One Is Enough. a Photograph Taken by the “Single-Pixel Camera” Built by Richard Baraniuk and Kevin Kelly of Rice University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Digital Holography Using a Laser Pointer and Consumer Digital Camera Report Date: June 22Nd, 2004
Digital Holography using a Laser Pointer and Consumer Digital Camera Report date: June 22nd, 2004 by David Garber, M.E. undergraduate, Johns Hopkins University, [email protected] Available online at http://pegasus.me.jhu.edu/~lefd/shc/LPholo/lphindex.htm Acknowledgements Faculty sponsor: Prof. Joseph Katz, [email protected] Project idea and direction: Dr. Edwin Malkiel, [email protected] Digital holography reconstruction: Jian Sheng, [email protected] Abstract The point of this project was to examine the feasibility of low-cost holography. Can viable holograms be recorded using an ordinary diode laser pointer and a consumer digital camera? How much does it cost? What are the major difficulties? I set up an in-line holographic system and recorded both still images and movies using a $600 Fujifilm Finepix S602Z digital camera and a $10 laser pointer by Lazerpro. Reconstruction of the stills shows clearly that successful holograms can be created with a low-cost optical setup. The movies did not reconstruct, due to compression and very low image resolution. Garber 2 Theoretical Background What is a hologram? The Merriam-Webster dictionary defines a hologram as, “a three-dimensional image reproduced from a pattern of interference produced by a split coherent beam of radiation (as a laser).” Holograms can produce a three-dimensional image, but it is more helpful for our purposes to think of a hologram as a photograph that can be refocused at any depth. So while a photograph taken of two people standing far apart would have one in focus and one blurry, a hologram taken of the same scene could be reconstructed to bring either person into focus. -
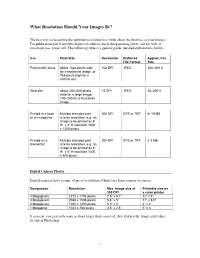
What Resolution Should Your Images Be?
What Resolution Should Your Images Be? The best way to determine the optimum resolution is to think about the final use of your images. For publication you’ll need the highest resolution, for desktop printing lower, and for web or classroom use, lower still. The following table is a general guide; detailed explanations follow. Use Pixel Size Resolution Preferred Approx. File File Format Size Projected in class About 1024 pixels wide 102 DPI JPEG 300–600 K for a horizontal image; or 768 pixels high for a vertical one Web site About 400–600 pixels 72 DPI JPEG 20–200 K wide for a large image; 100–200 for a thumbnail image Printed in a book Multiply intended print 300 DPI EPS or TIFF 6–10 MB or art magazine size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1800 x 1200 pixels. Printed on a Multiply intended print 200 DPI EPS or TIFF 2-3 MB laserwriter size by resolution; e.g. an image to be printed as 6” W x 4” H would be 1200 x 800 pixels. Digital Camera Photos Digital cameras have a range of preset resolutions which vary from camera to camera. Designation Resolution Max. Image size at Printable size on 300 DPI a color printer 4 Megapixels 2272 x 1704 pixels 7.5” x 5.7” 12” x 9” 3 Megapixels 2048 x 1536 pixels 6.8” x 5” 11” x 8.5” 2 Megapixels 1600 x 1200 pixels 5.3” x 4” 6” x 4” 1 Megapixel 1024 x 768 pixels 3.5” x 2.5” 5” x 3 If you can, you generally want to shoot larger than you need, then sharpen the image and reduce its size in Photoshop. -

Sample Manuscript Showing Specifications and Style
Information capacity: a measure of potential image quality of a digital camera Frédéric Cao 1, Frédéric Guichard, Hervé Hornung DxO Labs, 3 rue Nationale, 92100 Boulogne Billancourt, FRANCE ABSTRACT The aim of the paper is to define an objective measurement for evaluating the performance of a digital camera. The challenge is to mix different flaws involving geometry (as distortion or lateral chromatic aberrations), light (as luminance and color shading), or statistical phenomena (as noise). We introduce the concept of information capacity that accounts for all the main defects than can be observed in digital images, and that can be due either to the optics or to the sensor. The information capacity describes the potential of the camera to produce good images. In particular, digital processing can correct some flaws (like distortion). Our definition of information takes possible correction into account and the fact that processing can neither retrieve lost information nor create some. This paper extends some of our previous work where the information capacity was only defined for RAW sensors. The concept is extended for cameras with optical defects as distortion, lateral and longitudinal chromatic aberration or lens shading. Keywords: digital photography, image quality evaluation, optical aberration, information capacity, camera performance database 1. INTRODUCTION The evaluation of a digital camera is a key factor for customers, whether they are vendors or final customers. It relies on many different factors as the presence or not of some functionalities, ergonomic, price, or image quality. Each separate criterion is itself quite complex to evaluate, and depends on many different factors. The case of image quality is a good illustration of this topic. -

Seeing Like Your Camera ○ My List of Specific Videos I Recommend for Homework I.E
Accessing Lynda.com ● Free to Mason community ● Set your browser to lynda.gmu.edu ○ Log-in using your Mason ID and Password ● Playlists Seeing Like Your Camera ○ My list of specific videos I recommend for homework i.e. pre- and post-session viewing.. PART 2 - FALL 2016 ○ Clicking on the name of the video segment will bring you immediately to Lynda.com (or the login window) Stan Schretter ○ I recommend that you eventually watch the entire video class, since we will only use small segments of each video class [email protected] 1 2 Ways To Take This Course What Creates a Photograph ● Each class will cover on one or two topics in detail ● Light ○ Lynda.com videos cover a lot more material ○ I will email the video playlist and the my charts before each class ● Camera ● My Scale of Value ○ Maximum Benefit: Review Videos Before Class & Attend Lectures ● Composition & Practice after Each Class ○ Less Benefit: Do not look at the Videos; Attend Lectures and ● Camera Setup Practice after Each Class ○ Some Benefit: Look at Videos; Don’t attend Lectures ● Post Processing 3 4 This Course - “The Shot” This Course - “The Shot” ● Camera Setup ○ Exposure ● Light ■ “Proper” Light on the Sensor ■ Depth of Field ■ Stop or Show the Action ● Camera ○ Focus ○ Getting the Color Right ● Composition ■ White Balance ● Composition ● Camera Setup ○ Key Photographic Element(s) ○ Moving The Eye Through The Frame ■ Negative Space ● Post Processing ○ Perspective ○ Story 5 6 Outline of This Class Class Topics PART 1 - Summer 2016 PART 2 - Fall 2016 ● Topic 1 ○ Review of Part 1 ● Increasing Your Vision ● Brief Review of Part 1 ○ Shutter Speed, Aperture, ISO ○ Shutter Speed ● Seeing The Light ○ Composition ○ Aperture ○ Color, dynamic range, ● Topic 2 ○ ISO and White Balance histograms, backlighting, etc. -

Foveon FO18-50-F19 4.5 MP X3 Direct Image Sensor
® Foveon FO18-50-F19 4.5 MP X3 Direct Image Sensor Features The Foveon FO18-50-F19 is a 1/1.8-inch CMOS direct image sensor that incorporates breakthrough Foveon X3 technology. Foveon X3 direct image sensors Foveon X3® Technology • A stack of three pixels captures superior color capture full-measured color images through a unique stacked pixel sensor design. fidelity by measuring full color at every point By capturing full-measured color images, the need for color interpolation and in the captured image. artifact-reducing blur filters is eliminated. The Foveon FO18-50-F19 features the • Images have improved sharpness and immunity to color artifacts (moiré). powerful VPS (Variable Pixel Size) capability. VPS provides the on-chip capabil- • Foveon X3 technology directly converts light ity of grouping neighboring pixels together to form larger pixels that are optimal of all colors into useful signal information at every point in the captured image—no light for high frame rate, reduced noise, or dual mode still/video applications. Other absorbing filters are used to block out light. advanced features include: low fixed pattern noise, ultra-low power consumption, Variable Pixel Size (VPS) Capability and integrated digital control. • Neighboring pixels can be grouped together on-chip to obtain the effect of a larger pixel. • Enables flexible video capture at a variety of resolutions. • Enables higher ISO mode at lower resolutions. Analog Biases Row Row Digital Supplies • Reduces noise by combining pixels. Pixel Array Analog Supplies Readout Reset 1440 columns x 1088 rows x 3 layers On-Chip A/D Conversion Control Control • Integrated 12-bit A/D converter running at up to 40 MHz. -

Single-Pixel Imaging Via Compressive Sampling
© DIGITAL VISION Single-Pixel Imaging via Compressive Sampling [Building simpler, smaller, and less-expensive digital cameras] Marco F. Duarte, umans are visual animals, and imaging sensors that extend our reach— [ cameras—have improved dramatically in recent times thanks to the intro- Mark A. Davenport, duction of CCD and CMOS digital technology. Consumer digital cameras in Dharmpal Takhar, the megapixel range are now ubiquitous thanks to the happy coincidence that the semiconductor material of choice for large-scale electronics inte- Jason N. Laska, Ting Sun, Hgration (silicon) also happens to readily convert photons at visual wavelengths into elec- Kevin F. Kelly, and trons. On the contrary, imaging at wavelengths where silicon is blind is considerably Richard G. Baraniuk more complicated, bulky, and expensive. Thus, for comparable resolution, a US$500 digi- ] tal camera for the visible becomes a US$50,000 camera for the infrared. In this article, we present a new approach to building simpler, smaller, and cheaper digital cameras that can operate efficiently across a much broader spectral range than conventional silicon-based cameras. Our approach fuses a new camera architecture Digital Object Identifier 10.1109/MSP.2007.914730 1053-5888/08/$25.00©2008IEEE IEEE SIGNAL PROCESSING MAGAZINE [83] MARCH 2008 based on a digital micromirror device (DMD—see “Spatial Light Our “single-pixel” CS camera architecture is basically an Modulators”) with the new mathematical theory and algorithms optical computer (comprising a DMD, two lenses, a single pho- of compressive sampling (CS—see “CS in a Nutshell”). ton detector, and an analog-to-digital (A/D) converter) that com- CS combines sampling and compression into a single non- putes random linear measurements of the scene under view. -

Passport Photograph Instructions by the Police
Passport photograph instructions 1 (7) Passport photograph instructions by the police These instructions describe the technical and quality requirements on passport photographs. The same instructions apply to all facial photographs used on the passports, identity cards and permits granted by the police. The instructions are based on EU legislation and international treaties. The photographer usually sends the passport photograph directly to the police electronically, and it is linked to the application with a photograph retrieval code assigned to the photograph. You can also use a paper photograph, if you submit your application at a police service point. Contents • Photograph format • Technical requirements on the photograph • Dimensions and positioning • Posture • Lighting • Expressions, glasses, head-wear and make-up • Background Photograph format • The photograph can be a black-and-white or a colour photograph. • The dimensions of photographs submitted electronically must be exactly 500 x 653 pixels. Deviations as small as one pixel are not accepted. • Electronically submitted photographs must be saved in the JPEG format (not JPEG2000). The file extension can be either .jpg or .jpeg. • The maximum size of an electronically submitted photograph is 250 kilobytes. 1. Correct 2. Correct 2 (7) Technical requirements on the photograph • The photograph must be no more than six months old. • The photograph must not be manipulated in any way that would change even the small- est details in the subject’s appearance or in a way that could raise suspicions about the photograph's authenticity. Use of digital make-up is not allowed. • The photograph must be sharp and in focus over the entire face. -

Photographic Films
PHOTOGRAPHIC FILMS A camera has been called a “magic box.” Why? Because the box captures an image that can be made permanent. Photographic films capture the image formed by light reflecting from the surface being photographed. This instruction sheet describes the nature of photographic films, especially those used in the graphic communications industries. THE STRUCTURE OF FILM Protective Coating Emulsion Base Anti-Halation Backing Photographic films are composed of several layers. These layers include the base, the emulsion, the anti-halation backing and the protective coating. THE BASE The base, the thickest of the layers, supports the other layers. Originally, the base was made of glass. However, today the base can be made from any number of materials ranging from paper to aluminum. Photographers primarily use films with either a plastic (polyester) or paper base. Plastic-based films are commonly called “films” while paper-based films are called “photographic papers.” Polyester is a particularly suitable base for film because it is dimensionally stable. Dimensionally stable materials do not appreciably change size when the temperature or moisture- level of the film change. Films are subjected to heated liquids during processing (developing) and to heat during use in graphic processes. Therefore, dimensional stability is very important for graphic communications photographers because their final images must always match the given size. Conversely, paper is not dimen- sionally stable and is only appropriate as a film base when the “photographic print” is the final product (as contrasted to an intermediate step in a multi-step process). THE EMULSION The emulsion is the true “heart” of film. -

19Th Century Photograph Preservation: a Study of Daguerreotype And
UNIVERSITY OF OKLAHOMA PRESERVATION OF INFORMATION MATERIALS LIS 5653 900 19th Century Photograph Preservation A Study of Daguerreotype and Collodion Processes Jill K. Flowers 3/28/2009 19th Century Photograph Preservation A Study of Daguerreotype and Collodion Processes Jill K. Flowers Photography is the process of using light to record images. The human race has recorded the images of experience from the time when painting pictographs on cave walls was the only available medium. Humanity seems driven to transcribe life experiences not only into language but also into images. The birth of photography occurred in the 19th Century. There were at least seven different processes developed during the century. This paper will focus on two of the most prevalent formats. The daguerreotype and the wet plate collodion process were both highly popular and today they have a significant presence in archives, libraries, and museums. Examination of the process of image creation is reviewed as well as the preservation and restoration processes in use today. The daguerreotype was the first successful and practical form of commercial photography. Jacques Mande‟ Daguerre invented the process in a collaborative effort with Nicephore Niepce. Daguerre introduced the imaging process on August 19, 1839 in Paris and it was in popular use from 1839 to approximately 1860. The daguerreotype marks the beginning of the era of photography. Daguerreotypes are unique in the family of photographic process, in that the image is produced on metal directly without an intervening negative. Image support is provided by a copper plate, coated with silver, and then cleaned and highly polished. -

Making the Transition from Film to Digital
TECHNICAL PAPER Making the Transition from Film to Digital TABLE OF CONTENTS Photography became a reality in the 1840s. During this time, images were recorded on 2 Making the transition film that used particles of silver salts embedded in a physical substrate, such as acetate 2 The difference between grain or gelatin. The grains of silver turned dark when exposed to light, and then a chemical and pixels fixer made that change more or less permanent. Cameras remained pretty much the 3 Exposure considerations same over the years with features such as a lens, a light-tight chamber to hold the film, 3 This won’t hurt a bit and an aperture and shutter mechanism to control exposure. 3 High-bit images But the early 1990s brought a dramatic change with the advent of digital technology. 4 Why would you want to use a Instead of using grains of silver embedded in gelatin, digital photography uses silicon to high-bit image? record images as numbers. Computers process the images, rather than optical enlargers 5 About raw files and tanks of often toxic chemicals. Chemically-developed wet printing processes have 5 Saving a raw file given way to prints made with inkjet printers, which squirt microscopic droplets of ink onto paper to create photographs. 5 Saving a JPEG file 6 Pros and cons 6 Reasons to shoot JPEG 6 Reasons to shoot raw 8 Raw converters 9 Reading histograms 10 About color balance 11 Noise reduction 11 Sharpening 11 It’s in the cards 12 A matter of black and white 12 Conclusion Snafellnesjokull Glacier Remnant. -

Evolution of Photography: Film to Digital
University of North Georgia Nighthawks Open Institutional Repository Honors Theses Honors Program Fall 10-2-2018 Evolution of Photography: Film to Digital Charlotte McDonnold University of North Georgia, [email protected] Follow this and additional works at: https://digitalcommons.northgeorgia.edu/honors_theses Part of the Art and Design Commons, and the Fine Arts Commons Recommended Citation McDonnold, Charlotte, "Evolution of Photography: Film to Digital" (2018). Honors Theses. 63. https://digitalcommons.northgeorgia.edu/honors_theses/63 This Thesis is brought to you for free and open access by the Honors Program at Nighthawks Open Institutional Repository. It has been accepted for inclusion in Honors Theses by an authorized administrator of Nighthawks Open Institutional Repository. Evolution of Photography: Film to Digital A Thesis Submitted to the Faculty of the University of North Georgia In Partial Fulfillment Of the Requirements for the Degree Bachelor of Art in Studio Art, Photography and Graphic Design With Honors Charlotte McDonnold Fall 2018 EVOLUTION OF PHOTOGRAPHY 2 Acknowledgements I would like thank my thesis panel, Dr. Stephen Smith, Paul Dunlap, Christopher Dant, and Dr. Nancy Dalman. Without their support and guidance, this project would not have been possible. I would also like to thank my Honors Research Class from spring 2017. They provided great advice and were willing to listen to me talk about photography for an entire semester. A special thanks to my family and friends for reading over drafts, offering support, and advice throughout this project. EVOLUTION OF PHOTOGRAPHY 3 Abstract Due to the ever changing advancements in technology, photography is a constantly growing field. What was once an art form solely used by professionals is now accessible to every consumer in the world. -

Intro to Digital Photography.Pdf
ABSTRACT Learn and master the basic features of your camera to gain better control of your photos. Individualized chapters on each of the cameras basic functions as well as cheat sheets you can download and print for use while shooting. Neuberger, Lawrence INTRO TO DGMA 3303 Digital Photography DIGITAL PHOTOGRAPHY Mastering the Basics Table of Contents Camera Controls ............................................................................................................................. 7 Camera Controls ......................................................................................................................... 7 Image Sensor .............................................................................................................................. 8 Camera Lens .............................................................................................................................. 8 Camera Modes ............................................................................................................................ 9 Built-in Flash ............................................................................................................................. 11 Viewing System ........................................................................................................................ 11 Image File Formats ....................................................................................................................... 13 File Compression ......................................................................................................................