Post-Transcriptionally Impaired De Novo Mutations Contribute to The
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download (PDF)
ANALYTICAL SCIENCES NOVEMBER 2020, VOL. 36 1 2020 © The Japan Society for Analytical Chemistry Supporting Information Fig. S1 Detailed MS/MS data of myoglobin. 17 2 ANALYTICAL SCIENCES NOVEMBER 2020, VOL. 36 Table S1 : The protein names (antigens) identified by pH 2.0 solution in the eluted-fraction. These proteins were identified one or more out of six analyses. Accession Description P08908 5-hydroxytryptamine receptor 1A OS=Homo sapiens GN=HTR1A PE=1 SV=3 - [5HT1A_HUMAN] Q9NRR6 72 kDa inositol polyphosphate 5-phosphatase OS=Homo sapiens GN=INPP5E PE=1 SV=2 - [INP5E_HUMAN] P82987 ADAMTS-like protein 3 OS=Homo sapiens GN=ADAMTSL3 PE=2 SV=4 - [ATL3_HUMAN] Q9Y6K8 Adenylate kinase isoenzyme 5 OS=Homo sapiens GN=AK5 PE=1 SV=2 - [KAD5_HUMAN] P02763 Alpha-1-acid glycoprotein 1 OS=Homo sapiens GN=ORM1 PE=1 SV=1 - [A1AG1_HUMAN] P19652 Alpha-1-acid glycoprotein 2 OS=Homo sapiens GN=ORM2 PE=1 SV=2 - [A1AG2_HUMAN] P01011 Alpha-1-antichymotrypsin OS=Homo sapiens GN=SERPINA3 PE=1 SV=2 - [AACT_HUMAN] P01009 Alpha-1-antitrypsin OS=Homo sapiens GN=SERPINA1 PE=1 SV=3 - [A1AT_HUMAN] P04217 Alpha-1B-glycoprotein OS=Homo sapiens GN=A1BG PE=1 SV=4 - [A1BG_HUMAN] P08697 Alpha-2-antiplasmin OS=Homo sapiens GN=SERPINF2 PE=1 SV=3 - [A2AP_HUMAN] P02765 Alpha-2-HS-glycoprotein OS=Homo sapiens GN=AHSG PE=1 SV=1 - [FETUA_HUMAN] P01023 Alpha-2-macroglobulin OS=Homo sapiens GN=A2M PE=1 SV=3 - [A2MG_HUMAN] P01019 Angiotensinogen OS=Homo sapiens GN=AGT PE=1 SV=1 - [ANGT_HUMAN] Q9NQ90 Anoctamin-2 OS=Homo sapiens GN=ANO2 PE=1 SV=2 - [ANO2_HUMAN] P01008 Antithrombin-III -

PARSANA-DISSERTATION-2020.Pdf
DECIPHERING TRANSCRIPTIONAL PATTERNS OF GENE REGULATION: A COMPUTATIONAL APPROACH by Princy Parsana A dissertation submitted to The Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland July, 2020 © 2020 Princy Parsana All rights reserved Abstract With rapid advancements in sequencing technology, we now have the ability to sequence the entire human genome, and to quantify expression of tens of thousands of genes from hundreds of individuals. This provides an extraordinary opportunity to learn phenotype relevant genomic patterns that can improve our understanding of molecular and cellular processes underlying a trait. The high dimensional nature of genomic data presents a range of computational and statistical challenges. This dissertation presents a compilation of projects that were driven by the motivation to efficiently capture gene regulatory patterns in the human transcriptome, while addressing statistical and computational challenges that accompany this data. We attempt to address two major difficulties in this domain: a) artifacts and noise in transcriptomic data, andb) limited statistical power. First, we present our work on investigating the effect of artifactual variation in gene expression data and its impact on trans-eQTL discovery. Here we performed an in-depth analysis of diverse pre-recorded covariates and latent confounders to understand their contribution to heterogeneity in gene expression measurements. Next, we discovered 673 trans-eQTLs across 16 human tissues using v6 data from the Genotype Tissue Expression (GTEx) project. Finally, we characterized two trait-associated trans-eQTLs; one in Skeletal Muscle and another in Thyroid. Second, we present a principal component based residualization method to correct gene expression measurements prior to reconstruction of co-expression networks. -

Supplementary Methods
SUPPLEMENTARY METHODS Epilepsy cohorts Epilepsy cohorts contributing to the meta-analysis are detailed below. EPIGEN (Reported by – Chantal Depondt, Sanjay Sisodiya, Norman Delanty, Gianpiero Cavalleri, Erin Heinzen and David Goldstein) The EPIGEN study consisted of epilepsy cohorts from Beaumont Hospital Dublin (Ireland), Université Libre de Bruxelles (ULB, Belgium), Duke University Medical Centre (North Carolina, USA) and University College Hospital London (UK). Inclusion Criteria: Except for Duke, only adult (>16 years) patients with epilepsy were recruited. Exclusion Criteria: No specific exclusion criteria. Quality assurance: At all sites, subjects were recruited and phenotyped by experienced epilepsy specialists. At Duke, all cases underwent independent case-record review by an epilepsy nurse specialist, and ambiguous diagnoses were re-evaluated by a second epileptologist. If the diagnosis remained unclear, then the patient was excluded from the study. For London, all cases underwent review by independent epileptologists. For Brussels, study PI (Chantal Depondt) reviewed the classification of all cases by case-note review. For Dublin, no systematic quality assurance was undertaken. Site-specific details for each EPIGEN cohort as organized for the analysis are as follows: – EPIGEN-Dublin Patients were recruited from a specialized epilepsy clinic at Beaumont Hospital, Dublin, Ireland. Patients were mostly of Irish ethnicity. Patients were genotyped on the Illumina platform using a combination of chips (610-Quad+550+300v1/Omni1-Quad). – EPIGEN-Brussels Patients were recruited from epilepsy clinics at UZ Gasthuisberg, Katholieke Universiteit Leuven, and Hôpital Erasme, Université Libre de Bruxelles. Patients were largely of Belgian ethnicity. Patients were genotyped on the Illumina platform using a combination of chips (610-Quad/300 V1 & V2). -

Diseasespecific and Inflammationindependent Stromal
Full Length Arthritis & Rheumatism DOI 10.1002/art.37704 Disease-specific and inflammation-independent stromal alterations in spondyloarthritis synovitis Nataliya Yeremenko1,2, Troy Noordenbos1,2, Tineke Cantaert1,3, Melissa van Tok1,2, Marleen van de Sande1, Juan D. Cañete4, Paul P. Tak1,5*, Dominique Baeten1,2 1Department of Clinical Immunology and Rheumatology and 2Department of Experimental Immunology, Academic Medical Center/University of Amsterdam, the Netherlands. 3Department of Immunobiology, Yale University School of Medicine, New Haven, CT, USA. 4Department of Rheumatology, Hospital Clinic de Barcelona and IDIBAPS, Spain. 5Arthrogen B.V., Amsterdam, the Netherlands. *Currently also: GlaxoSmithKline, Stevenage, U.K. Corresponding author: Dominique Baeten, MD, PhD, Department of Clinical Immunology and Rheumatology, F4-105, Academic Medical Center/University of Amsterdam, Meibergdreef 9, 1105 AZ Amsterdam, The Netherlands. E-mail: [email protected] This article has been accepted for publication and undergone full peer review but has not been through the copyediting, typesetting, pagination and proofreading process which may lead to differences between this version and the Version of Record. Please cite this article as an ‘Accepted Article’, doi: 10.1002/art.37704 © 2012 American College of Rheumatology Received: Apr 11, 2012; Revised: Jul 25, 2012; Accepted: Sep 06, 2012 Arthritis & Rheumatism Page 2 of 36 Abstract Objective: The molecular processes driving the distinct patterns of synovial inflammation and tissue remodelling in spondyloarthritis (SpA) versus rheumatoid arthritis (RA) remain largely unknown. Therefore, we aimed to identify novel and unsuspected disease- specific pathways in SpA by a systematic and unbiased synovial gene expression analysis. Methods: Differentially expressed genes were identified by pan-genomic microarray and confirmed by quantitative PCR and immunohistochemistry using synovial tissue biopsies of SpA (n=63), RA (n=28) and gout (n=9) patients. -

Podocyte Specific Knockdown of Klf15 in Podocin-Cre Klf15flox/Flox Mice Was Confirmed
SUPPLEMENTARY FIGURE LEGENDS Supplementary Figure 1: Podocyte specific knockdown of Klf15 in Podocin-Cre Klf15flox/flox mice was confirmed. (A) Primary glomerular epithelial cells (PGECs) were isolated from 12-week old Podocin-Cre Klf15flox/flox and Podocin-Cre Klf15+/+ mice and cultured at 37°C for 1 week. Real-time PCR was performed for Nephrin, Podocin, Synaptopodin, and Wt1 mRNA expression (n=6, ***p<0.001, Mann-Whitney test). (B) Real- time PCR was performed for Klf15 mRNA expression (n=6, *p<0.05, Mann-Whitney test). (C) Protein was also extracted and western blot analysis for Klf15 was performed. The representative blot of three independent experiments is shown in the top panel. The bottom panel shows the quantification of Klf15 by densitometry (n=3, *p<0.05, Mann-Whitney test). (D) Immunofluorescence staining for Klf15 and Wt1 was performed in 12-week old Podocin-Cre Klf15flox/flox and Podocin-Cre Klf15+/+ mice. Representative images from four mice in each group are shown in the left panel (X 20). Arrows show colocalization of Klf15 and Wt1. Arrowheads show a lack of colocalization. Asterisk demonstrates nonspecific Wt1 staining. “R” represents autofluorescence from RBCs. In the right panel, a total of 30 glomeruli were selected in each mouse and quantification of Klf15 staining in the podocytes was determined by the ratio of Klf15+ and Wt1+ cells to Wt1+ cells (n=6 mice, **p<0.01, unpaired t test). Supplementary Figure 2: LPS treated Podocin-Cre Klf15flox/flox mice exhibit a lack of recovery in proteinaceous casts and tubular dilatation after DEX administration. -

Directed Proximity-Dependent Biotin Labelling in Zebrafish
TOOLS AND RESOURCES In vivo proteomic mapping through GFP- directed proximity-dependent biotin labelling in zebrafish Zherui Xiong1, Harriet P Lo1, Kerrie-Ann McMahon1, Nick Martel1, Alun Jones1, Michelle M Hill2, Robert G Parton1,3*, Thomas E Hall1* 1Institute for Molecular Bioscience, The University of Queensland, Brisbane, Australia; 2QIMR Berghofer Medical Research Institute, Herston, Australia; 3Centre for Microscopy and Microanalysis, The University of Queensland, Brisbane, Australia Abstract Protein interaction networks are crucial for complex cellular processes. However, the elucidation of protein interactions occurring within highly specialised cells and tissues is challenging. Here, we describe the development, and application, of a new method for proximity- dependent biotin labelling in whole zebrafish. Using a conditionally stabilised GFP-binding nanobody to target a biotin ligase to GFP-labelled proteins of interest, we show tissue-specific proteomic profiling using existing GFP-tagged transgenic zebrafish lines. We demonstrate the applicability of this approach, termed BLITZ (Biotin Labelling In Tagged Zebrafish), in diverse cell types such as neurons and vascular endothelial cells. We applied this methodology to identify interactors of caveolar coat protein, cavins, in skeletal muscle. Using this system, we defined specific interaction networks within in vivo muscle cells for the closely related but functionally distinct Cavin4 and Cavin1 proteins. *For correspondence: Introduction [email protected] (RGP); [email protected] (TEH) The understanding of the biological functions of a protein requires detailed knowledge of the mole- cules with which it interacts. However, robust elucidation of interacting proteins, including not only Competing interests: The strong direct protein-protein interactions, but also weak, transient or indirect interactions is challeng- authors declare that no ing. -

Synergistic Genetic Interactions Between Pkhd1 and Pkd1 Result in an ARPKD-Like Phenotype in Murine Models
BASIC RESEARCH www.jasn.org Synergistic Genetic Interactions between Pkhd1 and Pkd1 Result in an ARPKD-Like Phenotype in Murine Models Rory J. Olson,1 Katharina Hopp ,2 Harrison Wells,3 Jessica M. Smith,3 Jessica Furtado,1,4 Megan M. Constans,3 Diana L. Escobar,3 Aron M. Geurts,5 Vicente E. Torres,3 and Peter C. Harris 1,3 Due to the number of contributing authors, the affiliations are listed at the end of this article. ABSTRACT Background Autosomal recessive polycystic kidney disease (ARPKD) and autosomal dominant polycystic kidney disease (ADPKD) are genetically distinct, with ADPKD usually caused by the genes PKD1 or PKD2 (encoding polycystin-1 and polycystin-2, respectively) and ARPKD caused by PKHD1 (encoding fibrocys- tin/polyductin [FPC]). Primary cilia have been considered central to PKD pathogenesis due to protein localization and common cystic phenotypes in syndromic ciliopathies, but their relevance is questioned in the simple PKDs. ARPKD’s mild phenotype in murine models versus in humans has hampered investi- gating its pathogenesis. Methods To study the interaction between Pkhd1 and Pkd1, including dosage effects on the phenotype, we generated digenic mouse and rat models and characterized and compared digenic, monogenic, and wild-type phenotypes. Results The genetic interaction was synergistic in both species, with digenic animals exhibiting pheno- types of rapidly progressive PKD and early lethality resembling classic ARPKD. Genetic interaction be- tween Pkhd1 and Pkd1 depended on dosage in the digenic murine models, with no significant enhancement of the monogenic phenotype until a threshold of reduced expression at the second locus was breached. -

Defining Functional Interactions During Biogenesis of Epithelial Junctions
ARTICLE Received 11 Dec 2015 | Accepted 13 Oct 2016 | Published 6 Dec 2016 | Updated 5 Jan 2017 DOI: 10.1038/ncomms13542 OPEN Defining functional interactions during biogenesis of epithelial junctions J.C. Erasmus1,*, S. Bruche1,*,w, L. Pizarro1,2,*, N. Maimari1,3,*, T. Poggioli1,w, C. Tomlinson4,J.Lees5, I. Zalivina1,w, A. Wheeler1,w, A. Alberts6, A. Russo2 & V.M.M. Braga1 In spite of extensive recent progress, a comprehensive understanding of how actin cytoskeleton remodelling supports stable junctions remains to be established. Here we design a platform that integrates actin functions with optimized phenotypic clustering and identify new cytoskeletal proteins, their functional hierarchy and pathways that modulate E-cadherin adhesion. Depletion of EEF1A, an actin bundling protein, increases E-cadherin levels at junctions without a corresponding reinforcement of cell–cell contacts. This unexpected result reflects a more dynamic and mobile junctional actin in EEF1A-depleted cells. A partner for EEF1A in cadherin contact maintenance is the formin DIAPH2, which interacts with EEF1A. In contrast, depletion of either the endocytic regulator TRIP10 or the Rho GTPase activator VAV2 reduces E-cadherin levels at junctions. TRIP10 binds to and requires VAV2 function for its junctional localization. Overall, we present new conceptual insights on junction stabilization, which integrate known and novel pathways with impact for epithelial morphogenesis, homeostasis and diseases. 1 National Heart and Lung Institute, Faculty of Medicine, Imperial College London, London SW7 2AZ, UK. 2 Computing Department, Imperial College London, London SW7 2AZ, UK. 3 Bioengineering Department, Faculty of Engineering, Imperial College London, London SW7 2AZ, UK. 4 Department of Surgery & Cancer, Faculty of Medicine, Imperial College London, London SW7 2AZ, UK. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
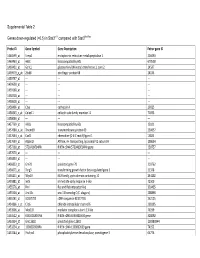
0.5) in Stat3∆/∆ Compared with Stat3flox/Flox
Supplemental Table 2 Genes down-regulated (<0.5) in Stat3∆/∆ compared with Stat3flox/flox Probe ID Gene Symbol Gene Description Entrez gene ID 1460599_at Ermp1 endoplasmic reticulum metallopeptidase 1 226090 1460463_at H60c histocompatibility 60c 670558 1460431_at Gcnt1 glucosaminyl (N-acetyl) transferase 1, core 2 14537 1459979_x_at Zfp68 zinc finger protein 68 24135 1459747_at --- --- --- 1459608_at --- --- --- 1459168_at --- --- --- 1458718_at --- --- --- 1458618_at --- --- --- 1458466_at Ctsa cathepsin A 19025 1458345_s_at Colec11 collectin sub-family member 11 71693 1458046_at --- --- --- 1457769_at H60a histocompatibility 60a 15101 1457680_a_at Tmem69 transmembrane protein 69 230657 1457644_s_at Cxcl1 chemokine (C-X-C motif) ligand 1 14825 1457639_at Atp6v1h ATPase, H+ transporting, lysosomal V1 subunit H 108664 1457260_at 5730409E04Rik RIKEN cDNA 5730409E04Rik gene 230757 1457070_at --- --- --- 1456893_at --- --- --- 1456823_at Gm70 predicted gene 70 210762 1456671_at Tbrg3 transforming growth factor beta regulated gene 3 21378 1456211_at Nlrp10 NLR family, pyrin domain containing 10 244202 1455881_at Ier5l immediate early response 5-like 72500 1455576_at Rinl Ras and Rab interactor-like 320435 1455304_at Unc13c unc-13 homolog C (C. elegans) 208898 1455241_at BC037703 cDNA sequence BC037703 242125 1454866_s_at Clic6 chloride intracellular channel 6 209195 1453906_at Med13l mediator complex subunit 13-like 76199 1453522_at 6530401N04Rik RIKEN cDNA 6530401N04 gene 328092 1453354_at Gm11602 predicted gene 11602 100380944 1453234_at -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Dynamic Transcriptomic Profiles of Zebrafish Gills in Response to Zinc
Zheng et al. BMC Genomics 2010, 11:548 http://www.biomedcentral.com/1471-2164/11/548 RESEARCH ARTICLE Open Access Dynamic transcriptomic profiles of zebrafish gills in response to zinc depletion Dongling Zheng1,4, Peter Kille2, Graham P Feeney2, Phil Cunningham1, Richard D Handy3, Christer Hogstrand1* Abstract Background: Zinc deficiency is detrimental to organisms, highlighting its role as an essential micronutrient contributing to numerous biological processes. To investigate the underlying molecular events invoked by zinc depletion we performed a temporal analysis of transcriptome changes observed within the zebrafish gill. This tissue represents a model system for studying ion absorption across polarised epithelial cells as it provides a major pathway for fish to acquire zinc directly from water whilst sharing a conserved zinc transporting system with mammals. Results: Zebrafish were treated with either zinc-depleted (water = 2.61 μgL-1; diet = 26 mg kg-1) or zinc-adequate (water = 16.3 μgL-1; diet = 233 mg kg-1) conditions for two weeks. Gill samples were collected at five time points and transcriptome changes analysed in quintuplicate using a 16K oligonucleotide array. Of the genes represented the expression of a total of 333 transcripts showed differential regulation by zinc depletion (having a fold-change greater than 1.8 and an adjusted P-value less than 0.1, controlling for a 10% False Discovery Rate). Down-regulation was dominant at most time points and distinct sets of genes were regulated at different stages. Annotation enrichment analysis revealed that ‘Developmental Process’ was the most significantly overrepresented Biological Process GO term (P = 0.0006), involving 26% of all regulated genes.