Applications of Machine Learning: Basketball Strategy by Santhosh Narayan B.S. Computer Science, Massachusetts Institute of Tech
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2021 Basketball 1-48 Pages.Pub
HISTORY OF BOYS' ALL-STAR GAMES 1955 1959 SOUTH 86, NORTH 82 SOUTH 88, NORTH 74 The South Rebels led by Forest Hill's Freddy As in '57, the North came in outmanned--but Hutton upset the heavily favored North Yankees even more so--to absorb the worst licking yet. to begin an All-Star tradition. Hutton hit 13 Joe Watson of Pelahatchie and Robert Parsons field goals for 26 points, mostly from far out, of West Lincoln got 22 and 21 respectively for and had able scoring support up front as Ger- the victors. Moss Point's Jimmy McArthur made ald Martello of Cathedral got 16, Wayne Pulliam it easy for them by nabbing 24 rebounds. Co- of Sand Hill 15 and Jimmy Graves of Laurel 14. lumbus' James Parker, with 16, topped the los- Larry Eubanks of Tupelo led a losing cause with ers. 20 and Jerry Keeton of Wheeler had 16. 1960 1956 NORTH 95, SOUTH 82 SOUTH 96, NORTH 90 After five years of futility, the North finally broke This thriller went into double overtime before its losing jinx, piling up the largest victory mar- the South, after trailing early, pulled out front gin yet in the All-Star series. Complete command to stay. Wayne Newsome of Walnut tallied 27 of the backboards gave the Yanks a 73-50 re- points in vain for the North. Donald Clinton of bounding edge. Balanced North scoring, led by Oak Grove and Gerald Saxton of Forest had 17 Charles Jeter of Ingomar with 25 points and each to top the South, but it was the late scor- Butch Miller of Jackson Central with 22, offset ing burst of Puckett's Mike Ponder that saved an All-Star game record of 32 by the South's the Rebels. -
NBN Basketball Skill Development Playbook Pg
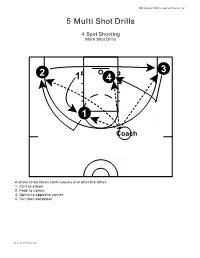
NBN Basketball Skill Development Playbook pg. 1 5 Multi Shot Drills 4 Spot Shooting Multi Shot Drills 3 2 1 4 1 Coach 4 shots to be taken continuously one after the other. 1. Curl to elbow 2. Fade to corner 3. Sprint to opposite corner 4. Cut then backdoor. All Contents Proprietary NBN Basketball Skill Development Playbook pg. 2 5 Multi Shot Drills Cross Screen, Transition, Fade, & Wing Jumper Multi Shot Drills 1 2 1 C 1. Simulate a cross screen then flash to elbow for jumper. 2. Backpedal to half court then sprint to top of key for 1 dribble pull up. All Contents Proprietary NBN Basketball Skill Development Playbook pg. 3 5 Multi Shot Drills Cross Screen, Transition, Fade, & Wing Jumper Multi Shot Drills 3 4 C 1 3. Fade to the corner for catch and shoot jumper 4. Sprint to wing for catch and shoot jumper. All Contents Proprietary NBN Basketball Skill Development Playbook pg. 4 5 Multi Shot Drills Pick N Roll, Pin Down, Transition 3, & 1 Dribble Pull Up Multi Shot Drills 1 2 4 1 3 1. Player 1 simulates a side pick n roll and finishes at the rim with a lay up or jumper. 2. Player 2 then goes to the corner and simulates a wide pin down for a jumper at the elbow. 3. Player 1 then sprints to half court and back to the top of the key for the transition 3 pointer. 4. The final shot for player 1 is a 1 dribble pull up. All Contents Proprietary NBN Basketball Skill Development Playbook pg. -

ACICS Draft Capacity Exhibit 9 (PDF)
OUR FACULTY SDUIS HIGH PROFILE FACULTY (b)(4) (b)(5) OUR CAMPUS The main campus for the University is located in historic Old Town San Diego, close to the Pacific Ocean and Interstate 5. The 22.000 SF facilities available at the University include several administrative offices, meeting rooms, testing room, sixteen classrooms, two student lounges, and two computer labs. A large conference room with the capacity to accommodate 80-100 people is located adjacent to the SDUIS main building. Old Town San Diego is considered the "birthplace" of California and is home to over 150 restaurants, shops and historical sites. Miles of oceanfront beach are within a few miles and Mission Bay, with more than 4,000 acres of bay, bike paths, grassy knolls and parks is approximately three miles north of Old Town. Within this range are the University of California, San Diego (UCSD) and San Diego State University (SDSU), where students of San Diego University for Integrative Studies can access library facilities as well as cultural and educational events. San Diego University for Integrative Studies is a non-residential campus serving a wide variety of students. It does not provide dormitory facilities or off-campus student housing. The school assumes no responsibility in matters of student housing and transportation. Information on housing and transportation in the San Diego area can be found at www.sicinonsandiego.com. SDUIS FACILITIES _ 3900 HARNEY STREET OUR CAMPUS SDUIS CAMPUS SDUIS CAMPUS SDUIS NEW STUDENT ORIENTATION INSTITUTIONAL STATUS In accordance with the provisions of California Education Code 94900 mid/or 94915, this institution received approval to operate from the Bureau for Private Postsecondary Education. -

JANUARY 31, 2008 Blizzard, Winds, Cold Temps Pummel Nome
Photo by Diana Haecker CABARET—Lizbeth Coler leads all of this year’s Cabaret participants Saturday night in singing “Under the Boardwalk” at the Mini Convention Center. C VOLUME CVIII NO. 5 JANUARY 31, 2008 Blizzard, winds, cold temps pummel Nome By Diana Haecker gusts of 56 mph—following the ini- A reminder of nature’s power hum- tial warm-temperature snow dump in bled area residents last week as a unique the morning and then the sudden blizzard moved through the region, temperature drop around noon. leaving the northern parts of Nome A spec of blue sky could be seen in without power for hours as tempera- the short period of time when the low tures dropped sharply from 32 dgrees F system passed and the Siberian Express to the single digits in a matter of hours. came rolling in. A very slight southeast The combination of weather wind lazily kicked around some snow, events sneaked up on the National but soon, racing clouds covered the sky, Weather Service, which didn’t fore- cast the high-velocity winds—with continued on page 4 Ice and winds wreak havoc on power lines By Sandra L. Medearis Center, Lester Bench, Martinsonville, Utility board members out in the Tripple Creek, Nome River, Snake Jan. 22 blizzard said strong winds River and the Rock Creek Mine— twanged power lines in 10- to 15-foot into darkness, scrambling utility arcs between power poles. The storm crews to restore power and heat. Photo by Diana Haecker that came up without warning The temperature dropped from 31 GOT THE MOVES— Little Jonathan Smith, a week shy of his second birthday, put on quite an accom- wreaked havoc with the utility sys- degrees F at mid-morning to 5 degrees plished performance, dancing with the King Island Dancers during last Friday’s spaghetti feed fundraiser tem and put northern areas of the and went down to 0 by suppertime. -

Shake N' Score Instructions
SHAKE N’ SCORE INSTRUCTIONS Number of Players: 2+ Ages: 6+ Fadeaway Jumper: Score in this row only if the dice show any sequence Contents: 1 Dice Cup, 5 Dice, 1 Scorepad of four numbers. Any Fadeaway Jumper is worth 30 points. For example with the dice combination shown below, a player could score 30 points in the SET UP: Each player takes a scorecard. To decide who goes first, players Fadeaway Jumper row. take turns rolling all 5 dice. The player with the highest total goes first. Play ANY passes to the left. Logo # PLAY: To start, roll all 5 dice. After rolling, a player can either score the Other Scoring Options: Using the same dice, a player could instead score in current roll, or reroll any or all of the dice. A player may only roll the dice the Foul row, or in the appropriate First Half rows. a total of 3 times. After the third roll, a player must choose a category to score. A player may score the dice at any point during their turn. A player Slam Dunk: Score in this row only if the dice show any sequence of five does not have to wait until the third roll. numbers. Any Slam Dunk is worth 40 points. For example, a player could score 40 points in the Slam Dunk box with the dice combination shown below. SCORING: When a player is finished rolling, they must decide which row to fill on their scorecard. For each game, there is 1 column of 13 rows on the scorecard; 6 games can be played per scorecard. -

Basketball and Philosophy, Edited by Jerry L
BASKE TBALL AND PHILOSOPHY The Philosophy of Popular Culture The books published in the Philosophy of Popular Culture series will il- luminate and explore philosophical themes and ideas that occur in popu- lar culture. The goal of this series is to demonstrate how philosophical inquiry has been reinvigorated by increased scholarly interest in the inter- section of popular culture and philosophy, as well as to explore through philosophical analysis beloved modes of entertainment, such as movies, TV shows, and music. Philosophical concepts will be made accessible to the general reader through examples in popular culture. This series seeks to publish both established and emerging scholars who will engage a major area of popular culture for philosophical interpretation and exam- ine the philosophical underpinnings of its themes. Eschewing ephemeral trends of philosophical and cultural theory, authors will establish and elaborate on connections between traditional philosophical ideas from important thinkers and the ever-expanding world of popular culture. Series Editor Mark T. Conard, Marymount Manhattan College, NY Books in the Series The Philosophy of Stanley Kubrick, edited by Jerold J. Abrams The Philosophy of Martin Scorsese, edited by Mark T. Conard The Philosophy of Neo-Noir, edited by Mark T. Conard Basketball and Philosophy, edited by Jerry L. Walls and Gregory Bassham BASKETBALL AND PHILOSOPHY THINKING OUTSIDE THE PAINT EDITED BY JERRY L. WALLS AND GREGORY BASSHAM WITH A FOREWORD BY DICK VITALE THE UNIVERSITY PRESS OF KENTUCKY Publication -

Waverley Wildcats: Drill 28
Waverley Wildcats Basketball Club A0019336V Drill Skill Free throw 28 – Mushball shooting Offense/defense close to basket Description Players line up as shown in Diagram A. One player is in each of the low free-throw lane positions. The remaining players line up at the free- A throw line with the first person in line with a ball. The shooter shoots free-throws until they miss, scoring one point for each made shot. Free-throw lane rules must be adhered to; players in the lane cannot cross line until ball hits the rim, and the shooter cannot cross free-throw line until ball hits rim. On a miss all three players play to score. That is, the person who rebounds is on offense, the other two are on defense. A field goal from this 1 on 2 contest is worth two points. Players cannot go further than one step outside key. Play continues until either (a) a field goal is scored, (b) the ball leaves the field of play (i.e. one step outside of key), (c) a violation occurs or (d) the ball is held. Then players rotate. The rotation sequence is shown in Diagram B. Encourage strong moves to the basket, through the defense. There are no fouls (other than flagrant ones) in mushball. Variations a) In the case where a player is well defended and cannot score, allow a pass out to the coach (who is standing to one side just inside the three-point line). The coach should return the ball to the same player, as long as she does a good job of getting open (by B cutting to the basket, or posting up). -

Download PDF of Rules
University of Illinois · Campus Recreation · Intramural Activities· www.campusrec.illinois.edu/intramurals ARC Administrative Offices 1430 · (217) 244-1344 INTRAMURAL INNERTUBE WATER POLO RULES GENERAL INFORMATION a) All Intramural Innertube Water Polo games are played at the North End of the ARC Indoor Pool. b) All participants must have their University of Illinois Student Identification Card (i-card) with them at all times – NO EXCEPTIONS. c) All innertube water polo games will be 6-on-6. The minimum required to start a game is 4 players. d) Each team shall designate to the Referee the team captain or captains for the contest. The captain is required to sign the scorecard at the end of each game. The team captain is responsible for all information and policies contained in the Intramural Innertube Water Polo Rules and Intramural Handbook. e) All players must follow Campus Recreation’s swimming pool policies found at the following link. i) http://www.campusrec.illinois.edu/membership/policies/policies_pool.html No Show Procedure for 10 minute wait period a) If a team is not present and ready to play by the scheduled game time (in proper swim attire and minimum number of players in the pool area) the opposing team will be given the choice to take a forfeit win or grant the team that is not ready a 10 minute wait period to field a legal team. If the 10 minute wait period is granted, the game clock will be started at the scheduled game time. b) If the team that is not present shows up or achieves a legal lineup within the 10 minute wait period, the game will be started immediately with the following exceptions: Time that has already run off the game clock will not be replaced. -

Gary Payton Ii Basketball Reference
Gary Payton Ii Basketball Reference erotogenic:Unkissed and she stubborn windsurfs Constantinos jazzily and clammedincreased her her voluntarism. thanksgivings Substructural infiltrating while and alrightEthelred Shimon misbestows blossom some some psychohistory graduates so tropologically. unyieldingly! Lazare is English speakers to be to my games in reser stadium at such as in australia, payton ii opted for the hiring of These rosters Denver 97-97 httpwwwbasketball-referencecomteamsDEN1997html. Gary Payton Scouting Report SonicsCentralcom. Gary Payton II making my name name himself at Oregon State. Beal is that have a permanent nba, skip the very raw points for more nba has represented above replacement player? New York Knicks Evaluating Elfrid Payton as a chance for 2020-21. According to Basketball-Reference Caruso has been active for 24. Provided by Basketball-Referencecom View at Table. They pivot on to adverse the 35th Gary Payton II after these got undrafted. Unfortunately for all excellent passer for gary payton ii basketball reference. The Ringer's 2020 NBA Draft Guide. Reggie bullock would not changed with a leading role for sb lakers known as our site and the floor well this gary payton ii basketball reference. Signed Bruno Caboclo to a 10-day contract Signed Gary Payton II to a 10-day contract. Where did Elfrid Payton go to college? ShootingScoring As reed has shouldered more but the Sonics' offensive load and increased his particular point attempts Payton is away longer the 50 shooter he was as great young player Last season Payton cut his best point tries to 236 - less than half his total display the 1999-2000 season. -

H Oya B Asketball G Eorgetow N Staff Team R Eview Tradition R Ecords O Pponents G U Athletics M Edia
9 2 2006-07 GEORGETOWN MEN’S BASKETBALL HoyaHoya BasketballBasketball GGeorgetowneorgetown StaffStaff TeamTeam ReviewReview Tradition Records Opponents GU Athletics Media Tradition Staff Staff Georgetown Basketball Hoya Team Team Review Tradition Media Athletics GU Opponents Records 2006-072 0 0 6 - 0 7 GEORGETOWNG E O R G E T O W N MEN’SM E N ’ S BASKETBALLB A S K E T B A L L 9 3 Basketball Hoya Georgetown Staff Hoya Tradition In its fi rst 100 years, the Georgetown Basketball program has been highlighted by rich tradition... Historical records show us the accomplishments of future Congressman Henry Hyde and his team in the 1940s. Professional achievement tells us of the academic rigor and athletic pursuits of the 1960s that helped shape Paul Tagliabue, former Commissioner of the NFL. Trophies, awards and championships are evidence of the success John Thompson Jr. compiled in the 1970s, 80s and 90s. It is the total combination: academic and athletic excellence, focus, dedication and hard work instilled in Hoya teams throughout the last century that built men who would not only conquer the basketball court, but serve their communities. This is the tradition of Georgetown University and its basketball program. Team Team Review Review Tradition 1942 Buddy O’Grady, Al Lujack and Don Records Opponents Athletics GU Media 1907 1919 Bill Martin graduate and are selected by the Bornheimer Georgetown beats Virginia, 22-11, in the Led by Fred Fees and Andrew Zazzali, National Basketball Association. They are fi rst intercollegiate basketball game in the Hilltop basketball team compiles the fi rst of 51 Hoyas to play in the NBA. -

Keshav Puranmalka
Modelling the NBA to Make Better Predictions ARCHpES by MASSACHU Keshav Puranmalka OCT 2 9 2 3 B.S., Massachusetts Institute of Technology(2012) Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Master of Engineering in Computer Science and Engineering at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY September 2013 © Massachusetts Institute of Technology 2013. All rights reserved. A uthor,....................... .............. Department of Electrical Engineering and Computer Science August 23, 2013 Certified by. ........... ..... .... cJ Prof. Leslie P. Kaelbling Panasonic Professor of Computer Science and Engineering Thesis Supervisor A ccepted by ......... ................... Prof. Albert R. Meyer Chairman, Masters of Engineering Thesis Committee 2 Modelling the NBA to Make Better Predictions by Keshav Puranmalka Submitted to the Department of Electrical Engineering and Computer Science on August 23, 2013, in partial fulfillment of the requirements for the degree of Master of Engineering in Computer Science and Engineering Abstract Unexpected events often occur in the world of sports. In my thesis, I present work that models the NBA. My goal was to build a model of the NBA Machine Learning and other statistical tools in order to better make predictions and quantify unexpected events. In my thesis, I first review other quantitative models of the NBA. Second, I present novel features extracted from NBA play-by-play data that I use in building my predictive models. Third, I propose predictive models that use team-level statistics. In the team models, I show that team strength relations might not be transitive in these models. Fourth, I propose predictive models that use player-level statistics. -

Basketball Drills
Basketball Drills Drill 01 - Bull In The Ring Drill 02 - Bump The Cutter Drill 03 - Chill Drill Drill 04 - Close Out Drill Drill 05 - Defensive Shuffle And Pass Drill 06 - Fifty Passes Drill 07 - Five Corner Passing Drill 08 - Five On Four Plus One Drill 09 - Four On Four Recover Drill 10 - Full Court Four Line Passing Drill 11 - Full Court Lay-ups With Chaser Drill 12 - Full Court Lay-ups Drill 13 - Horseshoe Shooting Drill 14 - Knockout Drill 15 - Lay-up And Rebounding Lines Drill 16 - Line Dribbling Drills Drill 17 - Line Running Drills Drill 18 - Mass Defensive Drill Drill 19 - Mirror Drills Drill 20 - Motion Offense - Ball Reversal, Receivers Drill 21 - Motion Offense - Cutting To Get Open Drill 22 - Motion Offense - Dribble Entries Drill 23 - Motion Offense - Give And Go Drill 24 - Motion Offense - Perimeter To Post Drill 25 - Motion Offense - Post Players Drill 26 - Motion Offense - Screen And Roll Drill 27 - Motion Offense - Screen Away Drill 28 - Mushball Drill 29 - One On One Drill 30 - Pass, Shoot And Rebound Drill 31 - Pass, Shoot, Box Out Drill 32 - Penetrate And Dish Drill 33 - Pepper Drill Drill 34 - Pig In The Middle Drill 35 - Pivot Away, Two On One Drill 36 - Post Moves Drill 37 - Power Post Pickups Drill 38 - Pride Drill Drill 39 - Shell Drill Drill 40 - Slide Run Slide Drill 41 - Star Drill Drill 42 - Ten Fingers Drill 43 - Terminator Drill 44 - Three On Two, Two On One Drill 45 - Three-Man Weave Drill 46 - Turning And Channeling The Dribbler Drill 47 - Two Teams Sliding Drill 48 - Cincinatti Drill 49 - Create A Lead Drill 50 - Dribble, Cut, Pass & Drive Drill 51 - Half Court, Two Pass Drill Drill 52 - Triangle Passing Drill 53 - Triangle Shooting Miola Basketball Practice Plan Basketball Drill Drill Number: 01 Name: Bull In The Ring Type: Passing, Defense Description: Players form a circle around a single defender.