Clinically Annotated Breast, Ovarian and Pancreatic Cancer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplementary Data
Figure 2S 4 7 A - C 080125 CSCs 080418 CSCs - + IFN-a 48 h + IFN-a 48 h + IFN-a 72 h 6 + IFN-a 72 h 3 5 MRFI 4 2 3 2 1 1 0 0 MHC I MHC II MICA MICB ULBP-1 ULBP-2 ULBP-3 ULBP-4 MHC I MHC II MICA MICB ULBP-1 ULBP-2 ULBP-3 ULBP-4 7 B 13 080125 FBS - D 080418 FBS - + IFN-a 48 h 12 + IFN-a 48 h + IFN-a 72 h + IFN-a 72 h 6 080125 FBS 11 10 5 9 8 4 7 6 3 MRFI 5 4 2 3 2 1 1 0 0 MHC I MHC II MICA MICB ULBP-1 ULBP-2 ULBP-3 ULBP-4 MHC I MHC II MICA MICB ULBP-1 ULBP-2 ULBP-3 ULBP-4 Molecule Molecule FIGURE 4S FIGURE 5S Panel A Panel B FIGURE 6S A B C D Supplemental Results Table 1S. Modulation by IFN-α of APM in GBM CSC and FBS tumor cell lines. Molecule * Cell line IFN-α‡ HLA β2-m# HLA LMP TAP1 TAP2 class II A A HC§ 2 7 10 080125 CSCs - 1∞ (1) 3 (65) 2 (91) 1 (2) 6 (47) 2 (61) 1 (3) 1 (2) 1 (3) + 2 (81) 11 (80) 13 (99) 1 (3) 8 (88) 4 (91) 1 (2) 1 (3) 2 (68) 080125 FBS - 2 (81) 4 (63) 4 (83) 1 (3) 6 (80) 3 (67) 2 (86) 1 (3) 2 (75) + 2 (99) 14 (90) 7 (97) 5 (75) 7 (100) 6 (98) 2 (90) 1 (4) 3 (87) 080418 CSCs - 2 (51) 1 (1) 1 (3) 2 (47) 2 (83) 2 (54) 1 (4) 1 (2) 1 (3) + 2 (81) 3 (76) 5 (75) 2 (50) 2 (83) 3 (71) 1 (3) 2 (87) 1 (2) 080418 FBS - 1 (3) 3 (70) 2 (88) 1 (4) 3 (87) 2 (76) 1 (3) 1 (3) 1 (2) + 2 (78) 7 (98) 5 (99) 2 (94) 5 (100) 3 (100) 1 (4) 2 (100) 1 (2) 070104 CSCs - 1 (2) 1 (3) 1 (3) 2 (78) 1 (3) 1 (2) 1 (3) 1 (3) 1 (2) + 2 (98) 8 (100) 10 (88) 4 (89) 3 (98) 3 (94) 1 (4) 2 (86) 2 (79) * expression of APM molecules was evaluated by intracellular staining and cytofluorimetric analysis; ‡ cells were treatead or not (+/-) for 72 h with 1000 IU/ml of IFN-α; # β-2 microglobulin; § β-2 microglobulin-free HLA-A heavy chain; ∞ values are indicated as ratio between the mean of fluorescence intensity of cells stained with the selected mAb and that of the negative control; bold values indicate significant MRFI (≥ 2). -

Mechanical Forces Induce an Asthma Gene Signature in Healthy Airway Epithelial Cells Ayşe Kılıç1,10, Asher Ameli1,2,10, Jin-Ah Park3,10, Alvin T
www.nature.com/scientificreports OPEN Mechanical forces induce an asthma gene signature in healthy airway epithelial cells Ayşe Kılıç1,10, Asher Ameli1,2,10, Jin-Ah Park3,10, Alvin T. Kho4, Kelan Tantisira1, Marc Santolini 1,5, Feixiong Cheng6,7,8, Jennifer A. Mitchel3, Maureen McGill3, Michael J. O’Sullivan3, Margherita De Marzio1,3, Amitabh Sharma1, Scott H. Randell9, Jefrey M. Drazen3, Jefrey J. Fredberg3 & Scott T. Weiss1,3* Bronchospasm compresses the bronchial epithelium, and this compressive stress has been implicated in asthma pathogenesis. However, the molecular mechanisms by which this compressive stress alters pathways relevant to disease are not well understood. Using air-liquid interface cultures of primary human bronchial epithelial cells derived from non-asthmatic donors and asthmatic donors, we applied a compressive stress and then used a network approach to map resulting changes in the molecular interactome. In cells from non-asthmatic donors, compression by itself was sufcient to induce infammatory, late repair, and fbrotic pathways. Remarkably, this molecular profle of non-asthmatic cells after compression recapitulated the profle of asthmatic cells before compression. Together, these results show that even in the absence of any infammatory stimulus, mechanical compression alone is sufcient to induce an asthma-like molecular signature. Bronchial epithelial cells (BECs) form a physical barrier that protects pulmonary airways from inhaled irritants and invading pathogens1,2. Moreover, environmental stimuli such as allergens, pollutants and viruses can induce constriction of the airways3 and thereby expose the bronchial epithelium to compressive mechanical stress. In BECs, this compressive stress induces structural, biophysical, as well as molecular changes4,5, that interact with nearby mesenchyme6 to cause epithelial layer unjamming1, shedding of soluble factors, production of matrix proteins, and activation matrix modifying enzymes, which then act to coordinate infammatory and remodeling processes4,7–10. -

1 Long-Read Genome Sequencing for the Diagnosis Of
bioRxiv preprint doi: https://doi.org/10.1101/2020.07.02.185447; this version posted September 14, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Long-read genome sequencing for the diagnosis of neurodevelopmental disorders Susan M. Hiatt1, James M.J. Lawlor1, Lori H. Handley1, Ryne C. Ramaker1, Brianne B. Rogers1,2, E. Christopher Partridge1, Lori Beth Boston1, Melissa Williams1, Christopher B. Plott1, Jerry Jenkins1, David E. Gray1, James M. Holt1, Kevin M. Bowling1, E. Martina Bebin3, Jane Grimwood1, Jeremy Schmutz1, Gregory M. Cooper1* 1HudsonAlpha Institute for Biotechnology, Huntsville, AL, USA, 35806 2Department of Genetics, University of Alabama at Birmingham, Birmingham, AL, USA, 35924 3Department of Neurology, University of Alabama at Birmingham, Birmingham, AL, USA, 35924 *[email protected], 256-327-9490 Conflicts of Interest The authors all declare no conflicts of interest. 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.07.02.185447; this version posted September 14, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-ND 4.0 International license. Abstract Purpose Exome and genome sequencing have proven to be effective tools for the diagnosis of neurodevelopmental disorders (NDDs), but large fractions of NDDs cannot be attributed to currently detectable genetic variation. This is likely, at least in part, a result of the fact that many genetic variants are difficult or impossible to detect through typical short-read sequencing approaches. -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Maintenance of the Marginal Zone B Cell Compartment Specifically Requires the RNA-Binding Protein ZFP36L1
Europe PMC Funders Group Author Manuscript Nat Immunol. Author manuscript; available in PMC 2017 October 10. Published in final edited form as: Nat Immunol. 2017 June ; 18(6): 683–693. doi:10.1038/ni.3724. Europe PMC Funders Author Manuscripts Maintenance of the marginal zone B cell compartment specifically requires the RNA-binding protein ZFP36L1 Rebecca Newman1,2, Helena Ahlfors1, Alexander Saveliev1, Alison Galloway1, Daniel J Hodson3, Robert Williams1, Gurdyal S. Besra4, Charlotte N Cook5, Adam F Cunningham5, Sarah E Bell1, and Martin Turner1,* 1Laboratory of Lymphocyte Signalling and Development, The Babraham Institute, Babraham Research Campus, Cambridge, CB22 3AT, United Kingdom 2Immune Receptor Activation Laboratory, The Francis Crick Institute, 1 Midland Road, London, NW1 1AT, United Kingdom 3Department of Haematology, University of Cambridge, The Clifford Allbutt Building, Cambridge Biomedical Campus, Hills Road, Cambridge, CB2 0AH, United Kingdom 4School of Biosciences, University of Birmingham, Birmingham, B15 2TT, United Kingdom 5MRC Centre for Immune Regulation, School of Immunity and Infection, University of Birmingham, Birmingham, B15 2TT, United Kingdom Abstract Europe PMC Funders Author Manuscripts RNA binding proteins (RBP) of the ZFP36 family are best known for inhibiting the expression of cytokines through binding to AU rich elements in the 3’UTR and promoting mRNA decay. Here we show an indispensible role for ZFP36L1 as the regulator of a post-transcriptional hub that determined the identity of marginal zone (MZ) B cells by promoting their proper localization and survival. ZFP36L1 controlled a gene expression program related to signaling, cell-adhesion and locomotion, in part by limiting the expression of the transcription factors KLF2 and IRF8, which are known to enforce the follicular B cell phenotype. -

(PWP2) Gene Mapping to 21Q22.3 Ronald G
Downloaded from genome.cshlp.org on October 2, 2021 - Published by Cold Spring Harbor Laboratory Press LETTER Isolation and Genomic Structure of a Human Homolog of the Yeast Periodic Tryptophan Protein 2 (PWP2) Gene Mapping to 21q22.3 Ronald G. Lafrenii~re, 1'4 Daniel L. Rochefort, 1 Nathalie Chr~tien, ~ Catherine E. Neville, 2 Robert G. Korneluk, 2 Lin Zuo, 3 Yalin Wei, 3 Jay Lichter, 3 and Guy A. Rouleau ~ 1Centre for Research in Neuroscience, McGill University, and Department of Neurology, Montreal General Hospital Research Institute, Montreal, Canada H3G 1A4; 2DNA Sequencing Core Facility, Canadian Genetic Diseases Network, Children's Hospital of Eastern Ontario, Ottawa, Canada K1H 8L1; 3Sequana Therapeutics, Inc., La Jolla, California 92037 As part of efforts to identify candidate genes for diseases mapping to the 21q22.3 region, we have assembled a 770-kb cosmid and BAC contig containing eight tightly linked markers. These cosmids and BACs were restriction mapped using eight rare cutting enzymes, with the goal of identifying CpG-rich islands. One such island was identified by the clustering of lqotl, Eagl, Sstll, and BssHIl sites, and corresponded to the Nod linking clone LJI04 described previously. A 7.6-kb l-lindlll fragment containing this CpG-rich island was subcloned and partially sequenced. A homology search using the sequence obtained from either side of the Nod site identified an expressed sequence tag with homology to the yeast periodic tryptophan protein 2 (PWP2). Several cDNAs corresponding to the human PWP2 gene were identified and partially sequenced. Northern blot analysis revealed a 3.3-kb transcript that was well expressed in all tissues tested. -

Regulates Cellular Telomerase Activity by Methylation of TERT Promoter
www.impactjournals.com/oncotarget/ Oncotarget, 2017, Vol. 8, (No. 5), pp: 7977-7988 Research Paper Tianshengyuan-1 (TSY-1) regulates cellular Telomerase activity by methylation of TERT promoter Weibo Yu1, Xiaotian Qin2, Yusheng Jin1, Yawei Li2, Chintda Santiskulvong3, Victor Vu1, Gang Zeng4,5, Zuofeng Zhang6, Michelle Chow1, Jianyu Rao1,5 1Department of Pathology and Laboratory Medicine, David Geffen School of Medicine, University of California at Los Angeles, Los Angeles, CA, USA 2Beijing Boyuantaihe Biological Technology Co., Ltd., Beijing, China 3Genomics Core, Cedars-Sinai Medical Center, Los Angeles, CA, USA 4Department of Urology, David Geffen School of Medicine, University of California at Los Angeles, Los Angeles, CA, USA 5Jonsson Comprehensive Cancer Center, University of California at Los Angeles, Los Angeles, CA, USA 6Department of Epidemiology, School of Public Health, University of California at Los Angeles, Los Angeles, CA, USA Correspondence to: Jianyu Rao, email: [email protected] Keywords: TSY-1, hematopoietic cells, Telomerase, TERT, methylation Received: September 08, 2016 Accepted: November 24, 2016 Published: December 15, 2016 ABSTRACT Telomere and Telomerase have recently been explored as anti-aging and anti- cancer drug targets with only limited success. Previously we showed that the Chinese herbal medicine Tianshengyuan-1 (TSY-1), an agent used to treat bone marrow deficiency, has a profound effect on stimulating Telomerase activity in hematopoietic cells. Here, the mechanism of TSY-1 on cellular Telomerase activity was further investigated using HL60, a promyelocytic leukemia cell line, normal peripheral blood mononuclear cells, and CD34+ hematopoietic stem cells derived from umbilical cord blood. TSY-1 increases Telomerase activity in normal peripheral blood mononuclear cells and CD34+ hematopoietic stem cells with innately low Telomerase activity but decreases Telomerase activity in HL60 cells with high intrinsic Telomerase activity, both in a dose-response manner. -
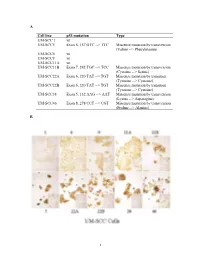
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Mouse Ppef1 Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Ppef1 Knockout Project (CRISPR/Cas9) Objective: To create a Ppef1 knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Ppef1 gene (NCBI Reference Sequence: NM_011147 ; Ensembl: ENSMUSG00000062168 ) is located on Mouse chromosome X. 16 exons are identified, with the ATG start codon in exon 1 and the TAA stop codon in exon 16 (Transcript: ENSMUST00000071204). Exon 2~4 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Homozygous null female and hemizygous null male mice are viable, fertile and display no overt abnormalities. Exon 2 starts from about 2.41% of the coding region. Exon 2~4 covers 18.41% of the coding region. The size of effective KO region: ~10105 bp. The KO region does not have any other known gene. Page 1 of 8 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 2 3 4 16 Legends Exon of mouse Ppef1 Knockout region Page 2 of 8 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section upstream of Exon 2 is aligned with itself to determine if there are tandem repeats. No significant tandem repeat is found in the dot plot matrix. So this region is suitable for PCR screening or sequencing analysis. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section downstream of Exon 4 is aligned with itself to determine if there are tandem repeats. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

NBN Gene Analysis and It's Impact on Breast Cancer
Journal of Medical Systems (2019) 43: 270 https://doi.org/10.1007/s10916-019-1328-z IMAGE & SIGNAL PROCESSING NBN Gene Analysis and it’s Impact on Breast Cancer P. Nithya1 & A. ChandraSekar1 Received: 8 March 2019 /Accepted: 7 May 2019 /Published online: 5 July 2019 # Springer Science+Business Media, LLC, part of Springer Nature 2019 Abstract Single Nucleotide Polymorphism (SNP) researches have become essential in finding out the congenital relationship of structural deviations with quantitative traits, heritable diseases and physical responsiveness to different medicines. NBN is a protein coding gene (Breast Cancer); Nibrin is used to fix and rebuild the body from damages caused because of strand breaks (both singular and double) associated with protein nibrin. NBN gene was retrieved from dbSNP/NCBI database and investigated using computational SNP analysis tools. The encrypted region in SNPs (exonal SNPs) were analyzed using software tools, SIFT, Provean, Polyphen, INPS, SNAP and Phd-SNP. The 3’ends of SNPs in un-translated region were also investigated to determine the impact of binding. The association of NBN gene polymorphism leads to several diseases was studied. Four SNPs were predicted to be highly damaged in coding regions which are responsible for the diseases such as, Aplastic Anemia, Nijmegan breakage syndrome, Microsephaly normal intelligence, immune deficiency and hereditary cancer predisposing syndrome (clivar). The present study will be helpful in finding the suitable drugs in future for various diseases especially for breast cancer. Keywords NBN . Single nucleotide polymorphism . Double strand breaks . nsSNP . Associated diseases Introduction NBN has a more complex structure due to its interaction with large proteins formed from the ATM gene which is NBN (Nibrin) is a protein coding gene, it is also known as highly essential in identifying damaged strands of DNA NBS1, Cell cycle regulatory Protein P95, is situated on and facilitating their repair [1]. -

Supplement 1 Microarray Studies
EASE Categories Significantly Enriched in vs MG vs vs MGC4-2 Pt1-C vs C4-2 Pt1-C UP-Regulated Genes MG System Gene Category EASE Global MGRWV Pt1-N RWV Pt1-N Score FDR GO Molecular Extracellular matrix cellular construction 0.0008 0 110 genes up- Function Interpro EGF-like domain 0.0009 0 regulated GO Molecular Oxidoreductase activity\ acting on single dono 0.0015 0 Function GO Molecular Calcium ion binding 0.0018 0 Function Interpro Laminin-G domain 0.0025 0 GO Biological Process Cell Adhesion 0.0045 0 Interpro Collagen Triple helix repeat 0.0047 0 KEGG pathway Complement and coagulation cascades 0.0053 0 KEGG pathway Immune System – Homo sapiens 0.0053 0 Interpro Fibrillar collagen C-terminal domain 0.0062 0 Interpro Calcium-binding EGF-like domain 0.0077 0 GO Molecular Cell adhesion molecule activity 0.0105 0 Function EASE Categories Significantly Enriched in Down-Regulated Genes System Gene Category EASE Global Score FDR GO Biological Process Copper ion homeostasis 2.5E-09 0 Interpro Metallothionein 6.1E-08 0 Interpro Vertebrate metallothionein, Family 1 6.1E-08 0 GO Biological Process Transition metal ion homeostasis 8.5E-08 0 GO Biological Process Heavy metal sensitivity/resistance 1.9E-07 0 GO Biological Process Di-, tri-valent inorganic cation homeostasis 6.3E-07 0 GO Biological Process Metal ion homeostasis 6.3E-07 0 GO Biological Process Cation homeostasis 2.1E-06 0 GO Biological Process Cell ion homeostasis 2.1E-06 0 GO Biological Process Ion homeostasis 2.1E-06 0 GO Molecular Helicase activity 2.3E-06 0 Function GO Biological