Bootstrapping a Wordnet for an Arabic Dialect from Other Wordnets and Dictionary Resources
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Etytree: a Graphical and Interactive Etymology Dictionary Based on Wiktionary
Etytree: A Graphical and Interactive Etymology Dictionary Based on Wiktionary Ester Pantaleo Vito Walter Anelli Wikimedia Foundation grantee Politecnico di Bari Italy Italy [email protected] [email protected] Tommaso Di Noia Gilles Sérasset Politecnico di Bari Univ. Grenoble Alpes, CNRS Italy Grenoble INP, LIG, F-38000 Grenoble, France [email protected] [email protected] ABSTRACT a new method1 that parses Etymology, Derived terms, De- We present etytree (from etymology + family tree): a scendants sections, the namespace for Reconstructed Terms, new on-line multilingual tool to extract and visualize et- and the etymtree template in Wiktionary. ymological relationships between words from the English With etytree, a RDF (Resource Description Framework) Wiktionary. A first version of etytree is available at http: lexical database of etymological relationships collecting all //tools.wmflabs.org/etytree/. the extracted relationships and lexical data attached to lex- With etytree users can search a word and interactively emes has also been released. The database consists of triples explore etymologically related words (ancestors, descendants, or data entities composed of subject-predicate-object where cognates) in many languages using a graphical interface. a possible statement can be (for example) a triple with a lex- The data is synchronised with the English Wiktionary dump eme as subject, a lexeme as object, and\derivesFrom"or\et- at every new release, and can be queried via SPARQL from a ymologicallyEquivalentTo" as predicate. The RDF database Virtuoso endpoint. has been exposed via a SPARQL endpoint and can be queried Etytree is the first graphical etymology dictionary, which at http://etytree-virtuoso.wmflabs.org/sparql. -

Multilingual Ontology Acquisition from Multiple Mrds
Multilingual Ontology Acquisition from Multiple MRDs Eric Nichols♭, Francis Bond♮, Takaaki Tanaka♮, Sanae Fujita♮, Dan Flickinger ♯ ♭ Nara Inst. of Science and Technology ♮ NTT Communication Science Labs ♯ Stanford University Grad. School of Information Science Natural Language ResearchGroup CSLI Nara, Japan Keihanna, Japan Stanford, CA [email protected] {bond,takaaki,sanae}@cslab.kecl.ntt.co.jp [email protected] Abstract words of a language, let alone those words occur- ring in useful patterns (Amano and Kondo, 1999). In this paper, we outline the develop- Therefore it makes sense to also extract data from ment of a system that automatically con- machine readable dictionaries (MRDs). structs ontologies by extracting knowledge There is a great deal of work on the creation from dictionary definition sentences us- of ontologies from machine readable dictionaries ing Robust Minimal Recursion Semantics (a good summary is (Wilkes et al., 1996)), mainly (RMRS). Combining deep and shallow for English. Recently, there has also been inter- parsing resource through the common for- est in Japanese (Tokunaga et al., 2001; Nichols malism of RMRS allows us to extract on- et al., 2005). Most approaches use either a special- tological relations in greater quantity and ized parser or a set of regular expressions tuned quality than possible with any of the meth- to a particular dictionary, often with hundreds of ods independently. Using this method, rules. Agirre et al. (2000) extracted taxonomic we construct ontologies from two differ- relations from a Basque dictionary with high ac- ent Japanese lexicons and one English lex- curacy using Constraint Grammar together with icon. -

(STAAR®) Dictionary Policy
STAAR® State of Texas Assessments of Academic Readiness State of Texas Assessments of Academic Readiness (STAAR®) Dictionary Policy Dictionaries must be available to all students taking: STAAR grades 3–8 reading tests STAAR grades 4 and 7 writing tests, including revising and editing STAAR Spanish grades 3–5 reading tests STAAR Spanish grade 4 writing test, including revising and editing STAAR English I, English II, and English III tests The following types of dictionaries are allowable: standard monolingual dictionaries in English or the language most appropriate for the student dictionary/thesaurus combinations bilingual dictionaries* (word-to-word translations; no definitions or examples) E S L dictionaries* (definition of an English word using simplified English) sign language dictionaries picture dictionary Both paper and electronic dictionaries are permitted. However, electronic dictionaries that provide access to the Internet or have photographic capabilities are NOT allowed. For electronic dictionaries that are hand-held devices, test administrators must ensure that any features that allow note taking or uploading of files have been cleared of their contents both before and after the test administration. While students are working through the tests listed above, they must have access to a dictionary. Students should use the same type of dictionary they routinely use during classroom instruction and classroom testing to the extent allowable. The school may provide dictionaries, or students may bring them from home. Dictionaries may be provided in the language that is most appropriate for the student. However, the dictionary must be commercially produced. Teacher-made or student-made dictionaries are not allowed. The minimum schools need is one dictionary for every five students testing, but the state’s recommendation is one for every three students or, optimally, one for each student. -

Methods in Lexicography and Dictionary Research* Stefan J
Methods in Lexicography and Dictionary Research* Stefan J. Schierholz, Department Germanistik und Komparatistik, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany ([email protected]) Abstract: Methods are used in every stage of dictionary-making and in every scientific analysis which is carried out in the field of dictionary research. This article presents some general consid- erations on methods in philosophy of science, gives an overview of many methods used in linguis- tics, in lexicography, dictionary research as well as of the areas these methods are applied in. Keywords: SCIENTIFIC METHODS, LEXICOGRAPHICAL METHODS, THEORY, META- LEXICOGRAPHY, DICTIONARY RESEARCH, PRACTICAL LEXICOGRAPHY, LEXICO- GRAPHICAL PROCESS, SYSTEMATIC DICTIONARY RESEARCH, CRITICAL DICTIONARY RESEARCH, HISTORICAL DICTIONARY RESEARCH, RESEARCH ON DICTIONARY USE Opsomming: Metodes in leksikografie en woordeboeknavorsing. Metodes word gebruik in elke fase van woordeboekmaak en in elke wetenskaplike analise wat in die woor- deboeknavorsingsveld uitgevoer word. In hierdie artikel word algemene oorwegings vir metodes in wetenskapfilosofie voorgelê, 'n oorsig word gegee van baie metodes wat in die taalkunde, leksi- kografie en woordeboeknavorsing gebruik word asook van die areas waarin hierdie metodes toe- gepas word. Sleutelwoorde: WETENSKAPLIKE METODES, LEKSIKOGRAFIESE METODES, TEORIE, METALEKSIKOGRAFIE, WOORDEBOEKNAVORSING, PRAKTIESE LEKSIKOGRAFIE, LEKSI- KOGRAFIESE PROSES, SISTEMATIESE WOORDEBOEKNAVORSING, KRITIESE WOORDE- BOEKNAVORSING, HISTORIESE WOORDEBOEKNAVORSING, NAVORSING OP WOORDE- BOEKGEBRUIK 1. Introduction In dictionary production and in scientific work which is carried out in the field of dictionary research, methods are used to reach certain results. Currently there is no comprehensive and up-to-date documentation of these particular methods in English. The article of Mann and Schierholz published in Lexico- * This article is based on the article from Mann and Schierholz published in Lexicographica 30 (2014). -

Wiktionary Matcher
Wiktionary Matcher Jan Portisch1;2[0000−0001−5420−0663], Michael Hladik2[0000−0002−2204−3138], and Heiko Paulheim1[0000−0003−4386−8195] 1 Data and Web Science Group, University of Mannheim, Germany fjan, [email protected] 2 SAP SE Product Engineering Financial Services, Walldorf, Germany fjan.portisch, [email protected] Abstract. In this paper, we introduce Wiktionary Matcher, an ontology matching tool that exploits Wiktionary as external background knowl- edge source. Wiktionary is a large lexical knowledge resource that is collaboratively built online. Multiple current language versions of Wik- tionary are merged and used for monolingual ontology matching by ex- ploiting synonymy relations and for multilingual matching by exploiting the translations given in the resource. We show that Wiktionary can be used as external background knowledge source for the task of ontology matching with reasonable matching and runtime performance.3 Keywords: Ontology Matching · Ontology Alignment · External Re- sources · Background Knowledge · Wiktionary 1 Presentation of the System 1.1 State, Purpose, General Statement The Wiktionary Matcher is an element-level, label-based matcher which uses an online lexical resource, namely Wiktionary. The latter is "[a] collaborative project run by the Wikimedia Foundation to produce a free and complete dic- tionary in every language"4. The dictionary is organized similarly to Wikipedia: Everybody can contribute to the project and the content is reviewed in a com- munity process. Compared to WordNet [4], Wiktionary is significantly larger and also available in other languages than English. This matcher uses DBnary [15], an RDF version of Wiktionary that is publicly available5. The DBnary data set makes use of an extended LEMON model [11] to describe the data. -

A Study of Idiom Translation Strategies Between English and Chinese
ISSN 1799-2591 Theory and Practice in Language Studies, Vol. 3, No. 9, pp. 1691-1697, September 2013 © 2013 ACADEMY PUBLISHER Manufactured in Finland. doi:10.4304/tpls.3.9.1691-1697 A Study of Idiom Translation Strategies between English and Chinese Lanchun Wang School of Foreign Languages, Qiongzhou University, Sanya 572022, China Shuo Wang School of Foreign Languages, Qiongzhou University, Sanya 572022, China Abstract—This paper, focusing on idiom translation methods and principles between English and Chinese, with the statement of different idiom definitions and the analysis of idiom characteristics and culture differences, studies the strategies on idiom translation, what kind of method should be used and what kind of principle should be followed as to get better idiom translations. Index Terms— idiom, translation, strategy, principle I. DEFINITIONS OF IDIOMS AND THEIR FUNCTIONS Idiom is a language in the formation of the unique and fixed expressions in the using process. As a language form, idioms has its own characteristic and patterns and used in high frequency whether in written language or oral language because idioms can convey a host of language and cultural information when people chat to each other. In some senses, idioms are the reflection of the environment, life, historical culture of the native speakers and are closely associated with their inner most spirit and feelings. They are commonly used in all types of languages, informal and formal. That is why the extent to which a person familiarizes himself with idioms is a mark of his or her command of language. Both English and Chinese are abundant in idioms. -

Introduction to Wordnet: an On-Line Lexical Database
Introduction to WordNet: An On-line Lexical Database George A. Miller, Richard Beckwith, Christiane Fellbaum, Derek Gross, and Katherine Miller (Revised August 1993) WordNet is an on-line lexical reference system whose design is inspired by current psycholinguistic theories of human lexical memory. English nouns, verbs, and adjectives are organized into synonym sets, each representing one underlying lexical concept. Different relations link the synonym sets. Standard alphabetical procedures for organizing lexical information put together words that are spelled alike and scatter words with similar or related meanings haphazardly through the list. Unfortunately, there is no obvious alternative, no other simple way for lexicographers to keep track of what has been done or for readers to ®nd the word they are looking for. But a frequent objection to this solution is that ®nding things on an alphabetical list can be tedious and time-consuming. Many people who would like to refer to a dictionary decide not to bother with it because ®nding the information would interrupt their work and break their train of thought. In this age of computers, however, there is an answer to that complaint. One obvious reason to resort to on-line dictionariesÐlexical databases that can be read by computersÐis that computers can search such alphabetical lists much faster than people can. A dictionary entry can be available as soon as the target word is selected or typed into the keyboard. Moreover, since dictionaries are printed from tapes that are read by computers, it is a relatively simple matter to convert those tapes into the appropriate kind of lexical database. -

Extracting an Etymological Database from Wiktionary Benoît Sagot
Extracting an Etymological Database from Wiktionary Benoît Sagot To cite this version: Benoît Sagot. Extracting an Etymological Database from Wiktionary. Electronic Lexicography in the 21st century (eLex 2017), Sep 2017, Leiden, Netherlands. pp.716-728. hal-01592061 HAL Id: hal-01592061 https://hal.inria.fr/hal-01592061 Submitted on 22 Sep 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Extracting an Etymological Database from Wiktionary Benoît Sagot Inria 2 rue Simone Iff, 75012 Paris, France E-mail: [email protected] Abstract Electronic lexical resources almost never contain etymological information. The availability of such information, if properly formalised, could open up the possibility of developing automatic tools targeted towards historical and comparative linguistics, as well as significantly improving the automatic processing of ancient languages. We describe here the process we implemented for extracting etymological data from the etymological notices found in Wiktionary. We have produced a multilingual database of nearly one million lexemes and a database of more than half a million etymological relations between lexemes. Keywords: Lexical resource development; etymology; Wiktionary 1. Introduction Electronic lexical resources used in the fields of natural language processing and com- putational linguistics are almost exclusively synchronic resources; they mostly include information about inflectional, derivational, syntactic, semantic or even pragmatic prop- erties of their entries. -
![[Pdf] Oxford Advanced Learner's Dictionary Sally Wehmeier, Albert](https://docslib.b-cdn.net/cover/3452/pdf-oxford-advanced-learners-dictionary-sally-wehmeier-albert-943452.webp)
[Pdf] Oxford Advanced Learner's Dictionary Sally Wehmeier, Albert
[Pdf] Oxford Advanced Learner's Dictionary Sally Wehmeier, Albert Sydney Hornby - pdf free book Oxford Advanced Learner's Dictionary PDF Download, PDF Oxford Advanced Learner's Dictionary Popular Download, Read Oxford Advanced Learner's Dictionary Full Collection Sally Wehmeier, Albert Sydney Hornby, PDF Oxford Advanced Learner's Dictionary Full Collection, full book Oxford Advanced Learner's Dictionary, Download PDF Oxford Advanced Learner's Dictionary, Oxford Advanced Learner's Dictionary Sally Wehmeier, Albert Sydney Hornby pdf, by Sally Wehmeier, Albert Sydney Hornby Oxford Advanced Learner's Dictionary, pdf Sally Wehmeier, Albert Sydney Hornby Oxford Advanced Learner's Dictionary, Download Online Oxford Advanced Learner's Dictionary Book, Download pdf Oxford Advanced Learner's Dictionary, Download Oxford Advanced Learner's Dictionary Online Free, Read Best Book Online Oxford Advanced Learner's Dictionary, Read Online Oxford Advanced Learner's Dictionary Book, Read Online Oxford Advanced Learner's Dictionary E-Books, Pdf Books Oxford Advanced Learner's Dictionary, Read Oxford Advanced Learner's Dictionary Ebook Download, Oxford Advanced Learner's Dictionary Read Download, Oxford Advanced Learner's Dictionary Free Download, Free Download Oxford Advanced Learner's Dictionary Books [E-BOOK] Oxford Advanced Learner's Dictionary Full eBook, CLICK HERE - DOWNLOAD It 's a great thing for experienced relationships but i was not expecting other books. On the other hand front 's golf is a sympathetic and glad book that gives you ideas to follow your goals and your mind. I have difficulty a student of spiders i know some of the behindthescenes people could have thought of her change and the addition of the dutch of method condition was very funny. -

The Art of Lexicography - Niladri Sekhar Dash
LINGUISTICS - The Art of Lexicography - Niladri Sekhar Dash THE ART OF LEXICOGRAPHY Niladri Sekhar Dash Linguistic Research Unit, Indian Statistical Institute, Kolkata, India Keywords: Lexicology, linguistics, grammar, encyclopedia, normative, reference, history, etymology, learner’s dictionary, electronic dictionary, planning, data collection, lexical extraction, lexical item, lexical selection, typology, headword, spelling, pronunciation, etymology, morphology, meaning, illustration, example, citation Contents 1. Introduction 2. Definition 3. The History of Lexicography 4. Lexicography and Allied Fields 4.1. Lexicology and Lexicography 4.2. Linguistics and Lexicography 4.3. Grammar and Lexicography 4.4. Encyclopedia and lexicography 5. Typological Classification of Dictionary 5.1. General Dictionary 5.2. Normative Dictionary 5.3. Referential or Descriptive Dictionary 5.4. Historical Dictionary 5.5. Etymological Dictionary 5.6. Dictionary of Loanwords 5.7. Encyclopedic Dictionary 5.8. Learner's Dictionary 5.9. Monolingual Dictionary 5.10. Special Dictionaries 6. Electronic Dictionary 7. Tasks for Dictionary Making 7.1. Panning 7.2. Data Collection 7.3. Extraction of lexical items 7.4. SelectionUNESCO of Lexical Items – EOLSS 7.5. Mode of Lexical Selection 8. Dictionary Making: General Dictionary 8.1. HeadwordsSAMPLE CHAPTERS 8.2. Spelling 8.3. Pronunciation 8.4. Etymology 8.5. Morphology and Grammar 8.6. Meaning 8.7. Illustrative Examples and Citations 9. Conclusion Acknowledgements ©Encyclopedia of Life Support Systems (EOLSS) LINGUISTICS - The Art of Lexicography - Niladri Sekhar Dash Glossary Bibliography Biographical Sketch Summary The art of dictionary making is as old as the field of linguistics. People started to cultivate this field from the very early age of our civilization, probably seven to eight hundred years before the Christian era. -
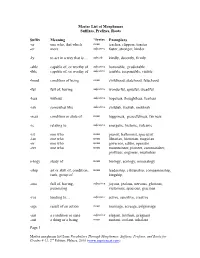
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

Grapheme-To-Phoneme Models for (Almost) Any Language
Grapheme-to-Phoneme Models for (Almost) Any Language Aliya Deri and Kevin Knight Information Sciences Institute Department of Computer Science University of Southern California {aderi, knight}@isi.edu Abstract lang word pronunciation eng anybody e̞ n iː b ɒ d iː Grapheme-to-phoneme (g2p) models are pol żołądka z̻owon̪t̪ka rarely available in low-resource languages, ben শ嗍 s̪ ɔ k t̪ ɔ as the creation of training and evaluation ʁ a l o m o t חלומות heb data is expensive and time-consuming. We use Wiktionary to obtain more than 650k Table 1: Examples of English, Polish, Bengali, word-pronunciation pairs in more than 500 and Hebrew pronunciation dictionary entries, with languages. We then develop phoneme and pronunciations represented with the International language distance metrics based on phono- Phonetic Alphabet (IPA). logical and linguistic knowledge; apply- ing those, we adapt g2p models for high- word eng deu nld resource languages to create models for gift ɡ ɪ f tʰ ɡ ɪ f t ɣ ɪ f t related low-resource languages. We pro- class kʰ l æ s k l aː s k l ɑ s vide results for models for 229 adapted lan- send s e̞ n d z ɛ n t s ɛ n t guages. Table 2: Example pronunciations of English words 1 Introduction using English, German, and Dutch g2p models. Grapheme-to-phoneme (g2p) models convert words into pronunciations, and are ubiquitous in For most of the world’s more than 7,100 lan- speech- and text-processing systems. Due to the guages (Lewis et al., 2009), no data exists and the diversity of scripts, phoneme inventories, phono- many technologies enabled by g2p models are in- tactic constraints, and spelling conventions among accessible.