Robust Pixel Classification for 3D Modeling with Structured Light
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
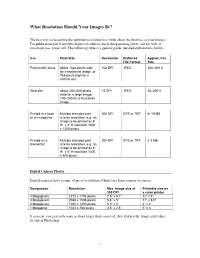
What Resolution Should Your Images Be?
What Resolution Should Your Images Be? The best way to determine the optimum resolution is to think about the final use of your images. For publication you’ll need the highest resolution, for desktop printing lower, and for web or classroom use, lower still. The following table is a general guide; detailed explanations follow. Use Pixel Size Resolution Preferred Approx. File File Format Size Projected in class About 1024 pixels wide 102 DPI JPEG 300–600 K for a horizontal image; or 768 pixels high for a vertical one Web site About 400–600 pixels 72 DPI JPEG 20–200 K wide for a large image; 100–200 for a thumbnail image Printed in a book Multiply intended print 300 DPI EPS or TIFF 6–10 MB or art magazine size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1800 x 1200 pixels. Printed on a Multiply intended print 200 DPI EPS or TIFF 2-3 MB laserwriter size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1200 x 800 pixels. Digital Camera Photos Digital cameras have a range of preset resolutions which vary from camera to camera. Designation Resolution Max. Image size at Printable size on 300 DPI a color printer 4 Megapixels 2272 x 1704 pixels 7.5” x 5.7” 12” x 9” 3 Megapixels 2048 x 1536 pixels 6.8” x 5” 11” x 8.5” 2 Megapixels 1600 x 1200 pixels 5.3” x 4” 6” x 4” 1 Megapixel 1024 x 768 pixels 3.5” x 2.5” 5” x 3 If you can, you generally want to shoot larger than you need, then sharpen the image and reduce its size in Photoshop. -

Foveon FO18-50-F19 4.5 MP X3 Direct Image Sensor
® Foveon FO18-50-F19 4.5 MP X3 Direct Image Sensor Features The Foveon FO18-50-F19 is a 1/1.8-inch CMOS direct image sensor that incorporates breakthrough Foveon X3 technology. Foveon X3 direct image sensors Foveon X3® Technology • A stack of three pixels captures superior color capture full-measured color images through a unique stacked pixel sensor design. fidelity by measuring full color at every point By capturing full-measured color images, the need for color interpolation and in the captured image. artifact-reducing blur filters is eliminated. The Foveon FO18-50-F19 features the • Images have improved sharpness and immunity to color artifacts (moiré). powerful VPS (Variable Pixel Size) capability. VPS provides the on-chip capabil- • Foveon X3 technology directly converts light ity of grouping neighboring pixels together to form larger pixels that are optimal of all colors into useful signal information at every point in the captured image—no light for high frame rate, reduced noise, or dual mode still/video applications. Other absorbing filters are used to block out light. advanced features include: low fixed pattern noise, ultra-low power consumption, Variable Pixel Size (VPS) Capability and integrated digital control. • Neighboring pixels can be grouped together on-chip to obtain the effect of a larger pixel. • Enables flexible video capture at a variety of resolutions. • Enables higher ISO mode at lower resolutions. Analog Biases Row Row Digital Supplies • Reduces noise by combining pixels. Pixel Array Analog Supplies Readout Reset 1440 columns x 1088 rows x 3 layers On-Chip A/D Conversion Control Control • Integrated 12-bit A/D converter running at up to 40 MHz. -

Single-Pixel Imaging Via Compressive Sampling
© DIGITAL VISION Single-Pixel Imaging via Compressive Sampling [Building simpler, smaller, and less-expensive digital cameras] Marco F. Duarte, umans are visual animals, and imaging sensors that extend our reach— [ cameras—have improved dramatically in recent times thanks to the intro- Mark A. Davenport, duction of CCD and CMOS digital technology. Consumer digital cameras in Dharmpal Takhar, the megapixel range are now ubiquitous thanks to the happy coincidence that the semiconductor material of choice for large-scale electronics inte- Jason N. Laska, Ting Sun, Hgration (silicon) also happens to readily convert photons at visual wavelengths into elec- Kevin F. Kelly, and trons. On the contrary, imaging at wavelengths where silicon is blind is considerably Richard G. Baraniuk more complicated, bulky, and expensive. Thus, for comparable resolution, a US$500 digi- ] tal camera for the visible becomes a US$50,000 camera for the infrared. In this article, we present a new approach to building simpler, smaller, and cheaper digital cameras that can operate efficiently across a much broader spectral range than conventional silicon-based cameras. Our approach fuses a new camera architecture Digital Object Identifier 10.1109/MSP.2007.914730 1053-5888/08/$25.00©2008IEEE IEEE SIGNAL PROCESSING MAGAZINE [83] MARCH 2008 based on a digital micromirror device (DMD—see “Spatial Light Our “single-pixel” CS camera architecture is basically an Modulators”) with the new mathematical theory and algorithms optical computer (comprising a DMD, two lenses, a single pho- of compressive sampling (CS—see “CS in a Nutshell”). ton detector, and an analog-to-digital (A/D) converter) that com- CS combines sampling and compression into a single non- putes random linear measurements of the scene under view. -

One Is Enough. a Photograph Taken by the “Single-Pixel Camera” Built by Richard Baraniuk and Kevin Kelly of Rice University
One is Enough. A photograph taken by the “single-pixel camera” built by Richard Baraniuk and Kevin Kelly of Rice University. (a) A photograph of a soccer ball, taken by a conventional digital camera at 64 64 resolution. (b) The same soccer ball, photographed by a single-pixel camera. The image is de- rived× mathematically from 1600 separate, randomly selected measurements, using a method called compressed sensing. (Photos courtesy of R. G. Baraniuk, Compressive Sensing [Lecture Notes], Signal Processing Magazine, July 2007. c 2007 IEEE.) 114 What’s Happening in the Mathematical Sciences Compressed Sensing Makes Every Pixel Count rash and computer files have one thing in common: compactisbeautiful.Butifyou’veevershoppedforadigi- Ttal camera, you might have noticed that camera manufac- turers haven’t gotten the message. A few years ago, electronic stores were full of 1- or 2-megapixel cameras. Then along came cameras with 3-megapixel chips, 10 megapixels, and even 60 megapixels. Unfortunately, these multi-megapixel cameras create enor- mous computer files. So the first thing most people do, if they plan to send a photo by e-mail or post it on the Web, is to com- pact it to a more manageable size. Usually it is impossible to discern the difference between the compressed photo and the original with the naked eye (see Figure 1, next page). Thus, a strange dynamic has evolved, in which camera engineers cram more and more data onto a chip, while software engineers de- Emmanuel Candes. (Photo cour- sign cleverer and cleverer ways to get rid of it. tesy of Emmanuel Candes.) In 2004, mathematicians discovered a way to bring this “armsrace”to a halt. -

Making the Transition from Film to Digital
TECHNICAL PAPER Making the Transition from Film to Digital TABLE OF CONTENTS Photography became a reality in the 1840s. During this time, images were recorded on 2 Making the transition film that used particles of silver salts embedded in a physical substrate, such as acetate 2 The difference between grain or gelatin. The grains of silver turned dark when exposed to light, and then a chemical and pixels fixer made that change more or less permanent. Cameras remained pretty much the 3 Exposure considerations same over the years with features such as a lens, a light-tight chamber to hold the film, 3 This won’t hurt a bit and an aperture and shutter mechanism to control exposure. 3 High-bit images But the early 1990s brought a dramatic change with the advent of digital technology. 4 Why would you want to use a Instead of using grains of silver embedded in gelatin, digital photography uses silicon to high-bit image? record images as numbers. Computers process the images, rather than optical enlargers 5 About raw files and tanks of often toxic chemicals. Chemically-developed wet printing processes have 5 Saving a raw file given way to prints made with inkjet printers, which squirt microscopic droplets of ink onto paper to create photographs. 5 Saving a JPEG file 6 Pros and cons 6 Reasons to shoot JPEG 6 Reasons to shoot raw 8 Raw converters 9 Reading histograms 10 About color balance 11 Noise reduction 11 Sharpening 11 It’s in the cards 12 A matter of black and white 12 Conclusion Snafellnesjokull Glacier Remnant. -

Evaluation of the Foveon X3 Sensor for Astronomy
Evaluation of the Foveon X3 sensor for astronomy Anna-Lea Lesage, Matthias Schwarz [email protected], Hamburger Sternwarte October 2009 Abstract Foveon X3 is a new type of CMOS colour sensor. We present here an evaluation of this sensor for the detection of transit planets. Firstly, we determined the gain , the dark current and the read out noise of each layer. Then the sensor was used for observations of Tau Bootes. Finally half of the transit of HD 189733 b could be observed. 1 Introduction The detection of exo-planet with the transit method relies on the observation of a diminution of the ux of the host star during the passage of the planet. This is visualised in time as a small dip in the light curve of the star. This dip represents usually a decrease of 1% to 3% of the magnitude of the star. Its detection is highly dependent of the stability of the detector, providing a constant ux for the star. However ground based observations are limited by the inuence of the atmosphere. The latter induces two eects : seeing which blurs the image of the star, and scintillation producing variation of the apparent magnitude of the star. The seeing can be corrected through the utilisation of an adaptive optic. Yet the eect of scintillation have to be corrected by the observation of reference stars during the observation time. The perturbation induced by the atmosphere are mostly wavelength independent. Thus, record- ing two identical images but at dierent wavelengths permit an identication of the wavelength independent eects. -

The Integrity of the Image
world press photo Report THE INTEGRITY OF THE IMAGE Current practices and accepted standards relating to the manipulation of still images in photojournalism and documentary photography A World Press Photo Research Project By Dr David Campbell November 2014 Published by the World Press Photo Academy Contents Executive Summary 2 8 Detecting Manipulation 14 1 Introduction 3 9 Verification 16 2 Methodology 4 10 Conclusion 18 3 Meaning of Manipulation 5 Appendix I: Research Questions 19 4 History of Manipulation 6 Appendix II: Resources: Formal Statements on Photographic Manipulation 19 5 Impact of Digital Revolution 7 About the Author 20 6 Accepted Standards and Current Practices 10 About World Press Photo 20 7 Grey Area of Processing 12 world press photo 1 | The Integrity of the Image – David Campbell/World Press Photo Executive Summary 1 The World Press Photo research project on “The Integrity of the 6 What constitutes a “minor” versus an “excessive” change is necessarily Image” was commissioned in June 2014 in order to assess what current interpretative. Respondents say that judgment is on a case-by-case basis, practice and accepted standards relating to the manipulation of still and suggest that there will never be a clear line demarcating these concepts. images in photojournalism and documentary photography are world- wide. 7 We are now in an era of computational photography, where most cameras capture data rather than images. This means that there is no 2 The research is based on a survey of 45 industry professionals from original image, and that all images require processing to exist. 15 countries, conducted using both semi-structured personal interviews and email correspondence, and supplemented with secondary research of online and library resources. -

Digital Camera Math! 37
Digital Camera Math! 37 Digital cameras are everywhere! They are in your cell phones, computers, iPads and countless other applications that you may not even be aware of. In astronomy, digital cameras were first developed in the 1970s to replace and extend photographic film techniques for detecting faint objects. Digital cameras are not only easy to operate and require no chemicals to make the images, but the data is already in digital form so that computers can quickly process the images. Commercially, digital cameras are referred to by the total number of pixels they contain. A ‘1 This is a 9200x9200 image sensor for a digital megapixel camera’ can have a square-shaped camera. The grey area contains the individual sensor with 1024x1024 pixels. This says nothing ‘pixel’ elements. Each square pixel is about 8 about the sensitivity of the camera, only how big an micrometers (8 microns) wide, and is sensitive image it can create from the camera lenses. to light. The pixels accumulate electrons as Although the largest commercial digital camera has light falls on them, and computers read out 80 megapixels in a 10328x7760 format, the largest each pixel and create the picture. astronomical camera developed for the Large Synoptic Survey Telescope uses 3200 megapixels (3.2 gigapixels)! Problem 1 – An amateur astronomer purchases a 6.1 megapixel digital camera. The sensor measures 20 mm x 20 mm. What is the format of the CCD sensor, and about how wide are each of the pixels in microns? Problem 2 – Suppose that with the telescope optical system, the entire full moon will fit inside the square CCD sensor. -

Lensfree On-Chip Microscopy Over a Wide Field- Of-View Using Pixel Super-Resolution
Lensfree on-chip microscopy over a wide field- of-view using pixel super-resolution Waheb Bishara1,*, Ting-Wei Su1, Ahmet F. Coskun1, and Aydogan Ozcan1,2,3 1 Electrical Engineering Department, University of California, Los Angeles, CA 90095, USA 2 California NanoSystems Institute, University of California, Los Angeles, CA 90095, USA 3 [email protected] * [email protected] http://innovate.ee.ucla.edu Abstract: We demonstrate lensfree holographic microscopy on a chip to achieve ~0.6 µm spatial resolution corresponding to a numerical aperture of ~0.5 over a large field-of-view of ~24 mm2. By using partially coherent illumination from a large aperture (~50 µm), we acquire lower resolution lensfree in-line holograms of the objects with unit fringe magnification. For each lensfree hologram, the pixel size at the sensor chip limits the spatial resolution of the reconstructed image. To circumvent this limitation, we implement a sub-pixel shifting based super-resolution algorithm to effectively recover much higher resolution digital holograms of the objects, permitting sub-micron spatial resolution to be achieved across the entire sensor chip active area, which is also equivalent to the imaging field-of- view (24 mm2) due to unit magnification. We demonstrate the success of this pixel super-resolution approach by imaging patterned transparent substrates, blood smear samples, as well as Caenoharbditis Elegans. © 2010 Optical Society of America OCIS codes. (090.1995) Digital holography References and Links 1. W. Haddad, D. Cullen, H. Solem, J. Longworth, A. McPherson, K. Boyer, and C. Rhodes, “Fourier-transform holographic microscopy,” Appl. Opt. 31(24), 4973–4978 (1992). -

Digital Image Basics
Chapter 1 Digital Image Basics 1.1 What is a Digital Image? To understand what a digital image is, we have to first realize that what we see when we look at a \digital image" is actually a physical image reconstructed from a digital image. The digital image itself is really a data structure within the computer, containing a number or code for each pixel or picture element in the image. This code determines the color of that pixel. Each pixel can be thought of as a discrete sample of a continuous real image. It is helpful to think about the common ways that a digital image is created. Some of the main ways are via a digital camera, a page or slide scanner, a 3D rendering program, or a paint or drawing package. The simplest process to understand is the one used by the digital camera. Figure 1.1 diagrams how a digital image is made with a digital camera. The camera is aimed at a scene in the world, and light from the scene is focused onto the camera's picture plane by the lens (Figure 1.1a). The camera's picture plane contains photosensors arranged in a grid-like array, with one sensor for each pixel in the resulting image (Figure 1.1b). Each sensor emits a voltage proportional to the intensity of the light falling on it, and an analog to digital conversion circuit converts the voltage to a binary code or number suitable for storage in a cell of computer memory. This code is called the pixel's value. -

2006 SPIE Invited Paper: a Brief History of 'Pixel'
REPRINT — author contact: <[email protected]> A Brief History of ‘Pixel’ Richard F. Lyon Foveon Inc., 2820 San Tomas Expressway, Santa Clara CA 95051 ABSTRACT The term pixel, for picture element, was first published in two different SPIE Proceedings in 1965, in articles by Fred C. Billingsley of Caltech’s Jet Propulsion Laboratory. The alternative pel was published by William F. Schreiber of MIT in the Proceedings of the IEEE in 1967. Both pixel and pel were propagated within the image processing and video coding field for more than a decade before they appeared in textbooks in the late 1970s. Subsequently, pixel has become ubiquitous in the fields of computer graphics, displays, printers, scanners, cameras, and related technologies, with a variety of sometimes conflicting meanings. Reprint — Paper EI 6069-1 Digital Photography II — Invited Paper IS&T/SPIE Symposium on Electronic Imaging 15–19 January 2006, San Jose, California, USA Copyright 2006 SPIE and IS&T. This paper has been published in Digital Photography II, IS&T/SPIE Symposium on Electronic Imaging, 15–19 January 2006, San Jose, California, USA, and is made available as an electronic reprint with permission of SPIE and IS&T. One print or electronic copy may be made for personal use only. Systematic or multiple reproduction, distribution to multiple locations via electronic or other means, duplication of any material in this paper for a fee or for commercial purposes, or modification of the content of the paper are prohibited. A Brief History of ‘Pixel’ Richard F. Lyon Foveon Inc., 2820 San Tomas Expressway, Santa Clara CA 95051 ABSTRACT The term pixel, for picture element, was first published in two different SPIE Proceedings in 1965, in articles by Fred C. -

Depth Map Quality Evaluation for Photographic Applications
https://doi.org/10.2352/ISSN.2470-1173.2020.9.IQSP-370 © 2020, Society for Imaging Science and Technology Depth Map Quality Evaluation for Photographic Applications Eloi Zalczer, François-Xavier Thomas, Laurent Chanas, Gabriele Facciolo and Frédéric Guichard DXOMARK; 24-26 Quai Alphonse Le Gallo, 92100 Boulogne-Billancourt, France Abstract As depth imaging is integrated into more and more consumer devices, manufacturers have to tackle new challenges. Applica- tions such as computational bokeh and augmented reality require dense and precisely segmented depth maps to achieve good re- sults. Modern devices use a multitude of different technologies to estimate depth maps, such as time-of-flight sensors, stereoscopic cameras, structured light sensors, phase-detect pixels or a com- bination thereof. Therefore, there is a need to evaluate the quality of the depth maps, regardless of the technology used to produce them. The aim of our work is to propose an end-result evalua- tion method based on a single scene, using a specifically designed chart. We consider the depth maps embedded in the photographs, which are not visible to the user but are used by specialized soft- ware, in association with the RGB pictures. Some of the aspects considered are spatial alignment between RGB and depth, depth consistency, and robustness to texture variations. This work also provides a comparison of perceptual and automatic evaluations. Introduction Computational Bokeh, and various other depth-based pho- tographic features, have become major selling points for flagship smartphones in the last few years. These applications have dif- ferent quality requirements than most depth imaging technolo- gies.