means one million pixels. When we discuss how sharp a digital image is or how much resolution it has, we usually refer to the number of megapixels that make up the image. One of the biggest selling features of digital cameras is the number of megapixels it is capable of producing when a picture is taken. -

One Is Enough. a Photograph Taken by the “Single-Pixel Camera” Built by Richard Baraniuk and Kevin Kelly of Rice University
One is Enough. A photograph taken by the “single-pixel camera” built by Richard Baraniuk and Kevin Kelly of Rice University. (a) A photograph of a soccer ball, taken by a conventional digital camera at 64 64 resolution. (b) The same soccer ball, photographed by a single-pixel camera. The image is de- rived× mathematically from 1600 separate, randomly selected measurements, using a method called compressed sensing. (Photos courtesy of R. G. Baraniuk, Compressive Sensing [Lecture Notes], Signal Processing Magazine, July 2007. c 2007 IEEE.) 114 What’s Happening in the Mathematical Sciences Compressed Sensing Makes Every Pixel Count rash and computer files have one thing in common: compactisbeautiful.Butifyou’veevershoppedforadigi- Ttal camera, you might have noticed that camera manufac- turers haven’t gotten the message. A few years ago, electronic stores were full of 1- or 2-megapixel cameras. Then along came cameras with 3-megapixel chips, 10 megapixels, and even 60 megapixels. Unfortunately, these multi-megapixel cameras create enor- mous computer files. So the first thing most people do, if they plan to send a photo by e-mail or post it on the Web, is to com- pact it to a more manageable size. Usually it is impossible to discern the difference between the compressed photo and the original with the naked eye (see Figure 1, next page). Thus, a strange dynamic has evolved, in which camera engineers cram more and more data onto a chip, while software engineers de- Emmanuel Candes. (Photo cour- sign cleverer and cleverer ways to get rid of it. tesy of Emmanuel Candes.) In 2004, mathematicians discovered a way to bring this “armsrace”to a halt. -

Making the Transition from Film to Digital
TECHNICAL PAPER Making the Transition from Film to Digital TABLE OF CONTENTS Photography became a reality in the 1840s. During this time, images were recorded on 2 Making the transition film that used particles of silver salts embedded in a physical substrate, such as acetate 2 The difference between grain or gelatin. The grains of silver turned dark when exposed to light, and then a chemical and pixels fixer made that change more or less permanent. Cameras remained pretty much the 3 Exposure considerations same over the years with features such as a lens, a light-tight chamber to hold the film, 3 This won’t hurt a bit and an aperture and shutter mechanism to control exposure. 3 High-bit images But the early 1990s brought a dramatic change with the advent of digital technology. 4 Why would you want to use a Instead of using grains of silver embedded in gelatin, digital photography uses silicon to high-bit image? record images as numbers. Computers process the images, rather than optical enlargers 5 About raw files and tanks of often toxic chemicals. Chemically-developed wet printing processes have 5 Saving a raw file given way to prints made with inkjet printers, which squirt microscopic droplets of ink onto paper to create photographs. 5 Saving a JPEG file 6 Pros and cons 6 Reasons to shoot JPEG 6 Reasons to shoot raw 8 Raw converters 9 Reading histograms 10 About color balance 11 Noise reduction 11 Sharpening 11 It’s in the cards 12 A matter of black and white 12 Conclusion Snafellnesjokull Glacier Remnant. -

Oxnard Course Outline
Course ID: DMS R120B Curriculum Committee Approval Date: 04/25/2018 Catalog Start Date: Fall 2018 COURSE OUTLINE OXNARD COLLEGE I. Course Identification and Justification: A. Proposed course id: DMS R120B Banner title: AdobePhotoShop II Full title: Adobe PhotoShop II B. Reason(s) course is offered: This course provides the development of skills necessary to combine the use of Photoshop digital image editing software with Adobe LightRoom's expanded digital photographic image editing abilities. These skills will enhance a student’s ability to enter into employment positions such as web master, graphics design, and digital image processing. C. C-ID: 1. C-ID Descriptor: 2. C-ID Status: D. Co-listed as: Current: None II. Catalog Information: A. Units: Current: 3.00 B. Course Hours: 1. In-Class Contact Hours: Lecture: 43.75 Activity: 0 Lab: 26.25 2. Total In-Class Contact Hours: 70 3. Total Outside-of-Class Hours: 87.5 4. Total Student Learning Hours: 157.5 C. Prerequisites, Corequisites, Advisories, and Limitations on Enrollment: 1. Prerequisites Current: DMS R120A: Adobe Photoshop I 2. Corequisites Current: 3. Advisories: Current: 4. Limitations on Enrollment: Current: D. Catalog description: Current: This course will continue the development of students’ skills in the use of Adobe Photoshop digital image editing software by integrating the enhanced editing capabilities of Adobe Lightroom into the Adobe Photoshop workflow. Students will learn how to “punch up” colors in specific areas of digital photographs, how to make dull-looking shots vibrant, remove distracting objects, straighten skewed shots and how to use Photoshop and Lightroom to create panoramas, edit Adobe raw DNG photos on mobile device, and apply Boundary Wrap to a merged panorama to prevent loss of detail in the image among other skills. -

Evaluation of the Foveon X3 Sensor for Astronomy
Evaluation of the Foveon X3 sensor for astronomy Anna-Lea Lesage, Matthias Schwarz [email protected], Hamburger Sternwarte October 2009 Abstract Foveon X3 is a new type of CMOS colour sensor. We present here an evaluation of this sensor for the detection of transit planets. Firstly, we determined the gain , the dark current and the read out noise of each layer. Then the sensor was used for observations of Tau Bootes. Finally half of the transit of HD 189733 b could be observed. 1 Introduction The detection of exo-planet with the transit method relies on the observation of a diminution of the ux of the host star during the passage of the planet. This is visualised in time as a small dip in the light curve of the star. This dip represents usually a decrease of 1% to 3% of the magnitude of the star. Its detection is highly dependent of the stability of the detector, providing a constant ux for the star. However ground based observations are limited by the inuence of the atmosphere. The latter induces two eects : seeing which blurs the image of the star, and scintillation producing variation of the apparent magnitude of the star. The seeing can be corrected through the utilisation of an adaptive optic. Yet the eect of scintillation have to be corrected by the observation of reference stars during the observation time. The perturbation induced by the atmosphere are mostly wavelength independent. Thus, record- ing two identical images but at dierent wavelengths permit an identication of the wavelength independent eects. -

Use and Analysis of Color Models in Image Processing
cess Pro ing d & o o T F e c f h o Sharma and Nayyer, J Food Process Technol 2015, 7:1 n l o a l n o DOI: 10.4172/2157-7110.1000533 r Journal of Food g u y o J Processing & Technology ISSN: 2157-7110 Perspective Open Access Use and Analysis of Color Models in Image Processing Bhubneshwar Sharma* and Rupali Nayyer Department of Electronics and Communication Engineering, S.S.C.E.T, Punjab Technical University, India Abstract The use of color image processing is divided by two factors. First color is used in object identification and simplifies extraction from a scene and color is powerful descriptor. Second, humans can use thousands of color shades and intensities. Color Image Processing is divided into two areas full color and pseudo-color processing. In this processing various color models are used that are based on color recognition, color components etc. A few papers on various applications such as lane detection, face detection, fruit quality evaluation etc based on these color models have been published. A survey on widely used models RGB, HSI, HSV, RGI, etc. is represented in this paper. Keywords: Image processing; Color models; RGB; HIS; HSV; RGI for matter surfaces, while ignoring ambient light, normalized RGB is invariant (under certain assumptions) to changes of surface orientation Introduction relatively to the light source. This, together with the transformation An image may be defined as a two dimensional function, f(x, y), simplicity helped this color space to gain popularity among the where x and y are spatial coordinates and the amplitude of f at any researchers [5-7] (Figure 1). -

ELEC 7450 - Digital Image Processing Image Acquisition
I indirect imaging techniques, e.g., MRI (Fourier), CT (Backprojection) I physical quantities other than intensities are measured I computation leads to 2-D map displayed as intensity Image acquisition Digital images are acquired by I direct digital acquisition (digital still/video cameras), or I scanning material acquired as analog signals (slides, photographs, etc.). I In both cases, the digital sensing element is one of the following: Line array Area array Single sensor Stanley J. Reeves ELEC 7450 - Digital Image Processing Image acquisition Digital images are acquired by I direct digital acquisition (digital still/video cameras), or I scanning material acquired as analog signals (slides, photographs, etc.). I In both cases, the digital sensing element is one of the following: Line array Area array Single sensor I indirect imaging techniques, e.g., MRI (Fourier), CT (Backprojection) I physical quantities other than intensities are measured I computation leads to 2-D map displayed as intensity Stanley J. Reeves ELEC 7450 - Digital Image Processing Single sensor acquisition Stanley J. Reeves ELEC 7450 - Digital Image Processing Linear array acquisition Stanley J. Reeves ELEC 7450 - Digital Image Processing Two types of quantization: I spatial: limited number of pixels I gray-level: limited number of bits to represent intensity at a pixel Array sensor acquisition I Irradiance incident at each photo-site is integrated over time I Resulting array of intensities is moved out of sensor array and into a buffer I Quantized intensities are stored as a grayscale image Stanley J. Reeves ELEC 7450 - Digital Image Processing Array sensor acquisition I Irradiance incident at each photo-site is integrated over time I Resulting array of intensities is moved out of sensor array and into a buffer I Quantized Two types of quantization: intensities are stored as a I spatial: limited number of pixels grayscale image I gray-level: limited number of bits to represent intensity at a pixel Stanley J.